обработка документов как основа построения информационных систем
введение
В данной работе предложен подход к построению информационных систем, основанный на обработке документов. Понятие “документ” формализовано, что позволяет точно описать представление документа в реляционных и иерархических СУБД. Эта технология позволяет строить информационные системы из “кубиков”, которыми являются отдельные модули, выполняющие преобразования документов.
Типичная информационная система выполняет набор функций, который обычно включает в себя следующие:
1. Ввод документов (с бумаги или в электронном виде).
2. Хранение этих документов.
3. Поиск по запросам (как предопределенным, так и незапланированным).
4. Редактирование операторами.
5. Создание выходных документов (на бумаге или в электронном виде).
Схематично это можно изобразить так:
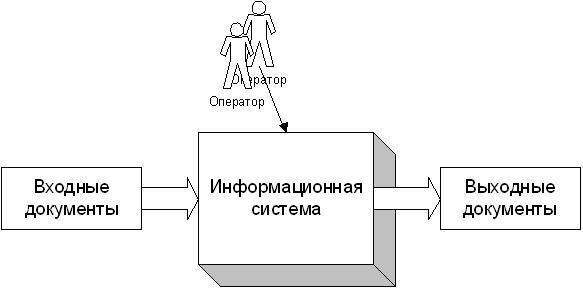
Обычно эти пункты реализуются разными способами:
1. Ввод документов специализированными средствами (сканирование и распознавание бумажных документов, разметка по реквизитам электронных неструктурированных документов) с последующим экспортом в какой-нибудь общеупотребительный формат (CSV, DBF и т.д.). Далее происходит импорт файлов из данного формата во внутреннее представление СУБД.
2. Хранение и поиск осуществляется средствами СУБД (чаще всего реляционной).
3. Редактирование осуществляется созданными специально для данной системы средствами, тесно связанными с конкретной СУБД.
4. Выходные документы создаются в два этапа: выполнение запроса к базе данных и заполнение на основе полученных данных выходных форм.
Видно, что на разных этапах документ имеет различное представление (файл в формате CSV, DBF или иной, внутреннее представление СУБД, внутреннее представление редактора, внутренние структуры подсистемы выходных документов), работа с ним происходит с помощью разных механизмов.
В данной работе предлагается унифицированное решение, которое базируется на едином представлении документа.
жизненный цикл документа
Жизненный цикл документа внутри информационной системы можно изобразить следующим образом:
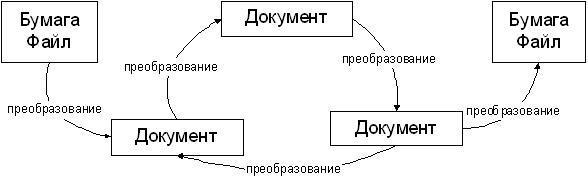
В системе существует несколько типов документов. В процессе жизненного цикла документ создается, преобразуется из одного типа в другой, становится основой для создания новых документов и, в конце концов, уничтожается.
В данной работе предлагается унифицировать представление документа так, чтобы на всех этапах жизненного цикла работа с ним велась единообразно. Это позволит выделить часто встречающиеся преобразования для повторного использования в других информационных системах. Кандидатами на такие преобразования являются:
1. Подсистема ввода — представление результатов распознавания бумажных документов.
2. Редактор структурированных документов — формат редактируемых данных.
3. Подсистема поиска — представление найденных документов.
4. Подсистема вывода — формат входных документов для генератора отчетов.
примеры преобразований
входные преобразования
Можно выделить несколько источников для входных преобразований:
1. Неэлектронный документ.В этом случае происходит распознавание в том или ином виде: распознавание текста отсканированных бумажных документов, распознавание речи, введенной с микрофона и т.д.
2. Неструктурированный документ.Необходимо выделение информации из такого документа. Примерами могут служить рубрикация, авторефирирование, автовыделение информации определенного типа: дат, географических названий, номеров телефонов и т.д.
