миграция данных
Казалось бы, что наличие уже существующей информационной системы (ИС) должно упростить и ускорить разработку новой ИС на основе старой, но на практике все обычно происходит с точностью до наоборот. Во первых, так как возникла необходимость в создании новой ИС, то это чаще всего означает, что ранее созданная ИС была создана с существенными изъянами и изобилует разнообразными ошибками.
Обычно, ото ИС, которая писалась на протяжении многих лет различными разработчиками. При этом проектная документация чаще всего находится в жалком состоянии, а порой и вообще отсутствует. «Настоящие» программисты не пишут документации, а тем более не документируют программный код. Зачем, ведь все просто и прозрачно. Тем не менее, когда смотришь на свой же код спустя пол года, то довольно сложно разобраться, что же там делалось. Особенно, если за это время было сделано несколько других проектов.
Мало того, каждый новый разработчик обычно не утруждает себя тщательным изучением ни кода, ни архитектуры системы. Так как сроки всегда «горят», то просто пишутся «примочки» для временного решения насущной проблемы. В результате получается «каша», состоящая из множества разношерстных модулей и каким то чудесным образом состыкованных технологий, которые порой не совместимы друг с другом. Положение усугубляется использованием устаревших систем управления базами данных (СУБД) для хранения данных, например dbase-III, FoxPro или Clipper. Отсутствие понятия транзакции, а при неумелом проектировании и ссылочной целостности приводит к многочисленным нарушениям целостности данных. Можно считать, что повезло, если в старой системе использовалась СУБД, иногда встречаются творения, использующие текстовые файлы для хранения данных (при миграции одной из таких систем автору пришлось писать специальный драйвер для доступа к такой базе данных).
Пожалуй, единственным положительным моментом является накопленный опыт по формированию требований к вновь разрабатываемой ИС. С другой стороны, опыт общения со старой системой может стать существенным тормозом при внедрении нового продукта. Чаще всего это возникает из-за различий построения визуального интерфейса и используемых функциональных клавиш для выполнения некоторых операций. Так, часть функциональных клавиш может быть зарезервирована операционной системой для выполнения некоторых действий. Типичным примером является применение клавиши “Enter” для перехода к следующему элементу редактируемой формы в старых ИС под DOS. В графических интерфейсах обычно для этих целей применяется клавиша “Tab”.
В результате, мы получаем жесткое противодействие со стороны пользователей при внедрении новой версии продукта. Конечно, можно эмулировать поведение UI (User Interface) интерфейса старой системы, но делать это лучше всего опционально. Т.е. ввести возможность настройки поведения системы в модуле конфигурирования ИС, а по умолчанию использовать настройки соответствующие текущей операционной системе. В противном случае, вновь разработанный продукт будет труден в освоении новыми пользователями, которые ожидают поведения программы в соответствии с текущими стандартами.
Что же касается работы с хранимыми данными старой системы, то тут положение еще хуже. Наиболее тяжелые последствия будет иметь решение руководства использовать часть модулей старой системы. Например, когда перед нами стоит задача разработать новую версию складского учета, а решением остальных задач (бухучет и т.д.) пока будет заниматься старая версия ИС. В данном режиме работы встает проблема миграции данных в «реальном» режиме времени. Накладные расходы, по поддержанию работы всех модулей в целом могут превысить затраты на разработку новой версии всех модулей. Причем затраты могут отличаться на порядки, с учетом возможных потерь от недочетов старой системы и ошибок при обмене и преобразовании данных. Так что следует тщательно оценить состояние старой ИС и целесообразности данного шага. И что самое интересное, на практике данная проблема обычно не затрагивается, вплоть до возникновения: “Вот создадим новую систему, а потом и будем заниматься стыковкой с другим программным обеспечением и мигрировать данные”.
Но вот настает момент, когда проблема назрела, новая система написана, и пора заниматься преобразованием и перекачкой данных в новую систему. Анализируя опыт мигрирования данных большого количества разнообразных информационных систем можно выделить типовую процедуру миграции данных, которая включает в себя:
. Анализ форматов данных структуры старой базы данных и новой, подготовка плана миграции и преобразования данных.
