все о netgraph: альтернативной сетевой подсистеме ядра FreeBSD
что такое Netgraph*?
Представьте следующую ситуацию: вы разрабатываете маршрутизатор TCP/IP, основанный на FreeBSD. Продукт должен поддерживать синхронные последовательные WAN-линии, то есть выделенные цифровые каналы, работающие на скоростях до T1, где используется инкапсуляция HDLC. Вы должны поддерживать следующие протоколы для передачи IP-пакетов через кабель:
- IP-пакеты, передаваемые поверх HDLC (простейший путь для транспортировки IP);
- IP пакеты, передаваемые поверх "Cisco HDLC" (по существу, пакеты дополнены двухбайтным полем Ethertype, и периодически посылаются keep-alive пакеты);
- IP-пакеты, передаваемые поверх Frame Relay (Frame Relay предоставляет до 1000 виртуальных каналов «точка-точка» поверх одой кабельной сети).
- IP в инкапсуляции RFC 1490 поверх frame relay (RFC 1490 определяет способ передачи нескольких протоколов через одно соединение и он часто используется совместно Frame Relay);
- PPP поверх HDLC;
- PPP поверх Frame Relay;
- PPP в инкапсуляции RFC 1490 поверх Frame Relay;
- PPP поверх ISDN.
Можно даже предположить, что вам придется поддерживать Frame Relay поверх ISDN!
На Рисунке 1 показаны все возможные комбинации.
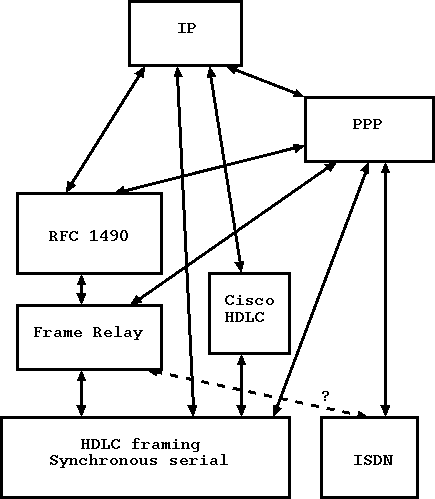
Рисунок 1. Способы передачи IP поверх последовательных синхронных и ISDN WAN-соединений.
Эта ситуация была показана Джулианом Элисчером (Julian Elischer) и мной в 1996, когда мы работали в компании Whistle InterJet. В то время во FreeBSD имелась очень ограниченная поддержка последовательного синхронного оборудования и протоколов. Мы думали использовать OEMing от Emerging Technologies, но вместо этого решили реализовать это сами.
Ответом был netgraph. Netgraph - это сетевая подсистема в ядре, следующая принципу UNIX достижения мощности посредством комбинации простых инструментов, каждый их которых предназначен для выполнения одной, вполне определенной задачи. Основная идея проста: есть узлы (nodes), инструменты и ребра (edges), которые соединяют пару узлов (отсюда и "граф" в "netgraph"). Пакеты данных идут в двух направлениях вдоль ребер от узла к узлу. Когда узел получает пакет данных, он обрабатывает его, и затем (обычно) отправляет его другому узлу. Обработка может заключаться в простейшем добавлении/удалении заголовков, а может быть и более сложной, или включать другие компоненты системы. Netgraph напоминает потоки (Streams) в System V, но он разработан более гибким и производительным.
Netgraph оказался очень полезным для работы в сети, и сейчас он используется в Whistle InterJet для всех указанных выше комбинаций протоколов (за исключением Frame Relay поверх ISDN) плюс обычный PPP поверх асинхронных последовательных интерфейсов (таких, как модемы и терминальные адаптеры) и PPTP, поддерживающий шифрование. Во всех этих протоколах данные полностью обрабатываются в ядре. В случае PPP, пакеты согласования (negotiation) обрабатываются отдельно в пользовательском режиме (смотрите порт FreeBSD для mpd).
узлы и ребра
Глядя на рисунок выше, очевидно, что должны быть узлы и ребра. Менее очевиден факт, что узел может иметь определенное число подключений к другим узлам. Например, вполне возможно иметь одновременно IP, IPX, и PPP в инкапсуляции RFC 1490; конечно, мультиплексирование - это та задача, для которой и нужен RFC 1490. В этом случае нужно три ребра подключить к узлу RFC 1490, одно для каждого стека протоколов. Нет требований, чтобы данные следовали строго в определенном направлении, и нет ограничений на действия, которые узел выполняет с пакетом. Узел может быть источником/потребителем данных, например, если он связан с аппаратной частью, или он может просто добавлять/удалять заголовки, мультиплексировать и т. п.
Узлы netgraph существуют в ядре и полупостоянно. Обычно узел существует, пока он подключен к какому либо другому узлу, однако некоторые узлы - постоянные, например, узлы, связанные с аппаратной частью; когда число ребер уменьшается до нуля, аппаратное устройство выключается. Поскольку узлы существуют в ядре, они не связаны с каким либо определенным процессом.
управляющие сообщения
Эта картина все еще слишком упрощенная. В реальной жизни узел нужно конфигурировать, запрашивать его состояние и т. д. Например, PPP - сложный протокол с большим количеством опций. Для этого в netgraph определены управляющие сообщения (control messages). Управляющее сообщение - это "внешнее управление". Вместо следования от узла к узлу (как это делают пакеты данных), управляющие сообщения посылаются асинхронно и непосредственно от одного узла к другому. Два узла могут быть не связаны (даже через другие узлы). Для обеспечения этого в netgraph существует простая схема адресации - узел можно идентифицировать, используя простую ASCII-строчку.
Управляющие сообщения - это просто структуры Си с фиксированным заголовком (структура ng_mesg) и переменной областью данных. Есть несколько управляющих сообщений, которые должны понимать все узлы; они называются общими управляющими сообщениями (generic control messages) и реализованы в базовой системе. Например, узлу можно указать разрушить себя или создать/разрушить ребро. Узлы могут также иметь свои собственные управляющие сообщения, зависящие от типа. Каждый тип узла, определяющий свои собственные управляющие сообщения, должен иметь уникальное значение typecookie. Комбинация полей typecookie и command в заголовке управляющего сообщения определяет, как его интерпретировать.
На управляющие сообщения часто идут ответы в виде ответных контрольных сообщений (reply control message). Например, чтоб узнать состояние узла или статистику, вы можете послать управляющее сообщение "get status"; узел пошлет вам ответ (который идентифицируется значением token, скопированным из исходного запроса), содержащий запрошенную информацию в поле данных. Заголовок ответного управляющего сообщения обычно такой же, как исходный заголовок, но выставлен флаг reply flag.
Netgraph предоставляет способ преобразования этих структур в строки ASCII и обратно для упрощения взаимодействия с человеком.
крючки (hooks)
На самом деле в netgraph ребра не существуют сами по себе. Ребро - это просто комбинация двух крючков (hooks), по одному от каждого узла. Крючок узла определяет, как узел может быть подключен. Каждый крючок имеет уникальное, статически определенное имя, которое часто отражает его цель. Имя имеет значение только в контексте данного узла; два узла могут иметь крючки с одинаковым названием.
