краткое пособие по сквозной диагностике информационной системы
продолжение. начало в «Сетевых Решениях» №8 за 2005 г.
уровень драйверов и сервисов
Под драйверами и сервисами будем понимать интеллектуальное ядро любого сетевого оборудования, обрабатывающее или передающее данные между приложением и уровнем активного оборудования.
Как-то классифицировать этот уровень сложно. Можно только грубо разделить активное сетевое оборудование на универсальные компьютеры и специализированные сетевые устройства. Для первых более характерна передача данных между уровнями, для вторых – обработка перед дальнейшей пересылкой.
Результаты сбоя работы интеллектуального ядра проявляются в виде:
- потери/искажения данных;
- замедления передачи;
- неверной обработки/передачи данных.
предварительная диагностика
Для распознавания проблем с потерей, замедлением передачи или неверной обработкой данных необходим сетевой анализатор с функциями декодирования пакетов и экспертной системой. Однако, при большом количестве компьютеров, и особенно в коммутируемых сетях, диагностирование каждого сетевого устройства может занять очень много времени. И практически невозможно будет провести таким методом диагностику, если проблемы возникают только при совместной работе многих устройств, например, перегрузка маршрутизатора. Также бывает необходимо предварительно сравнить работоспособность одинаковых устройств.
Для предварительного тестирования существует достаточно простое, свободно распространяемое, и в то же время очень эффективное средство – FTest, компании Пролан (http://www.prolan.ru/solutions/testing/ftest/index.html).
Программа FTest предназначена для диагностики локальных сетей методом нагрузочного (стрессового) тестирования.
В чем суть работы FTest? На компьютерах устанавливаются агенты, которые, используя стандартные вызовы операционной системы, читают или записывают данные в тестовых файлах на любом сервере, к которому компьютеры имеют полный доступ. Управление агентами осуществляется с любой рабочей станции, на которой устанавливается базовая программа FTest. Есть три режима работы агентов:
1. все агенты работают вместе, постепенно наращивая нагрузку;
2. агенты добавляются по очереди; нагрузка, создаваемая агентами, одинакова и не изменяется;
3. агенты запускаются и работают в одиночном режиме (калибровочный режим).
На стадии поиска установленных агентов (рис. 1) отображается информация об основных параметрах компьютеров (тип процессора, объем ОЗУ, тип сетевой карты), а также рассчитанный на базе этих и других параметров индекс производительности. В дальнейшем эти данные помогают более адекватно оценивать полученные результаты тестирования.
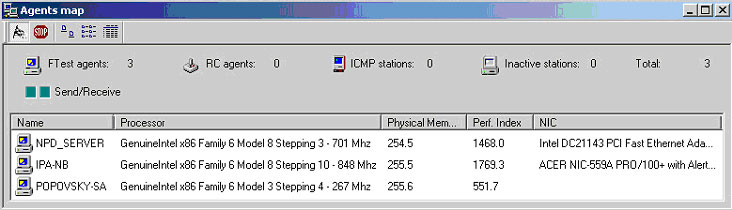
Рис. 1. Окно отображения обнаруженных агентов.
Выбор типа теста и параметров зависит от того, что мы хотим получить.
совместная работа агентов
Тест при совместной работе всех агентов предназначен, в первую очередь, для определения максимальной нагрузочной способности ИС. По результатам теста видно, как и какой максимальной нагрузочной способности достигают тестируемые станции в данной сети с определенным сервером. Тест может применяться как во время сдачи-приемки ИС, так и для периодического контроля ее работоспособности. В качестве параметров задаются:
- Minimum Offered Load (минимальная предлагаемая нагрузка) – значение нагрузки, которую предлагается создать всем станциям-агентам на первом шаге теста “FTest all stations”;
- Maximum Offered Load (максимальная предлагаемая нагрузка) – значение нагрузки, которую предлагается создать всем станциям-агентам на последнем шаге теста “FTest all stations”;
- Number of steps (число шагов) – число шагов, выполняемых всеми станциями-агентами в ходе теста;
- Duration of one step (длительность шага) – продолжительность каждого шага теста в секундах;
- File Transaction Mode (режим транзакций) – режим работы теста, при котором все файловые операции выполняются транзакциями;
- Share of read operations (%) (доля операций чтения) – процентная доля операций чтения в общем числе файловых операций, которые выполняет каждая станция-агент;
- Size of file (размер файла) – размер тестового файла на тестовом сервере;
- Size of record (размер записи) – размер записи в тестовом файле.
Если необходимо увидеть только максимальную нагрузочную способность данной ИС, можно задать минимальную и максимальные нагрузочные способности заведомо недостижимыми (например, 10000 Кбайт/с) и один этап теста.
Результаты теста отображаются в виде графика или отчета.
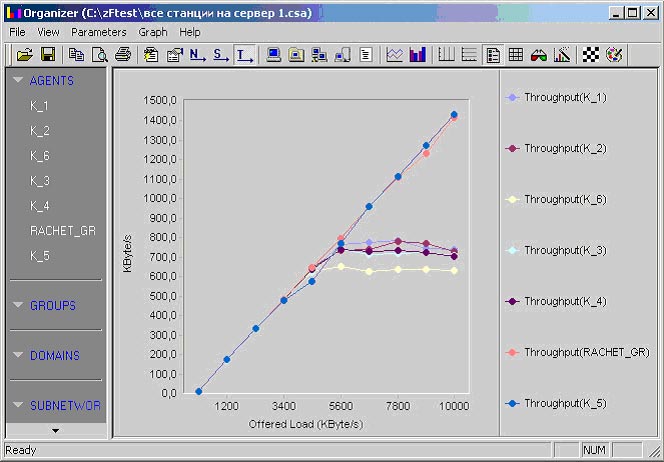
Рис. 2. Результаты теста работы семи станций с сервером.
В процессе тестов всех типов измеряются следующие параметры:
- Read Rate (скорость чтения) – характеризует среднюю скорость агента при выполнении операций чтения на каждом этапе теста. Вычисляется как размер записи (параметр Size of record (размер записи), деленный на время выполнения операции чтения. Полученные значения усредняются за время шага (параметр “Duration of one step (длительность шага). Измеряется в Кбайт/сек.
- Write Rate (скорость записи) – характеризует среднюю скорость агента при выполнении операций записи на каждом шаге теста. Вычисляется как размер записи (параметр Size of record, деленный на время выполнения операции записи. Полученные значения усредняются за время шага. Измеряется в Кбайт/сек.
