разработка веб-страниц с помощью google gears. Часть 1
В последний год становится все более яркой тенденция сращивать веб-приложения с традиционными настольными версиями программ. Конечно, это уже давно не новость. Если углубиться в историю, то первые решения такого рода появились еще во времена первого бума и последующего краха дот-комов. Но именно сейчас начинает меняться фокус приложения сил.
Смотрите: раньше в качестве цели декларировалась доставка в настольную программу содержимого из internet (в простейшем случае поиск по справке выполнялся не только в файлах на жестком диске компьютера, но в internet). Сейчас мы говорим: а давайте расширим возможности веб-приложения, дадим ему возможность выполняться на машине компьютера без подключения к сети. Дадим возможность хранить часть информации локально, а часть — в сети. Давайте доставим по сети на машину клиента ядро программы (не просто сайт с парой страниц, а сложное приложение наподобие google docs). Затем пользователь может работать в “сайтопрограмме”, а на стадии сохранения информации или для получения дополнительной функциональности подключиться к сети. Что вы говорите? Слышали это в рекламе пару лет назад? Не ново? Согласен, сейчас мир IT устроен так, что революции произойти не может, части технически продвинутых “гиков” будут мешать консервативно настроенные пользователи (коих большинство). Эти “консерваторы” будут сопротивляться: ведь они совершенно не понимают, зачем им нужно устанавливать у себя на компьютере какие-то непонятные и потенциально опасные плагины, зачем им нужно менять столь привычный internet explorer на новомодный firefox. Людям не нужна “классная” технология сама по себе, им нужны удобные инструменты для работы — такие, чтобы ими можно было начать пользоваться без дополнительных затрат времени. К чему я веду этот разговор? К тому, что нужно заниматься популяризацией технических идей, нужно, чтобы как можно больше людей занимались разработкой полезных и нужных веб-приложений. Я очень уважаю компании adobe, microsoft, sun. Мне очень нравятся те продукты, которые они представили на рынок: air (в девичестве apollo), silverlight, javafx. Но все дело в том, что разработка с помощью их требует изрядных сил и познаний. Да, продукты получаются качественные (при отсутствии кривизны рук у разработчиков), но и слишком дорогие. Мне нравится политика google: они не создают общие инструменты для веб-разработки, коих на рынке и так уже переизбыток — они создают сервисы (Google AJAX Feed API, Google AJAX Search API, Google Chart API, Google Checkout API). Затем они предоставляют для всех желающих api, учебную документацию, рассказывающую, “как программировать на этой штуке”, а потом проект начинает развиваться за счет приложения сил многих миллионов пользователей сети. Не правда ли, хороший лозунг: “заставь на себя работать весь мир”? Об одном из таких сервисов — google gears — я хочу сегодня рассказать. На самом деле я немного лукавлю: Google gears — не просто веб-сервис (вроде той классной javascript-библиотеки, загружающей вам на сайт список новостей). Google gears — нечто большее — это плагин (о ужас! его нужно устанавливать) для вашего браузера. В настоящее время поддерживаются internet explorer, firefox, safari (фанаты opera, вам придется обождать). Впервые я столкнулся с gears весной 2007 г., когда на странице моей подписки на rss-новости (google reader) появилась функция offline-просмотра новостей. Тогда меня это не впечатлило: как раз таки рынок rss- ридеров достаточно плотно заселен. Сам я пользуюсь встроенной в opera поддержкой чтения rss-лент и не особенно думаю о ее смене. Тогда я не заметил за лесом деревьев. Вернувшись к этой теме спустя время, я задумался над тем, как реализована эта функциональность, и можно ли ее использовать в своих проектах? Оказалось, что использование google gears позволяет строить сайты нового типа с изменениями и улучшениями не в “рюшечках”, а в методике показа информации. Предположим, что вы хотите сделать новостной сайт или сайт, публикующий статьи и учебные материалы. Естественно, важен не только сам материал, но и его обсуждение. Часто бывает так, что люди пишут в комментариях более ценные для вас замечания, чем собственно текст статьи. Ага, давайте сделаем rss-ленту, в которой будут публиковаться все сделанные комментарии. Нет проблем — на многих продвинутых сайтах и блогах подобная функция есть. Вот только при чтении этих комментариев (ведь многие из них могут приходить спустя несколько дней или недель) удобно иметь перед глазами исходный текст статьи. Неплохо, чтобы комментарии были привязаны к определенным местам в статье — таким, как сноски, неплохо, чтобы вы имели возможность добавлять собственные комментарии, видимые не только для всех, но и для определенных групп посетителей или только для самого себя. И тут никак универсальным программами RSS-ридерами не обойтись. С другой стороны, очень неудобно периодически заходить на сайт, чтобы проверить, появились ли новые заметки по интересующей вас теме, загружая каждый раз заново все содержимое статьи (которое наверняка не поменялось). Почти все, что я описал выше, можно сделать с помощью javascript и ajax. Вот только как быть с хранением данных — тех самых личных заметок или содержимого статьи? Как быть, если вы начали писать комментарий, но не успели, т.к., например, были вынуждены уйти, но хотите придти завтра и продолжить с прерванного места? Где хранить эти данные? В какой-то еще одной программе? Неудобно? Почему так распространены всевозможные сайты-сервисы “быстрых заметок”? Вся беда в том, что в браузере нет пристойных средств для хранения пользовательской информации. Я специально отметил слово “пристойных”. Все знают о cookie — небольших кусочках информации, которые сайт может сохранить на машине пользователя — так, чтобы при последующем посещении эту информацию взять и использовать. Традиционно cookie используются для хранения небольших данных — например, это имя, под которым посетитель сайта зарегистрирован. Информация может храниться в течение некоторого времени: несколько дней или месяцев. Вот только назвать cookie “пристойным” хранилищем информации — нет, и еще раз нет. Попробуйте, например, запустить следующий js-код:
for (var i = 0; i < 1000; i++)
document.cookie = 'var_' + i + '=' + 'value_' + i + ';';
alert (document.cookie);
alert ((document.cookie).length);
Это очень простой пример: в нем я помещаю внутрь cookie множество переменных с именами “var_0”, “var_1”, … “var_999”, каждой из этих переменных я присваиваю значение “value_0”, “value_1”, …,“value_999”. После окончания цикла я вывожу значение переменной “document.cookie” и длину этой переменной. Все cookie, которые вы сохраните внутри страницы, помещаются внутрь одной служебной переменной с именем “document.cookie”. Эта переменная имеет тип данных “строка” и внутри выглядит примерно так:
fio=vasyan; expires=Mon, 07 Jan 2008 20:51:46 GMT; path=/docs/java/; domain=www.site.com; secure
Как видите, в одной строке находится множество переменных, для каждой из них указывается имя, значение переменной, срок хранения, права доступа (каталог и домен из которого данное значение cookie будет доступно). Затем информация, помещенная внутрь cookie, сохраняется в виде небольших файликов на вашем компьютере. Проблема не в том, что такой формат представления данных неудобен (благо существует множество пользовательских js- функций, упрощающих операции “положить что-нибудь в cookie”, или “изъять”, или “удалить содержимое cookie”). Проблема в том, что, если запустить данный пример кода в трех браузерах: Internet Explorer, Firefox, Opera, — мы получим различные результаты. Так, для ie внутри переменной “document.cookie” окажутся только переменные с номерами от 980 по 999, а длина выводимой строки будет равна 378 символов. Как же в этих 378 символах смогла уместиться аж тысяча пар строк каждая длиной в добрых десятка два символов? Посмотрим, что покажет opera. Вывелись переменные с 970 по 998 — уже лучше — целых 568 символов. Но все равно куда-то пропали девять десятых всех помещенных внутрь cookie переменных. А что покажет firefox? Тут результат еще забавнее: вывелись переменные в интервале от var_0 до var_48, затем пустота — и, наконец, одинокая переменная под номером 999. Длина строки “document.cookie” для “лисы” равна целых 830 символов. Увы, но браузер сохраняет не любую информацию, помещенную в cookie, а только ту, которая укладывается в лимит 4 Кб. Есть ограничения на количество файлов cookie в рамках одного домена. Так, для internet explorer эта цифра составляет 20, для firefox — 50 и для opera — 30. Это еще не все. Для internet explorer суммарный объем всех cookie должен быть не более 4 Кб, а для остальных браузеров 4 Кб — это ограничение на один файл. Кроме того, в cookie неудобно хранить сложные структуры данных. Например, вы хотите сохранить не просто пару “ключ => строковое значение”, а массив элементов или объект. В такой ситуации остается только умыть руки.
