одиннадцать метрик контроля за успешной и эффективной работой Squid
В этой статье я расскажу вам, как добиться максимально эффективного функционирования Squid’а. Вы должны научиться разрешать проблемы еще до того, как пользователи начнут предъявлять вам претензии.
Для контроля работы в Squid предусмотрены два интерфейса: SNMP и администратор кэша. Каждый из этих интерфейсов имеет свои преимущества и недостатки.
Протокол SNMP удобен для работы в силу того, что он хорошо знаком многим из нас. Если у вас уже где-то используется SNMP-управление, вы сможете легко добавить к объектам управления и Squid . По умолчанию реализация SNMP не компилируется в Squid. Чтобы использовать SNMP, вы должны при компиляции использовать опцию --enable-snmp в ./configure. Это выглядит так: ./configure --enable-snmp ...
Недостатком SNMP является то, что вы не можете использовать его для контроля всех параметров, о которых говорится в этой статье. База MIB Squid’а осталась почти неизменной с момента написания в 1997 году. Некоторые из значений, которые вы должны контролировать, доступны только через интерфейс администратора кэша.
Администратор кэша — это набор «страниц», которые вы можете запросить из Squid’а, используя специальный синтаксис URL. Также вы можете использовать утилиту cachemgr.cgi, чтобы просматривать информацию с помощью веб-браузера. Как вы увидите из примеров, использовать администратор кэша для периодического сбора информации немного неудобно. Решение этой проблемы я дам в конце статьи.
размер процесса
Размер процесса Squid’а оказывает непосредственное влияние на производительность. Если процесс становится слишком большим и не помещается полностью в памяти, ваша операционная система перекачивает часть его на диск (своппинг). Это быстро снижает эффективность, о чем будет свидетельствовать увеличение времени ответа. Размер процесса Squid’ временами трудно контролируем. Он зависит и от числа объектов в кэше, и от числа параллельно работающих пользователей, и от типов объектов, которые они загружают.
Существует четыре способа определения размера процесса Squid’а. Какие-то из них могут не поддерживаться вашей операционной системой. Эти способы реализуются функциями: getrusage(), mallinfo(), mstats() и sbrk(). Функция getrusage() выдает Max RSS (Maximum Resident Set Size). Это самый большой размер области физической памяти, которую данный процесс когда-либо занимал. Данная метрика не всегда самое лучшая, поскольку если размер процесса превышает емкость вашей памяти, значение Max RSS не увеличивается. Другими словами, Max RSS всегда меньше размера физической памяти независимо от того, насколько большим становится процесс Squid’а.
Функции mallinfo()и mstats() входят в состав некоторых библиотек распределения памяти malloc. Они служат хорошими показателями размера процесса (если доступны). Функция mstats(), скажем, присутствует только в библиотке GNUmalloc.
Использование функции sbrk() также хороший способ определения размера процесса и работает это, кстати, в большинстве операционных систем.
К сожалению, единственным параметром, существующим в качестве объекта SNMP, является значение Max RSS, возвращаемое функцией getrusage(). Вы можете получить его с помощью нижеприведенного идентификатора объекта OID базы MIB Squid’а:
enterprises.nlanr.squid.cachePerf.cacheSysPerf.cacheMaxResSize
Чтобы получить другие параметры размера процесса, вам следует использовать администратор кэша. Запросите страницу “info” и поищите эти строки:
# squidclient mgr:info | less
...
Process Data Segment Size via sbrk(): 959398 KB
Maximum Resident Size: 924516 KB
...
Total space in arena: 959392 KB
Вы можете также использовать директиву high_memory_warning в squid.conf, которая предупредит вас, когда размер процесса превысит определенный вами лимит. Например:
high_memory_warning 500
интенсивность ошибок из-за отсутствия страницы
Как я отметил в предыдущем разделе, эффективность Squid’а снижается, когда размер процесса превышает емкость физической памяти вашей системы. Надежным способом обнаружения этого факта является контроль интенсивности ошибок процесса из-за отсутствия страниц.