- Read Throughput (пропускная способность при выполнении операций чтения) – характеризует пропускную способность, с которой каждый агент реально выполнял операции чтения на каждом шаге теста. Вычисляется как общий объем прочитанных с сервера данных, деленный на время шага. Измеряется в Кбайт/сек.
- Write Throughput (пропускная способность при выполнении операций записи) – характеризует пропускную способность, с которой каждый агент выполнял операции записи на каждом шаге теста. Вычисляется как общий объем записанных на сервер данных, деленный на время шага. Измеряется в Кбайт/сек.
- Throughput (пропускная способность) - Throughput = Read Throughput + Write Throughput.
Для большей информативности на рис 2 отображена только пропускная способность.
тест с пошаговым добавлением агентов
В отличие от совместной работы всех агентов, тест с пошаговым добавлением больше предназначен для диагностики, так как в результате теста мы не только видим суммарную нагрузочную способность ИС, но и влияние от каждой рабочей станции на ИС. Данный тест наилучшим образом подходит для выявления станций, создающих проблемы в сети.
При проведении полной диагностики ИС необходимо проводить диагностику всех уровней, начиная с нижнего, однако бывает целесообразно вначале проверить наличие ошибок в сегменте или протестировать сразу все станции и сервера с помощью FTest. К тому же при стрессовом тестировании мы сразу увидим проблемные станции, на которые нужно обратить внимание.
Калибровочный тест является дополнением теста с добавлением агентов. Проводится как для предварительного выявления возможностей станций, так и как самостоятельный тест для выявления проблемных станций.
В качестве параметров задаются время работы агента и нагрузка, создаваемая им.
На рис. 3 показан пример калибровочного теста.
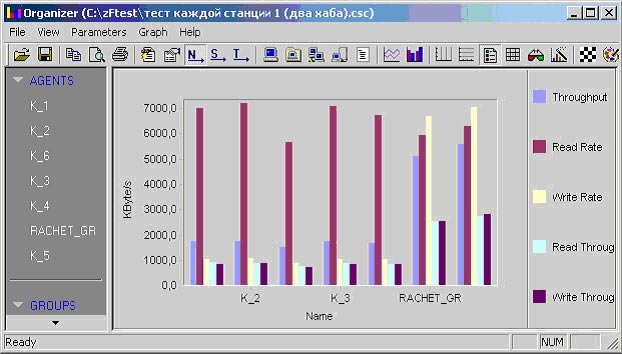
Рис. 3. Результат калибровочного теста.
диагностика потери данных
Данные при обработке в сетевом оборудовании могут пропадать в результате перегрузки или сбоя. При передаче данных с установлением соединения мы можем зафиксировать повтор транспортным или более высоким уровнем передачи пакета. В датаграммном режиме, естественно, никакого повтора не будет и отследить потери пакетов можно только с помощью статистики принимающего приложения.
Сам по себе процесс фиксирования повторов передачи прост, но практически все анализаторы выполняют его только при анализе уже захваченных пакетов. Видимо, Observer единственный, по крайней мере из программных анализаторов, проводит анализ в режиме реального времени, что является огромным преимуществом.
Экспертная система Observer (приведена на рис. 4) понимает потоки данных TCP, IPX, NetBIOS, UDP. Кроме определения повторов (Retransmission) эта система рассчитывает задержки передачи, фиксирует ответы типа Busy для IPX и нулевые окна для TCP.
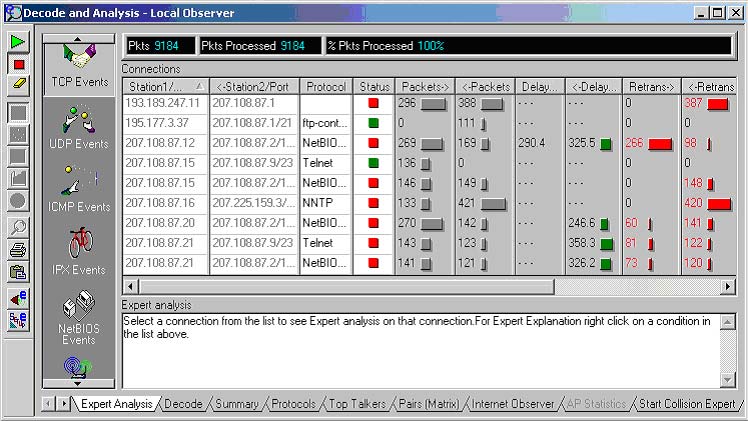
Рис. 4. Экспертная система Observer.
определение скорости передачи данных
Замедление передачи данных на уровне драйверов и сервисов ОС компьютера легче всего диагностировать с помощью FTest, тем более, что результаты сразу можно сравнить с аналогичными компьютерами. Так, на рис. 2 видно, что станции RACHET_GR и K_5 обладают гораздо большей пропускной способностью по сравнению с остальными станциями. Объясняется это очень просто и может служить прекрасным примером диагностики уровня сервиса. RACHET_GR и K_5 работают под управлением Windows 98, остальные машины работают под Windows 2000 и выполняют операции записи в транзакционном режиме. То есть записал – дождался подтверждения. Машины под Windows 98 производят запись и не ждут подтверждения, соответственно, скорость записи у них гораздо выше, что отражается на общем уровне пропускной способности.
Замедление скорости передачи при прохождении потока через сетевое устройство в основном вызывается перегрузкой устройства, и в конечном итоге вызовет потерю пакетов, что может быть зафиксировано экспертной системой Observer или с помощью SNMP-статистики устройства. В других случаях измерить скорость потока в сети можно с помощью функции Observer Pair Statistics (рис. 5). Заодно рассчитываются задержки передачи от каждой из сторон. Измерять скорость потока имеет смысл только если известно, какой она должна быть или во время настройки приложений. В крайнем случае, можно провести измерения, меняя активное оборудование и настройки и сравнивая полученные данные.
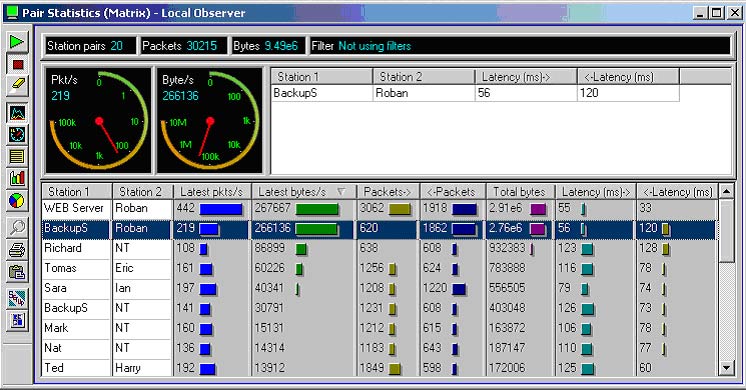
Рис. 5 Статистика потоков.