В настоящий момент очень мало кто хранит сведения, собираемые на сайте, именно внутри cookie. Обычно в cookie помещается некоторое число — код сессии (имя файла, номер записи в БД). Когда открывается веб-страница, идет обращение к http-серверу с указанием имени страницы, которую вы хотите открыть, плюс передается содержимое cookie. Затем на сервере на основании номера сессии выполняется поиск в файле или таблице БД реальной информации (той информации, которой много более, чем 4 Кб, той, которая может содержать сложные структуры данных). Естественно, не всегда следует и не всегда возможно хранить информацию на сервере. Например, при разработке крупных и часто посещаемых сайтов средства работы с сессиями переписываются фактически с нуля. Особенно ярко такая тенденция появилась с широким внедрением идей web 2.0. Веб-страницы, постоянно обращающиеся с помощью ajax к веб-серверу за информацией, способны свести с ума любую систему поддержки сессий (хранения пользовательской информации) на стороне сервера. В тех редких случаях, когда я был вынужден хранить большие данные на стороне клиента, приходилось использовать средства flash. Дело в том, что встроенные в flash методики “сохранить немножко информации на стороне клиента” гораздо либеральнее, чем стандартные средства браузера. Верить, что разработчики браузеров решат пересмотреть методику работы с cookie и добавят в браузеры новые возможности, не стоит. Тем более не стоит верить в то, что они это сделают единообразным образом и в полной мере удовлетворят потребности веб- разработчиков.
Сегодня я обещал рассказать о google gears. Сначала нужно скачать плагин для вашего браузера по следующему адресу:
http://gears.google.com/download.html. Там же вы найдете документацию и примеры, работающие с google gears.
Но прежде, чем я перейду к техническим деталям, позвольте мне напомнить в очередной раз: “серебряной пули нет”. Одной из ключевых возможностей этого плагина (далеко не единственной) является новая, абсолютно новая, модель хранения пользовательских данных на компьютере. Такого вы еще не видели! Вы знаете, что такое базы данных? Да, это те самые невероятно дорогие (или совершенно бесплатные) штуки, которые могут хранить миллионы единиц информации и мгновенно искать среди них нужную. Еще вы слышали, что для того, чтобы научиться работать с базами данных нужны долгие годы. На самом деле существует огромное множество различных баз данных (популярных, конечно, гораздо меньше). Базы данных ориентируются на различные платформы и сегменты потребителей, есть такие СУБД, что запустить их даже на мощном современном ПК — нетривиальная задача. Есть и такие СУБД, которые могут быть встроены внутрь вашего мобильника пятилетней давности. Для веб-сайтов традиционно применяют такие СУБД, как mysql, postgres. Серьезные предприятия хранят информацию в microsoft sql server, oracle, ibm db2. И есть среди этого списка такая СУБД, как sqlite. Это достаточно необычная СУБД, и многие из ее возможностей наверняка отпугнут “зубров программирования”. Тем не менее, она завоевывает известность и для поддержки в internet небольших сайтов, и для создания “портфельных приложений”. Под “портфельными приложениями” я понимаю ситуацию, когда программе нужна для работы БД, но при этом предполагается, что приложение будет переноситься на флэшке или распространяться на CD-диске. Естественно, требовать установки каких-то драйверов к БД и ее предварительной настройки перед работой просто глупо — клиенты не оценят. Еще один сегмент рынка, где властвует sqlite — всевозможные встраиваемые приложения. Для работы sqlite достаточно всего 200 Кб памяти. А если и этого вам окажется мало, то благодаря тому, что sqlite — open source, “продвинутые” программисты всегда могут “поработать напильником”. Так что, google gears — это всего лишь добавили внутрь браузера небольшую СУБД? Не только. Исторически первым об идее внедрить в браузер хоть небольшую, но базу данных заговорили в mozilla, планируя добавить эту функцию в firefox (новые возможности для разработчиков плагинов). Google gears — это не просто sqlite: программисты из google не пошли по пути создания мало кому нужной внутри браузера мини-СУБД, не стали добавлять к sqlite возможности ее “старших” братьев. Они придумали и реализовали другую методику согласования содержимого, находящегося в локальной базе данных на машине клиента, и данных, доступных на сервере. Теперь та картинка с развитой системой комментариев на новостном сайте становится возможной. Подсистема google gears загружает в локальное хранилище неизменяемую информацию на сайте, так что теперь вы можете работать с ней без выхода в интернет. А когда подключение к сети будет восстановлено, gears выполнит синхронизацию локальной информации и доступной на сайте (вдруг за это время появились новые статьи или комментарии). Условно google gears состоит из трех частей:
1. Локальный сервер, который кэширует нужные для работы приложения ресурсы — такие, как javascript, html, картинки. Слово “сервер” в названии может ввести в заблуждение. Но это совсем не означает, что вы можете с его помощью выполнять на стороне клиента php-скрипты.
2. Локальная база данных, построенная на основе sqlite.
3. Подсистема синхронизации, позволяющая выполнять перенос информации между клиентом и сервером.
Я покажу, как работать с gears, начав с простого примера, который не взаимодействует с сервером. Пока попытаемся хранить информацию только локально. В качестве примера будет записная книжка. Веб-страница будет содержать текстовое поле, куда нужно ввести некоторую заметку и кнопку “сохранить”. По нажатию на кнопку в базу будет помещаться введенная строка. Естественно, при перезагрузке страницы все введенные данные не будут потеряны, а будут отображены чуть ниже формы. Первое, с чего мы начнем — определим, установлен ли у нашего клиента google gears. Для этого я подключу к html-файлу приложения js-файл gears_init.js (его можно загрузить по адресу
http://code.google.com/apis/gears/resources/gears_init.js).
Затем я обращусь к глобальным переменным gears и google. Если этих переменных нет, то на компьютере нет и google gears.
<script src="gears_init.js"&glt;</script&glt;
<script&glt;
if (!window.google || !google.gears) {
alert ('google gears не установлен'); }
else{ alert ('Работаем с gears'); }
</script&glt;
При первом подключении к сайту, использующему gears, будет задан вопрос: “хотите ли вы для данного сайта разрешить использование gears” (см. рис. 1).
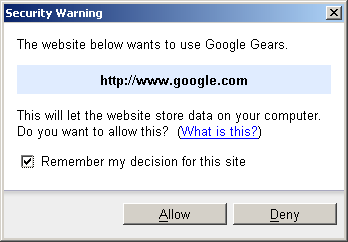
Рис. 1.
Естественно, в последующем вы можете просмотреть список “доверенных” сайтов и скорректировать его (меню Settings -> Google Gears Settings). После подключения к странице gears следует создать объект-подключение к базе данных. Для этого используйте функцию google.gears.factory.create. Это универсальная функция, создающая все объекты, с которыми только работают gears.
db = google.gears.factory.create('beta.database', '1.0');
if (db) { db.open('notebook'); }
Итак, я создал объект “база данных” затем с помощью функции open подключился к базе с именем notebook (естественно, указывать полный путь к файлу базы нельзя). После чего мы должны создать таблицы, из которых будет состоять база, и попробовать в них что-то занести. Особенности в синтаксисе создания таблицы незначительны по сравнению с другими СУБД — основные отличия в типах данных. Далее создается таблица с полями: id_note — уникальный номер для каждой из записей в таблице, note_title — заголовок заметки, note_date — дата публикации заметки, и note_text — собственно текст заметки:
db.execute('CREATE TABLE if not exists notes (id_note integer PRIMARY KEY NOT NULL, note_title varchar(50) NOT NULL, note_date date, note_text text)');
Для того, чтобы экспериментировать с синтаксисом sqlite, удобно воспользоваться специальной утилитой Gears In Motion (это часть google gears). Просто загрузите размещенную по адресу сайт html-страницу к себе на компьютер, а затем откройте ее как показано на рис. 2.