. Определение взаимосвязей между таблицами (иерархии объектов).
. Определение последовательности закачки данных в соответствии с иерархией зависимостей. Иногда, но не всегда (например, когда новая версия базы данных уже находится в эксплуатации) можно не учитывать взаимосвязи, а просто отключить все внешние ключи перед миграцией и
пересоздать их после завершения всех манипуляций с данными.
. Выполнение скрипта по изменению объектов в новой версии базы данных.
. Непосредственная перекачка данных с необходимыми преобразованиями “на лету”.
. Выполнение скрипта для восстановления отключенных индексов, дополнительных преобразований и т.д. после завершения процедуры миграции данных.
Самым простым вариантом обычно является создание промежуточной программы. Она должна связываться с исходной и целевой базами данных, и выполнять нужные преобразования.

Рис. 1. Вариант с промежуточной программой для миграции данных
Существенным недостатком данного решения может стать сетевая нагрузка при передаче данных. Если объем данных существенен, то сетевой обмен может сильно сказаться на производительности.
Более выгодным решением может быть предварительная загрузка старых данных во временные таблицы новой СУБД. Современные СУБД (например, Oracle) обычно содержат специальные утилиты, которые позволяют производить очень быструю закачку внешних данных различных форматов. Непосредственно модуль миграции пишется встроенными в СУБД процедурными языками (например, PL/SQL или java). Можно существенно повысить скорость выполнения процедуры миграции за счет того, что встроенные языки программирования работают в “родной” среде, оптимизированы под целевую СУБД и нет накладных расходов на обмен данными по сети.
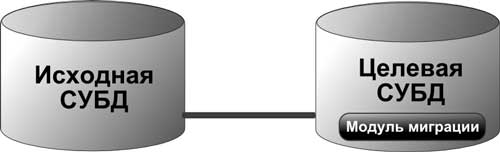
Рис. 2. Вариант миграции данных средствами СУБД
Из практического опыта написания таких программ хочется обратить внимание на использование пакетных SQL методов, которые поддерживаются большинством СУБД и языками программирования (например, методы addBatch() и executeBatch() в java). Выполнение одного оператора добавления INSERT или обновления UPDATE для массива данных пачками по 100 - 200 записей дает существенный выигрыш производительности, в сравнении с выполнением данного оператора поочередно в цикле для каждой записи.
Сергей Бердачук
Обычно, ото ИС, которая писалась на протяжении многих лет различными разработчиками. При этом проектная документация чаще всего находится в жалком состоянии, а порой и вообще отсутствует. «Настоящие» программисты не пишут документации, а тем более не документируют программный код. Зачем, ведь все просто и прозрачно. Тем не менее, когда смотришь на свой же код спустя пол года, то довольно сложно разобраться, что же там делалось. Особенно, если за это время было сделано несколько других проектов.
Мало того, каждый новый разработчик обычно не утруждает себя тщательным изучением ни кода, ни архитектуры системы. Так как сроки всегда «горят», то просто пишутся «примочки» для временного решения насущной проблемы. В результате получается «каша», состоящая из множества разношерстных модулей и каким то чудесным образом состыкованных технологий, которые порой не совместимы друг с другом. Положение усугубляется использованием устаревших систем управления базами данных (СУБД) для хранения данных, например dbase-III, FoxPro или Clipper. Отсутствие понятия транзакции, а при неумелом проектировании и ссылочной целостности приводит к многочисленным нарушениям целостности данных. Можно считать, что повезло, если в старой системе использовалась СУБД, иногда встречаются творения, использующие текстовые файлы для хранения данных (при миграции одной из таких систем автору пришлось писать специальный драйвер для доступа к такой базе данных).
Пожалуй, единственным положительным моментом является накопленный опыт по формированию требований к вновь разрабатываемой ИС. С другой стороны, опыт общения со старой системой может стать существенным тормозом при внедрении нового продукта. Чаще всего это возникает из-за различий построения визуального интерфейса и используемых функциональных клавиш для выполнения некоторых операций. Так, часть функциональных клавиш может быть зарезервирована операционной системой для выполнения некоторых действий. Типичным примером является применение клавиши “Enter” для перехода к следующему элементу редактируемой формы в старых ИС под DOS. В графических интерфейсах обычно для этих целей применяется клавиша “Tab”.
