одна модель адресов и маршрутизации в Интернет
Современная модель маршрутизации в Интернете выросла из вполне конкретных условий: подключенные по проводам стационарные компьютеры, принадлежащие крупным организациям (корпорациям и универистетам). Сеть росла и ширилась, возникали новые проблемы, которые решались в стиле ad- hoc, архитектурное наследство накапливалось слой за слоем. Если сравнивать Интернет со зданием, то подойдет аналогия старого замка, который достраивали и расширяли в разные эпохи. Я выделю два объекта для критики. Первый - это умножение сущностей, второй - существующая система маршрутизации.
умножение сущностей
Умножение сущностей происходит по очень простой причине. Когда людям дают технологию со всеми ее достоинствами и недостатками, люди начинают ее как-то использовать. И если какой-то умник вдруг решит что-то в технологии поменять, то он обнаружит, что даже самые нелепые фичи и баги кем-то используются и кто-то на них уже "забился". Поэтому развитие чаще происходит по пути создания некоторых новых механизмов, новых сущностей поверх старых. Если мы взглянем на маршрутизацию, то мы увидим такие сущности, как само устройство, его адреса, сетки/маски, уровнем выше - например, области OSPF, еще уровнем выше - автономные системы.
маршрутизация
Изначально рассчитывалось, что маршрутизация будет иметь иерархически-географический характер, по аналогии с телефонией. Но затем обнаружилось, что эта схема совсем не прогрессивна - и понеслось.
В настоящий момент используется схема с областями, дающая сублинейную сложность. Если объяснять на пальцах, то сложность маршрутизации на любой адрес (4 байта) разбита на задачу маршрутизации к соответствующей автономной системе (их ~2 байта), а затем внутри нее (оставшиеся 2 условных байта). Причем, внутри AS маршрутизация также может осуществляться между областями (OSPF, например). Таким образом система становится сложней, различных маршрутных таблиц больше, маршруты несколько кривей идеальных, однако каждая из маршрутных таблиц имеет приемлемый размер. При этом стоит заметить, что на каждом из уровней маршрутизация осуществляется алгоритмом типа Дейкстры или Форда-Беллмана. Или иерархически. Эта схема начала активно проседать, когда маленькие провайдеры и большие клиенты начали активно повышать свою связность (например, для повышения надежности или балансировки нагрузки) и анонсировать длинные префиксы. Маршрутная таблица в DFZ (Default Free Zone - это те, кто держат полную маршрутную таблицу) начала расти экспоненциально. Некоторое время (года два) ситуацию спасала агрегация по CIDR, но затем экспоненциальный рост возобновился. А что такое экспоненциальный рост, мы учили в школе :)
Есть самые разные предложения, что с этим ростом делать. Например, D.Krioukov и др. из CAIDA предложили как-нибудь повторить трюк - объединить, например, автономки в области. Тогда все шоколадно, две маршрутные таблицы в DFZ, каждая порядка байта (то есть где-то до сотен записей). Эта затея продвигается под слоганом Compact Interdomain Routing. К недостаткам технологии можно отнести повышение сложности системы (а соответственно, и понижение надежности), а также тот обидный факт, что качество маршрутов несколько ухудшится.
Теоретически, удлинение составит до 3-х раз в таких несмешных единицах, как AS hop (пройденные пакетом автономные системы). Практически, на scale-free топологиях среднее удлинение оценивается Крюковым и другими в 10%. Проблема также в том, что AS hop может происходить внутри одной стойки, а может - через океан. Как, впрочем, и обычный IP hop. Также стоит заметить, что при современном случайном распределении префиксов между автономками, эти префиксы все равно придется перечислять. То есть красиво и такой трюк проделать не получится.
что же тут плохо?
На мой скромный взгляд тут есть два базовых порока:
1. Хоп в качестве метрики расстояния ненадежен - может различаться на три-пять порядков по цене, дистанции, времени. Это влечет необходимость ручных подкруток, исключает автоматическую агрегацию.
2. Адреса не соответствуют топологии - возникает необходимость описывать взаимоотношение адресов и топологии сети. Адреса не соответствуют "областям" (например, AS) - возникает необходимость описывать взаимоотношения адресов и AS. Сущности притом абсолютно виртуальные.