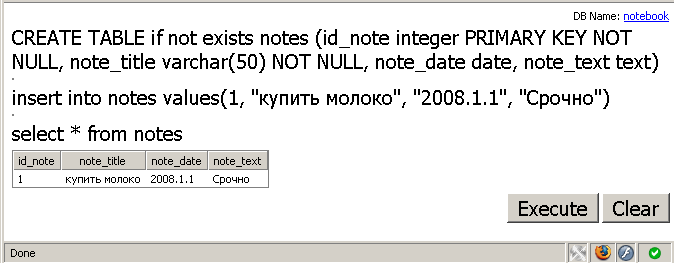
Рис. 2.
Созданное с помощью Gears приложение может работать без подключения к Internet (все необходимые ресурсы будут храниться на локальной машине клиента), а после восстановления связи информация будет синхронизирована. В прошлый раз я остановился на том, что показывал, как создать с помощью gears небольшое приложение “записная книжка”. Наверное, сегодня надо было бы завершить рассказ, показав, как сохранить информацию внутри этой книжки (не на сервере, а на машине клиента) и как добавить функцию обмена этими сведениями с веб-сервером, но все же нет. Сегодня я смещу фокус рассказа с gears на sqlite. В своих статьях я стремлюсь рассказывать не просто об отдельной программе (языке программирования или библиотеке), а охватить весь спектр технологий, решающих некоторую практическую задачу. И даже если вы не станете использовать gears, то, скорее всего, полученные сегодня знания по sqlite помогут вам разобраться с другими технологиями, использующими sqlite (тот же adobe air), в разработке “портфельных приложений” или классических веб-сайтов.
Sqlite — довольно интересная СУБД: одна из целей ее разработки была в создании инструмента, способного работать где угодно (не только серверы или настольные компьютеры, но и мобильные устройства) и со сколь угодно низкими затратами на ресурсы. Sqlite — встраиваемая СУБД. Это значит, что, в отличие от семейства клиент-серверных СУБД (mysql, postgres, oracle), у sqlite нет какого-то отдельного процесса (сервера), который был бы запущен на специальном компьютере и ждал бы запросов на обслуживание от множества клиентов. SQlite представляет собой библиотеку dll, которую можно интегрировать в любое приложение (в настоящее время есть интерфейсы для доступа к sqlite из таких языков, как: c++, php, perl, java, .net, ruby, delphi). Следовательно, Sqlite не рекомендуется использовать в тех ситуациях, когда база данных должна быть одновременно доступна для использования несколькими клиентами (даже на одной машине). Дело в том, что, хоть чтение из базы данных могут выполнять сразу любое количество клиентов, но вот операция записи является монопольной. А значит, для приложений, где количество операций “сохранить изменения” превалирует над “прочитать информацию”, sqlite будет мало полезна. Естественно, семейство встраиваемых СУБД состоит не только из sqlite. Фактически все “большие и сложные” СУБД (mysql, mssql, oracle) имеют меньших братьев, ориентированных на работу с меньшими нагрузками, не требующих сложных процедур установки и настройки (просто скопируй пару библиотек), способных работать на мобильных устройствах. Придут ли эти решения на рынок веб- приложений, сказать трудно. Сейчас фокус интереса крупных разработчиков направлен на sqlite. Я говорю про google с gears, adobe с air, mozilla с firefox, — все эти компании используют в своих продуктах sqlite. Одним из ключевых факторов успеха является то, что sqllite бесплатен и открыт для изменений всеми (лицензия public domain). Для лучшего понимания идеологии sqlite и направления его развития я настоятельно советую найти журнал linux format (он есть в свободном доступе в интернет и даже на русском) за декабрь 2005 г. — там было опубликовано интервью с создателем sqllite Ричардом Хиппом. К сожалению, хорошей русскоязычной документации по sqlite очень мало: энтузиазма переводчиков ( сайт ) хватило ненадолго. Если вам интересен вопрос связи php и sqlite, то наверняка найдете полезное для себя на странице сайт или сайте сайт . Для экспериментов с sqlite вовсе не обязательно писать код javascript с помощью gears. На сайте разработчиков библиотеки ( сайт ) можно найти несколько вариантов поставки sqllite. Это может быть dll или so-библиотеки для встраивания движка базы в другое приложение, исходные коды библиотеки, и наиболее ценный для нас вариант — загрузить архив с одной-единственной утилитой sqlite3.exe. Это командная консоль sqlite — в ней вы можете писать команды sql и тут же получать ответ. Для тех, кого пугает черный экран с мигающим курсором, и они хотят использовать графическую оболочку, могу порекомендовать сайт или сайт . Я настоятельно советую обзавестись каким- либо графическим менеджером СУБД: при знакомстве с sqlite вас ждет несколько сногсшибательных новостей, пережить которые в одной консоли будет тяжело.
Хотя sqlite отлична от своих более серьезных родственников, концепция у них одна и та же — реляционная. Это значит, что база данных (файл с расширением db) содержит описания таблиц, их индексы и собственно хранимую информацию. При запуске консоли sqlite.exe необходимо указать как параметр командной строки имя файла базы данных, с которым вы хотите работать. Если такого файла нет, он будет создан (см. рис. 3).
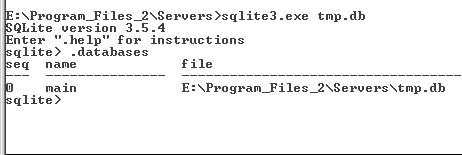
Рис. 3.
Естественно, gears никогда бы не позволил веб-приложению работать с файловой системой компьютера клиента и указывать каталог, где будет создан файл базы данных. Так, когда вы вызываете gears функцию db.open('имя_базы_данных'), в “секретном месте” создается файл с именем
имя_базы_данных#database. Естественно, gears заботятся о том, чтобы не возник конфликт, если пара веб-сайтов попробуют создать базу данных с одинаковым именем. Правда, есть и плохая новость: если вы заходите на один сайт с помощью firefox и с помощью internet explorer, то созданные ими базы данных (одноименные) все равно будут считаться разными. Остается надеяться, что по мере развития gears эта проблема будет решена. Команды, которые вы можете выполнять, делятся на две категории: стандартные sql-запросы и специфически команды — именно sqlite (они начинаются с точки и в основном служат для того, чтобы посмотреть список таблиц в базе и других административных задач). Что касается поддержки sql, то нам придется ограничиться стандартом SQL92. В ходе дальнейшего чтения вам может показаться, что sqlite — это что-то очень “сырое” и “недоделанное”. На самом деле выбор функциональности sqlite строго обоснован, и ее нельзя сравнивать, например, с ранними версиями mysql (там тоже не поддерживались многие из определенных стандартом SQL функций). Начнем с самого простого: создания таблиц. И тут нас ждет первый сюрприз. В sqlite нет различия между типами данных. Наверняка вы привыкли, что при создании таблицы (еще с самых древних времен) было необходимо сказать, какие в ней должны быть поля, какой тип данных в этих полях мог храниться (строки, числа), и даже размеры этих типов (например, строка, но размером не более 100 символов). В sqlite всего этого нет. В версии 2.0 все типы данных воспринимались как строки. В версии 3 произошли изменения и были выделены четыре “ненастоящих” типа данных: целые и вещественные числа, строки, двоичные данные (BLOB). Я назвал эти типы данных “ненастоящими”, потому что могу поместить в поле, созданное как целое число, строку текста (и, похоже, так останется навсегда — Ричард Хипп достаточно четко выразился в этом плане). Вот простой пример, создающий таблицу для хранения сведений о людях (ввод команды должен завершаться символом точки с запятой):
create table users (id, fio, age, sex);
Хоть ни одно поле не имеет указания на тип данных, пример работает. С другой стороны, если вы воспользуетесь каким-либо визуальным редактором sql, то можете заметить, что мастер создания таблицы предлагает вам выбрать для полей тип из падающего списка (на рис. 4 показано создание таблицы с помощью SqliteMaestro). И здесь нет никакого противоречия. Дело в том, что сама идея отказаться от типов данных настолько выбивает из колеи программистов (и меня в том числе), что разработчики SqliteMaestro решили спрятать эти возможности подальше, и вы никак не сможете в графической оболочке ввести в некоторое поле, помеченное при создании как число, строку. Но если вы откроете консоль sqlite.exe, то карточный домик иллюзии наличия типов данных разрушится в мгновение. Если вам более привычно, можете при создании таблицы указать тип создаваемых полей, но не надейтесь на то, что sqlite будет контролировать вводимые вами данные на предмет соответствия их этим типам данных.
create table users2 (id int, fio varchar(100), birthday date, sex varchar(1));
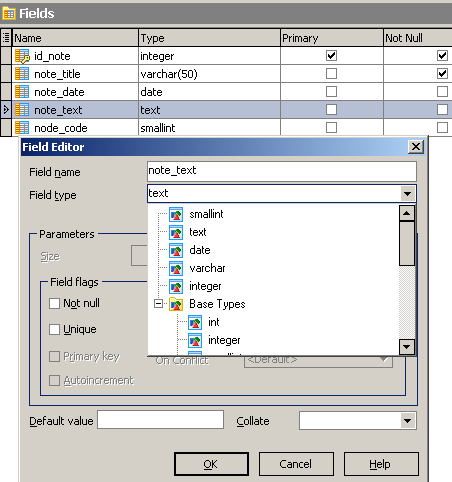
Рис. 4.