3. Структурированный документ.Это самый простой случай. Здесь необходимо лишь преобразование данных из одного формата в другой, например из DBF в XML.
выходные преобразования
Выходное преобразование переводит структурированную информацию в неструктурированную. Результатом являются, как правило, текстовые форматы, предназначенные для печати — HTML, RTF, TEX, PDF и другие.
Преобразование может предваряться подготовкой данных и, возможно, их агрегацией. Это делают программы, называемые обычно генераторами отчетов.
формальное определение документа
Формальное определение документа является модифицированной моделью объект/отношение (сущность/связь, Entity/Relationship). Особенности приложения модели к данной задаче следующие:
1. Объекты(сущности):
— нет различия междуслабымиисильными;
— тип объектов обязательно имеет имя;
— объекты могут иметьметаданные(не путать со свойствами, см. далее).
2. Свойства(реквизиты):
— толькопростые, нетсоставных(структур);
— естьключевые свойства, уникальные в контексте отношения;
— возможныоднозначныеимногозначныесвойства. Под многозначными свойствами понимается неупорядоченное множество попарно различных элементов (т.е. порядок элементов не сохраняется);
— свойства могутотсутствоватьу экземпляров;
— нетпроизводныхсвойств (таких, как сумма, среднее, минимум, максимум и т.д.);
— свойства (как и объекты) могут иметьметаданные.
3. Отношения.Возможны отношения как состепеньюдва (бинарные), так и более.
4. Подтипыотсутствуют.
По сути единственным серьезным дополнением модели сущность/связь является концепция метаданных.Метаданные документа— это некоторая дополнительная информация, которая семантически не может быть отнесена к свойствам документа. Например, идентификатор документа является внутренней информацией, которая актуальна для хранилища, но ее бессмысленно делать свойством.Метаданные свойства— это дополнительная информация о свойстве, которая отражает его представление в прикладной программе и влияет на его обработку. Например, прямоугольник привязки в системах распознавания текстов или разметка реквизита в информационных системах являются метаданными свойства.
Метаданные могут быть только простых типов или являться отношения — образующими (иными словами, являться ссылками на другие типы).
Документ— это множество объектов, связанных отношениями, с одним выделенным объектом — корневым.
унифицированный доступ к документам
Как уже отмечалось выше, в процессе своего жизненного цикла документ представляется различными способами: файл в различных форматах, внутреннее представление конкретной СУБД, внутреннее представление редактора, внутренние структуры подсистемы выходных документов.
Суть предложения — создать объектно-ориентированное представление документа как структуры данных современных объектно-ориентированных языков программирования. Особо следует подчеркнуть, что это не то же самое, что представление в объектно-ориентированных базах данных. ООБД задумывались для того, чтобы сократить разрыв между ООЯП и базами данных. Но в настоящее время этот разрыв пока достаточно велик. Задача объектно-ориентированного представления документа является менее общей и потому более простой, чем задача создания полноценной объектно-ориентированной СУБД.
Повторюсь еще раз, унифицированный доступ к документам призван решить лишь следующие задачи:
— создание документов из внешних источников (оптическое распознавание текстов и форм, структуризация данных, такая как рубрикация, и т.д.);
— хранение документов в современных базах данных;
— поиск документов;
— редактирование документов средствами редактора форм;
— создание выходных документов, таких как отчеты.
Для решения поставленной задачи предлагается следующая технология:
1. Создать описание документов. Это может быть сделано средствами конкретной СУБД с последующим преобразованием в XML-схему или непосредственным рисованием в редакторе XML-схем.
2. Преобразовать описание в набор файлов на современном языке программирования, например на Си++.
3. Включить в набор исходных текстов создаваемой информационной системы полученные файлы, а также заранее оттранслированную библиотеку, на которую опираются эти файлы.