В результате, мы получаем жесткое противодействие со стороны пользователей при внедрении новой версии продукта. Конечно, можно эмулировать поведение UI (User Interface) интерфейса старой системы, но делать это лучше всего опционально. Т.е. ввести возможность настройки поведения системы в модуле конфигурирования ИС, а по умолчанию использовать настройки соответствующие текущей операционной системе. В противном случае, вновь разработанный продукт будет труден в освоении новыми пользователями, которые ожидают поведения программы в соответствии с текущими стандартами.
Что же касается работы с хранимыми данными старой системы, то тут положение еще хуже. Наиболее тяжелые последствия будет иметь решение руководства использовать часть модулей старой системы. Например, когда перед нами стоит задача разработать новую версию складского учета, а решением остальных задач (бухучет и т.д.) пока будет заниматься старая версия ИС. В данном режиме работы встает проблема миграции данных в «реальном» режиме времени. Накладные расходы, по поддержанию работы всех модулей в целом могут превысить затраты на разработку новой версии всех модулей. Причем затраты могут отличаться на порядки, с учетом возможных потерь от недочетов старой системы и ошибок при обмене и преобразовании данных. Так что следует тщательно оценить состояние старой ИС и целесообразности данного шага. И что самое интересное, на практике данная проблема обычно не затрагивается, вплоть до возникновения: “Вот создадим новую систему, а потом и будем заниматься стыковкой с другим программным обеспечением и мигрировать данные”.
Но вот настает момент, когда проблема назрела, новая система написана, и пора заниматься преобразованием и перекачкой данных в новую систему. Анализируя опыт мигрирования данных большого количества разнообразных информационных систем можно выделить типовую процедуру миграции данных, которая включает в себя:
. Анализ форматов данных структуры старой базы данных и новой, подготовка плана миграции и преобразования данных.
. Определение взаимосвязей между таблицами (иерархии объектов).
. Определение последовательности закачки данных в соответствии с иерархией зависимостей. Иногда, но не всегда (например, когда новая версия базы данных уже находится в эксплуатации) можно не учитывать взаимосвязи, а просто отключить все внешние ключи перед миграцией и
пересоздать их после завершения всех манипуляций с данными.
. Выполнение скрипта по изменению объектов в новой версии базы данных.
. Непосредственная перекачка данных с необходимыми преобразованиями “на лету”.
. Выполнение скрипта для восстановления отключенных индексов, дополнительных преобразований и т.д. после завершения процедуры миграции данных.
Самым простым вариантом обычно является создание промежуточной программы. Она должна связываться с исходной и целевой базами данных, и выполнять нужные преобразования.
Рис. 1. Вариант с промежуточной программой для миграции данных
Существенным недостатком данного решения может стать сетевая нагрузка при передаче данных. Если объем данных существенен, то сетевой обмен может сильно сказаться на производительности.
Более выгодным решением может быть предварительная загрузка старых данных во временные таблицы новой СУБД. Современные СУБД (например, Oracle) обычно содержат специальные утилиты, которые позволяют производить очень быструю закачку внешних данных различных форматов. Непосредственно модуль миграции пишется встроенными в СУБД процедурными языками (например, PL/SQL или java). Можно существенно повысить скорость выполнения процедуры миграции за счет того, что встроенные языки программирования работают в “родной” среде, оптимизированы под целевую СУБД и нет накладных расходов на обмен данными по сети.
Рис. 2. Вариант миграции данных средствами СУБД
Из практического опыта написания таких программ хочется обратить внимание на использование пакетных SQL методов, которые поддерживаются большинством СУБД и языками программирования (например, методы addBatch() и executeBatch() в java). Выполнение одного оператора добавления INSERT или обновления UPDATE для массива данных пачками по 100 - 200 записей дает существенный выигрыш производительности, в сравнении с выполнением данного оператора поочередно в цикле для каждой записи.
Сергей Бердачук
Сетевые решения. Статья была опубликована в номере 02 за 2007 год в рубрике sysadmin
