оптимизация информационных систем на основе СУБД Oracle
Данная статья предназначена для руководителей и специалистов IT-подразделений, занимающихся эксплуатацией промышленных систем на основе СУБД Oracle, и желающих получить максимальную производительность своей ИС. Впрочем, если у вас используется отличная от Oracle СУБД, не спешите отложить эту статью в сторону: многие факты и советы, данные в этом материале, с равным успехом применимы и для других СУБД.
Если в основе информационной системы (ИС) лежит СУБД Oracle и возникает недовольство пользователей недостаточной производительностью ИС, то, как правило, усилия по исправлению ситуации направляются на оптимизацию СУБД. При этом иногда совершается следующая ошибка — усилия сосредотачиваются на изменении параметров CУБД, а не на уменьшении времени отклика для конечного пользователя. Администраторы ИС изменяют параметры СУБД, но желательного ускорения работы пользователи не получают.
Большое количество статей, обучающих материалов и документации описывают традиционный подход к оптимизации СУБД Oracle, основанный на знании большого количества значений коэффициентов производительности (Ratio tuning). Дальнейшая оптимизация БД связана с улучшением этих коэффициентов, однако с ростом сложности ИС такой подход становится все менее эффективным.
Возникает парадокс, когда все коэффициенты находятся в границах требуемых диапазонов, а недовольство пользователей производительностью своей ИС (временем отклика) растет все больше и больше.
На практике оказывается гораздо важнее уметь оценивать производительность ИС как единого целого, включая аппаратный комплекс, системное программное обеспечение, а также воздействие со стороны сетевого окружения.
мифы и легенды
Оптимизация ИС всегда была окружена слухами и легендами, например, о магических параметрах БД, способных привести к ускорению работы пользователей в десятки раз или о SQL-запросах, которые вдруг начинают формировать отчеты с космической скоростью.
Стоит поблагодарить авторов-фантастов за создание и развитие таких легенд, они делают все возможное, чтобы сотрудники подразделений, занимающиеся оптимизацией ИС, никогда не оставались без работы.
Но некоторые заблуждения являются просто вредными для общего понимания ситуации. На них стоит обратить внимание!
миф параметра fast=true
Часто можно услышать высказывание о том, что ускорить работу БД в несколько раз можно только с помощью настроек БД. Более того, часто возникают вопросы во сколько раз ускорится работа БД, если увеличить, например, кэш БД или журнальный буфер. К сожалению, изменение параметров самой БД практически не влияет на производительность ИС, за исключением случаев, когда были допущены грубейшие ошибки. Настройки могут повлиять на скорость выполнения отдельных процедур, но в целом поведение всей системы не сильно изменится (примерно на 10-15%). Правда состоит в том, что не существует универсального параметра, который позволил бы решить все проблемы разом.
Вместо поиска магических параметров БД в файле настроек init.ora следует сосредоточиться на общем времени отклика системы, а также на определении составляющих времени ожидания — ведь пользователя беспокоит большое время выполнения бизнес-процедур, а не размер кэша БД.
Таким образом, перед изменением любого параметра необходимо знать ответы на следующие вопросы: почему и зачем нужно его изменить, в чем ожидается выигрыш производительности и каким образом измерить произошедшие количественные изменения?
миф более быстрых ЦПУ
Всегда ли установка более быстрых ЦПУ поможет вам справиться с проблемами производительности? К сожалению, не всегда. Если перед обновлением ЦПУ проблема тщательно не изучена, то лучшим результатом будет то, что ситуация не ухудшится и деньги будут просто потрачены зря, при этом возможно возникнут и дополнительные проблемы!
В статье "The Practical Performance Analyst" описывается, что в случае конкуренции за ЦПУ обычных пользователей и программных роботов (batch jobs) возможно увеличение времени отклика системы для обычных пользователей.
Можно представить ситуацию, когда система испытывает перегрузку дисковой подсистемы. После установки более быстрых ЦПУ программные роботы еще быстрее будут получать доступ к ЦПУ, смогут выполнять больше запросов на чтение-запись в единицу времени и "добьют" дисковую подсистему. Время отклика системы для реальных пользователей увеличится.
Таким образом, установка более быстрых ЦПУ может решить данную проблему, только если они являются узким местом!