4. В результате программа будет иметь доступ к документам вне зависимости от их физического представления, формата данных и т.д. Всюду они будут видны как структуры данных на обычном языке программирования.
хранение документов в базах данных
Самым важным моментом в любой информационной системе является хранение документов в базе данных. Основными характеристиками являются скорость выполнения запросов и занимаемый объем.
реляционные БД
Соответствие между формальной моделью документа и представлением в реляционной СУБД:
— каждой сущности соответствует кортеж;
— однозначным свойствам соответствуют атрибуты кортежа;
— многозначные свойства представляются повторяющимися кортежами;
— ключевым свойствам соответствует ограничение на уникальность атрибутов;
— отсутствующим свойствам соответствуют NULL-значения;
— бинарному отношению типа “один ко многим” и “один к одному” соответствует дополнительное поле в кортеже, соответствующему сущности на стороне “многие”. Атрибутам отношения соответствуют поля в этом же кортеже;
— Бинарному отношению типа “многие ко многим” и отношениям со степенью более двух соответствуют кортежи с полями — внешними ключами, указывающими на кортежи — участники отношения. Атрибутам отношения соответствуют поля в этом же кортеже;
— метаданные представляются дополнительными полями в кортежах, соответствующих сущностям и свойствам.
иерархические БД
Соответствие между формальной моделью документа и представлением в реляционной СУБД:
— каждой сущности соответствует структура;
— однозначным свойствам соответствуют вершины в структуре;
— многозначные свойства представляются вершинами типа “массив структур” со структурами, имеющими единственное ключевое поле, соответствующее свойству;
— ключевым свойствам соответствуют ключевые вершины в структуре;
— отсутствующим свойствам соответствуют отсутствующие вершины;
— бинарному отношению типа “один ко многим” и “один к одному” соответствует вершина в структуре, соответствующей сущности на стороне “один”. Тип этой вершины — массив структур, соответствующих сущности на стороне “многие”. Атрибутам отношения соответствуют дополнительные вершины в дочерней структуре. Ключом в этой структуре является либо вершина, являющаяся естественным уникальным идентификатором, либо, в отсутствие таковой, искусственно добавленная вершина целого типа со случайным значением;
— Безатрибутному бинарному отношению типа “многие ко многим” соответствует вершина в одной из структур. Тип вершины — ссылка на значение, указывающая на другую структуру.
— атрибутному бинарному отношению типа “многие ко многим” и отношениям со степенью более двух соответствует вершина в одной из структур. Тип вершины — структура. Поля этой структуры — ссылки на значения, указывающие на структуры — участники отношения. Атрибутам отношения соответствуют поля в этой структуре;
— метаданные сущностей и свойств представляются дополнительными вершинами в структурах, соответствующих сущностям.
объектно-ориентированные БД
В настоящее время ООБД еще не дошли до такой высокой степени развития, когда их можно было ставить на одну ступень с реляционными или иерархическими.
В разных ООСУБД формальный документ может быть представлен совершенно по-разному. В IDL консорциума ODMG есть способ явно описать отношения, во многих других ООСУБД — нет. Поэтому отмечу лишь, что такое соответствие может быть неким средним между реляционными и иерархическими СУБД.
XML-файлы
XML-представление документов очень похоже на представление в иерархических СУБД. Только вместо дерева описания данных фигурирует XML-схема. Фактически, она позволяет описать все те же самые понятия в других терминах — терминах стандарта XML.
эффективность
Предлагаемый унифицированный метод доступа к документам — это всего лишь способ абстрагирования от физического представления данных. Вопросы эффективности относятся к конкретному физическому хранилищу. Что касается алгоритма построения схемы БД по описанию структуры документа, то она соответствует обычной практике, применяемой для реляционных и иерархических СУБД. В частности, для иерархических СУБД составные части одно документа оказываются физически расположенными в близких кластерах на диске.