В следующей части я попробую нарисовать лучший Интернет - каким бы он мог бы быть, если эти пороки исправить.
модель: Интернет, как океан
мера расстояния
Для разумной маршрутизации необходимо сохранить локальность, то есть метрику расстояния. Лучше всего для этого подходит RTT. Я на досуге расчел, что в радиусе ~150 км задержки, вызванные оборудованием, нивелируют нижнюю границу, обусловленную c. На больших расстояниях - уже c сказывается. Единственный видимый мне способ использовать RTT в маршрутизации - производить замеры с маршрутизирующих устройств, то есть подмешивать в проходящий поток свои пинги.
Если у нас есть локальность - уже маршрутизация требует O(log N), а не O(N0.5), как BGP. А если маршрутная таблица имеет логарифмический размер, то трюк с делением на области (BGP, OSPF, compact routing) нам уже не нужен. При маршрутизации используем только префикс, который одновременно является идентификатором устройства (или группы устройств) и идентификатором области - а именно, области, содержащей даунлинки данного устройства.
адреса - лишь отражение топологии сети
Во-первых, mobilis in mobili, как говаривал капитан Немо. Все сопли относительно сложностей переадресации устройств необходимо отбросить. Устройство получает адрес от аплинка, меняется аплинк - меняется адрес устройства. Автоматически.
Во-вторых, поскольку сеть имеет топологию далеко не древообразную, каждое устройство может иметь несколько аплинков, а значит и несколько адресов. Если сейчас маршрутизацию «плющит и колбасит» оттого, что небольшие провайдеры и большие клиенты начали мультихомиться, то у нас каждый сотовик будет мультихомиться, когда пожелает - получая адреса от каждого из аплинков (вероятно, сот). В результате получается топоним, как я это называю, то есть набор адресов каждого устройства - это ациклический ориентированный граф.
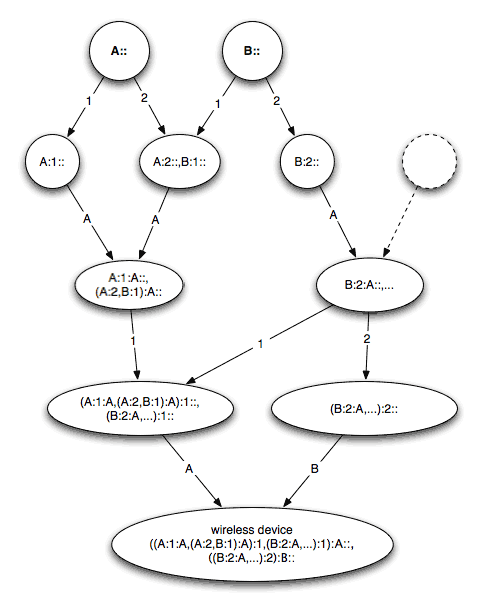
Рис. 1.
Рисунок 1 иллюстрирует следующую выкладку. Топоним конечного устройства, ((A:1:A,(A:2,B:1):A):1,(B:2:A,...):1) :A::,((B:2:A,...):2):B:: , представляет из себя набор IPv6-префиксов, каждый из которых достаточен для маршрутизации. Однако, поскольку разные адреса соответствуют разным маршрутам, то для участников из разных частей сети, а также в зависимости от других условий, какие-то адреса работают лучше, какие-то хуже. Единственный способ разобраться - методом проб и ошибок (то есть статистически).
* A:1:A:1:A::
* A:2:A:1:A::
* B:1:A:1:A::
* B:2:A:1:A::
* B:2:A:2:B::
* ...:2:B::
Таким образом, уже необходимо проапгрейдить стек конечных устройств - чтобы они могли работать со множественными адресами и выбирать лучший. Это требует изменений на 4 уровне (например, TCP), IP-пакет же на 3-м уровне остается прежним. Отчасти это перекликается с Site Multihoming by IPv6 Intermediation (shim6), если не считать того момента, что авторы shim6 все еще надеются приделать это, как патч к IPv6-стеку. Поскольку один адрес - это частный случай множества адресов, возможно сохранение прозрачной совместимости с современным TCP.