миф об утилизации ЦПУ
Администраторов часто волнует вопрос большой загрузки их ЦПУ, но на самом деле стоит волноваться как раз в обратном случае!
Что означает загрузка ЦПУ? То, что ИС работает, а не простаивает. Если пользователи имеют большое время отклика (наиболее важная характеристика системы) при простаивающих ЦПУ, важно найти причину. Одной из возможных причин могут быть блокировки (блокировки БД (dml locks, latch) или блокировки ОС (inode)).
Что касается загрузки ЦПУ, то иногда приводятся следующие данные — загрузка ЦПУ во время рабочего дня должна быть примерно 60%-80%, достигая 90% процентов в пиковые моменты (имеется в виду, прежде всего, запас прочности системы). Строго говоря, степень загрузки ЦПУ следует определять по размеру очереди выполнения (run queue).
Таким образом, ЦПУ должны быть максимально загружены, но не перегружены!
миф числа пользователей
Вопрос о том, "сколько процессоров мне необходимо?" звучит от пользователей очень часто. При этом характеризуя свою ИС часто говорят — "у меня будет 200 пользователей". Но число пользователей не может служить оценкой числа необходимых процессоров (например, аналитический отчет способен загрузить систему гораздо сильнее, чем интерактивные пользователи).
Для определения необходимого количества процессоров нужно знать архитектуру построения ИС и используемые средства для ее построения. Эти данные могут помочь наметить пути возможной оптимизации.
Какие же методы существуют для оценки необходимого аппаратного обеспечения? Если система не промышленная (например, такая, как Oracle Application), необходимо самостоятельно проводить нагрузочное тестирование. Эмулируя работу интерактивных пользователей и одновременно получая и анализируя системную статистику, можно с высокой точностью получить оценку необходимой процессорной мощности и требования к дисковой подсистеме.
Не экономьте на оценках производительности системы! Вложения в нагрузочное тестирование окупятся на этапе выбора аппаратного обеспечения!
миф однократной настройки
Руководители подразделений, отвечающие за сопровождение ИС, часто задают вопросы: "Ну хорошо, мы настроем систему — на сколько мне хватит этой настройки? Неужели опять придется вызывать консультантов через год, а то и быстрее?".
Ответ крайне прост: все зависит от того, насколько данная ИС изменится за это время — сколько появится новых пользователей, как изменится состав данных, сколько появится новых форм и отчетов.
Очень полезно отслеживать и затем отображать на графике все изменения ИС (возможно за прошедший год сильно изменилась ИС, обновлено оборудование). И поэтому, если проблемы с производительностью возникли вновь — необходимо повторить исследование ИС!
Здесь уместно провести аналогию с техническим обслуживанием (ТО) автомобиля. Никто из водителей не приходит в ужас от необходимости регулярной замены масла и фильтров, прохождения обязательной процедуры техосмотра. Относитесь к настройке ИС, как к ТО вашего автомобиля — просто придется определить частоту настройки самостоятельно, на основании изменений, происходящих с ИС и, что важно, заложить в бюджет средства на данную процедуру!
низкая производительность ИС: кого винить и как исправить ситуацию?
Чаще всего вопросы производительности возникают уже во время работы, поэтому стоит рассматривать ситуацию функционирующей информационной системы.
Информационная система работает успешно, группа системных администраторов справляется с ежедневными задачами, но все чаще и чаще возникают жалобы пользователей о том, что их не устраивает время отклика, из бухгалтерии сообщают, что подготовка квартального отчета занимает целый день.
На технических совещаниях, которые теперь проводятся одно за другим, администраторы БД считают, что виноваты разработчики системы, разработчики обвиняют во всем администраторов. Пользователи выражают свое недовольство все сильнее. Моральная обстановка на предприятии ухудшается, и как правило, крайними становятся администраторы БД. Скорее всего, все согласны с этим мнением — ведь кажется очевидным, что данную ситуацию должен исправлять администратор БД.
Наверное всех сильно удивит тот факт, что администраторы БД вообще не отвечают за производительность ИС! Они отвечают только за оптимальную настройку СУБД, и это не всегда означает, что после настройки ИС в целом начнет работать производительно.
Важно также знать разницу между производительностью ИС и производительностью СУБД, а также стоит разобраться, кто же должен найти причину низкой производительности ИС. Для этого определим, что входит в понятие оптимизации СУБД и уточним обязанности администратора БД.
