дисциплина обработки очереди HTB: руководство по использованию
введение
HTB задумывалась как более понятная, прозрачная и быстрая замена дисциплины CBQ для Linux. CBQ и HTB помогают контролировать исходящий трафик на заданном интерфейсе. Обе дисциплины позволяют разделить физический канал на несколько логических и распределить по ним трафик разных типов. Для этого необходимо определить как именно распределять физическое соединение и классифицировать исходящий трафик.
HTB в текущей реализации стала еще более масштабируемой. На сайте HTB опубликованы результаты сравнения CBQ и HTB.
Утилита tc (не только для HTB) использует следующие сокращения для обозначения пропускной способности: kbps означает килобайт в секунду, а kbit – килобит в секунду. Это один из наиболее часто встречающихся вопросов.
распределение канала
Рассмотрим задачу. Трафик клиентов A и B отправляется в сеть через интерфейс eth0 (см. рис. 1). Нужно гарантировать скорость 60 kbps для клиента B и 40 kpbs для A. Полосу А нужно в свою очередь разделить на 30 kbps для веб-трафика и 10 kbps для всего остального. Свободную часть канала нужно делить между клиентами в заданной пропорции.
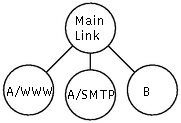
Рис. 1.
Согласно правилам HTB скорость передачи данных каждого класса будет равна минимуму из запрошенной скорости и скорости, гарантированной определением класса. Если класс запрашивает скорость меньше гарантированной, остаток полосы распределяется между остальными.
В литературе использование излишков пропускной способности канала описывается как “займ” или “одалживание”. В этом документе мы будем стараться придерживаться сложившейся терминологии, хотя нам она кажется неудачной, так как при “займах” трафика отсутствуют какие-либо гарантии. В HTB различные типы трафика описываются классами. Простейшая классификация трафика для нашей задачи показана на рисунке 1.
Рассмотрим команды, которые нам понадобятся.
tc qdisc add dev eth0 root handle 1: htb default 12
Эта команда присоединяет к устройству eth0 дисциплину очереди HTB и назначает ей управляющий дескриптор 1:. Это просто идентификатор, на который мы будем ссылаться ниже. Параметр default 12 указывает на то, что трафик, не попавший ни в одну классификацию, будет отнесен к классу 1:12. В общем виде (не только для HTB, но и для всех дисциплин и классов tc) управляющие дескрипторы (handles) выглядят как x:y где x – целое число, определяющее дисциплину, а y – целое число, определяющее класс, присоединенный к дисциплине. В дескрипторе дисциплины y должен быть равен 0. Дескриптор класса должен содержать ненулевое значение y. Запись 1: эквивалентна записи 1:0.
tc class add dev eth0 parent 1: classid 1:1 htb rate 100kbps ceil 100kbps
tc class add dev eth0 parent 1:1 classid 1:10 htb rate 30kbps ceil 100kbps
tc class add dev eth0 parent 1:1 classid 1:11 htb rate 10kbps ceil 100kbps
tc class add dev eth0 parent 1:1 classid 1:12 htb rate 60kbps ceil 100kbps
Первая строка присоединяет к дисциплине 1: корневой класс 1:11.
Класс называется корневым, если он является непосредственным потомком дисциплины HTB. Как и другие классы в дереве наследования HTB, корневые классы могут предоставлять часть своего канала соседним классам, но сами заимствовать каналы не могут. В этом их основная особенность. Можно было бы объявить все три класса трафика потомками корневой дисциплины, но тогда они не смогли бы использовать излишки пропускной способности соседей. В нашей задаче необходимо обеспечить возможность заимствования каналов, поэтому мы создали один корневой класс, а для непосредственного управления трафиком – несколько дочерних. Потомки корневого класса описаны в последних трех строчках. Параметр ceil обсудим позже.
Иногда возникает вопрос, зачем устанавливать параметр dev eth0 для потомков, если он уже определен для родительского класса. Причина в том, что каждому интерфейсу выделяется локальное пространство имен дескрипторов, поэтому, к примеру, eth0 и eth1 могут иметь разные классы с дескриптором 1:1.
Теперь определим критерии, по которым пакеты будут относиться к определенному классу. Описание методов классификации не входит в рамки обсуждения дисциплины HTB. За подробностями обратитесь к документации по команде tc filter. Нужные нам команды выглядят примерно так:
tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip src 1.2.3.4 match ip dport 80 0xffff flowid 1:10
tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip src 1.2.3.4 flowid 1:11
Здесь 1.2.3.4 - IP-адрес клиента А.
В классификаторе U32 есть недокументированная ошибка, которая приводит к тому, что команда tc filter show дублирует строчки для фильтров, содержащих классификаторы U32 c разными величинами prio.
Обратите внимание, что для класса 1:12 фильтр не создан. Возможно, дополнительный фильтр внес бы большую ясность, но сейчас мы хотим подчеркнуть, что класс 1:12 используется по умолчанию. Любой пакет, который не удовлетворяет условиям приведенных фильтров, будет отнесен к классу 1:12.