обработка и передача информации сетевыми устройствами
С одной стороны разбираться с проблемами обработки данных сетевыми устройствами легко, а с другой – тяжело. Результат неверной обработки, скорее всего, проявится в сбое, отказе обслуживания, то есть симптомы будут достаточно отчетливые. Однако для выяснения причин необходимо декодировать данные обмена и разобраться, почему сетевой сервис обработал их неверно. Для этого надо полностью понимать принципы функционирования сервиса. Декодирование – основная функция любого сетевого анализатора. Различия между анализаторами могут состоять только в следующем: выполняется ли декодирование в режиме реального времени и какое количество протоколов декодируется.
Отличным помощником может служить экспертная система WinPharaoh. В режиме реального времени она отслеживает системные сообщения сетевых устройств, например, сообщение об отказе в доступе к файлу на сервере.
Сервисы и драйверы рабочих станций, серверов, сетевого оборудования по сути являются программами, то есть неверная обработка вызывается ошибками, неверными настройками или отклонениями от стандартов в этом ПО.
пример 1 - диагностика работоспособности ноутбука
Проблемы в сети: после замены в ноутбуке беспроводного адаптера (2 Мбит/с) на сетевой адаптер (100 Мбит/с) и включения в коммутатор скорость работы в сети снизилась.
Методика и средства: диагностика проводилась с помощью экспертной системы и RMON-модуля анализатора Observer.
Результаты. На порту коммутатора, к которому был подключен ноутбук, ошибки не зафиксированы. Анализ работы ноутбука в сети показал повторы передач.
Вывод. Так как по сети нет ошибок передачи данных, остается только одно предположение – данные теряются на уровне сервиса ОС ноутбука еще до передачи в сеть. Внимательное исследование настроек сетевой карты показало, что она была настроена на одно прерывание с другим устройством ноутбука, а именно это и вызывало периодическое уничтожение данных передаваемых сетевой карте от уровня приложения.
Примечание. Стоит заметить, что в отличие от коллизии, повтором потерянных пакетов в этом случае занимался транспортный уровень, что привело к резкому падению работоспособности.
пример 2 - восстановление связи рабочей станции с Интернетом
Проблемы в сети: рабочая станция перестала получать доступ в Интернет. Никаких других проблем работы в сети не было.
Методика и средства: диагностика проводилась с помощью Observer.
Результаты. На фазе получения IP-адреса запрашиваемого ресурса Internet Explorer посылал запросы сразу на два прописанных в настройках станции DNS-сервера. Один из них являлся тестовым, внутрисетевым. Тестовый сервер тут же отвечал, что он неисправен. После этого Internet Explorer, не дожидаясь ответа от второго, сообщал, что не может установить IP-адрес.
Вывод. В данном случае мы имеем дело с явной неверной обработкой данных. После удаления из настроек тестового сервера связь с Интернетом восстановилась.
вопросы диагностики ПО
После проведения полной диагностики ИС до уровня приложения и устранения всех проблем остается выяснить только следующее: как приложение должно работать, как оно работает и от чего зависит его работа.
Важно понимать, что при диагностике ИС мы не рассматриваем внутренние проблемы приложения, то есть проблемы, связанные с его внутренним кодом. Будем считать, что приложение должно остаться таким, какое есть, и будем оценивать только внешние факторы ИС, влияющие на скорость работы приложения в ИС.
Как приложение должно работать, можно сказать только очень условно, так как работоспособность ПО зависит от работоспособности всех элементов ИС. Можно только измерить работоспособность на заведомо исправном тестовом стенде, соответствующем рекомендуемым требованиям для данного приложения, или во время сдачи-приемки. После этого можно контролировать работоспособность приложения и фиксировать замедление или ускорение его работы. Для измерений достаточно секундомера, чтобы зафиксировать время выполнения определенных операций.
Диагностика работы приложения является наиболее сложной задачей, поэтому в ней должны участвовать как минимум три специалиста с высоким уровнем квалификации: специалисты по сетям, серверам и программист (разработчик ПО). Работы являются очень трудоемкими, так как необходимо собрать, проанализировать и сделать выводы по большому количеству данных о функционировании ИС.
определение зависимости работы приложения от других элементов ИС
Для того, чтобы понять, от каких подсистем элементов ИС и на сколько зависит работоспособность приложения, нужно собрать данные о работе всех подсистем параллельно с протоколированием работы приложения. Причем для однозначных, не случайных результатов данные должны собираться достаточно продолжительное время (как минимум несколько дней), Но сразу возникает следующий вопрос – что делать с этой массой данных? Элементы ИС состоят из множества подсистем, например дисковая подсистема в сервере и процессор в маршрутизаторе. Только в одном сервере Windows 2000 с помощью административной утилиты Performance Logs and Alerts можно протоколировать несколько сотен параметров работоспособности подсистем.
Для проведения анализа данных о работоспособности ИС предназначена программа Trend Analyst компании Пролан.
Эффективность программы Trend Analyst основана на том, что с ее помощью можно привязать к единой временной шкале, наложить друг на друга и совместно обработать характеристики работы различных подсистем сети. Это могут быть характеристики работы каналов связи, серверов,
пользовательских приложений и т.п.
Особенность программы Trend Analyst заключается в том, что с ее помощью можно отображать и аналитически обрабатывать данные, которые измеряются различными средствами. Например, программой NPM Probe, входящей в состав пакета NPM Analyst и такими программами как Open View NNM компании Hewlett Packard, Observer Suite компании Network Instruments, CiscoWorks2000 компании Cisco, Spectrum компании Aprisma, и многими другими. Данными о работе приложения может являться время отклика на какую-нибудь операцию, например, бухгалтер нажимает “ввод” и получает через определенное время на экране выборку. Встроенная в программу функция может протоколировать данные о времени отклика.
Эмуляция работы приложения с файловым или SQL-сервером может выполняться агентами FTrend или NPM Probe.
Программа Trend Analyst позволяет не только объединить в единой базе данных разнородную информацию, но и провести ее вероятностный, корреляционный и регрессионный анализ.
Еще одним важным свойством Trend Analyst является возможность обработки данных, выраженных не только в процентном соотношении, но и в численном. Мы можем не знать и не узнать, сколько прерываний в секунду на сервере нормально для нашего приложения, а сколько много, но, увидев, что замедление работы приложения на 95% зависит от этого параметра – будем знать, где потенциальный источник проблем.