база документов
В последнее время появилось новое направление в развитии СУБД — документные БД. Они рассматриваются своими создателями как новый вид баз — их не считают ни реляционными, ни иерархическими, ни объектно-ориентированными. Это веяние появилось после того, как достаточно широкое распространение получил язык XML и связанные с ним стандарты.
Примером такой СУБД является продукт TAMINO компании Software AG.
Данная разработка позволит получить доступ к обычным базам данных, как к базам документов.
веб-приложения
Одним из важных приложений данной работы является создание веб-приложений. Типичное приложение состоит из некоторого набора программ, вызываемых по запросу клиента. Все программы устроены примерно одинаково. Они выполняют разбор входных параметров. В зависимости от этих параметров выполняются действия с базой данных (добавление, редактирование, удаление, выборка записей) и формируются выходные данные — HTML-страница.
Важный момент заключается в том, что данные в базе данных имеют туже или почти туже структуру, что и входные, и выходные данные.
Чем плохи популярные в настоящее время языки perl и PHP? В них не проверяется логическая корректность ни входных, ни выходных данных. Например, если программа ожидает получить целое число, а на вход приходит строка, то отследить этот факт — задача самой программы. Аналогично при выводе результата — получаемый HTML может содержать ошибки, такие как несбалансированность тегов, незакрытые комментарии и т.д. Нахождение таких ошибок остается на программисте, хотя это прекрасно могла бы сделать и система.
В настоящее время входные данные для веб-приложений представляют собой список пар “имя”=“значение”. И на первый взгляд может показаться, что использование в данном случае структурированных документов излишне. Но это неверно. Дело в том, что на вход программе могут поступать и структурированные данные. В этом случае приходится преодолевать данное ограничение формата HTML и протокола HTTP какими-нибудь искусственными преобразованиями имен. В настоящее время ведутся работы над стандартом XForms, который позволит передавать из HTML-форм в программы сложно структурированные данные.
сервер приложений
Использование предлагаемой технологии позволит строить серверные компоненты так, чтобы к ним могли обращаться как “тонкие” клиенты, так и “толстые”. Первые имеют много преимуществ, связанных с тем, что в качестве такого клиента выступает обычный браузер. Поэтому пользователю не нужно заботиться об инсталляции различных клиентских программ — с помощью браузера он может работать с любым веб-приложением. Однако такая технология имеет и недостатки — тонкий клиент может предоставить не все возможности по просмотру данных и лишь самые простые по их модификации. Для серьезной удаленной работы с информационной системой нужна полноценная клиентская программа. Данная разработка позволяет решать такие задачи следующим образом:
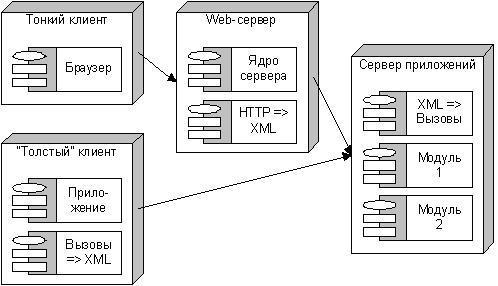
Модули, реализующие содержательную функциональность (бизнес-логику), реализуются на сервере приложений. На веб-сервере располагается дизайн страниц, но нет никаких программ. При поступлении HTTP-запроса к какому-либо модулю выполняется входное преобразование в XML-представление параметров, затем запрос передается серверу приложений, над результатом выполнения функции выполняется преобразование в HTML с использованием шаблонов дизайна.
Отличительной особенностью такой технологии является независимость веб-сервера от изменения программ. При появлении новой функциональности единственное, что нужно сделать — это предоставить дизайн для представления результатов новых модулей. Никакого программирования на веб-сервере нет.