Например, рассмотрим узел Cisco. Cisco HDLC - это очень простая схема мультиплексирования протоколов посредством дополнения каждого кадра спереди полем Ethertype перед передачей на физический уровень. Cisco HDLC поддерживает одновременную передачу IP, IPX, AppleTalk, и т. д. Таким образом, узел netgraph для Cisco HDLC определяет крючки, называемые inet, atalk, and ipx. Эти крючки предназначены для подключения к соответствующим вышележащим стекам протоколов. Узел также определяет крючок, называемый downstream, который подключается к нижележащему уровню, например узлу, связанному с синхронной последовательной платой. К пакетам, получаемым через крючки inet, atalk и ipx, добавляется два байта заголовка, и затем они отправляются через крючок downstream. Наоборот, из пакетов, полученных через downstream, удаляется заголовок, и они отправляются вверх через крючок, соответствующий протоколу. Узел также обрабатывает периодические пакеты "tickle" и запросы, определенные протоколом Cisco HDLC.
Крючки всегда либо подключены, либо не подключены; операция подключения или отключения пары крючков атомарная. Когда пакет посылается через крючок, которые не подключен, он отбрасывается.
некоторые примеры типов узлов
Некоторые типы узлов достаточно очевидны, такие, как Cisco HDLC. Другие менее очевидны, но предоставляют некоторые интересные функции, например, возможность обращаться непосредственно к устройству или открытому сокету внутри ядра.
Несколько примеров типов узлов, реализованных на настоящий момент во FreeBSD. Все эти типы узлов описаны в соответствующих страницах справочного руководства man.
Тип узла echo: ng_echo. Этот тип узла принимает подключения через любой крючок. Любые получаемые пакеты просто посылаются назад через тот же крючок. Любые не общие управляющие сообщения также возвращаются назад в виде ответов.
Тип узла discard: ng_disc. Этот тип узла принимает подключения через любой крючок. Любые пакеты данных и контрольные сообщения молча отбрасываются.
Тип узла tee: ng_tee. Этот тип узла похож на двунаправленную версию утилиты tee(1). Он копирует данные, проходящие через него в любом направлении (right или left), и полезен для отладки. Пакеты, получаемые через right, посылаются через left и копия шлется через right2left; аналогично для пакетов идущих от left к right. Пакеты, получаемые через right2left, посылаются через left и пакеты получаемые через left2right, отправляются через right.
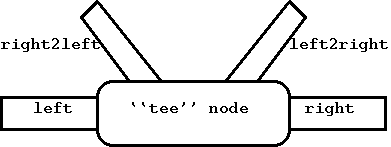
Рисунок 2. Тип узла tee.
Тип узла interface: ng_iface.
Этот тип узла - одновременно узел netgraph и системный интерфейс PPP. Он имеет (пока) три крючка, называемые "inet", "atalk" и "ipx". Эти крючки соответствуют стекам протоколов IP, AppleTalk и IPX соответственно. Первый раз, при создании интерфейсного узла, интерфейс ng0 показывается в выводе ifconfig’a. Вы можете прописать на этом интерфейсе адрес, как на другом PPP-интерфейсе, пинговать удаленную сторону, и т. д. Конечно, узел должен быть подключен к чему либо, иначе пакеты ping будут выходить через крючок inet и исчезать.
К сожалению, FreeBSD в настоящий момент не поддерживает удаление интерфейсов, таким образом, однажды создавшись, узел типа ng_iface будет существовать до следующей перезагрузки (однако это будет скоро исправлено).
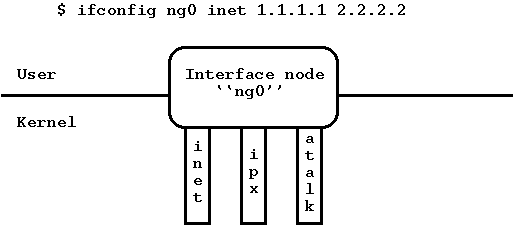
Рисунок 3. Тип узла interface.
Тип узла TTY: ng_tty. Этот тип узла - одновременно узел netgraph и дисциплина асинхронной последовательной линии (line discipline). Вы создаете узел установкой дисциплины линии NETGRAPHDISC на последовательной линии. Узел имеет один крючок, называемый hook. Пакеты, получаемые через hook передаются (как последовательные байты) через соответствующее последовательное устройство; данные, получаемые от устройства, формируются в пакеты и посылаются через hook. Нормальное чтение и запись в последовательную линию блокируются.
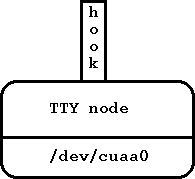
Рисунок 4. Тип узла TTY.
Тип узла socket: ng_socket. Этот тип узла очень важен, поскольку позволяет программам пользовательского режима взаимодействовать с системой netgraph. Каждый узел - одновременно узел netgraph и пара сокетов из семейства PF_NETGRAPH. Узел создается, когда программа пользовательского режима создает соответствующий сокет через системный вызов socket. Один сокет используется для передачи и получения пакетов данных, а второй для контрольных сообщений. Этот узел поддерживает крючки с произвольными именами, например "hook1", "hook2" и т. д.
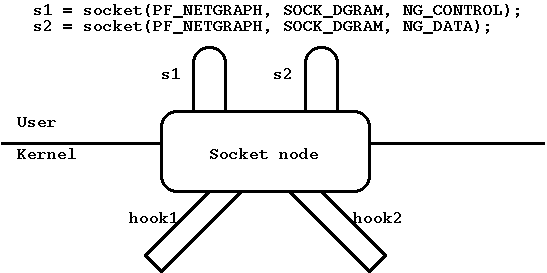
Рисунок 5. Тип узла socket.
Тип узла BPF: ng_bpf. Этот тип узла выполняет сравнение с шаблоном и фильтрацию пакетов так, как будто они следуют через bpf.
Тип узла ksocket: ng_ksocket. Этот тип узла противоположен ng_socket. Каждый узел одновременно является сокетом, полностью расположенном в ядре. Данные, получаемые узлом, записываются в сокет и наоборот. Нормальные bind(), connect(), и т. д. операции осуществимы вместо контрольных сообщений. Этот тип узла полезен для туннелирования пакетов через сокет (например, туннелирование IP поверх UDP).
Тип узла ethernet: ng_ether. Если вы скомпилировали ваше ядро с options NETGRAPH, то каждый интерфейс Ethernet также является узлом netgraph с таким же именем, как интерфейс. Каждый узел имеет два крючка "orphans" и "divert"; только один крючок может быть подключен одновременно. Если "orphans" подключен, то устройство продолжает работать нормально, за исключением того, что все пакеты Ethernet с неизвестным или неподдерживаемым типом, доставляются через этот крючок (в нормальном режиме эти пакеты просто отбрасываются). Когда подключен крючок "divert" - все входящие пакеты доставляются через этот крючок. Пакет, полученный через любой из этих крючков, передается в кабель. Все пакеты - "сырые" кадры Ethernet со стандартным 14-байтным заголовком (но без контрольной суммы). Этот тип узла полезен, например для PPP поверх Ethernet (PPPoE).
Синхронные драйверы: ar и sr. Если вы скомпилировали ваше ядро с options NETGRAPH, то драйверы ar(4) и sr(4) перестанут работать в нормальном режиме и вместо этого будут работать как постоянные узлы netgraph (с таким же именем, как название устройства). Сырые кадры HDLC могут быть прочитаны и записаны через крючок "rawdata".
метаинформация
В некоторых случаях пакеты данных могут иметь связанную метаинформацию, которую нужно передать вместе с пакетом. Хотя это редко используется, netgraph предоставляет механизм, чтобы сделать это. Пример метаинформации - приоритеты: некоторые пакеты могут иметь более высокий приоритет, чем другие. Типы узлов могут определять свою собственную, специфичную метаинформацию, и netgraph для этой цели определяет структуру ng_meta. Метаинформация не воспринимается базовой системой netgraph.
адресация узлов netgraph
Каждый узел netgraph адресуем через строку ASCII, называемую адрес узла (node address) или путь (path). Адрес узла используется только для отправки контрольных сообщений.