Ошибка из-за отсутствия страниц возникает, когда программе требуется доступ к той области памяти, которая была перекачана на диск. Ошибки такого рода являются блокирующими операциями. Т.е. процесс приостанавливается до тех пор, пока эта область памяти не считается назад с диска. До тех пор Squid не может выполнять никакую полезную работу. Низкая интенсивность ошибок из-за отсутствия страниц, скажем, меньше одной в секунду, может быть незаметной. Однако с увеличением частоты подобных ошибок запросы клиентов будут требовать все больше и больше времени для выполнения.
Используюя протокол SNMP для управления Squid’ом, мы сможем узнать только о количестве таких ошибок, но не об их интенсивности. Счетчик отражает постоянно растущее значение, определяемое с помощью функции getrusage(). Вы можете рассчитать интенсивность, сравнивая значения, полученные за разные промежутки времени. Такие программы как RRDTool и MRTG делают это автоматически. Вы можете узнать о количестве таких ошибок с помощью следующего OID протокола SNMP:
enterprises.nlanr.squid.cachePerf.cacheSysPerf.cacheSysPageFaults
Вы можете получить этот параметр и из info-страницы администратора кэша:
# squidclient mgr:info | grep 'Page faults'
Page faults with physical i/o: 2712
Вы можете также определить интенсивность, рассчитанную за 5- и 60-минутные интервалы, запросив следующие страницы администратора кэша:
# squidclient mgr:5min | grep page_fault
page_faults = 0.146658/sec
# squidclient mgr:60min | grep page_fault
page_faults = 0.041663/sec
Существует директива high_page_fault_warning в squid.conf, включив которую, вы будете получать уведомление, если Squid обнаружит высокую интенсивность ошибок из-за нехватки страниц. Вы можете указать лимит средней интенсивности, измеренный за интервал в одну минуту. Например:
high_page_fault_warning 10
интенсивность запросов HTTP
Интенсивность запросов HTTP является простой метрикой. Она отражает интенсивность запросов, поступающих в Squid со стороны клиентов. Беглый взгляд на график интенсивности запросов во времени поможет ответить на ряд вопросов. Например, если вы вдруг замечаете, что Squid кажется медленно работающим, вы можете определить, является ли это следствием увеличения нагрузки. Если интенсивность запросов оказывается нормальной, тогда медлительность обусловлена чем-то еще.
Как только вы поймете, каков образец вашей ежедневной нагрузки, вы легко сможете определить странные события, которые могут послужить основанием для дальнейших расследований. Например, внезапное падение нагрузки может говорить о каком-то виде простоя сети, или о том, что рассерженные пользователи поняли, как им обойти Squid. Аналогично, внезапное увеличение нагрузки может означать, что один или более ваших пользователей установили какое-то странное, возможно, запрещенное ПО (например менеджер закачек или клиентскую поисковую машину) или были инфицированы вирусом.
Как и в случае с количеством ошибок, обусловленных отсутствием страниц, вы сможете получить из SNMP только значение счетчика запросов HTTP. Для этого используйте следующий OID:
enterprises.nlanr.squid.cachePerf.cacheProtoStats.cacheProtoAggregateStats.
cacheProtoClientHttpRequests
Администратор кэша сообщает эту информацию разными способами:
# squidclient mgr:info | grep 'Number of HTTP requests'
Number of HTTP requests received: 535805
# squidclient mgr:info | grep 'Average HTTP requests'
Average HTTP requests per minute since start: 108.4
# squidclient mgr:5min | grep 'client_http.requests'
client_http.requests = 3.002991/sec
# squidclient mgr:60min | grep 'client_http.requests'
client_http.requests = 2.636987/sec
интенсивность запросов ICP
Если у вас есть смежные кэши, использующие ICP, вы, вероятно, захотите также контролировать интенсивность запросов ICP. Поскольку запросы ICP мало связаны с эффективностью, контроль, по крайней мере, поможет вам определить, когда смежные кэши работают.