Возникает вопрос, а что же будет корнем в такой системе адресации? Совершенно однозначно, это IX. Поскольку это а) точки и б) точки с очень хорошей connectivity. Это позволит нам практиковать гео-аггрегацию (см. далее).
маршрутизация - дело каждого
Раз маршрутные таблицы зависят от количества всех устройств логарифмически, то такие таблицы можно поддерживать чуть ли не на каждом IP- устройстве. А что?
Впрочем, устройство может поступать крайне просто: посмотрев адрес назначения (это обязательно!), маршрутизировать пакет в сторону ближайшего общего аплинка, наподобие сегодняшнего default gw. Назовем это каноническим путем. Тогда маршрутная таблица по размеру вообще равна количеству аплинков устройства.
Для того, чтобы использовать peering links, то есть такие линки, которые не вовлечены в отношения аплинк/даунлинк, разрешим устройствам обмениваться анонсами вида "данный префикс достижим через меня с таким-то RTT". Поскольку те устройства, что все-таки держат маршрутные таблицы, пингуют содержащиеся в них префиксы, то таким сведениям можно доверять. По сложности такой протокол будет уступать BGP, но несколько превзойдет ARP. Даже если такая схема даст сбой, устройство сможет это понять и откатиться к канонической маршрутизации. Автоматически.
оценка сложности
В этой статье я доказываю, что глобально такая схема будет иметь вычислительную сложность O(log N). Вкратце, доказательство базируется на следующем: на настоящий момент сети густо покрывают поверхность планеты, а маршруты оптимизированы и, как правило, RTT находится в диапазоне tc..10tc, подразумевая под tc кратчайшее возможное время прохождения сигнала по кратчайшей географической дистанции (по глобусу). В общем-то, нам важен тот факт, что в оптимизированной сети на дистанциях больше 100 км RTT определяется в первую очередь длиной провода. В таком случае, маршрутизатор может использовать следующую политику поддержания маршрутной таблицы: удалять все префиксы, которые не дают 10% выгоды в RTT относительно более общего префикса (то есть если IPv6- префикс 000A:000B:000C::/48 примерно на том же расстоянии, что и 000A:000B::/32, то можно не заморачиваться подробностями и более длинный префикс удалить). Чем больше расстояние - тем более короткие префиксы (более крупные агрегаты) достаточны для описания картины. Когда пакет "прыгает" к цели, каждый последующий маршрутизатор имеет все более точное представление о том, где эта цель находится.
Все это дает нам маршрутную таблицу логарифмического размера при фиксированном stretch (допустимом удлинении маршрута). Например, при stretch=1,1 на расстоянии 10000 км мы можем работать с агрегатами размером до 4000 км - то есть, по сути, помнить только направление до соответствующего IX.
в окрестности 100 км
В такой окрестности расстояние имеет второстепенное значение - важней топология сети, количество хопов, характеристики устройств. На иерархическую маршрутизацию в окрестности 100 км рассчитывать наивно. Маршрутизация по Дейкстре требует O(N) - если, конечно, не провернуть тот самый трюк с областями. Но мы от этого пытались уйти.
Жизнь станет проще, если рассматривать окрестность не как случайный/обычный/простой/любой граф, а как граф со scale-free топологией. Данная топология характеризуется степенным (k-?) распределением степеней вершин, то есть мало вершин с большой степенью (количеством связей) и много - с малой. Вершины с большой степенью называются хабы. Такая топология много где встречается - в социальных связях, половых контактах, связности аэропортов, графе ссылок WWW, связности автономных систем и отдельных маршрутизаторов. Хотя есть модели с большим количеством измерений, например HOT, которые претендуют на более точное описание топологии Сети, но здесь достаточно и этой.
Для решения задачи о кратчайших путях и имя и маршрутная таблица должны быть сублинейны, ориентировочно имя размера O(N0.2) и таблица размера O(N0.5). Принимая количество рутеров в окрестности 100 км за 1 миллион, это ~10 и 1000 соответственно.
устойчивость
Высказываю на правах гипотезы. Если замеры происходят на порядок чаще, чем изменения и изменения происходят постепенно, то система может прийти к "рыночному равновесию".