Многие узлы имеют имена. Например, узел, ассоциированный с устройством, будет обычно иметь такое же имя, как устройство. Когда узел имеет имя, он всегда может быть адресован, используя абсолютный адрес, состоящий из имени устройства и двоеточия. Например, если вы создали интерфейсный узел, названный "ng0", его адрес будет "ng0:".
Если узел не имеет имени, вы можете составить его из уникального номера ID узла, заключив его в квадратные скобки (каждый узел имеет уникальный номер ID). Таким образом, если узел ng0: имеет номер ID 1234, тогда "[1234]:" так же является адресом этого узла.
Наконец, адрес ".:" или "." всегда указывает на локальный узел (источник).
Относительная адресация также возможна когда два узла соединены опосредовано. Относительный адрес использует имена последовательных крючков в пути от одного узла к другому. Рассмотрим рисунок 6.
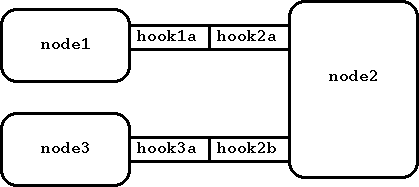
Рисунок 6. Простая конфигурация узлов.
Если узел node1 хочет послать контрольное сообщение узлу node2, он может использовать адрес ".:hook1a" или просто "hook1a". Для обращения к узлу node3 он может использовать адрес ".:hook1a.hook2b" или просто "hook1a.hook2b". Аналогично, узел node3 может обратиться к узлу node1, используя адрес ".:hook3a.hook2a" или просто "hook3a.hook2a".
Относительные и абсолютные адреса можно сочетать, например, "node1:hook1a.hook2b" будет указывать на узел node3.
использование Netgraph
Netgraph поставляется с утилитами командной строки и пользовательской библиотекой, которые позволяют взаимодействовать с системой ядра netgraph. Необходимы привилегии root для работы с netgraph из пользовательской режима.
Есть две утилиты командой строки для взаимодействия с netgraph: nghook и ngctl. nghook очень проста: она подключается к любому неподключенному крючку любого узла и позволяет вам передавать и получать пакеты данных через стандартный ввод и стандартный вывод. Вывод может быть дополнительно декодирован в читаемый человеком формат hex/ASCII. В командной строке вы указываете абсолютный адрес узла и имя крючка.
Например, если ваше ядро собрано с options NETGRAPH и вы имеете сетевой интерфейс fxp0, следующая команда перенаправит все сетевые пакеты получаемые картой и выведет их через стандартный вывод в формате hex/ASCII:
ngctl - более функциональная программа, которая позволяет вам делать практически все с netgraph из командной строки. Она работает в пакетном или интерактивном режиме, и поддерживает несколько команд, которые выполняют интересующую работу, в том числе:
- connect - соединить пару крючков для объединения двух узлов;
- list - вывести список всех узлов в системе;
- mkpeer - создать узел и подключить его к существующему узлу;
- msg - послать форматированное ASCII-сообщение узлу;
- name - назначит узлу имя;
- rmhook - отключить два подключенных крючка;
- show - показать информацию об узле;
- shutdown - удалить/сбросить узел, разрушив все подключения;
- status - получить статус узла в удобочитаемом виде;
- types - показать типы установленных узлов;
- quit - выйти из программы.
Эти команды могут быть объединены в скрипт, который делает что-то полезное. Например, предположим, что у вас есть две частные сети, которые разделены, но обе подключены к интернету через машины с FreeBSD. Сеть A имеет внутренние адреса из диапазона 192.168.1.0/24 и внешний IP адрес 1.1.1.1, в то время как сеть B имеет адреса 192.168.2.0/24 и внешний адрес 2.2.2.2. Используя Netgraph, вы можете легко сделать UDP для IP-трафика между двумя частными сетями. Пример скрипта, который это может сделать (его можно также найти в /usr/share/examples/netgraph):
Далее рассмотрим, как можно работать с ngctl в интерактивном режиме. Пользовательский ввод выделен жирным.
Запустим ngctl в интерактивном режиме. Будет показан список доступных команд.
ngctl создает при запуске узел типа ng_socket. Это наш локальный узел netgraph, который используется для взаимодействия с другими узлами в системе. Посмотрим на него. Мы видим, что ngctl назначил ему имя "ngctl652" и его тип "socket", номер ID 45 и он имеет ноль подключенных крючков, т. е. он не подключен к другим узлам.
Теперь мы создадим узел "tee" и подключим его к локальному узлу. Мы подключим крючок "right" узла "tee" к крючку "myhook" на локальном узле. Мы можем использовать любое имя для нашего крючка, так как узел типа ng_socket поддерживает крючки с произвольными именами. После этого снова посмотрим на наш локальный узел, чтобы убедиться, что он имеет безымянного соседа типа "tee".
Аналогично, если мы посмотрим на вывод узла tee, мы увидим, что он подключен к нашему локальному узлу через крючок "right". Узел "tee" все еще безымянный, но мы можем его указать, используя абсолютный адрес "[46]:" или относительный адрес ".:myhook" или "myhook".
Теперь назначим ему имя и убедимся, что можем по нему обратиться к этому узлу.
Теперь подключим узел Cisco HDLC к другой стороне узла "tee" и снова проверим узел "tee". Мы подключимся к крючку "downstream" узла Cisco HDLC, как будто бы узел tee соответствует подключению к WAN. Cisco HDLC слева (крючек "left") от узла tee, наш локальный узел справа (крючок "right") от узла tee.
Эй, что это такое?! Выглядит так, будто мы получаем какие то пакеты данных через наш крючок "myhook". Узел Cisco каждые 10 секунд посылает периодические пакеты keep-alive. Эти пакеты проходят через узел tee (слева направо от крючка "left" к крючку "right") и принимаются крючком "myhook", где ngctl показывает их в консоли.
Теперь посмотрим список всех узлов, существующих в системе. Заметим, что два наших интерфейса Ethernet также показаны, поскольку это постоянные узлы и мы собирали ядро с options NETGRAPH.
OK, давайте выключим (то есть удалим) узел Cisco HDLC, таким образом мы остановим получение данных.
Теперь, давайте посмотрим статистику узла tee. Мы пошлем управляющее сообщение и немедленно получим ответ. Команда и ответ конвертируются в/из ASCII автоматически с помощью ngctl, так как управляющие сообщение - это двоичная структура.
Ответ - это просто строковая версия структуры ng_tee_stats, возвращаемой в ответном управляющем сообщении (эта структура определена в ng_tee.h). Мы видим, что три кадра (и 72 байта) прошли через узел слева направо. Каждый кадр был скопирован и отправлен через крючок "left2right" (но поскольку этот крючок не подключен, эти кадры были отброшены).
OK, теперь проиграемся с узлом ng_ksocket.
Мы создали в ядре TCP-сокет, используя узел ng_ksocket, и подключили его к сервису "daytime" на локальной машине, который возвращает текущее время. Как мы узнали, что нужно использовать "inet/127.0.0.1:13" в качестве аргумента команды "connect"? Это описано в странице справочного руководства man ng_ksocket(8).
OK, поигрались и хватит.
libnetgraph
Существует так же пользовательская библиотека libnetgraph для использования в программах netgraph. Она предоставляет много полезных вызовов, которые описаны в справочном руководстве man. Пример использования их можно посмотреть в исходном коде /usr/src/usr.sbin/ngctl.
планы на будущее
Работа над Netgraph все еще продолжается, желание помочь приветствуется! Есть несколько идей по поводу будущей работы.