Чтобы получить через SNMP интенсивность запросов ICP, используйте следующий OID:
enterprises.nlanr.squid.cachePerf.cacheProtoStats.cacheProtoAggregateStats.
cacheIcpPktsRecv
Заметим, что счетчик SNMP отражает как запросы, так и ответы, которые получает кэш вашего Squid’а. Нет такого объекта SNMP, который покажет вам только запросы. Информацию только о запросах вы можете узнать от администратора кэша. Например:
# squidclient mgr:counters | grep icp.queries_recv
icp.queries_recv = 8595602
отвергнутые запросы (HTTP и ICP)
Обычно во время работы Squid число отвергнутых запросов небольшое. Однако высокая интенсивность или процент отвергнутых запросов говорит либо 1) об ошибке в правилах контроля доступа, либо 2) о неверной конфигурации со стороны клиента кэша, либо 3) о попытке атаковать ваш сервер.
Если вы используете какие-то специфические правила доступа, базирующиеся на адресах, вам необходимо тщательно отследить изменения IP-адресов клиентов вашего кэша. Например, у вас есть список IP-адресов смежных кэшей. Если один из этих соседей получает новый IP-адрес и не сообщает вам, все его запросы будут отклонены.
К сожалению, не существует легкого способа получить текущую сумму отвергнутых запросов как от SNMP, так и от администратора кэша. Если вы хотите отследить эту метрику, вам следует написать небольшой код, чтобы выделить ее либо из страницы client_list администратора кэша, либо из файла access.log Squid’а.
Страница client_list имеет счетчики для истории запросов ICP и HTTP каждого клиента. Это выглядит следующим образом:
Address: xxx.xxx.xxx.xxx
Name: xxx.xxx.xxx.xxx
Currently established connections: 0
ICP Requests 776
UDP_HIT 9 1%
UDP_MISS 615 79%
UDP_MISS_NOFETCH 152 20%
HTTP Requests 448
TCP_HIT 1 0%
TCP_MISS 201 45%
TCP_REFRESH_HIT 2 0%
TCP_IMS_HIT 1 0%
TCP_DENIED 243 54%
Вы можете написать Perl-скрипт, который выводит IP-адреса клиентов, число отвергнутых запросов которых TCP_DENIED или UDP_DENIED превышает определенный предел. Основная проблема по использованию этой информации заключается в том, что Squid никогда не сбрасывает счетчики. Таким образом, эти значения нечувствительны к кратковременным изменениям. Если Squid был в работе в течение дней или недель, может пройти время, прежде чем счетчики отвергнутых запросов превысят пороговое значение. Чтобы получить более оперативную обратную связь, вы можете поискать запросы UDP_DENIED и TCP_DENIED в файле access.log и посчитать их количество.
время обслуживания HTTP
Время обслуживания HTTP — это время, которое требуется для завершения одной транзакции HTTP. Другими словами, это промежуток времени между чтением запроса клиента и записью последней порции ответа. Обычно время ответа имеет довольно разбросанное распределение, поэтому в качестве неплохого показателя среднего значения мы используем медиану.
В большинстве случаев медиана времени обслуживания должна находиться в диапазоне 100-500 миллисекунд. То значение, которое вы фактически видите, зависит от скорости соединения с Интернетом и от других факторов. Естественно, что это значение колеблется также на протяжении дня. Чтобы понять, что является нормой для вашей инсталляции, вам нужно собрать данные за достаточно большой период времени. Продолжительное время обслуживания может говорить о том, что 1) мощности вашего провайдера перегружены; 2) ваш Squid перегружен или страдает от истощения ресурсов (памяти, файловых дескрипторов, CPU и т.д.). Если сомневаетесь в последнем, просто взгляните для подтверждения на другие метрики, описанные в данной статье.