обязанности администратора БД
Вообще говоря, нет документа, в котором обязанности администратора СУБД собраны воедино в формальном виде, тем не менее стоит попытаться сформулировать их, используя Руководство администратора БД и некоторые статьи известных специалистов по Oracle.
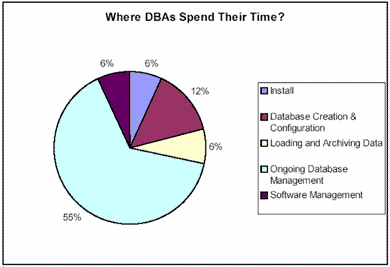
Рисунок 1. Распределение времени DBA (из обзора на конференции IOUG Live! 2001)
Из Рис. 1 видно, что в сферу ответственности администратора СУБД в первую очередь входит:
- установка программного обеспечения, установка обновлений для уже существующего программного обеспечения;
- создание баз данных, размещение СУБД на дисковой системе; планирование обновлений аппаратного обеспечения;
- загрузка и выгрузка пользовательских данных;
- управление доступностью: резервирование и восстановление БД;
- контроль БД: управление пользователями, правами доступа, безопасностью системы;
-мониторинг работы БД, проверки протоколов сообщений СУБД (alert.log).
Это не полный список обязанностей администратора — стоит также отметить такие задачи, как самообучение, взаимодействие с другими администраторами, обучение пользователей и разработчиков... Из приведенного списка видно, что большую часть времени занимают рутинные операции по поддержанию жизнедеятельности вашей ИС. И администраторам часто просто некогда изучать еще ОС и аппаратные особенности своей ИС.
оптимизация СУБД
Процесс оптимизации СУБД Oracle описан в учебном курсе Oracle 9i Perfomance Tuning. В нем подробно рассматриваются необходимые настройки СУБД и приводится оценка того, насколько оптимально выполнены эти настройки. Некоторые из них приведены в Табл. 1.
Таблица 1. Некоторые коэффициенты производительности БД
| Параметр | Buffer Hit Ratio (BCH). |
| Значение | Процент попаданий в буферный кэш. |
| Способ измерения | Bhr.sql или секция Instance summy Statistics из statspack. |
| Комментарий | Для OLTP-приложений должен быть не менее 90%. Для DSS приложений допустим меньший процент (до 60%). |
| Действия | Если BCH ниже порогового значения — следует увеличить значение параметра db_block_buffers (7l8l8i) или db_cache_size (9i). Конкретное значение параметра можно оценить с помощью таблицы X$KCBRBH (7I8l8i) или V$DB_CACHE_ADVICE (9i). Возможно имеет смысл использовать keep и recycle пулы (9i). |
| Параметр | Library Cache Hit Ratio (LCHR). |
| Значение | Процент попаданий в библиотечном кэше. |
| Способ измерения | Lchr.sql или секция Instance summy statistics из отчета statspack, также секция Library Cache Activity из отчета statspack. |
| Комментарий | LCHR должно быть не менее 99%. |
| Действия | Если параметр выходит за рамки допустимого диапазона, следует увеличить shared_pool. Также следует изучить вопрос об идентичности используемых SQL-выражений в приложении, возможно установив параметр cursor_sharing (8il9i) или изменив приложение. Следует также обратить внимание на параметры open_cursors, cursor_space_for_time, session_cached_cursors. Наиболее часто используемые процедуры следует закрепить в библиотечном кэше после старта экземпляра. Следует также, исследовав объем свободной памяти в SGA, провести настройку shared_pool_reserved_size c помощью v$shared_pool_reserved Если используется MTS-сервер, следует обратить внимание на конфигурацию large_pool. |
| Параметр | Data Dictionary Hit Ratio (DDHR). |
| Значение | Процент попаданий в кэше словаря данных. |
| Способ измерения | Ddhr.sql или секция Instance summy statistics из отчета statspack, также секция Dictionary cache stats из отчета statspack. |
| Комментарий | DDHR должен быть не менее 75% в целом, и не менее 98% для большинства объектов словаря данных. |
| Действия | Если параметр выходит за границы допустимого диапазона, следует увеличить shared_pool. |
| Параметр | Redo log buffer space. |
| Значение | Набор статистик, определяющих эффективность работы с журналами повторений. |
| Способ измерения | Rlsr.sql, Rcs.sql или секции Wait Events for DB, Instance Activity Stats из отчета statspack. |
| Комментарий | Не должно быть событий ожидания 'redo log space', отношение 'redo log allocation retries / redo entries должно быть менее 1%. |