типы узлов
Еще много типов узлов не написано:
- узлы типа "slip", которые будут реализовывать протокол SLIP. Это должно быть достаточно легко, и, возможно, скоро будет сделано;
- больше узлов сжатия и шифрования PPP, которые могут быть подключены к узлу ng_ppp, например, сжатие Deflate для PPP, 3DES-шифрование PPP и т. д.;
- реализация ipfw как узла netgraph;
- реализация динамического пакетного фильтра (DPF) как узла netgraph. DPF - это разновидность высокоскоростной, компилирующей налету (JIT compiling) версии BPF;
- общий узел типа "mux", где каждый крючок может быть настроен на добавление/удаление определенныого заголовка из пакетов.
Во FreeBSD сейчас имеется четыре реализации PPP: sppp, pppd, ppp, и порт MPD. Это достаточно глупо. Используя netgraph, это может быть объединено в один демон, работающий в пользовательском режиме, который будет выполнять все согласования и настройки, в то время как маршрутизация данных будет полностью происходить в ядре, через узлы ng_ppp. Это позволит объединить гибкость и удобство настройки демонов, работающих в пользовательском режиме, со скоростью работы в ядре. Сегодня MPD - единственная реализация, которая полностью основана на netgraph, но есть планы также переработать ppp;
- маршрутизирующий тип узлов. Каждый подключенный крючок соответствует маршруту назначения, например комбинации адреса и маски. Маршруты могут изменяться через управляющие сообщения;
- узел, реализующий пакетный фильтр с сохранением состояния (stateful firewall/NAT, замена для ipfw и/или ipfirewall);
- типы узлов для ограничения полосы пропускания и/или ее учета;
- добавление поддержки VLAN к существующим узлам Ethernet.
перевод управляющих сообщений в ASCII
Не все типы узлов, которые определяют свои собственные управляющие сообщения, поддерживают преобразование между двоичным видом и ASCII. Одна из задач - завершить эту работу для узлов, для которых это еще не сделано.
управление потоком
Одна из проблем, к которой возможно придется обратиться - это управление потом. Сейчас когда вы посылаете пакет данных, если конечный получатель узла не может принять его из-за переполнения очереди передачи или по другой причине, все что можно сделать - это отбросить пакет и вернуть ENOBUFS. Возможно, мы сможем определить новый код возврата ESLOWDOWN или что-то, что будет означать "пакет данных не отброшен; очередь полна; уменьшите скорость и попробуйте позже." Другой вариант - определить типы метаинформации, эквивалентные XOFF (остановить передачу) и XON (возобновить передачу).
чистка кода
Netgraph - объектно-ориентированный, но преимущества объектно-ориентированной архитектуры должны использоваться более полно без ущерба для производительности. Пока слишком много видимых полей в структурах, которые не должны быть доступны, и т. д., много также и других разных недоработок.
Также, страницы man для всех узлов (например, ng_tee(8)) в действительности должны находиться в разделе 4, а не 8.
выключение по цепочке
Было бы удобно сделать новое общее управляющее сообщение NGM_ELECTROCUTE, которое, если послать его узлу, выключит узел вместе со всеми узлами, связанными с ним непосредственно или через другие узлы. Это позволит выполнить быструю очистку сложного графа в netgraph одним ударом. В дополнение можно сделать новую опцию сокета (см. setsockopt(2)) которую нужно установить для сокета ng_socket, чтобы при его закрытии автоматически посылалось сообщение NGM_ELECTROCUTE.
Вместе две эти вещи позволят более надежно избежать в netgraph "утечку узлов".
обнаружение бесконечных петель
В базовую систему netgraph несложно включить "обнаружение бесконечных петель". Каждый узел должен иметь свой закрытый счетчик. Счетчик должен увеличиваться перед каждым обращением к методу rcvdata() данного узла, и уменьшаться потом. Если счетчик достиг нереально большого значения, мы считаем, что обнаружена бесконечная петля (и избегаем паники ядра).
другие сумасшедшие идеи
Теоретически, сетевая подсистема BSD может быть полностью заменена на netgraph. Конечно, скорее всего, это никогда не случится, но это хороший мысленный эксперимент. Каждое сетевое устройство должно быть постоянным узлом netgraph (как устройства Ethernet). Вверху каждого устройства Ethernet должен быть мультиплексор Ethertype. К нему должны быть подключены узлы IP, ARP, IPX, AppleTalk и т. д. Узел IP должен быть просто мультиплексором протокола IP, над которым должны находиться узлы TCP, UDP, и т. д. Узлы TCP и UDP должны, наконец, иметь узлы, похожие на сокеты сверху. И т. д., и т. д.
Фантазируем дальше: можно даже сделать все устройства в виде узлов netgraph. Реализовать преобразование между ioctl и управляющими сообщениями. А как вам идея обращаться напрямую к вашему SCSI-диску через ngctl(8)? Возможна и полная интеграция между netgraph и devfs.
Узел netgraf также являющийся слоем VFS? Файловая система в виде пространства узлов netgraph?
Если NFS может работать поверх UDP, это может работать поверх netgraph. Можно будет иметь диски NFS, удаленно смонтированные через ATM, или просто сделать NFS поверх чистого Ethernet без посредника в виде UDP.
Интересна идея программируемых типов узлов, чья реализация зависит от конфигурации, с использованием некой разновидности псевдокода.
Наверняка есть еще много сумасшедших идей, до которых мы еще не додумались :). Может быть ВЫ нам поможете?
* в статье описывается netgraph в 4-й ветке FreeBSD. В 5-й ветке netgraph претерпел ряд изменений.
Archie Cobbs, archie@freebsd.org, перевод Антона Южанинова, citrin@mail.ru. Оригинал статьи опубликован на сайте Daemon News.
обсуждение статьи
Представьте следующую ситуацию: вы разрабатываете маршрутизатор TCP/IP, основанный на FreeBSD. Продукт должен поддерживать синхронные последовательные WAN-линии, то есть выделенные цифровые каналы, работающие на скоростях до T1, где используется инкапсуляция HDLC. Вы должны поддерживать следующие протоколы для передачи IP-пакетов через кабель:
- IP-пакеты, передаваемые поверх HDLC (простейший путь для транспортировки IP);
- IP пакеты, передаваемые поверх "Cisco HDLC" (по существу, пакеты дополнены двухбайтным полем Ethertype, и периодически посылаются keep-alive пакеты);
- IP-пакеты, передаваемые поверх Frame Relay (Frame Relay предоставляет до 1000 виртуальных каналов «точка-точка» поверх одой кабельной сети).
- IP в инкапсуляции RFC 1490 поверх frame relay (RFC 1490 определяет способ передачи нескольких протоколов через одно соединение и он часто используется совместно Frame Relay);
- PPP поверх HDLC;
- PPP поверх Frame Relay;
- PPP в инкапсуляции RFC 1490 поверх Frame Relay;
- PPP поверх ISDN.
Можно даже предположить, что вам придется поддерживать Frame Relay поверх ISDN!
На Рисунке 1 показаны все возможные комбинации.
Рисунок 1. Способы передачи IP поверх последовательных синхронных и ISDN WAN-соединений.
Эта ситуация была показана Джулианом Элисчером (Julian Elischer) и мной в 1996, когда мы работали в компании Whistle InterJet. В то время во FreeBSD имелась очень ограниченная поддержка последовательного синхронного оборудования и протоколов. Мы думали использовать OEMing от Emerging Technologies, но вместо этого решили реализовать это сами.