вероятностный анализ
Функция вероятностного анализа позволяет обрабатывать любые характеристики, которые содержатся в базе данных программы Trend Analyst .По каждой характеристике с ее помощью можно вычислить: минимальное значение за заданный интервал времени, максимальное значение, среднее значение, среднеквадратическое отклонение от среднего значения, а также строить выборочную плотность вероятности (гистограмму). Выборочная плотность вероятности позволяет определить, какие значения и с какой вероятностью принимала выбранная характеристика за заданный интервал времени. Перед выполнением вероятностного анализа можно произвести предварительный отбор данных, по которым будут формироваться вероятностные оценки. При отборе задаются: дата начала и дата окончания анализируемого интервала времени, дни недели и время суток, по которым должны выполняться обработка данных. Это позволяет исключить из рассмотрения периоды времени, когда сеть не эксплуатировались.
Пример вероятностного анализа одной из характеристик работы сети (в данном случае – скорости выполнения операций чтения; единица измерения – КБайт/с), приведен на рис. 6.
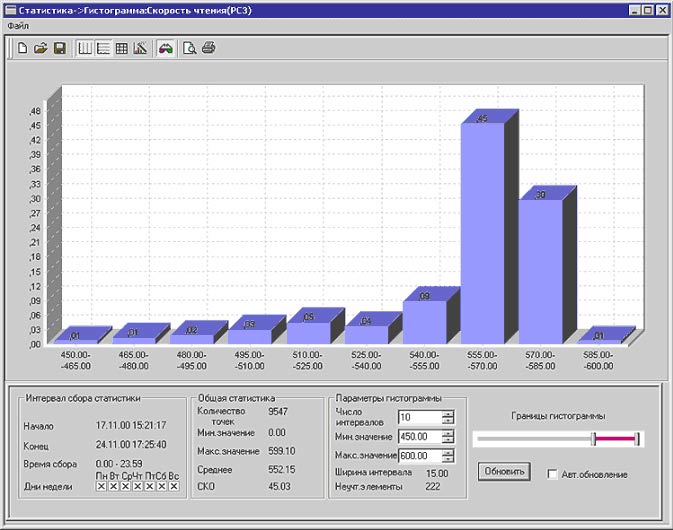
Рис. 6. Пример вероятностного анализа.
корреляционный анализ
Корреляционный анализ позволяет в процентном отношении показать, насколько зависит работа интересующей нас подсистемы от любой другой. Т.е. в результате анализа мы видим, что, например, время формирования отчета бухгалтерским приложением зависит на 95% от утилизации дисковой подсистемы сервера и на 40% от утилизации процессора рабочей станции.
Программа Trend Analyst позволяет вычислять два типа корреляционных отношений: парные и множественные. Парное корреляционное отношение – это отношение функции к одному аргументу. Множественное корреляционное отношение – это отношение некоторой функции к двум и более аргументам. Множественный корреляционный анализ проводится в том случае, если предполагается, что интересующая нас подсистема может зависеть только от нескольких подсистем сразу. Например, замедление работы приложения может быть связано с перегрузкой коммутатора, то еть функция скорости работы приложения будет сильно зависеть от одновременной загрузки всех портов коммутатора и слабо – от загрузки одного порта.
Результаты вычислений парных корреляционных отношений оформляются в виде таблицы. В каждой клетке таблицы выводится корреляционное отношение между характеристикой строки и столбца. Кроме этого, корреляционное отношение кодируется цветом. Наибольшему значению корреляционного отношения соответствует красный цвет клетки, наименьшему – белый цвет. Примерная таблица с проведенным корреляционным анализом приведена на рис. 7.
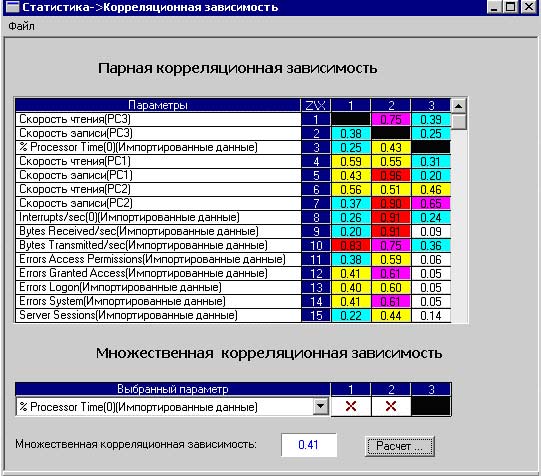
Рис. 7. Корреляционная таблица.
регрессионный анализ
Если в процессе корреляционного анализа будет установлена высокая степень зависимости подсистемами, желательно установить, каков вид этой зависимости. Например, если в процессе корреляционного анализа было установлено, что скорость работы сети в наибольшей степени зависит от доли широковещательных пакетов, необходимо построить график этой зависимости. Такой график поможет правильно установить критичную долю широковещательных пакетов. Такими же характеристиками, влияющими на работу сети, могут быть: число ошибок передачи данных, утилизация процессора сервера, утилизация канала связи и т.п.
Важно отметить, что регрессионный анализ позволяет оценить пороговые значения характеристик работы подсистем, критичные именно для
диагностируемой ИС. Эти пороговые значения, в дальнейшем, могут задаваться в средствах мониторинга для выдачи сигналов тревоги. Например, в пакетах Observer, MS Performance Monitor 2000, Novell ManageWise, HP Open View NNM и многих других. Таким образом, регрессионный анализ существенно увеличивает эффективность использования средств сетевого управления.
Пример работы функции регрессионного анализа пакета Trend Analyst приведен на рис 8 (разрыв в графике обозначает отсутствие данных в точке разрыва).
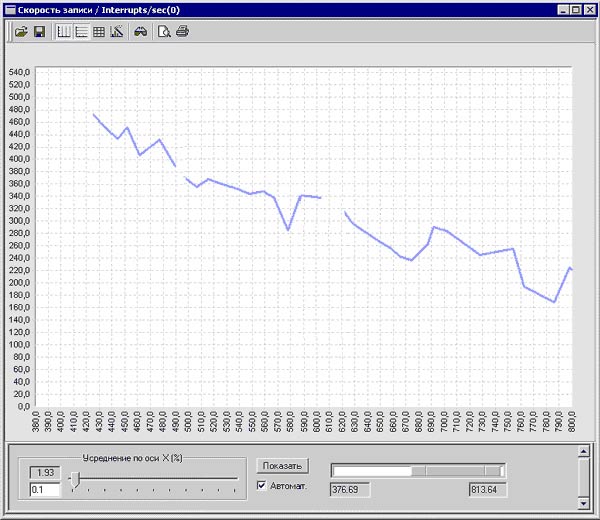
Рис 8. Пример работы функции регрессионного анализа.