| Действия | Если параметры выходят за границы допустимого диапазона, следует увеличить размер буфера журналов повторения, перенести журналы повторения на более быстрые устройства, уменьшить количество создаваемой redo информации, настроить оптимальную частоту процесса checkpoint с помощью log_checkpoint_interval, log_checkpoint_timeout Дополнительные данные могут быть получены из скрипта rl.sql или секции Latch Activity из отчета statspack. |
| Параметр | Rollback segment statistics. |
| Значение | Набор статистик, определяющих конкуренцию за сегменты отката. |
| Способ измерения | Rollback.sql, Rollback_sum.sql или секции Buffer wait Statistics и Instance Activity Stats из отчета statspack Roll_cont.sql или секция Rollback Segment Stats из отчета statspack. |
| Комментарий | Процент ожиданий при обращении к сегментам отката к обращению к данным должен быть не более 1%. Статистика ожиданий/к статистике успешных захватов для отдельных сегментов должна быть менее 0.01 |
| Действия | Если параметры выходят за границы допустимого диапазона, следует увеличить число сегментов отката. |
| Параметр | Sorts ratio. |
| Значение | Набор параметров, определяющих сортировки, выполняемые пользовательскими процессами. |
| Способ измерения | Sr.sql или секция Instance Activity Stats из отчета statspack. |
| Комментарий | Отношение sorts disk/sorts memory должно быть менее 5%. |
| Действия | Если параметр выходит за границы допустимого диапазона, следует увеличить параметр sort_area_size или установить параметры workarea_size_policy = auto и pga_aggregate_target (9i). |
| Параметр | Latch activity. |
| Значение | Набор важнейших "защелок" БД. |
| Способ измерения | Latch.sql или секции Latch Activity и Wait event (если последняя содержит большое значение для latch free) из отчета statspack. |
| Комментарий | Необходимо рассмотреть каждую "защелку" отдельно и устранить причину ожиданий защелки. Для любого типа защелки процент промахов как для захватов без ожиданий, так и захватов после ожидания на процессоре должен быть близок к 0. |
| Действия | Если процент промахов больше 0, то в зависимости от типа "защелки" обратите внимании на следующие рекомендации: Shared pool latch and library cache latch — низкий процент повторного использования SQL и PL/SQL конструкций. Cache buffer lru chain latch — эта защелка отвечает за защиту "грязных" блоков в буферном кэше, а также при поиске свободных блоков серверным процессом. Следует оптимизировать работу процесса DBWR или оптимизировать приложение. Cache buffer chains — эти защелки отвечают за защиту определенных блоков в буферном кэше, при частом обращении к одним и тем же блокам. Следует определить объект, к которому относятся эти блоки, и изменить логику приложения. Redo allocation — отвечает за выделение места в буфере журнала повторения (redo log buffer). См. параметр Redo log buffer space. Redo copy — отвечает за запись в буфер журнала повторений. См. параметр Redo log buffer space. На многопроцессорной машине следует также обратить внимание на параметр SPIN_COUNT. Его увеличение может дать ускорение работы БД, но потребует больше процессорных ресурсов. |
| Параметр | Enqueue stats. |
| Значение | Набор важнейших блокировок БД с временами ожидания каждой блокировки. |
| Способ измерения | Enq.sql или секция Enqueue Activity из отчета statspack (9i). Lock_stats.sql показывает статистику ожиданий для различного типа блокировок. |
| Комментарий | Необходимо рассмотреть каждую блокировку отдельно и устранить ожидания данного типа. |
| Действия | Типы блокировок: TX — Transaction lock.Ожидания, связанные с блокировками этого типа, вызваны плохим дизайном приложения или настройками на уровне таблиц. TM — DML enqueue. Ожидания, связанные с блокировками этого типа, вызваны плохим дизайном приложения или, например, отсутствием индексов для внешних ключей. SP — Space Management enqueue.Ожидания, связанные с блокировками этого типа, вызваны или частым выделением места под объекты, или частыми сортировками. |