Теперь можно назначить дисциплины очередей для краевых классов. По умолчанию устанавливается дисциплина pfifo.
tc qdisc add dev eth0 parent 1:10 handle 20: pfifo limit 5
tc qdisc add dev eth0 parent 1:11 handle 30: pfifo limit 5
tc qdisc add dev eth0 parent 1:12 handle 40: sfq perturb 10
Итак, все необходимые команды выполнены.
Посмотрим что происходит, когда идет поток пакетов каждого класса со скоростью 90 kbps, и время от времени передача пакетов одного из классов прекращается.
Изначально генерируется 90kb данных каждого класса. Поскольку для передачи такого объема требуется скорость, превышающая возможную, каждому классу выделяется минимальная гарантированная в определении (параметром rate) скорость. Когда передача данных класса 0 прекращается, канал, который использовался этим классом, распределяется между остальными пропорционально указанным гарантированным скоростям: 1 часть классу 1 и 6 частей классу 2 (увеличение скорости для класса 1 трудно заметить, поскольку оно равно всего 4 kbps). Когда же прекращается поток данных класса 1, канал этого класса так же распределяется между оставшимися двумя (теперь незаметно увеличение канала для класса 0).
Сейчас стоит рассмотреть понятие квантов трафика. В процессе конкурентной передачи данных нескольких классов обслуживание каждого из них начинается после того, как обработано некоторое количество байт предыдущего класса. Это количество байт называется квантом (quantum). Когда несколько классов претендуют на канал родительского, они получают части канала пропорциональные их квантам. Важно знать, что расчет распределения канала тем точнее, чем меньше размер кванта (но квант все же должен быть не меньше величины MTU). Как правило нет необходимости задавать кванты вручную, поскольку HTB рассчитывает их самостоятельно. Размер кванта класса устанавливается (при создании или изменении класса) равным запрошенной скорости деленной на глобальный параметр r2q. По умолчанию r2q равен 10, что приемлемо для скоростей выше 15 kbps (120 kbit), поскольку обычно MTU равен 1500. Для меньших скоростей величина r2q равна 1; это подходит для скоростей от 12 kbit. При желании можно установить величину кванта вручную. В этом случае параметр r2q игнорируется. Будут выведены предупреждения о том, что установленная величина не верна, но ими можно пренебречь.
Приведенный пример был бы хорошим решением, если бы А и B не были независимыми клиентами. Но клиент А, который оплатил скорость 40 kbps, предпочитает чтобы излишки полосы, предназначенной для его веб-трафика, использовались для передачи остальных его данных, а не переходили к клиенту B. Выполнение этого требования обеспечивается созданием иерархии классов HTB.
иерархическое распределение
Задача, поставленная в конце предыдущей главы, решается введением иерархии классов, показанной на рисунке 2. Трафик клиента А теперь детализируется потомками независимого класса. Как было сказано выше, скорость передачи данных каждого класса равна минимуму из запрошенной скорости и скорости, гарантированной определением класса. Это применимо к тем классам HTB, которые не имеют потомков. Такие классы мы называем краевыми. Для родительских классов действует правило: скорость передачи данных родительского класса равна минимуму из скорости, гарантированной определением класса, и суммы скоростей, запрошенных дочерними классами. В нашем случае клиенту А гарантирована скорость 40 kbps. Если он не использует полосу, выделенную для веб-трафика, остаток канала в первую очередь отводится трафику, относящемуся к другим классам клиента А.
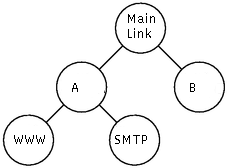
Рис. 2.
Трафик, относящийся к внутренним классам, тоже может быть классифицирован путем присоединения к ним фильтров. В итоге трафик будет отнесен к одному из краевых классов или к классу 1:0. Скорость, гарантированная родительскому классу, должна равняться сумме скоростей, гарантированных классам-потомкам.
Теперь список команд выглядит так:
tc class add dev eth0 parent 1: classid 1:1 htb rate 100kbps ceil 100kbps
tc class add dev eth0 parent 1:1 classid 1:2 htb rate 40kbps ceil 100kbps
tc class add dev eth0 parent 1:2 classid 1:10 htb rate 30kbps ceil 100kbps
tc class add dev eth0 parent 1:2 classid 1:11 htb rate 10kbps ceil 100kbps
tc class add dev eth0 parent 1:1 classid 1:12 htb rate 60kbps ceil 100kbps
ограничение максимальной скорости
Параметр ceil определяет максимальную скорость передачи данных класса. Класс не может получить канал больше указанной величины. По умолчанию ceil равен rate (в предыдущих примерах мы всегда явно указывали величину ceil именно для того, чтобы разрешить перераспределение всего канала). Теперь вместо ceil=100kbps установим для классов 1:2 (весь трафик клиента А) и 1:11 (не относящийся к WWW трафик клиента A) ceil=60kbps и ceil=20kbps соответственно.