Ответом был netgraph. Netgraph - это сетевая подсистема в ядре, следующая принципу UNIX достижения мощности посредством комбинации простых инструментов, каждый их которых предназначен для выполнения одной, вполне определенной задачи. Основная идея проста: есть узлы (nodes), инструменты и ребра (edges), которые соединяют пару узлов (отсюда и "граф" в "netgraph"). Пакеты данных идут в двух направлениях вдоль ребер от узла к узлу. Когда узел получает пакет данных, он обрабатывает его, и затем (обычно) отправляет его другому узлу. Обработка может заключаться в простейшем добавлении/удалении заголовков, а может быть и более сложной, или включать другие компоненты системы. Netgraph напоминает потоки (Streams) в System V, но он разработан более гибким и производительным.
Netgraph оказался очень полезным для работы в сети, и сейчас он используется в Whistle InterJet для всех указанных выше комбинаций протоколов (за исключением Frame Relay поверх ISDN) плюс обычный PPP поверх асинхронных последовательных интерфейсов (таких, как модемы и терминальные адаптеры) и PPTP, поддерживающий шифрование. Во всех этих протоколах данные полностью обрабатываются в ядре. В случае PPP, пакеты согласования (negotiation) обрабатываются отдельно в пользовательском режиме (смотрите порт FreeBSD для mpd).
узлы и ребра
Глядя на рисунок выше, очевидно, что должны быть узлы и ребра. Менее очевиден факт, что узел может иметь определенное число подключений к другим узлам. Например, вполне возможно иметь одновременно IP, IPX, и PPP в инкапсуляции RFC 1490; конечно, мультиплексирование - это та задача, для которой и нужен RFC 1490. В этом случае нужно три ребра подключить к узлу RFC 1490, одно для каждого стека протоколов. Нет требований, чтобы данные следовали строго в определенном направлении, и нет ограничений на действия, которые узел выполняет с пакетом. Узел может быть источником/потребителем данных, например, если он связан с аппаратной частью, или он может просто добавлять/удалять заголовки, мультиплексировать и т. п.
Узлы netgraph существуют в ядре и полупостоянно. Обычно узел существует, пока он подключен к какому либо другому узлу, однако некоторые узлы - постоянные, например, узлы, связанные с аппаратной частью; когда число ребер уменьшается до нуля, аппаратное устройство выключается. Поскольку узлы существуют в ядре, они не связаны с каким либо определенным процессом.
управляющие сообщения
Эта картина все еще слишком упрощенная. В реальной жизни узел нужно конфигурировать, запрашивать его состояние и т. д. Например, PPP - сложный протокол с большим количеством опций. Для этого в netgraph определены управляющие сообщения (control messages). Управляющее сообщение - это "внешнее управление". Вместо следования от узла к узлу (как это делают пакеты данных), управляющие сообщения посылаются асинхронно и непосредственно от одного узла к другому. Два узла могут быть не связаны (даже через другие узлы). Для обеспечения этого в netgraph существует простая схема адресации - узел можно идентифицировать, используя простую ASCII-строчку.
Управляющие сообщения - это просто структуры Си с фиксированным заголовком (структура ng_mesg) и переменной областью данных. Есть несколько управляющих сообщений, которые должны понимать все узлы; они называются общими управляющими сообщениями (generic control messages) и реализованы в базовой системе. Например, узлу можно указать разрушить себя или создать/разрушить ребро. Узлы могут также иметь свои собственные управляющие сообщения, зависящие от типа. Каждый тип узла, определяющий свои собственные управляющие сообщения, должен иметь уникальное значение typecookie. Комбинация полей typecookie и command в заголовке управляющего сообщения определяет, как его интерпретировать.
На управляющие сообщения часто идут ответы в виде ответных контрольных сообщений (reply control message). Например, чтоб узнать состояние узла или статистику, вы можете послать управляющее сообщение "get status"; узел пошлет вам ответ (который идентифицируется значением token, скопированным из исходного запроса), содержащий запрошенную информацию в поле данных. Заголовок ответного управляющего сообщения обычно такой же, как исходный заголовок, но выставлен флаг reply flag.
Netgraph предоставляет способ преобразования этих структур в строки ASCII и обратно для упрощения взаимодействия с человеком.
крючки (hooks)
На самом деле в netgraph ребра не существуют сами по себе. Ребро - это просто комбинация двух крючков (hooks), по одному от каждого узла. Крючок узла определяет, как узел может быть подключен. Каждый крючок имеет уникальное, статически определенное имя, которое часто отражает его цель. Имя имеет значение только в контексте данного узла; два узла могут иметь крючки с одинаковым названием.
Например, рассмотрим узел Cisco. Cisco HDLC - это очень простая схема мультиплексирования протоколов посредством дополнения каждого кадра спереди полем Ethertype перед передачей на физический уровень. Cisco HDLC поддерживает одновременную передачу IP, IPX, AppleTalk, и т. д. Таким образом, узел netgraph для Cisco HDLC определяет крючки, называемые inet, atalk, and ipx. Эти крючки предназначены для подключения к соответствующим вышележащим стекам протоколов. Узел также определяет крючок, называемый downstream, который подключается к нижележащему уровню, например узлу, связанному с синхронной последовательной платой. К пакетам, получаемым через крючки inet, atalk и ipx, добавляется два байта заголовка, и затем они отправляются через крючок downstream. Наоборот, из пакетов, полученных через downstream, удаляется заголовок, и они отправляются вверх через крючок, соответствующий протоколу. Узел также обрабатывает периодические пакеты "tickle" и запросы, определенные протоколом Cisco HDLC.
Крючки всегда либо подключены, либо не подключены; операция подключения или отключения пары крючков атомарная. Когда пакет посылается через крючок, которые не подключен, он отбрасывается.
некоторые примеры типов узлов
Некоторые типы узлов достаточно очевидны, такие, как Cisco HDLC. Другие менее очевидны, но предоставляют некоторые интересные функции, например, возможность обращаться непосредственно к устройству или открытому сокету внутри ядра.
Несколько примеров типов узлов, реализованных на настоящий момент во FreeBSD. Все эти типы узлов описаны в соответствующих страницах справочного руководства man.
Тип узла echo: ng_echo. Этот тип узла принимает подключения через любой крючок. Любые получаемые пакеты просто посылаются назад через тот же крючок. Любые не общие управляющие сообщения также возвращаются назад в виде ответов.
Тип узла discard: ng_disc. Этот тип узла принимает подключения через любой крючок. Любые пакеты данных и контрольные сообщения молча отбрасываются.
Тип узла tee: ng_tee. Этот тип узла похож на двунаправленную версию утилиты tee(1). Он копирует данные, проходящие через него в любом направлении (right или left), и полезен для отладки. Пакеты, получаемые через right, посылаются через left и копия шлется через right2left; аналогично для пакетов идущих от left к right. Пакеты, получаемые через right2left, посылаются через left и пакеты получаемые через left2right, отправляются через right.
Рисунок 2. Тип узла tee.
Тип узла interface: ng_iface.
Этот тип узла - одновременно узел netgraph и системный интерфейс PPP. Он имеет (пока) три крючка, называемые "inet", "atalk" и "ipx". Эти крючки соответствуют стекам протоколов IP, AppleTalk и IPX соответственно. Первый раз, при создании интерфейсного узла, интерфейс ng0 показывается в выводе ifconfig’a. Вы можете прописать на этом интерфейсе адрес, как на другом PPP-интерфейсе, пинговать удаленную сторону, и т. д. Конечно, узел должен быть подключен к чему либо, иначе пакеты ping будут выходить через крючок inet и исчезать.
К сожалению, FreeBSD в настоящий момент не поддерживает удаление интерфейсов, таким образом, однажды создавшись, узел типа ng_iface будет существовать до следующей перезагрузки (однако это будет скоро исправлено).