То есть если у нас два линка, RTT 100ms и 102ms, мы шлем 60% через один и 40% через другой. Один линк начинает проседать (пошли дропы) - перекладываем по 5% на другой, причем временной шаг перекладывания, повторяюсь, в 10 раз больше шага замера. Вопрос во временном масштабе. Какие (микро)колебания игнорировать, а за какими (макро)колебаниями следовать. Например, изменения паттернов трафика в зависимости от времени дня/выходных/праздников - это то, к чему нужно адаптироваться. А кратковременные всплески не должны существенно повлиять на маршрутизацию (трафик имеет фрактальную, микроосциллированную природу).
последствия
Задача сети - передавать данные быстро, дешево и без сбоев. Описанный подход к маршрутизации позволит выполнить эту задачу лучше.
самонастройка
Устройства могут сами себя настраивать, а конструкция обладает избыточностью. Как пример следствия, устройство может само "попробовать" новый аплинк и либо оставить его, либо убрать. Общая идея: монтер проложил провод - и оно работает. Также интересный эффект заключается в том, что подобная сеть сможет собраться из кусочков, как Терминатор. Сама собой. Также, поскольку список адресов можно произвольно пополнять/сокращать - появляется возможность прозрачного роуминга на уровне IP. То есть на уровне IP происходит то же, что сейчас с сотовым телефоном - устройство перемещается, и постоянно остается на связи, независимо от технологии доступа. Есть рядом хот-спот - есть видеоконференцсвязь. Есть сота - доступен голос.
Получаем полную цифровую конвергенцию :). И чтобы этого достичь с массой мелких устройств, необходима технология, работающая абсолютно без админов. Вообще. Администрирование должно сводится к следующему: горит красная лампочка - поднял, отправил в ремонт. Прислали - положил обратно :)
Успех цифровых фотоаппаратов и рост функционала сотовых телефонов - хорошие показатели того, к чему дело идет.
базовый QoS
QoS в IP-сети общего пользования разрешается непосредственным практическим образом - перебираем разные IP-адреса цели и смотрим, где eRTT меньше получается (под eRTT далее подразумевается "эффективный RTT": средний RTT за период, при этом в случае дропа время ретрансмиссии добавляется к RTT). Разные адреса соответствуют разным путям.
Аналогично может вести себя каждый промежуточный маршрутизатор: раз он замеряет eRTT до префиксов в своей маршрутной таблице - он может посылать пакеты более короткими путями. Сам. С учетом переполнения каналов (когда пинги теряться начнут). «Черезпакетица» и jitter, в худшем случае, вымениваются на задержку. По черновой прикидке, мы получаем буфер размером порядка не более всего трафика, находящегося в полете. То есть некоторый практический уровень QoS осуществим в подобной публичной сети. Если у пользователя особые запросы - то нужны и особые средства, реализовывать которые "для всех" довольно дорого.
надежность
Надежность достигается многократным дублированием на всех уровнях и через overprovisioning. Overprovisioning (прокладывание каналов избыточной на сегодня пропускной способности) и сегодня является самой простой и надежной мерой обеспечения качества связи. Учитывая, что новые технологии позволяют на порядки увеличить пропускную способность уже существующих каналов, а проложить второй провод рядом с первым - дешевле, чем первый, то так оно, по-видимому, и останется (© A.Odlyzko).
Кстати, если верить RFC3439, то основные источники ненадежности - это усложнение систем и человеческий фактор (80%). Система в нашем случае получается чрезвычайно простая (одноуровневая), а человек из процесса исключен.
Конкуренция и кооперация
Интересная особенность описываемой технологии, что при нескольких аплинках их возможности в плане покрытия и пропускной способности складываются: получается + или U, а не max, как при выборе одного ("лучшего") оператора. В частности, это позволяет побороть основное противоречие беспроводных технологий: чем выше частота, тем меньше радиус действия (и, соответственно, дороже выстроить покрытие). В нашем случае: достаточно покрыть продвинутой технологией только те участки, где она востребована. Также, не требуется многократного покрытия.
когда же?
Заметим, что в изложенной схеме используется крайне мало абсолютно оригинальных идей. Разве что использование RTT в качестве метрики при маршрутизации если и предлагалось, то не обсуждалось широко. Самоназначение адресов - DHCP, префиксы - CIDR, множественность адресов - shim6, автоматическое вычисление методом проб и ошибок похоже на определение окна в TCP и т.д. В данном подходе сделана лишь попытка все разобрать и собрать заново по-правильному (кайдзен).