Рассмотренное свойство используется ISP, когда нужно ограничить ширину канала клиента независимо от того, используется ли канал остальными клиентами (ISP могут расширить канал за плату). Отметим, что поскольку корневой класс не может заимствовать скорость, нет необходимости определять для него параметр ceil.
Величина ceil должна быть не меньше rate. Кроме того, величина ceil для родительского класса должна быть не меньше, чем у любого дочернего класса.
ускорения
/* В этой главе предполагается, что читатель знаком с технологией регулировки скорости отсылки пакетов при помощи токенов. – прим. переводчика. */
Сетевое устройство может передавать только один пакет в один момент времени и только с определенной устройством скоростью. Программам разделения канала остается только использовать эти параметры для расчетов деления канала на полосы требуемого размера. Таким образом, текущая и максимальная скорости передачи данных не могут быть урегулированы мгновенно. Они рассчитываются на основании усредненных данных о скорости отсылки пакетов. В действительности передача данных с учетом заданных свойств классов происходит следующим образом: устройству передается некоторое количество пакетов одного класса (которые отправляются в сеть со скоростью, определенной устройством, то есть максимально возможной), после чего некоторое время обрабатываются пакеты остальных классов. Параметры класса burst и cburst определяют количество данных, которое можно передать на максимальной скорости (скорости оборудования), после чего переключиться на обслуживание других классов.
Чем меньше параметр cburst (в идеале он должен быть равен размеру одного пакета), тем лучше он сглаживает ускорение передачи данных, чтобы скорость передачи не превысила величину ceil. Так же действует параметр peakrate дисциплины TBF.
Если параметр burst родительского класса меньше, чем у какого-нибудь из потомков, можно ожидать, что передача данных этого класса иногда будет останавливаться (так как дочерний класс пытается создать большее ускорение, чем позволено родительскому). HTB помнит о неудачной попытке ускорения в течение минуты.
Возникает вопрос: для чего нужно регулировать ускорение? Дело в том, что это дешевый и простой способ улучшить время отклика на переполненных каналах. К резким колебания склонен, к примеру, веб-трафик. Вы запрашиваете страницу, создавая ускорение, потом читаете ее. За время чтения “накапливается энергия” для следующего ускорения.
Параметры burst и cburst всегда должны быть не меньше, чем такие же параметры дочерних классов.
Оперируя высокими скоростями на компьютере с низкой частотой таймера, необходимо минимизировать величины burst и cburst для всех классов. Интервал срабатывания таймера равен 10 ms для архитектуры i386 и 1 ms для Alpha. Минимальное эффективное ускорение рассчитывается по формуле (максимальная скорость)*(интервал таймера). Например, чтобы обеспечить скорость 10 mbit на компьютере i386 параметр burst должен быть равен 12kb.
Заниженная величина burst приведет к тому, что данные будут передаваться на скорости, которая ниже запрошенной параметром rate. Последние версии tc по умолчанию самостоятельно рассчитывают и устанавливают минимальное значение burst.
распределение с учетом приоритетов
Рассмотрим два аспекта распределения каналов с учетом приоритетов.
Первый касается распределения излишков канала между потомками одного класса. Как было сказано выше, излишки канала распределяются
пропорционально гарантированным классам скоростям. Возьмем конфигурацию из раздела «иерархическое распределение», установим приоритет 0 (высший) для класса SMTP и приоритет 1 для остальных. При этом класс SMTP получит все излишки канала. Действует правило, согласно которому при распределении излишков канала класс с наивысшим приоритетом обслуживается в первую очередь. Тем не менее установки гарантированной (rate) и максимальной (seil) скоростей продолжают действовать.
Второй аспект касается общей задержки пакета. Скорость передачи данных между Ethernet-устройствами слишком высока, чтобы заметить и оценить задержку передачи пакета. Есть простое решение задачи создания наблюдаемой задержки. Создадим корневой класс HTB с гарантированной скоростью меньше 100 kbps, к нему присоединим еще одну дисциплину HTB, а к ней – класс, которому гарантируем скорость 100 kbps. Таким образом мы смоделировали перегруженное соединение с увеличенными задержками.
Рассмотрим простой сценарий с двумя классами трафика.
Дисциплина, симулирующая задержку:
tc qdisc add dev eth0 root handle 100: htb
tc class add dev eth0 parent 100: classid 100:1 htb rate 90kbps
Наблюдаемая дисциплина:
tc qdisc add dev eth0 parent 100:1 handle 1: htb
AC="tc class add dev eth0 parent"
$AC 1: classid 1:1 htb rate 100kbps
$AC 1:2 classid 1:10 htb rate 50kbps ceil 100kbps prio 1
$AC 1:2 classid 1:11 htb rate 50kbps ceil 100kbps prio 1
tc qdisc add dev eth0 parent 1:10 handle 20: pfifo limit 2
tc qdisc add dev eth0 parent 1:11 handle 21: pfifo limit 2
Создание дисциплины-потомка HTB означает не то же самое, что создание дочерних классов HTB. При наличии единственной дисциплины, присоединенной к устройству, классифицированный трафик отправляется в сеть со скоростью и задержками, определенными оборудованием (грубо говоря, “со скоростью света”). При “вложении” дисциплин корневая дисциплина фактически является моделью устройства, к которому присоединена дочерняя, таким образом условия отправки данных дочерней дисциплиной регулируются программно со всеми вытекающими последствиями.