Я все равно смогу вносить в поле, помеченное как date, произвольные строки текста. На самом деле в sqlite есть “хитрое понятие”, называемое “manifest typing”. Его идея в том, что тип данных ассоциируется с самим значением, а не с полем или переменной, в которой это значение хранится. Это похоже на разницу между языками программирования с динамической и статической типизацией. Если вы попытаетесь внести в некоторое поле значение, равное цифре, то оно будет сохранено как цифра. На стадии сравнения переменных или полей таблицы между собой решение будет принято на основе значений, которые хранятся в этих полях. При создании таблицы не следует давать ей имя, начинающееся со слова "sqlite_" — оно является зарезервированным. Создаваемые таблицы могут быть как persistent (сохраняющими свои значения между несколькими сеансами sqlite в файле), так и temporary. В этом случае, если несколько пользователей, одновременно работающих с одной и той же базой sqlite, создадут temporary-таблицы (путь даже и одноименные), эти таблицы будут независимы для каждого из подключений и будут автоматически уничтожены, как только соединение с БД будет прервано. Вот пример создания временной таблицы (отличие от предыдущего примера только в ключевом слове “temporary”):
create temporary table users7(fio, age, sex);
Создавая таблицу в любой другой СУБД, вы часто использовали “ограничения”, накладываемые на значения полей (unique, check, триггеры). Посмотрим, что же уцелело из этого набора в sqlite? Уцелело все. Во-первых, сохранилась концепция первичного ключа (такого поля или набора полей, которые гарантированно уникальны для любых записей в таблице). Если поле при создании помечено как primary key, то любая попытка внести в него дублирующиеся значения будет неудачной.
sqlite&glt; create table x1 (i int primary key);
sqlite&glt; insert into x1 values (1);
sqlite&glt; insert into x1 values (2);
sqlite&glt; insert into x1 values (2);
SQL error: column i is not unique
И даже есть возможность сказать, что значение первичного ключа будет назначаться не нами, а самой СУБД (старые добрые identity и
auto_increment). Обратите внимание в следующем примере на то, что поле первичного ключа объявляется как INTEGER (не INT).
sqlite&glt; create table table_c (id INT primary key autoincrement, fio varchar(100));
SQL error: AUTOINCREMENT is only allowed on an INTEGER PRIMARY KEY
sqlite&glt; create table table_d (id INTEGER primary key autoincrement, fio varchar(100));
sqlite&glt; insert into table_d (fio) values ('Bill');
sqlite&glt; insert into table_d (fio) values ('Mary');
sqlite&glt; select * from table_d;
1|Bill
2|Mary
В том случае, если при вставке записи мы не укажем значения некоторого поля, оно получит значение по умолчанию (DEFAULT). Этим значением может быть не только строка или число, но и ключевые слова: CURRENT_TIME, CURRENT_DATE, CURRENT_TIMESTAMP — это соответственно текущее время, текущая дата, текущая дата и время.
sqlite&glt; create table users5 (fio, now default current_timestamp);
sqlite&glt; insert into users5 (fio) values ('mary');
sqlite&glt; select * from users5;
mary|2008-01-15 14:26:47
Для того, чтобы созданная нами таблица работала быстро, нам нужны индексы. Sqlite позволяет нам создать две их разновидности (кроме первичных): обычные и уникальные. Если обычные индексы только ускоряют операции с данными (зависящие от полей, по которым построены индексы), то уникальные индексы запретят вам дублировать значения привязанных к ним полей. Есть два момента, когда вы можете создать индекс: либо на стадии определения таблицы, либо позже. Следующий пример показывает, как назначить полю fio уникальный индекс:
create table users4 (id integer primary key, fio varchar(100) unique);
insert into users4 (fio) values ('mary');
insert into users4 (fio) values ('mary');
SQL error: column fio is not unique
Или после того, как таблица была создана, вы можете добавить к ней как обычный, так и уникальный индекс. Важно при создании индекса назначить ему имя (в примере это idx_fio, unq_fio):
create index idx_fio on users(fio); создаем обычный индекс
sqlite> create unique index unq_fio on users(fio); и пример с уникальным индексом
sqlite> insert into users (fio) values ('Mark');
sqlite> insert into users (fio) values ('Mark');
SQL error: column fio is not unique
Индексы можно удалять, используя для этого команду “drop index имя_индекса”. Не важно, уникальный это индекс или обычный — главное — чтобы они были созданы с помощью “create index”. Создавая таблицу, вы можете наложить ограничения на значения полей (например, величина зарплаты сотрудника должна быть в диапазоне от $0 до $1000). Для этого используются CHECK ограничения. Есть два вида check: ограничения, накладываемые на одно поле, и ограничения, которые оперируют всеми полями в таблице одновременно. В следующем примере я создам таблицу с двумя “числовыми” полями. На первое из них будет наложено требование: значение поля должно быть более 100, для второго поля значение менее 200, и третье ограничение говорит, что сумма этих двух полей не должна превосходить 150. Условия CHECK проверяются всегда (как при добавлении новой записи, так и при редактировании существующей).
sqlite&glt; create table numbers (num_1 int check(num_1 &glt; 100), num_2 int check (num_2 &llt; 200), check (num_1 + num_2 &llt; 150));
sqlite&glt; insert into numbers values (200,100);
SQL error: constraint failed
sqlite&glt; insert into numbers values (110,30); теперь ограничения CHECK не нарушены
sqlite&glt; update numbers set num_1 = 400; пробуем обновить запись так, чтобы нарушить CHECK для всей таблицы
SQL error: constraint failed
И третий способ контролировать ввод данных в таблицы — использовать триггеры. Триггер — это процедура, которая вызывается всякий раз, когда значение в таблице меняется (добавление, удаление или правка записей). Триггер может выполнять сложные проверки для вносимых данных или выполнять изменения в смежных таблицах. Очевидно, что созданная нами таблица может нуждаться в корректировке: мы можем захотеть добавить парочку полей, поменять их имена, удалить поле. Неприятный сюрприз в том, что команда ALTER (стандартная SQL-инструкция правки таблицы) в sqlite реализована, мягко говоря, не полностью. Вы можете только переименовывать таблицы или добавлять к ним новые поля — например, так:
alter table users rename to people; переименовали таблицу users в people
alter table users add cash float; добавили новое поле — зарплата человека
Если же вы хотите сделать что-то посложнее, то единственный путь — создать еще одну таблицу в соответствии с новыми пожеланиями, скопировать в нее данные из предыдущей и затем удалить старую таблицу. Это не сложно, но, чтобы избежать глупых ошибок-опечаток, лучше использовать, например, SqliteMaestro. Там мастер изменения структуры таблиц сам сгенерирует и выполнит все эти рутинные шаги. Для удаления созданной таблицы используйте команду “drop table имя таблицы”. Создав несколько таблиц, вы захотите просмотреть их список и из каких полей они состоят. В первом случае вам поможет команда “.tables ШАБЛОН”. Она выведет имена всех таблиц в текущей базе данных (или только тех, что соответствуют шаблону, если вы его укажете). Для того, чтобы увидеть код, создавший таблицу, используйте команду “.schema ШАБЛОН”. В случае, если вы укажете значение шаблона, будет выведен код DDL, создающий ту таблицу, имя которой совпадает с этим шаблоном. Если же шаблон не указан, будет выведен код создания для абсолютно всех таблиц. Наверняка пригодится и команда, которая создает полный дамп содержимого базы данных “.dump”. Не забудьте только перед тем, как выполнить дамп базы, перенаправить поток вывода во внешний файл — например, так: “.output имя_файла”, — после чего вернуть вывод снова на экран поможет команда “.output stdout”. Роль команды dump для переноса базы данных с одного компьютера на другой не столь значительна, как для mysql или postgres. С момента выпуска первой версии sqlite в 2000 году уже прошли десятки раз, когда менялся внутренний формат файла для хранения содержимого базы данных. Хотя в большинстве своем каждая новая версия sqlite неплохо работает с файлами, созданными в предыдущей версии (но только в рамках одной “старшей версии”). Более того, формат хранения данных не зависит от разрядности компьютера (32 и 64 бита) порядка “старший байт-младший байт”. Фактически вы можете послать db-файл по электронной почте, будучи уверенным, что на другой стороне он прочитается без проблем. Если же у вас возникнут проблемы, используйте для переноса данных dump.