В конце концов, сегодня и оборудование и провода - лишь стремительно дешевеющие продукты глубокой переработки песка. Чем популярней изделие, тем оно дешевле, и т.д. и т.п. Реально дефицитный ресурс - это люди. И если схема действует на 20% менее эффективно, но требует на 50% меньше людей - то это хорошая схема. Потому что грешно экономить песок и слабые электромагнитные импульсы за счет людей. И невыгодно.
Кто знает, может и увидим подобную, а то и лучшую сеть, еще при нашей жизни.
Виктор Грищенко
умножение сущностей
Умножение сущностей происходит по очень простой причине. Когда людям дают технологию со всеми ее достоинствами и недостатками, люди начинают ее как-то использовать. И если какой-то умник вдруг решит что-то в технологии поменять, то он обнаружит, что даже самые нелепые фичи и баги кем-то используются и кто-то на них уже "забился". Поэтому развитие чаще происходит по пути создания некоторых новых механизмов, новых сущностей поверх старых. Если мы взглянем на маршрутизацию, то мы увидим такие сущности, как само устройство, его адреса, сетки/маски, уровнем выше - например, области OSPF, еще уровнем выше - автономные системы.
маршрутизация
Изначально рассчитывалось, что маршрутизация будет иметь иерархически-географический характер, по аналогии с телефонией. Но затем обнаружилось, что эта схема совсем не прогрессивна - и понеслось.
В настоящий момент используется схема с областями, дающая сублинейную сложность. Если объяснять на пальцах, то сложность маршрутизации на любой адрес (4 байта) разбита на задачу маршрутизации к соответствующей автономной системе (их ~2 байта), а затем внутри нее (оставшиеся 2 условных байта). Причем, внутри AS маршрутизация также может осуществляться между областями (OSPF, например). Таким образом система становится сложней, различных маршрутных таблиц больше, маршруты несколько кривей идеальных, однако каждая из маршрутных таблиц имеет приемлемый размер. При этом стоит заметить, что на каждом из уровней маршрутизация осуществляется алгоритмом типа Дейкстры или Форда-Беллмана. Или иерархически. Эта схема начала активно проседать, когда маленькие провайдеры и большие клиенты начали активно повышать свою связность (например, для повышения надежности или балансировки нагрузки) и анонсировать длинные префиксы. Маршрутная таблица в DFZ (Default Free Zone - это те, кто держат полную маршрутную таблицу) начала расти экспоненциально. Некоторое время (года два) ситуацию спасала агрегация по CIDR, но затем экспоненциальный рост возобновился. А что такое экспоненциальный рост, мы учили в школе :)
Есть самые разные предложения, что с этим ростом делать. Например, D.Krioukov и др. из CAIDA предложили как-нибудь повторить трюк - объединить, например, автономки в области. Тогда все шоколадно, две маршрутные таблицы в DFZ, каждая порядка байта (то есть где-то до сотен записей). Эта затея продвигается под слоганом Compact Interdomain Routing. К недостаткам технологии можно отнести повышение сложности системы (а соответственно, и понижение надежности), а также тот обидный факт, что качество маршрутов несколько ухудшится.
Теоретически, удлинение составит до 3-х раз в таких несмешных единицах, как AS hop (пройденные пакетом автономные системы). Практически, на scale-free топологиях среднее удлинение оценивается Крюковым и другими в 10%. Проблема также в том, что AS hop может происходить внутри одной стойки, а может - через океан. Как, впрочем, и обычный IP hop. Также стоит заметить, что при современном случайном распределении префиксов между автономками, эти префиксы все равно придется перечислять. То есть красиво и такой трюк проделать не получится.
что же тут плохо?
На мой скромный взгляд тут есть два базовых порока:
1. Хоп в качестве метрики расстояния ненадежен - может различаться на три-пять порядков по цене, дистанции, времени. Это влечет необходимость ручных подкруток, исключает автоматическую агрегацию.