Симулятор будет генерировать трафик обоих классов со скоростью 50 kbps, а в некоторый момент выполнит команду, которая повысит приоритет веб- трафика:
tc class change dev eth0 parent 1:2 classid 1:10 htb rate 50kbps ceil 100kbps burst 2k prio 0
С этого момента задержка класса WWW упадет почти до нуля, в то время как задержка SMTP будет расти. Когда приоритет одного класса улучшает задержку, задержка другого класса ухудшается.
Каким классам резонно назначать высший приоритет? В основном это те классы трафика, которые должны передаваться с минимальными задержками. Например видео- и аудиотрафик (здесь нужно серьезно обдумать ограничения, чтобы этот трафик не оккупировал канал полностью) или интерактивный (telnet, SSH) трафик, который по своей природе состоит из временных всплесков и не сильно влияет на соседние потоки. Распространенный трюк – увеличивать приоритет ICMP-пакетов чтобы показывать хорошее время отклика утилиты ping даже на полностью загруженных каналах (понятно, что с технической точки зрения это не говорит об улучшении соединения).
разбор статистики
Утилита tc позволяет накапливать статистику использования дисциплин очередей Linux. К сожалению данные статистики не разъясняются авторами утилиты, поэтому зачастую выглядят бесполезными. Попытаемся разобраться со статистикой HTB.
Сперва рассмотрим статистику дисциплины HTB. Здесь рассматриваются данные, собранные во время исполнения примера из раздела «иерархическое распределение».
# tc -s -d qdisc show dev eth0
qdisc pfifo 22: limit 5p
Sent 0 bytes 0 pkts (dropped 0, overlimits 0)
qdisc pfifo 21: limit 5p
Sent 2891500 bytes 5783 pkts (dropped 820, overlimits 0)
qdisc pfifo 20: limit 5p
Sent 1760000 bytes 3520 pkts (dropped 3320, overlimits 0)
qdisc htb 1: r2q 10 default 1 direct_packets_stat 0
Sent 4651500 bytes 9303 pkts (dropped 4140, overlimits 34251)
Первые три дисциплины относятся к краевым классам. Их мы рассматривать не будем, поскольку статистика PFIFO очевидна.
Дисциплина HTB. Значение overlimits показывает сколько раз дисциплина задерживала пакеты. direct_packets_stat показывает, сколько пакетов было послано через прямую очередь. Остальные данные очевидны. Рассмотрим статистику классов:
# tc -s -d class show dev eth0
class htb 1:1 root prio 0 rate 800Kbit ceil 800Kbit burst 2Kb/8 mpu 0b
cburst 2Kb/8 mpu 0b quantum 10240 level 3
Sent 5914000 bytes 11828 pkts (dropped 0, overlimits 0)
rate 70196bps 141pps
lended: 6872 borrowed: 0 giants: 0
class htb 1:2 parent 1:1 prio 0 rate 320Kbit ceil 4000Kbit burst 2Kb/8 mpu 0b
cburst 2Kb/8 mpu 0b quantum 4096 level 2
Sent 5914000 bytes 11828 pkts (dropped 0, overlimits 0)
rate 70196bps 141pps
lended: 1017 borrowed: 6872 giants: 0
class htb 1:10 parent 1:2 leaf 20: prio 1 rate 224Kbit ceil 800Kbit burst 2Kb/8 mpu 0b
cburst 2Kb/8 mpu 0b quantum 2867 level 0
Sent 2269000 bytes 4538 pkts (dropped 4400, overlimits 36358)
rate 14635bps 29pps
lended: 2939 borrowed: 1599 giants: 0
Для экономии места статистика классов 1:11 и 1:12 опущена. В начале показаны параметры класса, установленные при создании. Есть информация об уровне класса и размере кванта. Значение overlimits показывает сколько раз пакеты класса не были отосланы вследствие ограничений rate/cell (в настоящий момент рассчитывается только для краевых классов). Строка rate ... pps показывает реальную (рассчитываемую в среднем за 10 секунд) скорость передачи пакетов класса. lended это количество пакетов других классов, прошедших через канал класса “в долг”, а borrowed – количество пакетов этого класса, прошедших через одолженные каналы. Ссуды (lends) считаются отдельно для каждого класса, в то время как займы (borrows) считаются с учетом переходов (если класс 1:10 занимает канал у класса 1:2, а тот для этого занимает канал у класса 1:1, увеличиваются счетчики займов как для 1:10, так и для 1:2). Значение giants показывает количество пакетов, оказавшихся больше MTU, установленного командой tc. Такие пакеты HTB обрабатывает, но скорость регулируется с большей погрешностью. Используйте установку MTU при помощи tc (по умолчанию 1600 байт).