пример 1 - диагностика работы базы данных
Цель: тестирование проводилось для: выявления факторов ИС, влияющих на работоспособность базы данных; определения количества пользователей поддерживаемых данной базой данных без существенного замедления их работы.
Методика тестирования и средства. В течение недели проводилось одновременное тестирование центрального коммутирующего маршрутизатора Cisco Catalyst 6509, сервера базы данных Oracle (ОС Windows Server 2000) и SQL-приложения.
Тестирование проводилось круглосуточно при нормальной работе пользователей с базой данных и заключалось в:
- анализе работы тестового SQL-приложения с помощью средства пакета диагностики NPM Analyst, компании ProLAN;
- сборе данных о работе сервера выдаваемых системой Performance Logs and Alerts с помощью NPM Analyst;
- сборе данных о работе центрального коммутирующего маршрутизатора Cisco Catalyst 6509 с помощью программного анализатора Observer v.9 компании NetworkInstruments.
Визуальный анализ состояния компьютерной сети: структура существующей информационной кабельной системы соответствует рекомендациям
международного стандарта ISO 11801 «Информационные технологии. Структурированная кабельная система для помещений заказчиков».
Результаты анализа работы Cisco Catalyst 6509 и порта сервера. Утилизация портов коммутатора за время тестирования находилась в пределах 5%, при редких пиках на некоторых портах достигала 10-20%.
Утилизация порта коммутатора, к которому подключен сервер базы данных, за время тестирования находилась в пределах 1% (что составляет менее 10 Мбит/с), при редких пиках достигала 3%.
За время тестирования ошибок на портах коммутатора не зафиксировано.
В течение каждого рабочего дня при работе с сервером фиксировалось не более 10 активных пользователей, у которых обмен данными с сервером за день составлял более 1 мегабайта.
Средняя скорость передачи данных для одного потока находилась в пределах 300 Кбайт/с, в пиках достигала 600 Кбайт/с, что соответствует 1% утилизации канала (менее 10 Мбит/с).
Результаты анализа работы сервера и корреляция с работой тестового SQL-приложения. Корреляция работы тестового SQL-приложения с данными о работе сервера показывает, что скорость выполнения тестового SQL-приложения зависела в основном от работы дисковой подсистемы (89%. Время выполнения SQL-операции находилось в промежутке от 6 до 20 сек.
Загрузка дисковой подсистемы часто достигала 100% и в наибольшей степени коррелировала с выполнением тестового SQL-приложения (89%). Загрузка процессора практически никогда не опускалась ниже 50%, даже при отсутствии работы пользователей с базой данных, что, однако, не может быть вызвано выполнением тестового приложения и сбором данных из системы Performance Logs and Alerts, так как иногда загрузка падала ниже 10% при выполнявшемся тестировании.
Загрузка процессора практически никогда не достигала 100% и слабо коррелировала с выполнением тестового SQL приложения (45%).
Количество одновременных подключений к базе данных не превышало 10 (данные по количеству подключений на графике выведены с множителем - 10, для наибольшей информативности).
Выводы. Сетевые подсистемы сервера и коммутатора не загружены и имеют большой запас производительности.
В первую очередь на работоспособность сервера базы данных влияет дисковая подсистема, причем время выполнения тестового SQL-приложения увеличивалось в 3 раза и больше.
Замечания и рекомендации. Необходимо оптимизировать работу базы данных с дисковой подсистемой или модернизировать дисковую подсистему. Необходимо выяснить – что вызывало постоянную загрузку процессора до 50%.
Сергей Поповский, z_7@mail.ru.
уровень драйверов и сервисов
Под драйверами и сервисами будем понимать интеллектуальное ядро любого сетевого оборудования, обрабатывающее или передающее данные между приложением и уровнем активного оборудования.
Как-то классифицировать этот уровень сложно. Можно только грубо разделить активное сетевое оборудование на универсальные компьютеры и специализированные сетевые устройства. Для первых более характерна передача данных между уровнями, для вторых – обработка перед дальнейшей пересылкой.
Результаты сбоя работы интеллектуального ядра проявляются в виде:
- потери/искажения данных;
- замедления передачи;
- неверной обработки/передачи данных.
предварительная диагностика
Для распознавания проблем с потерей, замедлением передачи или неверной обработкой данных необходим сетевой анализатор с функциями декодирования пакетов и экспертной системой. Однако, при большом количестве компьютеров, и особенно в коммутируемых сетях, диагностирование каждого сетевого устройства может занять очень много времени. И практически невозможно будет провести таким методом диагностику, если проблемы возникают только при совместной работе многих устройств, например, перегрузка маршрутизатора. Также бывает необходимо предварительно сравнить работоспособность одинаковых устройств.
Для предварительного тестирования существует достаточно простое, свободно распространяемое, и в то же время очень эффективное средство – FTest, компании Пролан (http://www.prolan.ru/solutions/testing/ftest/index.html).
Программа FTest предназначена для диагностики локальных сетей методом нагрузочного (стрессового) тестирования.
В чем суть работы FTest? На компьютерах устанавливаются агенты, которые, используя стандартные вызовы операционной системы, читают или записывают данные в тестовых файлах на любом сервере, к которому компьютеры имеют полный доступ. Управление агентами осуществляется с любой рабочей станции, на которой устанавливается базовая программа FTest. Есть три режима работы агентов:
1. все агенты работают вместе, постепенно наращивая нагрузку;
2. агенты добавляются по очереди; нагрузка, создаваемая агентами, одинакова и не изменяется;
3. агенты запускаются и работают в одиночном режиме (калибровочный режим).
На стадии поиска установленных агентов (рис. 1) отображается информация об основных параметрах компьютеров (тип процессора, объем ОЗУ, тип сетевой карты), а также рассчитанный на базе этих и других параметров индекс производительности. В дальнейшем эти данные помогают более адекватно оценивать полученные результаты тестирования.
Рис. 1. Окно отображения обнаруженных агентов.
Выбор типа теста и параметров зависит от того, что мы хотим получить.