2. Адреса не соответствуют топологии - возникает необходимость описывать взаимоотношение адресов и топологии сети. Адреса не соответствуют "областям" (например, AS) - возникает необходимость описывать взаимоотношения адресов и AS. Сущности притом абсолютно виртуальные.
В следующей части я попробую нарисовать лучший Интернет - каким бы он мог бы быть, если эти пороки исправить.
модель: Интернет, как океан
мера расстояния
Для разумной маршрутизации необходимо сохранить локальность, то есть метрику расстояния. Лучше всего для этого подходит RTT. Я на досуге расчел, что в радиусе ~150 км задержки, вызванные оборудованием, нивелируют нижнюю границу, обусловленную c. На больших расстояниях - уже c сказывается. Единственный видимый мне способ использовать RTT в маршрутизации - производить замеры с маршрутизирующих устройств, то есть подмешивать в проходящий поток свои пинги.
Если у нас есть локальность - уже маршрутизация требует O(log N), а не O(N0.5), как BGP. А если маршрутная таблица имеет логарифмический размер, то трюк с делением на области (BGP, OSPF, compact routing) нам уже не нужен. При маршрутизации используем только префикс, который одновременно является идентификатором устройства (или группы устройств) и идентификатором области - а именно, области, содержащей даунлинки данного устройства.
адреса - лишь отражение топологии сети
Во-первых, mobilis in mobili, как говаривал капитан Немо. Все сопли относительно сложностей переадресации устройств необходимо отбросить. Устройство получает адрес от аплинка, меняется аплинк - меняется адрес устройства. Автоматически.
Во-вторых, поскольку сеть имеет топологию далеко не древообразную, каждое устройство может иметь несколько аплинков, а значит и несколько адресов. Если сейчас маршрутизацию «плющит и колбасит» оттого, что небольшие провайдеры и большие клиенты начали мультихомиться, то у нас каждый сотовик будет мультихомиться, когда пожелает - получая адреса от каждого из аплинков (вероятно, сот). В результате получается топоним, как я это называю, то есть набор адресов каждого устройства - это ациклический ориентированный граф.
Рис. 1.
Рисунок 1 иллюстрирует следующую выкладку. Топоним конечного устройства, ((A:1:A,(A:2,B:1):A):1,(B:2:A,...):1) :A::,((B:2:A,...):2):B:: , представляет из себя набор IPv6-префиксов, каждый из которых достаточен для маршрутизации. Однако, поскольку разные адреса соответствуют разным маршрутам, то для участников из разных частей сети, а также в зависимости от других условий, какие-то адреса работают лучше, какие-то хуже. Единственный способ разобраться - методом проб и ошибок (то есть статистически).
* A:1:A:1:A::
* A:2:A:1:A::
* B:1:A:1:A::
* B:2:A:1:A::
* B:2:A:2:B::
* ...:2:B::
Таким образом, уже необходимо проапгрейдить стек конечных устройств - чтобы они могли работать со множественными адресами и выбирать лучший. Это требует изменений на 4 уровне (например, TCP), IP-пакет же на 3-м уровне остается прежним. Отчасти это перекликается с Site Multihoming by IPv6 Intermediation (shim6), если не считать того момента, что авторы shim6 все еще надеются приделать это, как патч к IPv6-стеку. Поскольку один адрес - это частный случай множества адресов, возможно сохранение прозрачной совместимости с современным TCP.
Возникает вопрос, а что же будет корнем в такой системе адресации? Совершенно однозначно, это IX. Поскольку это а) точки и б) точки с очень хорошей connectivity. Это позволит нам практиковать гео-аггрегацию (см. далее).
маршрутизация - дело каждого
Раз маршрутные таблицы зависят от количества всех устройств логарифмически, то такие таблицы можно поддерживать чуть ли не на каждом IP- устройстве. А что?
Впрочем, устройство может поступать крайне просто: посмотрев адрес назначения (это обязательно!), маршрутизировать пакет в сторону ближайшего общего аплинка, наподобие сегодняшнего default gw. Назовем это каноническим путем. Тогда маршрутная таблица по размеру вообще равна количеству аплинков устройства.