Martin Devera aka devik, перевод Алексея Ремизова
HTB задумывалась как более понятная, прозрачная и быстрая замена дисциплины CBQ для Linux. CBQ и HTB помогают контролировать исходящий трафик на заданном интерфейсе. Обе дисциплины позволяют разделить физический канал на несколько логических и распределить по ним трафик разных типов. Для этого необходимо определить как именно распределять физическое соединение и классифицировать исходящий трафик.
HTB в текущей реализации стала еще более масштабируемой. На сайте HTB опубликованы результаты сравнения CBQ и HTB.
Утилита tc (не только для HTB) использует следующие сокращения для обозначения пропускной способности: kbps означает килобайт в секунду, а kbit – килобит в секунду. Это один из наиболее часто встречающихся вопросов.
распределение канала
Рассмотрим задачу. Трафик клиентов A и B отправляется в сеть через интерфейс eth0 (см. рис. 1). Нужно гарантировать скорость 60 kbps для клиента B и 40 kpbs для A. Полосу А нужно в свою очередь разделить на 30 kbps для веб-трафика и 10 kbps для всего остального. Свободную часть канала нужно делить между клиентами в заданной пропорции.
Рис. 1.
Согласно правилам HTB скорость передачи данных каждого класса будет равна минимуму из запрошенной скорости и скорости, гарантированной определением класса. Если класс запрашивает скорость меньше гарантированной, остаток полосы распределяется между остальными.
В литературе использование излишков пропускной способности канала описывается как “займ” или “одалживание”. В этом документе мы будем стараться придерживаться сложившейся терминологии, хотя нам она кажется неудачной, так как при “займах” трафика отсутствуют какие-либо гарантии. В HTB различные типы трафика описываются классами. Простейшая классификация трафика для нашей задачи показана на рисунке 1.
Рассмотрим команды, которые нам понадобятся.
tc qdisc add dev eth0 root handle 1: htb default 12
Эта команда присоединяет к устройству eth0 дисциплину очереди HTB и назначает ей управляющий дескриптор 1:. Это просто идентификатор, на который мы будем ссылаться ниже. Параметр default 12 указывает на то, что трафик, не попавший ни в одну классификацию, будет отнесен к классу 1:12. В общем виде (не только для HTB, но и для всех дисциплин и классов tc) управляющие дескрипторы (handles) выглядят как x:y где x – целое число, определяющее дисциплину, а y – целое число, определяющее класс, присоединенный к дисциплине. В дескрипторе дисциплины y должен быть равен 0. Дескриптор класса должен содержать ненулевое значение y. Запись 1: эквивалентна записи 1:0.
tc class add dev eth0 parent 1: classid 1:1 htb rate 100kbps ceil 100kbps
tc class add dev eth0 parent 1:1 classid 1:10 htb rate 30kbps ceil 100kbps
tc class add dev eth0 parent 1:1 classid 1:11 htb rate 10kbps ceil 100kbps
tc class add dev eth0 parent 1:1 classid 1:12 htb rate 60kbps ceil 100kbps
Первая строка присоединяет к дисциплине 1: корневой класс 1:11.
Класс называется корневым, если он является непосредственным потомком дисциплины HTB. Как и другие классы в дереве наследования HTB, корневые классы могут предоставлять часть своего канала соседним классам, но сами заимствовать каналы не могут. В этом их основная особенность. Можно было бы объявить все три класса трафика потомками корневой дисциплины, но тогда они не смогли бы использовать излишки пропускной способности соседей. В нашей задаче необходимо обеспечить возможность заимствования каналов, поэтому мы создали один корневой класс, а для непосредственного управления трафиком – несколько дочерних. Потомки корневого класса описаны в последних трех строчках. Параметр ceil обсудим позже.
Иногда возникает вопрос, зачем устанавливать параметр dev eth0 для потомков, если он уже определен для родительского класса. Причина в том, что каждому интерфейсу выделяется локальное пространство имен дескрипторов, поэтому, к примеру, eth0 и eth1 могут иметь разные классы с дескриптором 1:1.
Теперь определим критерии, по которым пакеты будут относиться к определенному классу. Описание методов классификации не входит в рамки обсуждения дисциплины HTB. За подробностями обратитесь к документации по команде tc filter. Нужные нам команды выглядят примерно так:
tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip src 1.2.3.4 match ip dport 80 0xffff flowid 1:10
tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip src 1.2.3.4 flowid 1:11
Здесь 1.2.3.4 - IP-адрес клиента А.
В классификаторе U32 есть недокументированная ошибка, которая приводит к тому, что команда tc filter show дублирует строчки для фильтров, содержащих классификаторы U32 c разными величинами prio.
Обратите внимание, что для класса 1:12 фильтр не создан. Возможно, дополнительный фильтр внес бы большую ясность, но сейчас мы хотим подчеркнуть, что класс 1:12 используется по умолчанию. Любой пакет, который не удовлетворяет условиям приведенных фильтров, будет отнесен к классу 1:12.