В следующий раз я продолжу и завершу рассказ о совместном использовании sqlite и google gears, а также покажу, как использовать sqlite на стороне веб-сервера.
black-zorro, black-zorro@tut.by.
Смотрите: раньше в качестве цели декларировалась доставка в настольную программу содержимого из internet (в простейшем случае поиск по справке выполнялся не только в файлах на жестком диске компьютера, но в internet). Сейчас мы говорим: а давайте расширим возможности веб-приложения, дадим ему возможность выполняться на машине компьютера без подключения к сети. Дадим возможность хранить часть информации локально, а часть — в сети. Давайте доставим по сети на машину клиента ядро программы (не просто сайт с парой страниц, а сложное приложение наподобие google docs). Затем пользователь может работать в “сайтопрограмме”, а на стадии сохранения информации или для получения дополнительной функциональности подключиться к сети. Что вы говорите? Слышали это в рекламе пару лет назад? Не ново? Согласен, сейчас мир IT устроен так, что революции произойти не может, части технически продвинутых “гиков” будут мешать консервативно настроенные пользователи (коих большинство). Эти “консерваторы” будут сопротивляться: ведь они совершенно не понимают, зачем им нужно устанавливать у себя на компьютере какие-то непонятные и потенциально опасные плагины, зачем им нужно менять столь привычный internet explorer на новомодный firefox. Людям не нужна “классная” технология сама по себе, им нужны удобные инструменты для работы — такие, чтобы ими можно было начать пользоваться без дополнительных затрат времени. К чему я веду этот разговор? К тому, что нужно заниматься популяризацией технических идей, нужно, чтобы как можно больше людей занимались разработкой полезных и нужных веб-приложений. Я очень уважаю компании adobe, microsoft, sun. Мне очень нравятся те продукты, которые они представили на рынок: air (в девичестве apollo), silverlight, javafx. Но все дело в том, что разработка с помощью их требует изрядных сил и познаний. Да, продукты получаются качественные (при отсутствии кривизны рук у разработчиков), но и слишком дорогие. Мне нравится политика google: они не создают общие инструменты для веб-разработки, коих на рынке и так уже переизбыток — они создают сервисы (Google AJAX Feed API, Google AJAX Search API, Google Chart API, Google Checkout API). Затем они предоставляют для всех желающих api, учебную документацию, рассказывающую, “как программировать на этой штуке”, а потом проект начинает развиваться за счет приложения сил многих миллионов пользователей сети. Не правда ли, хороший лозунг: “заставь на себя работать весь мир”? Об одном из таких сервисов — google gears — я хочу сегодня рассказать. На самом деле я немного лукавлю: Google gears — не просто веб-сервис (вроде той классной javascript-библиотеки, загружающей вам на сайт список новостей). Google gears — нечто большее — это плагин (о ужас! его нужно устанавливать) для вашего браузера. В настоящее время поддерживаются internet explorer, firefox, safari (фанаты opera, вам придется обождать). Впервые я столкнулся с gears весной 2007 г., когда на странице моей подписки на rss-новости (google reader) появилась функция offline-просмотра новостей. Тогда меня это не впечатлило: как раз таки рынок rss- ридеров достаточно плотно заселен. Сам я пользуюсь встроенной в opera поддержкой чтения rss-лент и не особенно думаю о ее смене. Тогда я не заметил за лесом деревьев. Вернувшись к этой теме спустя время, я задумался над тем, как реализована эта функциональность, и можно ли ее использовать в своих проектах? Оказалось, что использование google gears позволяет строить сайты нового типа с изменениями и улучшениями не в “рюшечках”, а в методике показа информации. Предположим, что вы хотите сделать новостной сайт или сайт, публикующий статьи и учебные материалы. Естественно, важен не только сам материал, но и его обсуждение. Часто бывает так, что люди пишут в комментариях более ценные для вас замечания, чем собственно текст статьи. Ага, давайте сделаем rss-ленту, в которой будут публиковаться все сделанные комментарии. Нет проблем — на многих продвинутых сайтах и блогах подобная функция есть. Вот только при чтении этих комментариев (ведь многие из них могут приходить спустя несколько дней или недель) удобно иметь перед глазами исходный текст статьи. Неплохо, чтобы комментарии были привязаны к определенным местам в статье — таким, как сноски, неплохо, чтобы вы имели возможность добавлять собственные комментарии, видимые не только для всех, но и для определенных групп посетителей или только для самого себя. И тут никак универсальным программами RSS-ридерами не обойтись. С другой стороны, очень неудобно периодически заходить на сайт, чтобы проверить, появились ли новые заметки по интересующей вас теме, загружая каждый раз заново все содержимое статьи (которое наверняка не поменялось). Почти все, что я описал выше, можно сделать с помощью javascript и ajax. Вот только как быть с хранением данных — тех самых личных заметок или содержимого статьи? Как быть, если вы начали писать комментарий, но не успели, т.к., например, были вынуждены уйти, но хотите придти завтра и продолжить с прерванного места? Где хранить эти данные? В какой-то еще одной программе? Неудобно? Почему так распространены всевозможные сайты-сервисы “быстрых заметок”? Вся беда в том, что в браузере нет пристойных средств для хранения пользовательской информации. Я специально отметил слово “пристойных”. Все знают о cookie — небольших кусочках информации, которые сайт может сохранить на машине пользователя — так, чтобы при последующем посещении эту информацию взять и использовать. Традиционно cookie используются для хранения небольших данных — например, это имя, под которым посетитель сайта зарегистрирован. Информация может храниться в течение некоторого времени: несколько дней или месяцев. Вот только назвать cookie “пристойным” хранилищем информации — нет, и еще раз нет. Попробуйте, например, запустить следующий js-код:
for (var i = 0; i < 1000; i++)
document.cookie = 'var_' + i + '=' + 'value_' + i + ';';
alert (document.cookie);
alert ((document.cookie).length);
Это очень простой пример: в нем я помещаю внутрь cookie множество переменных с именами “var_0”, “var_1”, … “var_999”, каждой из этих переменных я присваиваю значение “value_0”, “value_1”, …,“value_999”. После окончания цикла я вывожу значение переменной “document.cookie” и длину этой переменной. Все cookie, которые вы сохраните внутри страницы, помещаются внутрь одной служебной переменной с именем “document.cookie”. Эта переменная имеет тип данных “строка” и внутри выглядит примерно так:
fio=vasyan; expires=Mon, 07 Jan 2008 20:51:46 GMT; path=/docs/java/; domain=www.site.com; secure
Как видите, в одной строке находится множество переменных, для каждой из них указывается имя, значение переменной, срок хранения, права доступа (каталог и домен из которого данное значение cookie будет доступно). Затем информация, помещенная внутрь cookie, сохраняется в виде небольших файликов на вашем компьютере. Проблема не в том, что такой формат представления данных неудобен (благо существует множество пользовательских js- функций, упрощающих операции “положить что-нибудь в cookie”, или “изъять”, или “удалить содержимое cookie”). Проблема в том, что, если запустить данный пример кода в трех браузерах: Internet Explorer, Firefox, Opera, — мы получим различные результаты. Так, для ie внутри переменной “document.cookie” окажутся только переменные с номерами от 980 по 999, а длина выводимой строки будет равна 378 символов. Как же в этих 378 символах смогла уместиться аж тысяча пар строк каждая длиной в добрых десятка два символов? Посмотрим, что покажет opera. Вывелись переменные с 970 по 998 — уже лучше — целых 568 символов. Но все равно куда-то пропали девять десятых всех помещенных внутрь cookie переменных. А что покажет firefox? Тут результат еще забавнее: вывелись переменные в интервале от var_0 до var_48, затем пустота — и, наконец, одинокая переменная под номером 999. Длина строки “document.cookie” для “лисы” равна целых 830 символов. Увы, но браузер сохраняет не любую информацию, помещенную в cookie, а только ту, которая укладывается в лимит 4 Кб. Есть ограничения на количество файлов cookie в рамках одного домена. Так, для internet explorer эта цифра составляет 20, для firefox — 50 и для opera — 30. Это еще не все. Для internet explorer суммарный объем всех cookie должен быть не более 4 Кб, а для остальных браузеров 4 Кб — это ограничение на один файл. Кроме того, в cookie неудобно хранить сложные структуры данных. Например, вы хотите сохранить не просто пару “ключ => строковое значение”, а массив элементов или объект. В такой ситуации остается только умыть руки.