Чтобы получить пятиминутную медиану времени обслуживания для всех запросов HTTP, используйте этот OID протокола SNMP:
enterprises.nlanr.squid.cachePerf.cacheProtoStats.cacheMedianSvcTable.
cacheMedianSvcEntry.cacheHttpAllSvcTime.5
Просматривая базу MIB, вы можете найти отдельные значения для результативных обращений в кэш, кэш-промахов и 304 (немодифицированных) ответов. Чтобы получить медиану времени обслуживания HTTP от администратора кэша, выполните следующее:
# squidclient mgr:5min | grep client_http.all_median_svc_time
client_http.all_median_svc_time = 0.127833 seconds
Вы также можете использовать в файле squid.conf директиву high_response_time_warning, которая предупредит вас, если время ответа превысит пороговое значение. Например:
high_response_time_warning 700
время обслуживания DNS
Время обслуживания DNS — это похожая метрика, хотя она измеряет только промежуток времени, необходимый для разрешения кэш-промахов DNS. Замеры времени обслуживания HTTP фактически включают время разрешения DNS. Однако поскольку кэш DNS Squid’а обычно имеет высокий процент результативных обращений в кэш, большая часть запросов HTTP не требует временных затрат на разрешение DNS.
Продолжительное время обслуживания DNS обычно указывает на проблему с главным неймсервером Squid’а. Таким образом, если вы видите большую медиану времени ответа DNS, вы должны обратить внимание на проблемы сервера DNS, а не Squid’а. Если вы не в состоянии определить проблему, вы можете выбрать для Squid другой резолвер DNS или, может быть, запустить отдельный резолвер на том же хосте, что и Squid.
Чтобы получить от SNMP пятиминутную медиану времени обслуживания DNS, запросите этот OID:
enterprises.nlanr.squid.cachePerf.cacheProtoStats.cacheMedianSvcTable.
cacheMedianSvcEntry.cacheDnsSvcTime.5
А от администратора кэша:
# squidclient mgr:5min | grep dns.median_svc_time
dns.median_svc_time = 0.058152 seconds
открытые файловые дескрипторы
Файловые дескрипторы относятся к числу конечных ресурсов, используемых в Squid. Если вы не знаете критических лимитов файловых дескрипторов для эффективной работы Squid, прочтите первый раздел статьи «Шесть вещей, которые должен знать новичок-администратор Squid», опубликованной в «СР» №2 за этот год и/или Часть 3 Руководства по Squid: The Definitive Guide.
В процессе контроля использования файловых дескрипторов Squid’а, вы, вероятно, обнаружите, что оно каким-том образом связано со скоростью соединения HTTP и со временем обслуживания HTTP. Увеличение времени обслуживания или скорости соединения приводит к росту использования файловых дескрипторов. Тем не менее, неплохо также обеспечить слежение за этой метрикой. Например, если вы изобразите в виде графика использование файловых дескрипторов во времени и увидите отсутствие прогресса, лимит вашего файлового дескриптора, вероятно, не достаточно высок.
MIB протокола SNMP Squid’а не имеет OID для количества текущих открытых файловых дескрипторов. Однако она может сообщить число неиспользованных (закрытых) дескрипторов. Вы можете либо вычесть эту величину из известного лимита, либо просто узнать число неиспользованных дескрипторов. OID имеет вид:
enterprises.nlanr.squid.cachePerf.cacheSysPerf.cacheCurrentUnusedFDescrCnt
Чтобы получить от администратора кэша число использованных (открытых) файловых дескрипторов, найдите эту строку на странице “info”:
# squidclient mgr:info | grep 'Number of file desc currently in use'
Number of file desc currently in use: 88
загрузка CPU
Загрузка CPU зависит от широкого множества факторов, в том числе железа, включенных функциональных возможностей Squid’а, размера кэша, интенсивности запросов HTTP и ICP и многих других. Более того, высокая степень использования CPU не обязательно является плохим показателем. При всех прочих равных условиях лучше иметь высокую степень использования CPU и высокую интенсивность запросов, чем низкую степень использования и небольшую интенсивность запросов. Другими словами, после удаления узкого места, каковым является ввод/вывод диска, вы можете заметить, что использовнаие CPU растет, а не падает. Это хорошо, поскольку означает, что Squid за тот же промежуток времени справляется с большим количеством запросов.