Для того, чтобы использовать peering links, то есть такие линки, которые не вовлечены в отношения аплинк/даунлинк, разрешим устройствам обмениваться анонсами вида "данный префикс достижим через меня с таким-то RTT". Поскольку те устройства, что все-таки держат маршрутные таблицы, пингуют содержащиеся в них префиксы, то таким сведениям можно доверять. По сложности такой протокол будет уступать BGP, но несколько превзойдет ARP. Даже если такая схема даст сбой, устройство сможет это понять и откатиться к канонической маршрутизации. Автоматически.
оценка сложности
В этой статье я доказываю, что глобально такая схема будет иметь вычислительную сложность O(log N). Вкратце, доказательство базируется на следующем: на настоящий момент сети густо покрывают поверхность планеты, а маршруты оптимизированы и, как правило, RTT находится в диапазоне tc..10tc, подразумевая под tc кратчайшее возможное время прохождения сигнала по кратчайшей географической дистанции (по глобусу). В общем-то, нам важен тот факт, что в оптимизированной сети на дистанциях больше 100 км RTT определяется в первую очередь длиной провода. В таком случае, маршрутизатор может использовать следующую политику поддержания маршрутной таблицы: удалять все префиксы, которые не дают 10% выгоды в RTT относительно более общего префикса (то есть если IPv6- префикс 000A:000B:000C::/48 примерно на том же расстоянии, что и 000A:000B::/32, то можно не заморачиваться подробностями и более длинный префикс удалить). Чем больше расстояние - тем более короткие префиксы (более крупные агрегаты) достаточны для описания картины. Когда пакет "прыгает" к цели, каждый последующий маршрутизатор имеет все более точное представление о том, где эта цель находится.
Все это дает нам маршрутную таблицу логарифмического размера при фиксированном stretch (допустимом удлинении маршрута). Например, при stretch=1,1 на расстоянии 10000 км мы можем работать с агрегатами размером до 4000 км - то есть, по сути, помнить только направление до соответствующего IX.
в окрестности 100 км
В такой окрестности расстояние имеет второстепенное значение - важней топология сети, количество хопов, характеристики устройств. На иерархическую маршрутизацию в окрестности 100 км рассчитывать наивно. Маршрутизация по Дейкстре требует O(N) - если, конечно, не провернуть тот самый трюк с областями. Но мы от этого пытались уйти.
Жизнь станет проще, если рассматривать окрестность не как случайный/обычный/простой/любой граф, а как граф со scale-free топологией. Данная топология характеризуется степенным (k-?) распределением степеней вершин, то есть мало вершин с большой степенью (количеством связей) и много - с малой. Вершины с большой степенью называются хабы. Такая топология много где встречается - в социальных связях, половых контактах, связности аэропортов, графе ссылок WWW, связности автономных систем и отдельных маршрутизаторов. Хотя есть модели с большим количеством измерений, например HOT, которые претендуют на более точное описание топологии Сети, но здесь достаточно и этой.
Для решения задачи о кратчайших путях и имя и маршрутная таблица должны быть сублинейны, ориентировочно имя размера O(N0.2) и таблица размера O(N0.5). Принимая количество рутеров в окрестности 100 км за 1 миллион, это ~10 и 1000 соответственно.
устойчивость
Высказываю на правах гипотезы. Если замеры происходят на порядок чаще, чем изменения и изменения происходят постепенно, то система может прийти к "рыночному равновесию".
То есть если у нас два линка, RTT 100ms и 102ms, мы шлем 60% через один и 40% через другой. Один линк начинает проседать (пошли дропы) - перекладываем по 5% на другой, причем временной шаг перекладывания, повторяюсь, в 10 раз больше шага замера. Вопрос во временном масштабе. Какие (микро)колебания игнорировать, а за какими (макро)колебаниями следовать. Например, изменения паттернов трафика в зависимости от времени дня/выходных/праздников - это то, к чему нужно адаптироваться. А кратковременные всплески не должны существенно повлиять на маршрутизацию (трафик имеет фрактальную, микроосциллированную природу).
последствия
Задача сети - передавать данные быстро, дешево и без сбоев. Описанный подход к маршрутизации позволит выполнить эту задачу лучше.