В настоящий момент очень мало кто хранит сведения, собираемые на сайте, именно внутри cookie. Обычно в cookie помещается некоторое число — код сессии (имя файла, номер записи в БД). Когда открывается веб-страница, идет обращение к http-серверу с указанием имени страницы, которую вы хотите открыть, плюс передается содержимое cookie. Затем на сервере на основании номера сессии выполняется поиск в файле или таблице БД реальной информации (той информации, которой много более, чем 4 Кб, той, которая может содержать сложные структуры данных). Естественно, не всегда следует и не всегда возможно хранить информацию на сервере. Например, при разработке крупных и часто посещаемых сайтов средства работы с сессиями переписываются фактически с нуля. Особенно ярко такая тенденция появилась с широким внедрением идей web 2.0. Веб-страницы, постоянно обращающиеся с помощью ajax к веб-серверу за информацией, способны свести с ума любую систему поддержки сессий (хранения пользовательской информации) на стороне сервера. В тех редких случаях, когда я был вынужден хранить большие данные на стороне клиента, приходилось использовать средства flash. Дело в том, что встроенные в flash методики “сохранить немножко информации на стороне клиента” гораздо либеральнее, чем стандартные средства браузера. Верить, что разработчики браузеров решат пересмотреть методику работы с cookie и добавят в браузеры новые возможности, не стоит. Тем более не стоит верить в то, что они это сделают единообразным образом и в полной мере удовлетворят потребности веб- разработчиков.
Сегодня я обещал рассказать о google gears. Сначала нужно скачать плагин для вашего браузера по следующему адресу:
http://gears.google.com/download.html. Там же вы найдете документацию и примеры, работающие с google gears.
Но прежде, чем я перейду к техническим деталям, позвольте мне напомнить в очередной раз: “серебряной пули нет”. Одной из ключевых возможностей этого плагина (далеко не единственной) является новая, абсолютно новая, модель хранения пользовательских данных на компьютере. Такого вы еще не видели! Вы знаете, что такое базы данных? Да, это те самые невероятно дорогие (или совершенно бесплатные) штуки, которые могут хранить миллионы единиц информации и мгновенно искать среди них нужную. Еще вы слышали, что для того, чтобы научиться работать с базами данных нужны долгие годы. На самом деле существует огромное множество различных баз данных (популярных, конечно, гораздо меньше). Базы данных ориентируются на различные платформы и сегменты потребителей, есть такие СУБД, что запустить их даже на мощном современном ПК — нетривиальная задача. Есть и такие СУБД, которые могут быть встроены внутрь вашего мобильника пятилетней давности. Для веб-сайтов традиционно применяют такие СУБД, как mysql, postgres. Серьезные предприятия хранят информацию в microsoft sql server, oracle, ibm db2. И есть среди этого списка такая СУБД, как sqlite. Это достаточно необычная СУБД, и многие из ее возможностей наверняка отпугнут “зубров программирования”. Тем не менее, она завоевывает известность и для поддержки в internet небольших сайтов, и для создания “портфельных приложений”. Под “портфельными приложениями” я понимаю ситуацию, когда программе нужна для работы БД, но при этом предполагается, что приложение будет переноситься на флэшке или распространяться на CD-диске. Естественно, требовать установки каких-то драйверов к БД и ее предварительной настройки перед работой просто глупо — клиенты не оценят. Еще один сегмент рынка, где властвует sqlite — всевозможные встраиваемые приложения. Для работы sqlite достаточно всего 200 Кб памяти. А если и этого вам окажется мало, то благодаря тому, что sqlite — open source, “продвинутые” программисты всегда могут “поработать напильником”. Так что, google gears — это всего лишь добавили внутрь браузера небольшую СУБД? Не только. Исторически первым об идее внедрить в браузер хоть небольшую, но базу данных заговорили в mozilla, планируя добавить эту функцию в firefox (новые возможности для разработчиков плагинов). Google gears — это не просто sqlite: программисты из google не пошли по пути создания мало кому нужной внутри браузера мини-СУБД, не стали добавлять к sqlite возможности ее “старших” братьев. Они придумали и реализовали другую методику согласования содержимого, находящегося в локальной базе данных на машине клиента, и данных, доступных на сервере. Теперь та картинка с развитой системой комментариев на новостном сайте становится возможной. Подсистема google gears загружает в локальное хранилище неизменяемую информацию на сайте, так что теперь вы можете работать с ней без выхода в интернет. А когда подключение к сети будет восстановлено, gears выполнит синхронизацию локальной информации и доступной на сайте (вдруг за это время появились новые статьи или комментарии). Условно google gears состоит из трех частей:
1. Локальный сервер, который кэширует нужные для работы приложения ресурсы — такие, как javascript, html, картинки. Слово “сервер” в названии может ввести в заблуждение. Но это совсем не означает, что вы можете с его помощью выполнять на стороне клиента php-скрипты.
2. Локальная база данных, построенная на основе sqlite.
3. Подсистема синхронизации, позволяющая выполнять перенос информации между клиентом и сервером.
Я покажу, как работать с gears, начав с простого примера, который не взаимодействует с сервером. Пока попытаемся хранить информацию только локально. В качестве примера будет записная книжка. Веб-страница будет содержать текстовое поле, куда нужно ввести некоторую заметку и кнопку “сохранить”. По нажатию на кнопку в базу будет помещаться введенная строка. Естественно, при перезагрузке страницы все введенные данные не будут потеряны, а будут отображены чуть ниже формы. Первое, с чего мы начнем — определим, установлен ли у нашего клиента google gears. Для этого я подключу к html-файлу приложения js-файл gears_init.js (его можно загрузить по адресу
http://code.google.com/apis/gears/resources/gears_init.js).
Затем я обращусь к глобальным переменным gears и google. Если этих переменных нет, то на компьютере нет и google gears.
<script src="gears_init.js"&glt;</script&glt;
<script&glt;
if (!window.google || !google.gears) {
alert ('google gears не установлен'); }
else{ alert ('Работаем с gears'); }
</script&glt;
При первом подключении к сайту, использующему gears, будет задан вопрос: “хотите ли вы для данного сайта разрешить использование gears” (см. рис. 1).
Рис. 1.
Естественно, в последующем вы можете просмотреть список “доверенных” сайтов и скорректировать его (меню Settings -> Google Gears Settings). После подключения к странице gears следует создать объект-подключение к базе данных. Для этого используйте функцию google.gears.factory.create. Это универсальная функция, создающая все объекты, с которыми только работают gears.
db = google.gears.factory.create('beta.database', '1.0');
if (db) { db.open('notebook'); }
Итак, я создал объект “база данных” затем с помощью функции open подключился к базе с именем notebook (естественно, указывать полный путь к файлу базы нельзя). После чего мы должны создать таблицы, из которых будет состоять база, и попробовать в них что-то занести. Особенности в синтаксисе создания таблицы незначительны по сравнению с другими СУБД — основные отличия в типах данных. Далее создается таблица с полями: id_note — уникальный номер для каждой из записей в таблице, note_title — заголовок заметки, note_date — дата публикации заметки, и note_text — собственно текст заметки:
db.execute('CREATE TABLE if not exists notes (id_note integer PRIMARY KEY NOT NULL, note_title varchar(50) NOT NULL, note_date date, note_text text)');
Для того, чтобы экспериментировать с синтаксисом sqlite, удобно воспользоваться специальной утилитой Gears In Motion (это часть google gears). Просто загрузите размещенную по адресу сайт html-страницу к себе на компьютер, а затем откройте ее как показано на рис. 2.