В данных по использованию CPU есть два момента для наблюдения. Во-первых, любые периоды времени 100% использования CPU говорят о какой-то проблеме, вероятно, о программных неполадках. Henrik Nordstrom обнаружил несовместимость в ядрах Linux 2.2 при использовании функции poll() в то время, когда включена директива half_closed_clients. Этот дефект ядер Linux может привести к периодам 100-процентной загрузки CPU. Чтобы обойти эту ситуацию, вы можете запретить директиву half_closed_clients.
Второй повод для наблюдения за загрузкой CPU заключается в том, чтобы просто быть уверенным, что ваш CPU не становится узким местом. Это может случиться при использовании таких процессороемких фич, как Cache-Digests, CARP или большие списки управления доступом на базе регулярных выражений. Если вы видите примерно 75 % использования CPU, вам необходимо рассмотреть вопрос апгрейда железа.
SNMP MIB Squid’а предоставляет данные по загрузке процессора с помощью следующего OID:
enterprises.nlanr.squid.cachePerf.cacheSysPerf.cacheCpuUsage
К сожалению, это просто отношение процессорного времени к фактическому времени с момента запуска процесса. Это означает, что незначительные изменения в использовании CPU не будут показаны. Чтобы получить более точные измерения, вы должны использовать администратор кэша:
# squidclient mgr:5min | grep cpu_usage
cpu_usage = 1.711396%
свободное пространство на диске
Дисковое пространство — еще один конечный ресурс, расходуемый Squid. Когда вы запускаете Squid на выделенной системе, контроль за использованием диска является относительно легкой задачей. Если у вас есть другие приложения, использующие те же разделы диска, что и Squid, вам следует быть немного более осторожным. Мы должны побеспокоиться о пространстве на диске по двум причинам: возможно разрастание кэша и файлов регистрации.
Если Squid во время записи в кэш получает сообщение об ошибке “no space left on device” (на устройстве не осталось места), он сбрасывает размер кэша и продолжает работу. Другими словами, это не фатальная ошибка. Устанавливается новый размер кэша, который Squid считает текущим размером. Это также побуждает Squid начать удаление существующих объектов, чтобы создать пространство для новых. Однако выход за пределы области при записи файла регистрации является фатальной ошибкой. Процесс Squid заканчивает работу, а не продолжает ее без возможности записи логов.
Информацию о свободном месте на диске можно получить только при помощи администратора кэша. Более того, Squid сообщает вам только о директориях cache_dir. Он не сообщит вам о раздела, где вы храните ваши файлы регистрации (если только эта область не является также кэш-директорией). Из этого следует, чтобы управлять свободным пространством в вашем разделе с логами, вы можете разработать свой собственный простой скрипт. Страница storedir администратора кэша имеет для каждой кэш-директории раздел, подобный этому:
Store Directory #0 (diskd): /cache0/Cache
FS Block Size 1024 Bytes
First level subdirectories: 16
Second level subdirectories: 64
Maximum Size: 15360000 KB
Current Size: 13823540 KB
Percent Used: 90.00%
Filemap bits in use: 774113 of 2097152 (37%)
Filesystem Space in use: 14019955/17370434 KB (81%)
Filesystem Inodes in use: 774981/4340990 (18%)
Flags:
Pending operations: 0
Removal policy: lru
LRU reference age: 22.46 days
Нас особенно интересуют две строки: “Percent Use” и “Filesystem Space in use”.
В строке “Percent Use” показано, сколько метста на диске использовал Squid по сравнению с тем размером, который указан в строке cache_dir. Она обычно равна или меньше значения для cache_swap_low.
В строке “Filesystem Space in use” показано, сколько места фактически занято на этом разделе.
Squid получает информацию от системного вызова statvfs(). Она должна совпадать с той информацией, которую можно увидеть при запуске df из шелла.
доля результативных обращений
Доля результативных обращений в кэш, или кэш-попаданий, является еще одной метрикой, которая может время от времени значительно изменяться. Высокая степень ее изменчивости не всегда является хорошим показателем. Внезапное падение доли кэш-попаданий означает, что один из клиентов кэша является специальной программой вроде клинетского поискового ПО, или еще чем-то, добавляющим к запросам заголовок no-cache. Вероятно, в процессе контроля лучше всего просто понять, сколько успешных запросов обслуживается непосредственно из кэша (если босс просит вас обосновать наличие Squid’а).