совместная работа агентов
Тест при совместной работе всех агентов предназначен, в первую очередь, для определения максимальной нагрузочной способности ИС. По результатам теста видно, как и какой максимальной нагрузочной способности достигают тестируемые станции в данной сети с определенным сервером. Тест может применяться как во время сдачи-приемки ИС, так и для периодического контроля ее работоспособности. В качестве параметров задаются:
- Minimum Offered Load (минимальная предлагаемая нагрузка) – значение нагрузки, которую предлагается создать всем станциям-агентам на первом шаге теста “FTest all stations”;
- Maximum Offered Load (максимальная предлагаемая нагрузка) – значение нагрузки, которую предлагается создать всем станциям-агентам на последнем шаге теста “FTest all stations”;
- Number of steps (число шагов) – число шагов, выполняемых всеми станциями-агентами в ходе теста;
- Duration of one step (длительность шага) – продолжительность каждого шага теста в секундах;
- File Transaction Mode (режим транзакций) – режим работы теста, при котором все файловые операции выполняются транзакциями;
- Share of read operations (%) (доля операций чтения) – процентная доля операций чтения в общем числе файловых операций, которые выполняет каждая станция-агент;
- Size of file (размер файла) – размер тестового файла на тестовом сервере;
- Size of record (размер записи) – размер записи в тестовом файле.
Если необходимо увидеть только максимальную нагрузочную способность данной ИС, можно задать минимальную и максимальные нагрузочные способности заведомо недостижимыми (например, 10000 Кбайт/с) и один этап теста.
Результаты теста отображаются в виде графика или отчета.
Рис. 2. Результаты теста работы семи станций с сервером.
В процессе тестов всех типов измеряются следующие параметры:
- Read Rate (скорость чтения) – характеризует среднюю скорость агента при выполнении операций чтения на каждом этапе теста. Вычисляется как размер записи (параметр Size of record (размер записи), деленный на время выполнения операции чтения. Полученные значения усредняются за время шага (параметр “Duration of one step (длительность шага). Измеряется в Кбайт/сек.
- Write Rate (скорость записи) – характеризует среднюю скорость агента при выполнении операций записи на каждом шаге теста. Вычисляется как размер записи (параметр Size of record, деленный на время выполнения операции записи. Полученные значения усредняются за время шага. Измеряется в Кбайт/сек.
- Read Throughput (пропускная способность при выполнении операций чтения) – характеризует пропускную способность, с которой каждый агент реально выполнял операции чтения на каждом шаге теста. Вычисляется как общий объем прочитанных с сервера данных, деленный на время шага. Измеряется в Кбайт/сек.
- Write Throughput (пропускная способность при выполнении операций записи) – характеризует пропускную способность, с которой каждый агент выполнял операции записи на каждом шаге теста. Вычисляется как общий объем записанных на сервер данных, деленный на время шага. Измеряется в Кбайт/сек.
- Throughput (пропускная способность) - Throughput = Read Throughput + Write Throughput.
Для большей информативности на рис 2 отображена только пропускная способность.
тест с пошаговым добавлением агентов
В отличие от совместной работы всех агентов, тест с пошаговым добавлением больше предназначен для диагностики, так как в результате теста мы не только видим суммарную нагрузочную способность ИС, но и влияние от каждой рабочей станции на ИС. Данный тест наилучшим образом подходит для выявления станций, создающих проблемы в сети.
При проведении полной диагностики ИС необходимо проводить диагностику всех уровней, начиная с нижнего, однако бывает целесообразно вначале проверить наличие ошибок в сегменте или протестировать сразу все станции и сервера с помощью FTest. К тому же при стрессовом тестировании мы сразу увидим проблемные станции, на которые нужно обратить внимание.
Калибровочный тест является дополнением теста с добавлением агентов. Проводится как для предварительного выявления возможностей станций, так и как самостоятельный тест для выявления проблемных станций.
В качестве параметров задаются время работы агента и нагрузка, создаваемая им.
На рис. 3 показан пример калибровочного теста.
Рис. 3. Результат калибровочного теста.
диагностика потери данных
Данные при обработке в сетевом оборудовании могут пропадать в результате перегрузки или сбоя. При передаче данных с установлением соединения мы можем зафиксировать повтор транспортным или более высоким уровнем передачи пакета. В датаграммном режиме, естественно, никакого повтора не будет и отследить потери пакетов можно только с помощью статистики принимающего приложения.
Сам по себе процесс фиксирования повторов передачи прост, но практически все анализаторы выполняют его только при анализе уже захваченных пакетов. Видимо, Observer единственный, по крайней мере из программных анализаторов, проводит анализ в режиме реального времени, что является огромным преимуществом.
Экспертная система Observer (приведена на рис. 4) понимает потоки данных TCP, IPX, NetBIOS, UDP. Кроме определения повторов (Retransmission) эта система рассчитывает задержки передачи, фиксирует ответы типа Busy для IPX и нулевые окна для TCP.
Рис. 4. Экспертная система Observer.
определение скорости передачи данных
Замедление передачи данных на уровне драйверов и сервисов ОС компьютера легче всего диагностировать с помощью FTest, тем более, что результаты сразу можно сравнить с аналогичными компьютерами. Так, на рис. 2 видно, что станции RACHET_GR и K_5 обладают гораздо большей пропускной способностью по сравнению с остальными станциями. Объясняется это очень просто и может служить прекрасным примером диагностики уровня сервиса. RACHET_GR и K_5 работают под управлением Windows 98, остальные машины работают под Windows 2000 и выполняют операции записи в транзакционном режиме. То есть записал – дождался подтверждения. Машины под Windows 98 производят запись и не ждут подтверждения, соответственно, скорость записи у них гораздо выше, что отражается на общем уровне пропускной способности.
Замедление скорости передачи при прохождении потока через сетевое устройство в основном вызывается перегрузкой устройства, и в конечном итоге вызовет потерю пакетов, что может быть зафиксировано экспертной системой Observer или с помощью SNMP-статистики устройства. В других случаях измерить скорость потока в сети можно с помощью функции Observer Pair Statistics (рис. 5). Заодно рассчитываются задержки передачи от каждой из сторон. Измерять скорость потока имеет смысл только если известно, какой она должна быть или во время настройки приложений. В крайнем случае, можно провести измерения, меняя активное оборудование и настройки и сравнивая полученные данные.
Рис. 5 Статистика потоков.
обработка и передача информации сетевыми устройствами
С одной стороны разбираться с проблемами обработки данных сетевыми устройствами легко, а с другой – тяжело. Результат неверной обработки, скорее всего, проявится в сбое, отказе обслуживания, то есть симптомы будут достаточно отчетливые. Однако для выяснения причин необходимо декодировать данные обмена и разобраться, почему сетевой сервис обработал их неверно. Для этого надо полностью понимать принципы функционирования сервиса. Декодирование – основная функция любого сетевого анализатора. Различия между анализаторами могут состоять только в следующем: выполняется ли декодирование в режиме реального времени и какое количество протоколов декодируется.