самонастройка
Устройства могут сами себя настраивать, а конструкция обладает избыточностью. Как пример следствия, устройство может само "попробовать" новый аплинк и либо оставить его, либо убрать. Общая идея: монтер проложил провод - и оно работает. Также интересный эффект заключается в том, что подобная сеть сможет собраться из кусочков, как Терминатор. Сама собой. Также, поскольку список адресов можно произвольно пополнять/сокращать - появляется возможность прозрачного роуминга на уровне IP. То есть на уровне IP происходит то же, что сейчас с сотовым телефоном - устройство перемещается, и постоянно остается на связи, независимо от технологии доступа. Есть рядом хот-спот - есть видеоконференцсвязь. Есть сота - доступен голос.
Получаем полную цифровую конвергенцию :). И чтобы этого достичь с массой мелких устройств, необходима технология, работающая абсолютно без админов. Вообще. Администрирование должно сводится к следующему: горит красная лампочка - поднял, отправил в ремонт. Прислали - положил обратно :)
Успех цифровых фотоаппаратов и рост функционала сотовых телефонов - хорошие показатели того, к чему дело идет.
базовый QoS
QoS в IP-сети общего пользования разрешается непосредственным практическим образом - перебираем разные IP-адреса цели и смотрим, где eRTT меньше получается (под eRTT далее подразумевается "эффективный RTT": средний RTT за период, при этом в случае дропа время ретрансмиссии добавляется к RTT). Разные адреса соответствуют разным путям.
Аналогично может вести себя каждый промежуточный маршрутизатор: раз он замеряет eRTT до префиксов в своей маршрутной таблице - он может посылать пакеты более короткими путями. Сам. С учетом переполнения каналов (когда пинги теряться начнут). «Черезпакетица» и jitter, в худшем случае, вымениваются на задержку. По черновой прикидке, мы получаем буфер размером порядка не более всего трафика, находящегося в полете. То есть некоторый практический уровень QoS осуществим в подобной публичной сети. Если у пользователя особые запросы - то нужны и особые средства, реализовывать которые "для всех" довольно дорого.
надежность
Надежность достигается многократным дублированием на всех уровнях и через overprovisioning. Overprovisioning (прокладывание каналов избыточной на сегодня пропускной способности) и сегодня является самой простой и надежной мерой обеспечения качества связи. Учитывая, что новые технологии позволяют на порядки увеличить пропускную способность уже существующих каналов, а проложить второй провод рядом с первым - дешевле, чем первый, то так оно, по-видимому, и останется (© A.Odlyzko).
Кстати, если верить RFC3439, то основные источники ненадежности - это усложнение систем и человеческий фактор (80%). Система в нашем случае получается чрезвычайно простая (одноуровневая), а человек из процесса исключен.
Конкуренция и кооперация
Интересная особенность описываемой технологии, что при нескольких аплинках их возможности в плане покрытия и пропускной способности складываются: получается + или U, а не max, как при выборе одного ("лучшего") оператора. В частности, это позволяет побороть основное противоречие беспроводных технологий: чем выше частота, тем меньше радиус действия (и, соответственно, дороже выстроить покрытие). В нашем случае: достаточно покрыть продвинутой технологией только те участки, где она востребована. Также, не требуется многократного покрытия.
когда же?
Заметим, что в изложенной схеме используется крайне мало абсолютно оригинальных идей. Разве что использование RTT в качестве метрики при маршрутизации если и предлагалось, то не обсуждалось широко. Самоназначение адресов - DHCP, префиксы - CIDR, множественность адресов - shim6, автоматическое вычисление методом проб и ошибок похоже на определение окна в TCP и т.д. В данном подходе сделана лишь попытка все разобрать и собрать заново по-правильному (кайдзен).
В конце концов, сегодня и оборудование и провода - лишь стремительно дешевеющие продукты глубокой переработки песка. Чем популярней изделие, тем оно дешевле, и т.д. и т.п. Реально дефицитный ресурс - это люди. И если схема действует на 20% менее эффективно, но требует на 50% меньше людей - то это хорошая схема. Потому что грешно экономить песок и слабые электромагнитные импульсы за счет людей. И невыгодно.
Кто знает, может и увидим подобную, а то и лучшую сеть, еще при нашей жизни.
Виктор Грищенко
Сетевые решения. Статья была опубликована в номере 04 за 2006 год в рубрике технологии