Процент кэш-попаданий за последние 5 минут вы можете получить с помощью этого запроса OID SNMP:
enterprises.nlanr.squid.cachePerf.cacheProtoStats.cacheMedianSvcTable.
cacheMedianSvcEntry.cacheRequestHitRatio.5
Та же информация есть на info-странице администратора кэша:
# squidclient mgr:info | grep 'Request Hit Ratios'
Request Hit Ratios: 5min: 29.8%, 60min: 44.1%
моя утилита Squid-rrd Monitoring
Администратор кэша в большей или меньшей степени предоставляет более полезную информацию, чем реализация SNMP. Однако выходные данные кэш-администратора требуют обработки. Вам было бы не просто написать пакет программ, чтобы собрать всю относящуюся к делу информацию и выделить нужные значения. Особенно, когда я уже сделал это для вас :).
У меня есть perl-скрипт, недавно усовершенствованный Dan’ом Kogai, который предназначен для выполнения запросов к кэш-администратору и сохранения ответов в базе данных RRD. Если вы ничего не знаете о таком инструменте, как RRDtool, вам необходимо с ним познакомиться, потому что он очень классный! :)
Мой скрипт периодически запускается из cron’а. Он выполняет запросы к кэш-администратору и использует регулярные выражения, чтобы обработать выходные данные для определенных метрик. Полученные значения хранятся в различных файлах RRD. У меня есть также шаблонный CGI-скрипт, который отображает данные RRD.
Мой код и документацию вы можете найти на сайте: www.squid-cache.org/~wessels/squid-rrd. Ниже приведено несколько примеров диаграмм. Другие диаграммы вы можете посмотреть, посетив мою страницу статистики для прокси IRCache:www.ircache.net/Cache/Statistics/Vitals/rrd/cgi.
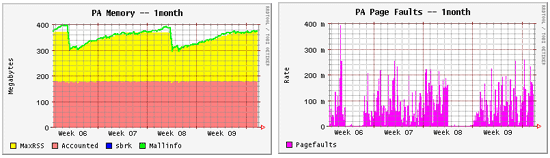
Рис. 1.
На первых двух диаграммах (см. рис. 1) показаны использование памяти и интенсивность отказов из-за отсутствия страниц в течение одного месяца. На них ясно видно, когда рестартовал Squid (по падению использования памяти). На диаграмме видно также, как растет интенсивность отказов из-за отсутствия страниц по мере увеличения загрузки памяти.
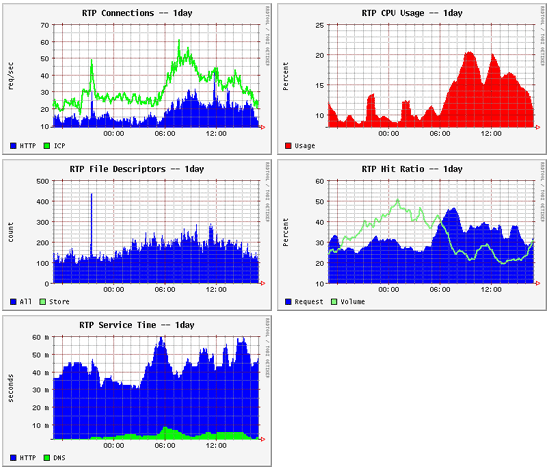
Рис. 2.
На следующих пяти диаграммах (рис. 2) показаны различные метрики за 24-х часовой период. Вы видите, как рост нагрузки вызывает соответствующий рост использования CPU, файловых дескрипторов и, в какой-то степени, увеличение времени ответа. На диаграмме использования файловых дескрипторов виден короткий пик в поздние вечерние часы.
Duane Wessels, перевод Ларисы Семченко.
Сетевые решения. Статья была опубликована в номере 04 за 2004 год в рубрике sysadmin