Теперь можно назначить дисциплины очередей для краевых классов. По умолчанию устанавливается дисциплина pfifo.
tc qdisc add dev eth0 parent 1:10 handle 20: pfifo limit 5
tc qdisc add dev eth0 parent 1:11 handle 30: pfifo limit 5
tc qdisc add dev eth0 parent 1:12 handle 40: sfq perturb 10
Итак, все необходимые команды выполнены.
Посмотрим что происходит, когда идет поток пакетов каждого класса со скоростью 90 kbps, и время от времени передача пакетов одного из классов прекращается.
Изначально генерируется 90kb данных каждого класса. Поскольку для передачи такого объема требуется скорость, превышающая возможную, каждому классу выделяется минимальная гарантированная в определении (параметром rate) скорость. Когда передача данных класса 0 прекращается, канал, который использовался этим классом, распределяется между остальными пропорционально указанным гарантированным скоростям: 1 часть классу 1 и 6 частей классу 2 (увеличение скорости для класса 1 трудно заметить, поскольку оно равно всего 4 kbps). Когда же прекращается поток данных класса 1, канал этого класса так же распределяется между оставшимися двумя (теперь незаметно увеличение канала для класса 0).
Сейчас стоит рассмотреть понятие квантов трафика. В процессе конкурентной передачи данных нескольких классов обслуживание каждого из них начинается после того, как обработано некоторое количество байт предыдущего класса. Это количество байт называется квантом (quantum). Когда несколько классов претендуют на канал родительского, они получают части канала пропорциональные их квантам. Важно знать, что расчет распределения канала тем точнее, чем меньше размер кванта (но квант все же должен быть не меньше величины MTU). Как правило нет необходимости задавать кванты вручную, поскольку HTB рассчитывает их самостоятельно. Размер кванта класса устанавливается (при создании или изменении класса) равным запрошенной скорости деленной на глобальный параметр r2q. По умолчанию r2q равен 10, что приемлемо для скоростей выше 15 kbps (120 kbit), поскольку обычно MTU равен 1500. Для меньших скоростей величина r2q равна 1; это подходит для скоростей от 12 kbit. При желании можно установить величину кванта вручную. В этом случае параметр r2q игнорируется. Будут выведены предупреждения о том, что установленная величина не верна, но ими можно пренебречь.
Приведенный пример был бы хорошим решением, если бы А и B не были независимыми клиентами. Но клиент А, который оплатил скорость 40 kbps, предпочитает чтобы излишки полосы, предназначенной для его веб-трафика, использовались для передачи остальных его данных, а не переходили к клиенту B. Выполнение этого требования обеспечивается созданием иерархии классов HTB.
иерархическое распределение
Задача, поставленная в конце предыдущей главы, решается введением иерархии классов, показанной на рисунке 2. Трафик клиента А теперь детализируется потомками независимого класса. Как было сказано выше, скорость передачи данных каждого класса равна минимуму из запрошенной скорости и скорости, гарантированной определением класса. Это применимо к тем классам HTB, которые не имеют потомков. Такие классы мы называем краевыми. Для родительских классов действует правило: скорость передачи данных родительского класса равна минимуму из скорости, гарантированной определением класса, и суммы скоростей, запрошенных дочерними классами. В нашем случае клиенту А гарантирована скорость 40 kbps. Если он не использует полосу, выделенную для веб-трафика, остаток канала в первую очередь отводится трафику, относящемуся к другим классам клиента А.
Рис. 2.
Трафик, относящийся к внутренним классам, тоже может быть классифицирован путем присоединения к ним фильтров. В итоге трафик будет отнесен к одному из краевых классов или к классу 1:0. Скорость, гарантированная родительскому классу, должна равняться сумме скоростей, гарантированных классам-потомкам.
Теперь список команд выглядит так:
tc class add dev eth0 parent 1: classid 1:1 htb rate 100kbps ceil 100kbps
tc class add dev eth0 parent 1:1 classid 1:2 htb rate 40kbps ceil 100kbps
tc class add dev eth0 parent 1:2 classid 1:10 htb rate 30kbps ceil 100kbps
tc class add dev eth0 parent 1:2 classid 1:11 htb rate 10kbps ceil 100kbps
tc class add dev eth0 parent 1:1 classid 1:12 htb rate 60kbps ceil 100kbps
ограничение максимальной скорости
Параметр ceil определяет максимальную скорость передачи данных класса. Класс не может получить канал больше указанной величины. По умолчанию ceil равен rate (в предыдущих примерах мы всегда явно указывали величину ceil именно для того, чтобы разрешить перераспределение всего канала). Теперь вместо ceil=100kbps установим для классов 1:2 (весь трафик клиента А) и 1:11 (не относящийся к WWW трафик клиента A) ceil=60kbps и ceil=20kbps соответственно.
Рассмотренное свойство используется ISP, когда нужно ограничить ширину канала клиента независимо от того, используется ли канал остальными клиентами (ISP могут расширить канал за плату). Отметим, что поскольку корневой класс не может заимствовать скорость, нет необходимости определять для него параметр ceil.