Отличным помощником может служить экспертная система WinPharaoh. В режиме реального времени она отслеживает системные сообщения сетевых устройств, например, сообщение об отказе в доступе к файлу на сервере.
Сервисы и драйверы рабочих станций, серверов, сетевого оборудования по сути являются программами, то есть неверная обработка вызывается ошибками, неверными настройками или отклонениями от стандартов в этом ПО.
пример 1 - диагностика работоспособности ноутбука
Проблемы в сети: после замены в ноутбуке беспроводного адаптера (2 Мбит/с) на сетевой адаптер (100 Мбит/с) и включения в коммутатор скорость работы в сети снизилась.
Методика и средства: диагностика проводилась с помощью экспертной системы и RMON-модуля анализатора Observer.
Результаты. На порту коммутатора, к которому был подключен ноутбук, ошибки не зафиксированы. Анализ работы ноутбука в сети показал повторы передач.
Вывод. Так как по сети нет ошибок передачи данных, остается только одно предположение – данные теряются на уровне сервиса ОС ноутбука еще до передачи в сеть. Внимательное исследование настроек сетевой карты показало, что она была настроена на одно прерывание с другим устройством ноутбука, а именно это и вызывало периодическое уничтожение данных передаваемых сетевой карте от уровня приложения.
Примечание. Стоит заметить, что в отличие от коллизии, повтором потерянных пакетов в этом случае занимался транспортный уровень, что привело к резкому падению работоспособности.
пример 2 - восстановление связи рабочей станции с Интернетом
Проблемы в сети: рабочая станция перестала получать доступ в Интернет. Никаких других проблем работы в сети не было.
Методика и средства: диагностика проводилась с помощью Observer.
Результаты. На фазе получения IP-адреса запрашиваемого ресурса Internet Explorer посылал запросы сразу на два прописанных в настройках станции DNS-сервера. Один из них являлся тестовым, внутрисетевым. Тестовый сервер тут же отвечал, что он неисправен. После этого Internet Explorer, не дожидаясь ответа от второго, сообщал, что не может установить IP-адрес.
Вывод. В данном случае мы имеем дело с явной неверной обработкой данных. После удаления из настроек тестового сервера связь с Интернетом восстановилась.
вопросы диагностики ПО
После проведения полной диагностики ИС до уровня приложения и устранения всех проблем остается выяснить только следующее: как приложение должно работать, как оно работает и от чего зависит его работа.
Важно понимать, что при диагностике ИС мы не рассматриваем внутренние проблемы приложения, то есть проблемы, связанные с его внутренним кодом. Будем считать, что приложение должно остаться таким, какое есть, и будем оценивать только внешние факторы ИС, влияющие на скорость работы приложения в ИС.
Как приложение должно работать, можно сказать только очень условно, так как работоспособность ПО зависит от работоспособности всех элементов ИС. Можно только измерить работоспособность на заведомо исправном тестовом стенде, соответствующем рекомендуемым требованиям для данного приложения, или во время сдачи-приемки. После этого можно контролировать работоспособность приложения и фиксировать замедление или ускорение его работы. Для измерений достаточно секундомера, чтобы зафиксировать время выполнения определенных операций.
Диагностика работы приложения является наиболее сложной задачей, поэтому в ней должны участвовать как минимум три специалиста с высоким уровнем квалификации: специалисты по сетям, серверам и программист (разработчик ПО). Работы являются очень трудоемкими, так как необходимо собрать, проанализировать и сделать выводы по большому количеству данных о функционировании ИС.
определение зависимости работы приложения от других элементов ИС
Для того, чтобы понять, от каких подсистем элементов ИС и на сколько зависит работоспособность приложения, нужно собрать данные о работе всех подсистем параллельно с протоколированием работы приложения. Причем для однозначных, не случайных результатов данные должны собираться достаточно продолжительное время (как минимум несколько дней), Но сразу возникает следующий вопрос – что делать с этой массой данных? Элементы ИС состоят из множества подсистем, например дисковая подсистема в сервере и процессор в маршрутизаторе. Только в одном сервере Windows 2000 с помощью административной утилиты Performance Logs and Alerts можно протоколировать несколько сотен параметров работоспособности подсистем.
Для проведения анализа данных о работоспособности ИС предназначена программа Trend Analyst компании Пролан.
Эффективность программы Trend Analyst основана на том, что с ее помощью можно привязать к единой временной шкале, наложить друг на друга и совместно обработать характеристики работы различных подсистем сети. Это могут быть характеристики работы каналов связи, серверов,
пользовательских приложений и т.п.
Особенность программы Trend Analyst заключается в том, что с ее помощью можно отображать и аналитически обрабатывать данные, которые измеряются различными средствами. Например, программой NPM Probe, входящей в состав пакета NPM Analyst и такими программами как Open View NNM компании Hewlett Packard, Observer Suite компании Network Instruments, CiscoWorks2000 компании Cisco, Spectrum компании Aprisma, и многими другими. Данными о работе приложения может являться время отклика на какую-нибудь операцию, например, бухгалтер нажимает “ввод” и получает через определенное время на экране выборку. Встроенная в программу функция может протоколировать данные о времени отклика.
Эмуляция работы приложения с файловым или SQL-сервером может выполняться агентами FTrend или NPM Probe.
Программа Trend Analyst позволяет не только объединить в единой базе данных разнородную информацию, но и провести ее вероятностный, корреляционный и регрессионный анализ.
Еще одним важным свойством Trend Analyst является возможность обработки данных, выраженных не только в процентном соотношении, но и в численном. Мы можем не знать и не узнать, сколько прерываний в секунду на сервере нормально для нашего приложения, а сколько много, но, увидев, что замедление работы приложения на 95% зависит от этого параметра – будем знать, где потенциальный источник проблем.
вероятностный анализ
Функция вероятностного анализа позволяет обрабатывать любые характеристики, которые содержатся в базе данных программы Trend Analyst .По каждой характеристике с ее помощью можно вычислить: минимальное значение за заданный интервал времени, максимальное значение, среднее значение, среднеквадратическое отклонение от среднего значения, а также строить выборочную плотность вероятности (гистограмму). Выборочная плотность вероятности позволяет определить, какие значения и с какой вероятностью принимала выбранная характеристика за заданный интервал времени. Перед выполнением вероятностного анализа можно произвести предварительный отбор данных, по которым будут формироваться вероятностные оценки. При отборе задаются: дата начала и дата окончания анализируемого интервала времени, дни недели и время суток, по которым должны выполняться обработка данных. Это позволяет исключить из рассмотрения периоды времени, когда сеть не эксплуатировались.