интеграция с устаревшими системами
В реальной жизни довольно часто возникают задачи примерно следующего содержания. Существует некоторый программный комплекс, разработанный несколько лет тому назад, который хранит свои данные в реляционной базе. Комплекс реально функционирует, и эти данные постоянно изменяются. Необходимо написать некоторый новый модуль, который обеспечил бы дополнительную функциональность при работе с этими же данными. Создавать этот модуль с использованием тех же технологий, с помощью которых был написан и сам комплекс, выглядит неразумным. Намного логичнее использовать современные достижения в области объектно-ориентированных технологий, которые позволят сократить сроки разработки и повысить качество программ.
Одним из выходов является создание новой объектно-ориентированной БД и специальной программы, которая будет периодически конвертировать данные из старой базы в новую и обратно. Но такой комплекс из двух систем будет трудно обслуживать, конвертация чревата возникновением ошибок, нарушением целостности данных и т.д.
Предлагаемая технология позволит создать объектно-ориентированный документный интерфейс к старой базе данных. Кроме того, она позволит сделать распределенную систему, в которой часть данных расположены в старой БД, а часть в новой. Программы при этом будет работать с базами одинаково.
проектирование и язык UML
В начале статьи было сказано, что основой для описания структуры документа может быть схема базы данных (реляционной или иерархической) или XML-схема. В будущем этот список может быть дополнен описанием данных на языке UML. Сам по себе UML описывает лишь представление программного комплекса с помощью диаграмм. Однако в настоящее время существует стандарт XMI, который описывает формат данных, предназначенный для хранения UML-описаний.
предыстория
Идея разбиения сложной системы на модули на основе обрабатываемых данных не нова. В частности, она положена в основу конвейерной обработки в операционной системе UNIX. В ней существует довольно много самостоятельных утилит, управляемых из командной строки. Каждая из них выполняет самостоятельную функцию. Программист имеет возможность собрать из этих утилит довольно сложную систему. Все эти программы ориентированы на построчную обработку. Все они предполагают, что файл состоит из строк. Некоторые дополнительно считают, что каждая строка состоит из полей, перечисленных через разделители.
Предлагаемая технология отличается тем, что в ней построчная обработка заменена смысловой обработкой блоков, составляющих документ. Она может быть как линейной (полная аналогия с плоским текстовым файлом), так и рекурсивной.
Говоря о предыстории, нельзя не сказать о “классической” схеме построения информационной системы, когда все данные хранятся в единой базе данных, и все подсистемы общаются с этим единственным хранилищем. В реальных системах далеко не всегда удается поместить все данные в одну базу. В первую очередь это касается случаев, когда компания уже имеет одну или несколько информационных систем, и вновь создаваемая система должна с ними взаимодействовать, быть может, плавно забирая на себя их функциональность. Другая ситуация — распределенная компания, офисы которой не имеют каналов связи, достаточных для взаимодействия в режиме online средствами СУБД или иных стандартных средств. Остается возможность передачи информации лишь на уровне приложений. В таких случаях обмен осуществляется с помощью документов.
заключение
В данной работе предложен подход к построению информационных систем, основанный на понятиях “документ” и “преобразование документа”. Применение этой технологии позволяет строить информационные системы из “кубиков”, которыми являются отдельные модули, выполняющие преобразования.
Технология позволяет единообразно подходить к приему входных, обработке внутренних и созданию выходных документов. Кроме того, она позволяет строить распределенные системы, основанные на различных СУБД, интегрировать новые разработки и устаревшие системы, иметь доступ к обычным БД, как к базам документов, реализовывать сервера приложений, используемые и “тонкими”, и “толстыми” клиентами, создавать надежные веб-приложения.
Внедрение и использование этой технологии не имеет серьезных технологических рисков, так как она не вносит фундаментальные изменения в архитектуру информационной системы, а является связующим звеном между существующими в настоящее время и проверенными годами технологиями.
Обработка данных производится эффективно, т.к. это делается средствами традиционных компилируемых языков программирования.
Порай Д.С.
обсуждение статьи
Сетевые решения. Статья была опубликована в номере 03 за 2004 год в рубрике технологии