Величина ceil должна быть не меньше rate. Кроме того, величина ceil для родительского класса должна быть не меньше, чем у любого дочернего класса.
ускорения
/* В этой главе предполагается, что читатель знаком с технологией регулировки скорости отсылки пакетов при помощи токенов. – прим. переводчика. */
Сетевое устройство может передавать только один пакет в один момент времени и только с определенной устройством скоростью. Программам разделения канала остается только использовать эти параметры для расчетов деления канала на полосы требуемого размера. Таким образом, текущая и максимальная скорости передачи данных не могут быть урегулированы мгновенно. Они рассчитываются на основании усредненных данных о скорости отсылки пакетов. В действительности передача данных с учетом заданных свойств классов происходит следующим образом: устройству передается некоторое количество пакетов одного класса (которые отправляются в сеть со скоростью, определенной устройством, то есть максимально возможной), после чего некоторое время обрабатываются пакеты остальных классов. Параметры класса burst и cburst определяют количество данных, которое можно передать на максимальной скорости (скорости оборудования), после чего переключиться на обслуживание других классов.
Чем меньше параметр cburst (в идеале он должен быть равен размеру одного пакета), тем лучше он сглаживает ускорение передачи данных, чтобы скорость передачи не превысила величину ceil. Так же действует параметр peakrate дисциплины TBF.
Если параметр burst родительского класса меньше, чем у какого-нибудь из потомков, можно ожидать, что передача данных этого класса иногда будет останавливаться (так как дочерний класс пытается создать большее ускорение, чем позволено родительскому). HTB помнит о неудачной попытке ускорения в течение минуты.
Возникает вопрос: для чего нужно регулировать ускорение? Дело в том, что это дешевый и простой способ улучшить время отклика на переполненных каналах. К резким колебания склонен, к примеру, веб-трафик. Вы запрашиваете страницу, создавая ускорение, потом читаете ее. За время чтения “накапливается энергия” для следующего ускорения.
Параметры burst и cburst всегда должны быть не меньше, чем такие же параметры дочерних классов.
Оперируя высокими скоростями на компьютере с низкой частотой таймера, необходимо минимизировать величины burst и cburst для всех классов. Интервал срабатывания таймера равен 10 ms для архитектуры i386 и 1 ms для Alpha. Минимальное эффективное ускорение рассчитывается по формуле (максимальная скорость)*(интервал таймера). Например, чтобы обеспечить скорость 10 mbit на компьютере i386 параметр burst должен быть равен 12kb.
Заниженная величина burst приведет к тому, что данные будут передаваться на скорости, которая ниже запрошенной параметром rate. Последние версии tc по умолчанию самостоятельно рассчитывают и устанавливают минимальное значение burst.
распределение с учетом приоритетов
Рассмотрим два аспекта распределения каналов с учетом приоритетов.
Первый касается распределения излишков канала между потомками одного класса. Как было сказано выше, излишки канала распределяются
пропорционально гарантированным классам скоростям. Возьмем конфигурацию из раздела «иерархическое распределение», установим приоритет 0 (высший) для класса SMTP и приоритет 1 для остальных. При этом класс SMTP получит все излишки канала. Действует правило, согласно которому при распределении излишков канала класс с наивысшим приоритетом обслуживается в первую очередь. Тем не менее установки гарантированной (rate) и максимальной (seil) скоростей продолжают действовать.
Второй аспект касается общей задержки пакета. Скорость передачи данных между Ethernet-устройствами слишком высока, чтобы заметить и оценить задержку передачи пакета. Есть простое решение задачи создания наблюдаемой задержки. Создадим корневой класс HTB с гарантированной скоростью меньше 100 kbps, к нему присоединим еще одну дисциплину HTB, а к ней – класс, которому гарантируем скорость 100 kbps. Таким образом мы смоделировали перегруженное соединение с увеличенными задержками.
Рассмотрим простой сценарий с двумя классами трафика.
Дисциплина, симулирующая задержку:
tc qdisc add dev eth0 root handle 100: htb
tc class add dev eth0 parent 100: classid 100:1 htb rate 90kbps
Наблюдаемая дисциплина:
tc qdisc add dev eth0 parent 100:1 handle 1: htb
AC="tc class add dev eth0 parent"
$AC 1: classid 1:1 htb rate 100kbps
$AC 1:2 classid 1:10 htb rate 50kbps ceil 100kbps prio 1
$AC 1:2 classid 1:11 htb rate 50kbps ceil 100kbps prio 1
tc qdisc add dev eth0 parent 1:10 handle 20: pfifo limit 2
tc qdisc add dev eth0 parent 1:11 handle 21: pfifo limit 2
Создание дисциплины-потомка HTB означает не то же самое, что создание дочерних классов HTB. При наличии единственной дисциплины, присоединенной к устройству, классифицированный трафик отправляется в сеть со скоростью и задержками, определенными оборудованием (грубо говоря, “со скоростью света”). При “вложении” дисциплин корневая дисциплина фактически является моделью устройства, к которому присоединена дочерняя, таким образом условия отправки данных дочерней дисциплиной регулируются программно со всеми вытекающими последствиями.