Рисунок 3. Тип узла interface.
Тип узла TTY: ng_tty. Этот тип узла - одновременно узел netgraph и дисциплина асинхронной последовательной линии (line discipline). Вы создаете узел установкой дисциплины линии NETGRAPHDISC на последовательной линии. Узел имеет один крючок, называемый hook. Пакеты, получаемые через hook передаются (как последовательные байты) через соответствующее последовательное устройство; данные, получаемые от устройства, формируются в пакеты и посылаются через hook. Нормальное чтение и запись в последовательную линию блокируются.
Рисунок 4. Тип узла TTY.
Тип узла socket: ng_socket. Этот тип узла очень важен, поскольку позволяет программам пользовательского режима взаимодействовать с системой netgraph. Каждый узел - одновременно узел netgraph и пара сокетов из семейства PF_NETGRAPH. Узел создается, когда программа пользовательского режима создает соответствующий сокет через системный вызов socket. Один сокет используется для передачи и получения пакетов данных, а второй для контрольных сообщений. Этот узел поддерживает крючки с произвольными именами, например "hook1", "hook2" и т. д.
Рисунок 5. Тип узла socket.
Тип узла BPF: ng_bpf. Этот тип узла выполняет сравнение с шаблоном и фильтрацию пакетов так, как будто они следуют через bpf.
Тип узла ksocket: ng_ksocket. Этот тип узла противоположен ng_socket. Каждый узел одновременно является сокетом, полностью расположенном в ядре. Данные, получаемые узлом, записываются в сокет и наоборот. Нормальные bind(), connect(), и т. д. операции осуществимы вместо контрольных сообщений. Этот тип узла полезен для туннелирования пакетов через сокет (например, туннелирование IP поверх UDP).
Тип узла ethernet: ng_ether. Если вы скомпилировали ваше ядро с options NETGRAPH, то каждый интерфейс Ethernet также является узлом netgraph с таким же именем, как интерфейс. Каждый узел имеет два крючка "orphans" и "divert"; только один крючок может быть подключен одновременно. Если "orphans" подключен, то устройство продолжает работать нормально, за исключением того, что все пакеты Ethernet с неизвестным или неподдерживаемым типом, доставляются через этот крючок (в нормальном режиме эти пакеты просто отбрасываются). Когда подключен крючок "divert" - все входящие пакеты доставляются через этот крючок. Пакет, полученный через любой из этих крючков, передается в кабель. Все пакеты - "сырые" кадры Ethernet со стандартным 14-байтным заголовком (но без контрольной суммы). Этот тип узла полезен, например для PPP поверх Ethernet (PPPoE).
Синхронные драйверы: ar и sr. Если вы скомпилировали ваше ядро с options NETGRAPH, то драйверы ar(4) и sr(4) перестанут работать в нормальном режиме и вместо этого будут работать как постоянные узлы netgraph (с таким же именем, как название устройства). Сырые кадры HDLC могут быть прочитаны и записаны через крючок "rawdata".
метаинформация
В некоторых случаях пакеты данных могут иметь связанную метаинформацию, которую нужно передать вместе с пакетом. Хотя это редко используется, netgraph предоставляет механизм, чтобы сделать это. Пример метаинформации - приоритеты: некоторые пакеты могут иметь более высокий приоритет, чем другие. Типы узлов могут определять свою собственную, специфичную метаинформацию, и netgraph для этой цели определяет структуру ng_meta. Метаинформация не воспринимается базовой системой netgraph.
адресация узлов netgraph
Каждый узел netgraph адресуем через строку ASCII, называемую адрес узла (node address) или путь (path). Адрес узла используется только для отправки контрольных сообщений.
Многие узлы имеют имена. Например, узел, ассоциированный с устройством, будет обычно иметь такое же имя, как устройство. Когда узел имеет имя, он всегда может быть адресован, используя абсолютный адрес, состоящий из имени устройства и двоеточия. Например, если вы создали интерфейсный узел, названный "ng0", его адрес будет "ng0:".
Если узел не имеет имени, вы можете составить его из уникального номера ID узла, заключив его в квадратные скобки (каждый узел имеет уникальный номер ID). Таким образом, если узел ng0: имеет номер ID 1234, тогда "[1234]:" так же является адресом этого узла.
Наконец, адрес ".:" или "." всегда указывает на локальный узел (источник).
Относительная адресация также возможна когда два узла соединены опосредовано. Относительный адрес использует имена последовательных крючков в пути от одного узла к другому. Рассмотрим рисунок 6.
Рисунок 6. Простая конфигурация узлов.
Если узел node1 хочет послать контрольное сообщение узлу node2, он может использовать адрес ".:hook1a" или просто "hook1a". Для обращения к узлу node3 он может использовать адрес ".:hook1a.hook2b" или просто "hook1a.hook2b". Аналогично, узел node3 может обратиться к узлу node1, используя адрес ".:hook3a.hook2a" или просто "hook3a.hook2a".
Относительные и абсолютные адреса можно сочетать, например, "node1:hook1a.hook2b" будет указывать на узел node3.
использование Netgraph
Netgraph поставляется с утилитами командной строки и пользовательской библиотекой, которые позволяют взаимодействовать с системой ядра netgraph. Необходимы привилегии root для работы с netgraph из пользовательской режима.
Есть две утилиты командой строки для взаимодействия с netgraph: nghook и ngctl. nghook очень проста: она подключается к любому неподключенному крючку любого узла и позволяет вам передавать и получать пакеты данных через стандартный ввод и стандартный вывод. Вывод может быть дополнительно декодирован в читаемый человеком формат hex/ASCII. В командной строке вы указываете абсолютный адрес узла и имя крючка.
Например, если ваше ядро собрано с options NETGRAPH и вы имеете сетевой интерфейс fxp0, следующая команда перенаправит все сетевые пакеты получаемые картой и выведет их через стандартный вывод в формате hex/ASCII:
nghook -a fxp0: divert
ngctl - более функциональная программа, которая позволяет вам делать практически все с netgraph из командной строки. Она работает в пакетном или интерактивном режиме, и поддерживает несколько команд, которые выполняют интересующую работу, в том числе:
- connect - соединить пару крючков для объединения двух узлов;
- list - вывести список всех узлов в системе;
- mkpeer - создать узел и подключить его к существующему узлу;
- msg - послать форматированное ASCII-сообщение узлу;
- name - назначит узлу имя;
- rmhook - отключить два подключенных крючка;
- show - показать информацию об узле;
- shutdown - удалить/сбросить узел, разрушив все подключения;
- status - получить статус узла в удобочитаемом виде;
- types - показать типы установленных узлов;
- quit - выйти из программы.