| Параметр | IO Stats. |
| Значение | Статистика распределения операций ввода-вывода по файлам данных. |
| Способ измерения | Dioa.sql или секция File IO Stats из отчета statspack. |
| Комментарий | Среднее время чтения для файлов данных должно быть порядка 20-30ms. Если отношение количества операций чтения к числу прочитанных блоков существенно меньше 1, значит приложение выполняет много операций full scan. |
| Действя | Если параметры выходят за границы допустимого диапазона следует оптимизировать работу ввода-вывода. Перенесите файлы данных на более быстрые устройства (или raw device), убедитесь в эффективности вашего приложения (отсутствия необоснованных операций ввода-вывода). Убедитесь, что нагрузка на ваши табличные пространства сбалансирована, иначе переместите сегменты данных. |
Администратор СУБД отвечает за то, чтобы были выполнены все необходимые настройки СУБД. Как оценить, что такие настройки выполнены оптимально? Во-первых, параметры должны соответствовать значениям в таблице 1, и, во-вторых (возможно это более важная оценка), нужно убедиться в отсутствии значительного времени соответствующих событий ожиданий (waits events) на уровне пользовательской сессии или экземпляра БД в целом. Так, например, правильно выбранный размер журнального файла (Redo log space request) должен привести к отсутствию событий ожиданий.
Исходя из приведенного примера может показаться, что оптимизация БД крайне проста. Измеряем соответствующие параметры, смотрим, попадают ли они в необходимые диапазоны, если нет, то действуем согласно вышеприведенным инструкциям.
Но даже оптимально настроенная СУБД (с точки зрения администратора) не обязательно означает максимальную производительность ИС! Почему ранее упоминалось, что администраторы СУБД не отвечают за производительность ИС? Да потому, что у них нет для этого необходимых средств и часто знаний (не по их вине)!
Возвращаясь к примеру выше, даже уменьшив время ожидания для события space request, скорее всего, не удастся решить все проблемы производительности, связанные с журнальным файлом. Скорее всего потребуется перенести журнальные файлы Redo log space request на более быстрые или менее загруженные диски. Для этого нужно знать ответы на следующие вопросы: какие диски и как загружены в системе, что такое вообще "загруженный диск", знать, как ОС работает с подсистемой ввода-вывода, как включить в ОС асинхронный ввод-вывод и т.д. — т.е. знать дополнительно ОС и аппаратные средства. Может ли штатный администратор БД знать все это? Вероятнее всего нет. Это не входит в программу курсов, и на это у него практически нет времени.
Администраторам СУБД достаточно знать, что buffer hit ratio в течение дня имеет значение не менее 99.78%, что означает, что проблем с чтениями в СУБД нет. Но так ли это на самом деле? Не совсем. Cary Millsap в своей работе "Why You Should Focus on LIOs Instead of PIOs" предупреждает о том, что опасность логических чтений часто недооценивается. В этом можно убедиться на реальных примерах. Большое число логических чтений ведет к использованию большого числа защелок (latches) и, следовательно, увеличивает время ожидания серверного процесса на процессоре и время ожидания для конечного пользователя.
Так что нам дает тот факт, что у работающей ИС высокий процент попаданий наших запросов в кэш БД? Было минимизировано число дисковых чтений, но как это сказалось на времени отклика системы? Ведь если присутствует огромное количество логических чтений (из кэша БД), то наше приложение все равно работает медленно. Таким образом, получается, что для оптимизации производительности ИС данный параметр не дает практические ничего! А ведь это один из основных параметров оптимизации в классическом представлении.
Тем не менее, автор придерживается мнения, что это нормальный подход, когда администратор СУБД должен отвечать только за настройку СУБД.
Следует ли из вышеперечисленного, что вообще не нужно обращать внимание на параметры СУБД? Ни в коем случае. Правильный вывод — не останавливайтесь только на изменении параметров СУБД!
кто должен заниматься оптимизацией СУБД?