Симулятор будет генерировать трафик обоих классов со скоростью 50 kbps, а в некоторый момент выполнит команду, которая повысит приоритет веб- трафика:
tc class change dev eth0 parent 1:2 classid 1:10 htb rate 50kbps ceil 100kbps burst 2k prio 0
С этого момента задержка класса WWW упадет почти до нуля, в то время как задержка SMTP будет расти. Когда приоритет одного класса улучшает задержку, задержка другого класса ухудшается.
Каким классам резонно назначать высший приоритет? В основном это те классы трафика, которые должны передаваться с минимальными задержками. Например видео- и аудиотрафик (здесь нужно серьезно обдумать ограничения, чтобы этот трафик не оккупировал канал полностью) или интерактивный (telnet, SSH) трафик, который по своей природе состоит из временных всплесков и не сильно влияет на соседние потоки. Распространенный трюк – увеличивать приоритет ICMP-пакетов чтобы показывать хорошее время отклика утилиты ping даже на полностью загруженных каналах (понятно, что с технической точки зрения это не говорит об улучшении соединения).
разбор статистики
Утилита tc позволяет накапливать статистику использования дисциплин очередей Linux. К сожалению данные статистики не разъясняются авторами утилиты, поэтому зачастую выглядят бесполезными. Попытаемся разобраться со статистикой HTB.
Сперва рассмотрим статистику дисциплины HTB. Здесь рассматриваются данные, собранные во время исполнения примера из раздела «иерархическое распределение».
# tc -s -d qdisc show dev eth0
qdisc pfifo 22: limit 5p
Sent 0 bytes 0 pkts (dropped 0, overlimits 0)
qdisc pfifo 21: limit 5p
Sent 2891500 bytes 5783 pkts (dropped 820, overlimits 0)
qdisc pfifo 20: limit 5p
Sent 1760000 bytes 3520 pkts (dropped 3320, overlimits 0)
qdisc htb 1: r2q 10 default 1 direct_packets_stat 0
Sent 4651500 bytes 9303 pkts (dropped 4140, overlimits 34251)
Первые три дисциплины относятся к краевым классам. Их мы рассматривать не будем, поскольку статистика PFIFO очевидна.
Дисциплина HTB. Значение overlimits показывает сколько раз дисциплина задерживала пакеты. direct_packets_stat показывает, сколько пакетов было послано через прямую очередь. Остальные данные очевидны. Рассмотрим статистику классов:
# tc -s -d class show dev eth0
class htb 1:1 root prio 0 rate 800Kbit ceil 800Kbit burst 2Kb/8 mpu 0b
cburst 2Kb/8 mpu 0b quantum 10240 level 3
Sent 5914000 bytes 11828 pkts (dropped 0, overlimits 0)
rate 70196bps 141pps
lended: 6872 borrowed: 0 giants: 0
class htb 1:2 parent 1:1 prio 0 rate 320Kbit ceil 4000Kbit burst 2Kb/8 mpu 0b
cburst 2Kb/8 mpu 0b quantum 4096 level 2
Sent 5914000 bytes 11828 pkts (dropped 0, overlimits 0)
rate 70196bps 141pps
lended: 1017 borrowed: 6872 giants: 0
class htb 1:10 parent 1:2 leaf 20: prio 1 rate 224Kbit ceil 800Kbit burst 2Kb/8 mpu 0b
cburst 2Kb/8 mpu 0b quantum 2867 level 0
Sent 2269000 bytes 4538 pkts (dropped 4400, overlimits 36358)
rate 14635bps 29pps
lended: 2939 borrowed: 1599 giants: 0
Для экономии места статистика классов 1:11 и 1:12 опущена. В начале показаны параметры класса, установленные при создании. Есть информация об уровне класса и размере кванта. Значение overlimits показывает сколько раз пакеты класса не были отосланы вследствие ограничений rate/cell (в настоящий момент рассчитывается только для краевых классов). Строка rate ... pps показывает реальную (рассчитываемую в среднем за 10 секунд) скорость передачи пакетов класса. lended это количество пакетов других классов, прошедших через канал класса “в долг”, а borrowed – количество пакетов этого класса, прошедших через одолженные каналы. Ссуды (lends) считаются отдельно для каждого класса, в то время как займы (borrows) считаются с учетом переходов (если класс 1:10 занимает канал у класса 1:2, а тот для этого занимает канал у класса 1:1, увеличиваются счетчики займов как для 1:10, так и для 1:2). Значение giants показывает количество пакетов, оказавшихся больше MTU, установленного командой tc. Такие пакеты HTB обрабатывает, но скорость регулируется с большей погрешностью. Используйте установку MTU при помощи tc (по умолчанию 1600 байт).
Martin Devera aka devik, перевод Алексея Ремизова
Сетевые решения. Статья была опубликована в номере 05 за 2006 год в рубрике sysadmin