Эти команды могут быть объединены в скрипт, который делает что-то полезное. Например, предположим, что у вас есть две частные сети, которые разделены, но обе подключены к интернету через машины с FreeBSD. Сеть A имеет внутренние адреса из диапазона 192.168.1.0/24 и внешний IP адрес 1.1.1.1, в то время как сеть B имеет адреса 192.168.2.0/24 и внешний адрес 2.2.2.2. Используя Netgraph, вы можете легко сделать UDP для IP-трафика между двумя частными сетями. Пример скрипта, который это может сделать (его можно также найти в /usr/share/examples/netgraph):
#!/bin/sh
# Этот скрипт устанавливает виртуальный канал точка-точка между двумя
# подсетями, используя UDP пакеты в качестве "глобального канала".
# Эти две подсети могут иметь адреса немаршрутизируемые между двумя
# файрволами.
# Определение локальной и удаленной внутренней сетей, также как и
# локального и удаленного внешних IP адресов и номера UDP порта,
# которые будут использованы для туннеля
#
LOC_INTERIOR_IP=192.168.1.1
LOC_EXTERIOR_IP=1.1.1.1
REM_INTERIOR_IP=192.168.2.1
REM_EXTERIOR_IP=2.2.2.2
REM_INSIDE_NET=192.168.2.0
UDP_TUNNEL_PORT=4028
# Создать интерфейсный узел "ng0", если его еще нету,
# если есть, просто убедиться, что он ни к чему не подключен
#
if ifconfig ng0 >/dev/null 2>&1; then
ifconfig ng0 inet down delete >/dev/null 2>&1
ngctl shutdown ng0:
else
ngctl mkpeer iface dummy inet
fi
# Присоединить UDP сокет к крюку "inet" интерфейсного узла использую
# узел типа ng_ksocket(8).
#
ngctl mkpeer ng0: ksocket inet inet/dgram/udp
# Присоединить UDP сокет к локальному внешнему IP и порту
#
ngctl msg ng0:inet bind inet/${LOC_EXTERIOR_IP}:${UDP_TUNNEL_PORT}
# Установить соединение с внешним IP и портом на удаленном сервере
#
ngctl msg ng0:inet connect inet/${REM_EXTERIOR_IP}:${UDP_TUNNEL_PORT}
# Настроить интерфейс точка-точка
#
ifconfig ng0 ${LOC_INTERIOR_IP} ${REM_INTERIOR_IP}
# Добавить маршрут к удаленной частной сети через туннель
#
route add ${REM_INSIDE_NET} ${REM_INTERIOR_IP}
Далее рассмотрим, как можно работать с ngctl в интерактивном режиме. Пользовательский ввод выделен жирным.
Запустим ngctl в интерактивном режиме. Будет показан список доступных команд.
$ ngctl
Available commands:
connect Connects hookof the node at to
debug Get/set debugging verbosity level
help Show command summary or get more help on a specific command
list Show information about all nodes
mkpeer Create and connect a new node to the node at "path"
msg Send a netgraph control message to the node at "path"
name Assign nameto the node at
read Read and execute commands from a file
rmhook Disconnect hook "hook" of the node at "path"
show Show information about the node at
shutdown Shutdown the node at
status Get human readable status information from the node at
types Show information about all installed node types
quit Exit program
ngctl создает при запуске узел типа ng_socket. Это наш локальный узел netgraph, который используется для взаимодействия с другими узлами в системе. Посмотрим на него. Мы видим, что ngctl назначил ему имя "ngctl652" и его тип "socket", номер ID 45 и он имеет ноль подключенных крючков, т. е. он не подключен к другим узлам.
+ show .
Name: ngctl652 Type: socket ID: 00000045 Num hooks: 0
Теперь мы создадим узел "tee" и подключим его к локальному узлу. Мы подключим крючок "right" узла "tee" к крючку "myhook" на локальном узле. Мы можем использовать любое имя для нашего крючка, так как узел типа ng_socket поддерживает крючки с произвольными именами. После этого снова посмотрим на наш локальный узел, чтобы убедиться, что он имеет безымянного соседа типа "tee".
+ help mkpeer
Usage: mkpeer [path]
Summary: Create and connect a new node to the node at "path"
Description:
The mkpeer command atomically creates a new node of type "type"
and connects it to the node at "path". The hooks used for the
connection are "hook" on the original node and "peerhook" on
the new node. If "path" is omitted then "." is assumed.
+ mkpeer . tee myhook right
+ show .
Name: ngctl652 Type: socket ID: 00000045 Num hooks: 1
Local hookPeer namePeer typePeer IDPeer hook
--------------------------------------------
myhooktee00000046right
Аналогично, если мы посмотрим на вывод узла tee, мы увидим, что он подключен к нашему локальному узлу через крючок "right". Узел "tee" все еще безымянный, но мы можем его указать, используя абсолютный адрес "[46]:" или относительный адрес ".:myhook" или "myhook".
+ show .:myhook
Name:Type: teeID: 00000046Num hooks: 1
Local hookPeer namePeer typePeer IDPeer hook
--------------------------------------------
rightngctl652socket00000045myhook
Теперь назначим ему имя и убедимся, что можем по нему обратиться к этому узлу.
+ name .:myhook mytee
+ show mytee:
Name: myteeType: teeID: 00000046Num hooks: 1
Local hookPeer namePeer typePeer IDPeer hook
--------------------------------------------
rightngctl652socket00000045myhook
Теперь подключим узел Cisco HDLC к другой стороне узла "tee" и снова проверим узел "tee". Мы подключимся к крючку "downstream" узла Cisco HDLC, как будто бы узел tee соответствует подключению к WAN. Cisco HDLC слева (крючек "left") от узла tee, наш локальный узел справа (крючок "right") от узла tee.
+ mkpeer mytee: cisco left downstream
+ show mytee:
Name: myteeType: teeID: 00000046Num hooks: 2
Local hookPeer namePeer typePeer IDPeer hook
--------------------------------------------
leftcisco00000047downstream
rightngctl652socket00000045myhook
+
Rec'd data packet on hook "myhook":
0000: 8f 00 80 35 00 00 00 02 00 00 00 00 00 00 00 00 ...5............
0010: ff ff 00 20 8c 08 40 00 ... ..@.
+
Rec'd data packet on hook "myhook":
0000: 8f 00 80 35 00 00 00 02 00 00 00 00 00 00 00 00 ...5............
0010: ff ff 00 20 b3 18 00 17 ... ....
Эй, что это такое?! Выглядит так, будто мы получаем какие то пакеты данных через наш крючок "myhook". Узел Cisco каждые 10 секунд посылает периодические пакеты keep-alive. Эти пакеты проходят через узел tee (слева направо от крючка "left" к крючку "right") и принимаются крючком "myhook", где ngctl показывает их в консоли.
Теперь посмотрим список всех узлов, существующих в системе. Заметим, что два наших интерфейса Ethernet также показаны, поскольку это постоянные узлы и мы собирали ядро с options NETGRAPH.
+ list
There are 5 total nodes:
Name:Type: ciscoID: 00000047Num hooks: 1
Name: myteeType: teeID: 00000046Num hooks: 2
Name: ngctl652Type: socketID: 00000045Num hooks: 1
Name: : etherID: 00000002Num hooks: 0
Name: fxp0Type: etherID: 00000001Num hooks: 0
+
Rec'd data packet on hook "myhook":
0000: 8f 00 80 35 00 00 00 02 00 00 00 00 00 00 00 00 ...5............
0010: ff ff 00 22 4d 40 40 00 ..."M@@.
OK, давайте выключим (то есть удалим) узел Cisco HDLC, таким образом мы остановим получение данных.
+ shutdown mytee:left
+ show mytee:
Name: mytee Type: tee ID: 00000046 Num hooks: 1
Local hook Peer name Peer type Peer ID Peer hook
---------- --------- --------- ------- ---------
right ngctl652 socket 00000045 myhook
Теперь, давайте посмотрим статистику узла tee. Мы пошлем управляющее сообщение и немедленно получим ответ. Команда и ответ конвертируются в/из ASCII автоматически с помощью ngctl, так как управляющие сообщение - это двоичная структура.
+ help msg
Usage: msg path command [args ... ]
Aliases: cmd
Summary: Send a netgraph control message to the node at "path"
Description:
The msg command constructs a netgraph control message from the
command name and ASCII arguments (if any) and sends that
message to the node. It does this by first asking the node to
convert the ASCII message into binary format, and re-sending the
result. The typecookie used for the message is assumed to be
the typecookie corresponding to the target node's type.