Теперь стоит остановиться на вопросе — кто же должен заниматься оптимизацией ИС? Автор придерживается мнения, что "в обычном штатном расписании такая позиция просто не предусмотрена". Проще говоря, в штате не должно быть специалиста по оптимизации ИС. Почему? Дело в том, что это специфичный род деятельности, во многом основанный на опыте. И достаются эти знания путем исследования достаточно большого количества различных систем. Формализовать такой опыт практически невозможно, а саму эту работу можно сравнить с детективной работой. Кажется все просто — собери улики (данные о производительности), опроси свидетелей (пользователей и администраторов) и поймай преступника (причину низкой производительности системы). Однако почти каждое дело (ИС) уникально по-своему. И тут очень важен полученный ранее опыт.
Хотелось бы подчеркнуть следующее: работа по оптимизации ИС никак не связана с ежедневной поддержкой ИС, т.е. с тем, чем обязаны заниматься ваши администраторы.
Оказывается, в фирмах-поставщиках ОС и СУБД инженеры, отвечающие за производительность, также выделены в отдельные подразделения. Так в Oracle существует Oracle Support Services Centers of Expertise, в Sun Microsystems Sun's Enterprise Engineering Group. Статьи инженеров вышеперечисленных подразделений представляют особенную ценность для получения знаний о внутреннем мире БД и аппаратной платформы.
Мне кажется, что были приведены достаточно убедительные аргументы, что персонал не виноват в сложившейся ситуации. Перейдем теперь к более интересному вопросу: что же делать? Какой есть выход из этой ситуации?
что делать?
Все звучит очень просто: необходимо выполнить комплексное обследование информационной системы, для того, чтобы определить узкие места, а также оценить их влияние на общий отклик системы.
когда нужно исследовать ИС?
Практически неважно, на каком этапе развития находится информационная система — нужно серьезно ее исследовать, документировать результаты данного исследования, а также получить средства для такого исследования, чтобы при необходимости повторить его самостоятельно, через какой-то промежуток времени. Кто предупрежден о предстоящих проблемах — тот вооружен знаниями, как этим проблемам противостоять.
Рассмотрим конкретные рекомендации разработчикам и специалистам службы сопровождения на каждом из этапов развития ИС.
Разработка ИС.На этапе разработки желательно провести лекции для разработчиков о современных методах разработки и опциях версии, которую они используют. Вероятно не потребуется изобретать велосипед, потому что необходимые разработчикам механизмы уже введены в новых версиях.
Необходимо познакомить разработчиков с практическими приемами сбора и обработки данных о производительности SQL-запросов, убедить их обращать серьезное внимание на производительность ИС еще на этапе ее разработки. Почему это так важно? Потому, что, как правило, на этом этапе у разработчиков еще нет достаточного объема тестовых данных, а без реального объема данных успешно работает практически любой код.
Внедрение.Одним из вопросов, возникающих при внедрении ИС, является вопрос о том, какое аппаратное обеспечение потребуется для реальной эксплуатации ИС. Для этого необходимо при помощи разработчиков написать код для нагрузочного тестирования. Получив данные о производительности в тестовом окружении, можно выполнить расчет (sizing) программно-аппаратного комплекса для реальной эксплуатации системы. А обнаруженные узкие места исправить до начала эксплуатации системы.
Эксплуатация.При эксплуатации ИС вопрос производительности считается одним из главных, поскольку, если не обеспечивается требуемое время реакции системы — эта система не выполняет возложенных на нее функций. Необходимо собирать данные о производительности ИС постоянно, так как постоянно меняется ИС — разработчики устанавливают новое ПО, в систему добавляются новые пользователи, данные внутри БД также изменяются. Хорошо, если удается справляться со вновь возникающими проблемами изменением параметров системы, но рано или поздно потребуется обновление аппаратного обеспечения. Как правило, обновление аппаратного обеспечения требует времени и соответствующих позиций в бюджете. И если есть данные о росте нагрузки на систему во времени, то и легко можно предоставить соответствующие расчеты для руководства.
заключение
В этой статье были даны теоретические основы оптимизации ИС вообще и баз данных в частности. Для тех, кого живо заинтересовала эта тематика, в следующем номере «СР» будет предложено продолжение темы – статья «Оптимизация информационной системы на базе БД Oracle с помощью пакета Jump-Jet», в которой будет детально описан указанный программный продукт, методология обследования, а также приведены примеры успешной оптимизации ИС с его помощью.
Дмитрий Волков, ORACLE 9i OCP, группа программных решений "Инфосистемы Джет".
Сетевые решения. Статья была опубликована в номере 07 за 2004 год в рубрике software