Рис. 2.
Созданное с помощью Gears приложение может работать без подключения к Internet (все необходимые ресурсы будут храниться на локальной машине клиента), а после восстановления связи информация будет синхронизирована. В прошлый раз я остановился на том, что показывал, как создать с помощью gears небольшое приложение “записная книжка”. Наверное, сегодня надо было бы завершить рассказ, показав, как сохранить информацию внутри этой книжки (не на сервере, а на машине клиента) и как добавить функцию обмена этими сведениями с веб-сервером, но все же нет. Сегодня я смещу фокус рассказа с gears на sqlite. В своих статьях я стремлюсь рассказывать не просто об отдельной программе (языке программирования или библиотеке), а охватить весь спектр технологий, решающих некоторую практическую задачу. И даже если вы не станете использовать gears, то, скорее всего, полученные сегодня знания по sqlite помогут вам разобраться с другими технологиями, использующими sqlite (тот же adobe air), в разработке “портфельных приложений” или классических веб-сайтов.
Sqlite — довольно интересная СУБД: одна из целей ее разработки была в создании инструмента, способного работать где угодно (не только серверы или настольные компьютеры, но и мобильные устройства) и со сколь угодно низкими затратами на ресурсы. Sqlite — встраиваемая СУБД. Это значит, что, в отличие от семейства клиент-серверных СУБД (mysql, postgres, oracle), у sqlite нет какого-то отдельного процесса (сервера), который был бы запущен на специальном компьютере и ждал бы запросов на обслуживание от множества клиентов. SQlite представляет собой библиотеку dll, которую можно интегрировать в любое приложение (в настоящее время есть интерфейсы для доступа к sqlite из таких языков, как: c++, php, perl, java, .net, ruby, delphi). Следовательно, Sqlite не рекомендуется использовать в тех ситуациях, когда база данных должна быть одновременно доступна для использования несколькими клиентами (даже на одной машине). Дело в том, что, хоть чтение из базы данных могут выполнять сразу любое количество клиентов, но вот операция записи является монопольной. А значит, для приложений, где количество операций “сохранить изменения” превалирует над “прочитать информацию”, sqlite будет мало полезна. Естественно, семейство встраиваемых СУБД состоит не только из sqlite. Фактически все “большие и сложные” СУБД (mysql, mssql, oracle) имеют меньших братьев, ориентированных на работу с меньшими нагрузками, не требующих сложных процедур установки и настройки (просто скопируй пару библиотек), способных работать на мобильных устройствах. Придут ли эти решения на рынок веб- приложений, сказать трудно. Сейчас фокус интереса крупных разработчиков направлен на sqlite. Я говорю про google с gears, adobe с air, mozilla с firefox, — все эти компании используют в своих продуктах sqlite. Одним из ключевых факторов успеха является то, что sqllite бесплатен и открыт для изменений всеми (лицензия public domain). Для лучшего понимания идеологии sqlite и направления его развития я настоятельно советую найти журнал linux format (он есть в свободном доступе в интернет и даже на русском) за декабрь 2005 г. — там было опубликовано интервью с создателем sqllite Ричардом Хиппом. К сожалению, хорошей русскоязычной документации по sqlite очень мало: энтузиазма переводчиков ( сайт ) хватило ненадолго. Если вам интересен вопрос связи php и sqlite, то наверняка найдете полезное для себя на странице сайт или сайте сайт . Для экспериментов с sqlite вовсе не обязательно писать код javascript с помощью gears. На сайте разработчиков библиотеки ( сайт ) можно найти несколько вариантов поставки sqllite. Это может быть dll или so-библиотеки для встраивания движка базы в другое приложение, исходные коды библиотеки, и наиболее ценный для нас вариант — загрузить архив с одной-единственной утилитой sqlite3.exe. Это командная консоль sqlite — в ней вы можете писать команды sql и тут же получать ответ. Для тех, кого пугает черный экран с мигающим курсором, и они хотят использовать графическую оболочку, могу порекомендовать сайт или сайт . Я настоятельно советую обзавестись каким- либо графическим менеджером СУБД: при знакомстве с sqlite вас ждет несколько сногсшибательных новостей, пережить которые в одной консоли будет тяжело.
Хотя sqlite отлична от своих более серьезных родственников, концепция у них одна и та же — реляционная. Это значит, что база данных (файл с расширением db) содержит описания таблиц, их индексы и собственно хранимую информацию. При запуске консоли sqlite.exe необходимо указать как параметр командной строки имя файла базы данных, с которым вы хотите работать. Если такого файла нет, он будет создан (см. рис. 3).
Рис. 3.
Естественно, gears никогда бы не позволил веб-приложению работать с файловой системой компьютера клиента и указывать каталог, где будет создан файл базы данных. Так, когда вы вызываете gears функцию db.open('имя_базы_данных'), в “секретном месте” создается файл с именем
имя_базы_данных#database. Естественно, gears заботятся о том, чтобы не возник конфликт, если пара веб-сайтов попробуют создать базу данных с одинаковым именем. Правда, есть и плохая новость: если вы заходите на один сайт с помощью firefox и с помощью internet explorer, то созданные ими базы данных (одноименные) все равно будут считаться разными. Остается надеяться, что по мере развития gears эта проблема будет решена. Команды, которые вы можете выполнять, делятся на две категории: стандартные sql-запросы и специфически команды — именно sqlite (они начинаются с точки и в основном служат для того, чтобы посмотреть список таблиц в базе и других административных задач). Что касается поддержки sql, то нам придется ограничиться стандартом SQL92. В ходе дальнейшего чтения вам может показаться, что sqlite — это что-то очень “сырое” и “недоделанное”. На самом деле выбор функциональности sqlite строго обоснован, и ее нельзя сравнивать, например, с ранними версиями mysql (там тоже не поддерживались многие из определенных стандартом SQL функций). Начнем с самого простого: создания таблиц. И тут нас ждет первый сюрприз. В sqlite нет различия между типами данных. Наверняка вы привыкли, что при создании таблицы (еще с самых древних времен) было необходимо сказать, какие в ней должны быть поля, какой тип данных в этих полях мог храниться (строки, числа), и даже размеры этих типов (например, строка, но размером не более 100 символов). В sqlite всего этого нет. В версии 2.0 все типы данных воспринимались как строки. В версии 3 произошли изменения и были выделены четыре “ненастоящих” типа данных: целые и вещественные числа, строки, двоичные данные (BLOB). Я назвал эти типы данных “ненастоящими”, потому что могу поместить в поле, созданное как целое число, строку текста (и, похоже, так останется навсегда — Ричард Хипп достаточно четко выразился в этом плане). Вот простой пример, создающий таблицу для хранения сведений о людях (ввод команды должен завершаться символом точки с запятой):
create table users (id, fio, age, sex);
Хоть ни одно поле не имеет указания на тип данных, пример работает. С другой стороны, если вы воспользуетесь каким-либо визуальным редактором sql, то можете заметить, что мастер создания таблицы предлагает вам выбрать для полей тип из падающего списка (на рис. 4 показано создание таблицы с помощью SqliteMaestro). И здесь нет никакого противоречия. Дело в том, что сама идея отказаться от типов данных настолько выбивает из колеи программистов (и меня в том числе), что разработчики SqliteMaestro решили спрятать эти возможности подальше, и вы никак не сможете в графической оболочке ввести в некоторое поле, помеченное при создании как число, строку. Но если вы откроете консоль sqlite.exe, то карточный домик иллюзии наличия типов данных разрушится в мгновение. Если вам более привычно, можете при создании таблицы указать тип создаваемых полей, но не надейтесь на то, что sqlite будет контролировать вводимые вами данные на предмет соответствия их этим типам данных.
create table users2 (id int, fio varchar(100), birthday date, sex varchar(1));
Рис. 4.