Пример вероятностного анализа одной из характеристик работы сети (в данном случае – скорости выполнения операций чтения; единица измерения – КБайт/с), приведен на рис. 6.
Рис. 6. Пример вероятностного анализа.
корреляционный анализ
Корреляционный анализ позволяет в процентном отношении показать, насколько зависит работа интересующей нас подсистемы от любой другой. Т.е. в результате анализа мы видим, что, например, время формирования отчета бухгалтерским приложением зависит на 95% от утилизации дисковой подсистемы сервера и на 40% от утилизации процессора рабочей станции.
Программа Trend Analyst позволяет вычислять два типа корреляционных отношений: парные и множественные. Парное корреляционное отношение – это отношение функции к одному аргументу. Множественное корреляционное отношение – это отношение некоторой функции к двум и более аргументам. Множественный корреляционный анализ проводится в том случае, если предполагается, что интересующая нас подсистема может зависеть только от нескольких подсистем сразу. Например, замедление работы приложения может быть связано с перегрузкой коммутатора, то еть функция скорости работы приложения будет сильно зависеть от одновременной загрузки всех портов коммутатора и слабо – от загрузки одного порта.
Результаты вычислений парных корреляционных отношений оформляются в виде таблицы. В каждой клетке таблицы выводится корреляционное отношение между характеристикой строки и столбца. Кроме этого, корреляционное отношение кодируется цветом. Наибольшему значению корреляционного отношения соответствует красный цвет клетки, наименьшему – белый цвет. Примерная таблица с проведенным корреляционным анализом приведена на рис. 7.
Рис. 7. Корреляционная таблица.
регрессионный анализ
Если в процессе корреляционного анализа будет установлена высокая степень зависимости подсистемами, желательно установить, каков вид этой зависимости. Например, если в процессе корреляционного анализа было установлено, что скорость работы сети в наибольшей степени зависит от доли широковещательных пакетов, необходимо построить график этой зависимости. Такой график поможет правильно установить критичную долю широковещательных пакетов. Такими же характеристиками, влияющими на работу сети, могут быть: число ошибок передачи данных, утилизация процессора сервера, утилизация канала связи и т.п.
Важно отметить, что регрессионный анализ позволяет оценить пороговые значения характеристик работы подсистем, критичные именно для
диагностируемой ИС. Эти пороговые значения, в дальнейшем, могут задаваться в средствах мониторинга для выдачи сигналов тревоги. Например, в пакетах Observer, MS Performance Monitor 2000, Novell ManageWise, HP Open View NNM и многих других. Таким образом, регрессионный анализ существенно увеличивает эффективность использования средств сетевого управления.
Пример работы функции регрессионного анализа пакета Trend Analyst приведен на рис 8 (разрыв в графике обозначает отсутствие данных в точке разрыва).
Рис 8. Пример работы функции регрессионного анализа.
пример 1 - диагностика работы базы данных
Цель: тестирование проводилось для: выявления факторов ИС, влияющих на работоспособность базы данных; определения количества пользователей поддерживаемых данной базой данных без существенного замедления их работы.
Методика тестирования и средства. В течение недели проводилось одновременное тестирование центрального коммутирующего маршрутизатора Cisco Catalyst 6509, сервера базы данных Oracle (ОС Windows Server 2000) и SQL-приложения.
Тестирование проводилось круглосуточно при нормальной работе пользователей с базой данных и заключалось в:
- анализе работы тестового SQL-приложения с помощью средства пакета диагностики NPM Analyst, компании ProLAN;
- сборе данных о работе сервера выдаваемых системой Performance Logs and Alerts с помощью NPM Analyst;
- сборе данных о работе центрального коммутирующего маршрутизатора Cisco Catalyst 6509 с помощью программного анализатора Observer v.9 компании NetworkInstruments.
Визуальный анализ состояния компьютерной сети: структура существующей информационной кабельной системы соответствует рекомендациям
международного стандарта ISO 11801 «Информационные технологии. Структурированная кабельная система для помещений заказчиков».
Результаты анализа работы Cisco Catalyst 6509 и порта сервера. Утилизация портов коммутатора за время тестирования находилась в пределах 5%, при редких пиках на некоторых портах достигала 10-20%.
Утилизация порта коммутатора, к которому подключен сервер базы данных, за время тестирования находилась в пределах 1% (что составляет менее 10 Мбит/с), при редких пиках достигала 3%.
За время тестирования ошибок на портах коммутатора не зафиксировано.
В течение каждого рабочего дня при работе с сервером фиксировалось не более 10 активных пользователей, у которых обмен данными с сервером за день составлял более 1 мегабайта.
Средняя скорость передачи данных для одного потока находилась в пределах 300 Кбайт/с, в пиках достигала 600 Кбайт/с, что соответствует 1% утилизации канала (менее 10 Мбит/с).
Результаты анализа работы сервера и корреляция с работой тестового SQL-приложения. Корреляция работы тестового SQL-приложения с данными о работе сервера показывает, что скорость выполнения тестового SQL-приложения зависела в основном от работы дисковой подсистемы (89%. Время выполнения SQL-операции находилось в промежутке от 6 до 20 сек.
Загрузка дисковой подсистемы часто достигала 100% и в наибольшей степени коррелировала с выполнением тестового SQL-приложения (89%). Загрузка процессора практически никогда не опускалась ниже 50%, даже при отсутствии работы пользователей с базой данных, что, однако, не может быть вызвано выполнением тестового приложения и сбором данных из системы Performance Logs and Alerts, так как иногда загрузка падала ниже 10% при выполнявшемся тестировании.
Загрузка процессора практически никогда не достигала 100% и слабо коррелировала с выполнением тестового SQL приложения (45%).
Количество одновременных подключений к базе данных не превышало 10 (данные по количеству подключений на графике выведены с множителем - 10, для наибольшей информативности).
Выводы. Сетевые подсистемы сервера и коммутатора не загружены и имеют большой запас производительности.
В первую очередь на работоспособность сервера базы данных влияет дисковая подсистема, причем время выполнения тестового SQL-приложения увеличивалось в 3 раза и больше.
Замечания и рекомендации. Необходимо оптимизировать работу базы данных с дисковой подсистемой или модернизировать дисковую подсистему. Необходимо выяснить – что вызывало постоянную загрузку процессора до 50%.
Сергей Поповский, z_7@mail.ru.
Сетевые решения. Статья была опубликована в номере 09 за 2005 год в рубрике лабораторная работа