+ msg mytee: getstats
Rec'd response "getstats" (1) from "mytee:":
Args: { right={ outOctets=72 outFrames=3 } left={ inOctets=72 inFrames=3 }
left2right={ outOctets=72 outFrames=3 } }
Ответ - это просто строковая версия структуры ng_tee_stats, возвращаемой в ответном управляющем сообщении (эта структура определена в ng_tee.h). Мы видим, что три кадра (и 72 байта) прошли через узел слева направо. Каждый кадр был скопирован и отправлен через крючок "left2right" (но поскольку этот крючок не подключен, эти кадры были отброшены).
OK, теперь проиграемся с узлом ng_ksocket.
+ mkpeer ksocket myhook2 inet/stream/tcp
+ msg .:myhook2 connect inet/127.0.0.1:13
ngctl: send msg: Operation now in progress
Rec'd data packet on hook "myhook":
0000: 54 75 65 20 46 65 62 20 20 31 20 31 31 3a 30 32 Tue Feb 1 11:02
0010: 3a 32 38 20 32 30 30 30 0d 0a :28 2000..
Мы создали в ядре TCP-сокет, используя узел ng_ksocket, и подключили его к сервису "daytime" на локальной машине, который возвращает текущее время. Как мы узнали, что нужно использовать "inet/127.0.0.1:13" в качестве аргумента команды "connect"? Это описано в странице справочного руководства man ng_ksocket(8).
OK, поигрались и хватит.
+ quit
libnetgraph
Существует так же пользовательская библиотека libnetgraph для использования в программах netgraph. Она предоставляет много полезных вызовов, которые описаны в справочном руководстве man. Пример использования их можно посмотреть в исходном коде /usr/src/usr.sbin/ngctl.
планы на будущее
Работа над Netgraph все еще продолжается, желание помочь приветствуется! Есть несколько идей по поводу будущей работы.
типы узлов
Еще много типов узлов не написано:
- узлы типа "slip", которые будут реализовывать протокол SLIP. Это должно быть достаточно легко, и, возможно, скоро будет сделано;
- больше узлов сжатия и шифрования PPP, которые могут быть подключены к узлу ng_ppp, например, сжатие Deflate для PPP, 3DES-шифрование PPP и т. д.;
- реализация ipfw как узла netgraph;
- реализация динамического пакетного фильтра (DPF) как узла netgraph. DPF - это разновидность высокоскоростной, компилирующей налету (JIT compiling) версии BPF;
- общий узел типа "mux", где каждый крючок может быть настроен на добавление/удаление определенныого заголовка из пакетов.
Во FreeBSD сейчас имеется четыре реализации PPP: sppp, pppd, ppp, и порт MPD. Это достаточно глупо. Используя netgraph, это может быть объединено в один демон, работающий в пользовательском режиме, который будет выполнять все согласования и настройки, в то время как маршрутизация данных будет полностью происходить в ядре, через узлы ng_ppp. Это позволит объединить гибкость и удобство настройки демонов, работающих в пользовательском режиме, со скоростью работы в ядре. Сегодня MPD - единственная реализация, которая полностью основана на netgraph, но есть планы также переработать ppp;
- маршрутизирующий тип узлов. Каждый подключенный крючок соответствует маршруту назначения, например комбинации адреса и маски. Маршруты могут изменяться через управляющие сообщения;
- узел, реализующий пакетный фильтр с сохранением состояния (stateful firewall/NAT, замена для ipfw и/или ipfirewall);
- типы узлов для ограничения полосы пропускания и/или ее учета;
- добавление поддержки VLAN к существующим узлам Ethernet.
перевод управляющих сообщений в ASCII
Не все типы узлов, которые определяют свои собственные управляющие сообщения, поддерживают преобразование между двоичным видом и ASCII. Одна из задач - завершить эту работу для узлов, для которых это еще не сделано.
управление потоком
Одна из проблем, к которой возможно придется обратиться - это управление потом. Сейчас когда вы посылаете пакет данных, если конечный получатель узла не может принять его из-за переполнения очереди передачи или по другой причине, все что можно сделать - это отбросить пакет и вернуть ENOBUFS. Возможно, мы сможем определить новый код возврата ESLOWDOWN или что-то, что будет означать "пакет данных не отброшен; очередь полна; уменьшите скорость и попробуйте позже." Другой вариант - определить типы метаинформации, эквивалентные XOFF (остановить передачу) и XON (возобновить передачу).
чистка кода
Netgraph - объектно-ориентированный, но преимущества объектно-ориентированной архитектуры должны использоваться более полно без ущерба для производительности. Пока слишком много видимых полей в структурах, которые не должны быть доступны, и т. д., много также и других разных недоработок.
Также, страницы man для всех узлов (например, ng_tee(8)) в действительности должны находиться в разделе 4, а не 8.
выключение по цепочке
Было бы удобно сделать новое общее управляющее сообщение NGM_ELECTROCUTE, которое, если послать его узлу, выключит узел вместе со всеми узлами, связанными с ним непосредственно или через другие узлы. Это позволит выполнить быструю очистку сложного графа в netgraph одним ударом. В дополнение можно сделать новую опцию сокета (см. setsockopt(2)) которую нужно установить для сокета ng_socket, чтобы при его закрытии автоматически посылалось сообщение NGM_ELECTROCUTE.
Вместе две эти вещи позволят более надежно избежать в netgraph "утечку узлов".
обнаружение бесконечных петель
В базовую систему netgraph несложно включить "обнаружение бесконечных петель". Каждый узел должен иметь свой закрытый счетчик. Счетчик должен увеличиваться перед каждым обращением к методу rcvdata() данного узла, и уменьшаться потом. Если счетчик достиг нереально большого значения, мы считаем, что обнаружена бесконечная петля (и избегаем паники ядра).
другие сумасшедшие идеи
Теоретически, сетевая подсистема BSD может быть полностью заменена на netgraph. Конечно, скорее всего, это никогда не случится, но это хороший мысленный эксперимент. Каждое сетевое устройство должно быть постоянным узлом netgraph (как устройства Ethernet). Вверху каждого устройства Ethernet должен быть мультиплексор Ethertype. К нему должны быть подключены узлы IP, ARP, IPX, AppleTalk и т. д. Узел IP должен быть просто мультиплексором протокола IP, над которым должны находиться узлы TCP, UDP, и т. д. Узлы TCP и UDP должны, наконец, иметь узлы, похожие на сокеты сверху. И т. д., и т. д.
Фантазируем дальше: можно даже сделать все устройства в виде узлов netgraph. Реализовать преобразование между ioctl и управляющими сообщениями. А как вам идея обращаться напрямую к вашему SCSI-диску через ngctl(8)? Возможна и полная интеграция между netgraph и devfs.
Узел netgraf также являющийся слоем VFS? Файловая система в виде пространства узлов netgraph?
Если NFS может работать поверх UDP, это может работать поверх netgraph. Можно будет иметь диски NFS, удаленно смонтированные через ATM, или просто сделать NFS поверх чистого Ethernet без посредника в виде UDP.
Интересна идея программируемых типов узлов, чья реализация зависит от конфигурации, с использованием некой разновидности псевдокода.
Наверняка есть еще много сумасшедших идей, до которых мы еще не додумались :). Может быть ВЫ нам поможете?
* в статье описывается netgraph в 4-й ветке FreeBSD. В 5-й ветке netgraph претерпел ряд изменений.
Archie Cobbs, archie@freebsd.org, перевод Антона Южанинова, citrin@mail.ru. Оригинал статьи опубликован на сайте Daemon News.
обсуждение статьи
Сетевые решения. Статья была опубликована в номере 10 за 2004 год в рубрике software