Я все равно смогу вносить в поле, помеченное как date, произвольные строки текста. На самом деле в sqlite есть “хитрое понятие”, называемое “manifest typing”. Его идея в том, что тип данных ассоциируется с самим значением, а не с полем или переменной, в которой это значение хранится. Это похоже на разницу между языками программирования с динамической и статической типизацией. Если вы попытаетесь внести в некоторое поле значение, равное цифре, то оно будет сохранено как цифра. На стадии сравнения переменных или полей таблицы между собой решение будет принято на основе значений, которые хранятся в этих полях. При создании таблицы не следует давать ей имя, начинающееся со слова "sqlite_" — оно является зарезервированным. Создаваемые таблицы могут быть как persistent (сохраняющими свои значения между несколькими сеансами sqlite в файле), так и temporary. В этом случае, если несколько пользователей, одновременно работающих с одной и той же базой sqlite, создадут temporary-таблицы (путь даже и одноименные), эти таблицы будут независимы для каждого из подключений и будут автоматически уничтожены, как только соединение с БД будет прервано. Вот пример создания временной таблицы (отличие от предыдущего примера только в ключевом слове “temporary”):
create temporary table users7(fio, age, sex);
Создавая таблицу в любой другой СУБД, вы часто использовали “ограничения”, накладываемые на значения полей (unique, check, триггеры). Посмотрим, что же уцелело из этого набора в sqlite? Уцелело все. Во-первых, сохранилась концепция первичного ключа (такого поля или набора полей, которые гарантированно уникальны для любых записей в таблице). Если поле при создании помечено как primary key, то любая попытка внести в него дублирующиеся значения будет неудачной.
sqlite&glt; create table x1 (i int primary key);
sqlite&glt; insert into x1 values (1);
sqlite&glt; insert into x1 values (2);
sqlite&glt; insert into x1 values (2);
SQL error: column i is not unique
И даже есть возможность сказать, что значение первичного ключа будет назначаться не нами, а самой СУБД (старые добрые identity и
auto_increment). Обратите внимание в следующем примере на то, что поле первичного ключа объявляется как INTEGER (не INT).
sqlite&glt; create table table_c (id INT primary key autoincrement, fio varchar(100));
SQL error: AUTOINCREMENT is only allowed on an INTEGER PRIMARY KEY
sqlite&glt; create table table_d (id INTEGER primary key autoincrement, fio varchar(100));
sqlite&glt; insert into table_d (fio) values ('Bill');
sqlite&glt; insert into table_d (fio) values ('Mary');
sqlite&glt; select * from table_d;
1|Bill
2|Mary
В том случае, если при вставке записи мы не укажем значения некоторого поля, оно получит значение по умолчанию (DEFAULT). Этим значением может быть не только строка или число, но и ключевые слова: CURRENT_TIME, CURRENT_DATE, CURRENT_TIMESTAMP — это соответственно текущее время, текущая дата, текущая дата и время.
sqlite&glt; create table users5 (fio, now default current_timestamp);
sqlite&glt; insert into users5 (fio) values ('mary');
sqlite&glt; select * from users5;
mary|2008-01-15 14:26:47
Для того, чтобы созданная нами таблица работала быстро, нам нужны индексы. Sqlite позволяет нам создать две их разновидности (кроме первичных): обычные и уникальные. Если обычные индексы только ускоряют операции с данными (зависящие от полей, по которым построены индексы), то уникальные индексы запретят вам дублировать значения привязанных к ним полей. Есть два момента, когда вы можете создать индекс: либо на стадии определения таблицы, либо позже. Следующий пример показывает, как назначить полю fio уникальный индекс:
create table users4 (id integer primary key, fio varchar(100) unique);
insert into users4 (fio) values ('mary');
insert into users4 (fio) values ('mary');
SQL error: column fio is not unique
Или после того, как таблица была создана, вы можете добавить к ней как обычный, так и уникальный индекс. Важно при создании индекса назначить ему имя (в примере это idx_fio, unq_fio):
create index idx_fio on users(fio); создаем обычный индекс
sqlite> create unique index unq_fio on users(fio); и пример с уникальным индексом
sqlite> insert into users (fio) values ('Mark');
sqlite> insert into users (fio) values ('Mark');
SQL error: column fio is not unique
Индексы можно удалять, используя для этого команду “drop index имя_индекса”. Не важно, уникальный это индекс или обычный — главное — чтобы они были созданы с помощью “create index”. Создавая таблицу, вы можете наложить ограничения на значения полей (например, величина зарплаты сотрудника должна быть в диапазоне от $0 до $1000). Для этого используются CHECK ограничения. Есть два вида check: ограничения, накладываемые на одно поле, и ограничения, которые оперируют всеми полями в таблице одновременно. В следующем примере я создам таблицу с двумя “числовыми” полями. На первое из них будет наложено требование: значение поля должно быть более 100, для второго поля значение менее 200, и третье ограничение говорит, что сумма этих двух полей не должна превосходить 150. Условия CHECK проверяются всегда (как при добавлении новой записи, так и при редактировании существующей).
sqlite&glt; create table numbers (num_1 int check(num_1 &glt; 100), num_2 int check (num_2 &llt; 200), check (num_1 + num_2 &llt; 150));
sqlite&glt; insert into numbers values (200,100);
SQL error: constraint failed
sqlite&glt; insert into numbers values (110,30); теперь ограничения CHECK не нарушены
sqlite&glt; update numbers set num_1 = 400; пробуем обновить запись так, чтобы нарушить CHECK для всей таблицы
SQL error: constraint failed
И третий способ контролировать ввод данных в таблицы — использовать триггеры. Триггер — это процедура, которая вызывается всякий раз, когда значение в таблице меняется (добавление, удаление или правка записей). Триггер может выполнять сложные проверки для вносимых данных или выполнять изменения в смежных таблицах. Очевидно, что созданная нами таблица может нуждаться в корректировке: мы можем захотеть добавить парочку полей, поменять их имена, удалить поле. Неприятный сюрприз в том, что команда ALTER (стандартная SQL-инструкция правки таблицы) в sqlite реализована, мягко говоря, не полностью. Вы можете только переименовывать таблицы или добавлять к ним новые поля — например, так:
alter table users rename to people; переименовали таблицу users в people
alter table users add cash float; добавили новое поле — зарплата человека
Если же вы хотите сделать что-то посложнее, то единственный путь — создать еще одну таблицу в соответствии с новыми пожеланиями, скопировать в нее данные из предыдущей и затем удалить старую таблицу. Это не сложно, но, чтобы избежать глупых ошибок-опечаток, лучше использовать, например, SqliteMaestro. Там мастер изменения структуры таблиц сам сгенерирует и выполнит все эти рутинные шаги. Для удаления созданной таблицы используйте команду “drop table имя таблицы”. Создав несколько таблиц, вы захотите просмотреть их список и из каких полей они состоят. В первом случае вам поможет команда “.tables ШАБЛОН”. Она выведет имена всех таблиц в текущей базе данных (или только тех, что соответствуют шаблону, если вы его укажете). Для того, чтобы увидеть код, создавший таблицу, используйте команду “.schema ШАБЛОН”. В случае, если вы укажете значение шаблона, будет выведен код DDL, создающий ту таблицу, имя которой совпадает с этим шаблоном. Если же шаблон не указан, будет выведен код создания для абсолютно всех таблиц. Наверняка пригодится и команда, которая создает полный дамп содержимого базы данных “.dump”. Не забудьте только перед тем, как выполнить дамп базы, перенаправить поток вывода во внешний файл — например, так: “.output имя_файла”, — после чего вернуть вывод снова на экран поможет команда “.output stdout”. Роль команды dump для переноса базы данных с одного компьютера на другой не столь значительна, как для mysql или postgres. С момента выпуска первой версии sqlite в 2000 году уже прошли десятки раз, когда менялся внутренний формат файла для хранения содержимого базы данных. Хотя в большинстве своем каждая новая версия sqlite неплохо работает с файлами, созданными в предыдущей версии (но только в рамках одной “старшей версии”). Более того, формат хранения данных не зависит от разрядности компьютера (32 и 64 бита) порядка “старший байт-младший байт”. Фактически вы можете послать db-файл по электронной почте, будучи уверенным, что на другой стороне он прочитается без проблем. Если же у вас возникнут проблемы, используйте для переноса данных dump.
В следующий раз я продолжу и завершу рассказ о совместном использовании sqlite и google gears, а также покажу, как использовать sqlite на стороне веб-сервера.
black-zorro, black-zorro@tut.by.
Сетевые решения. Статья была опубликована в номере 02 за 2008 год в рубрике программирование
