Oracle: эффективность сквозной кластеризации
Когда речь заходит о кластеризации, проектировщик системы должен осознать различия между применением аппаратных (hardware-based) и программных (software-based) кластеров. Кластеризация — задача весьма сложная на практике, хотя на уровне определений она выглядит достаточно просто.
Кластеризация — это распределение аппаратуры и программного обеспечения по узлам, которые работают вместе как единая система с тем, чтобы гарантировать продолжение функционирования пользовательских приложений во время чрезмерных нагрузок, либо в случае выхода из строя одного из узлов кластера. Кластеризация становится все более популярной, благодаря недавним улучшениям программного обеспечения управления внешней памятью и приложений, что облегчает этот процесс и делает его более приемлемым в ценовом отношении. А это особенно важно сейчас, когда руководители организаций скупы в отношении расходов на ИТ. Конечно, наличие мощных и очень надежных серверов очень привлекательно, но они весьма дороги. Поэтому многие компании, включая Oracle, используют недорогие массово выпускаемые серверы. Но такой подход ведет к тому, что в сравнении с мощным сервером нагрузка на каждый “малый” сервер меньше и вероятность его сбоя выше.
Ключевым становится следующий вопрос: "Как обеспечить необходимую мощность и надежность уровня предприятия нашим приложениям при условии применения менее надежных серверов?" Ответ: решением будет эффективная кластеризация. Но, как говорится, дьявол таится в деталях. Сразу же возникает множество проблем, как, например, соответствие потребностям приложений, состав необходимой аппаратуры, структура программного обеспечения. Возможность кластеризации может быть учтена уже при проектировании программного обеспечения приложений. Мы рассмотрим различные способы создания кластеров и покажем, что построение эффективных кластеров не сводится к применению одного единственного подхода, необходимо рассмотрение ряда возможностей, из которых для реализации отбираются наиболее походящие для ваших приложений.
аппаратная кластеризация
Кластеры можно разделить по категориям в соответствии с назначением их основного использования.
Кластеры высокой готовности (high-availability clusters), или отказоустойчивые (failover),применяются для того, чтобы не допустить прекращения обслуживания в случае выхода из строя основного сервера. Как правило, в этом случае используется дублирующий сервер.
Кластеры с балансировкой нагрузки (load-balancing clusters)обеспечивают более эффективное использование ресурсов вычислительной системы. В случае высоких нагрузок на серверы, запросы перенаправляются на наименее загруженные серверы.Кластеры высокой производительности (high-performancesters clusters) обычно применяются для достижения высокой скорости вычислений. Типичные для этого случая приложения: прогнозирование, в том числе погоды, и научные вычисления. Для получения результатов за короткий промежуток необходимо параллелизировать вычисления. С этой целью первыми были использованы кластерные системы с массивно-параллельной обработкой данных (massively parallel processing (MPP)). На уровне аппаратуры можно и далее продолжить классификацию: кластер из ПК, кластер из рабочих станций, кластер из SMP-серверов (SMP — symmetric multiprocessing, многопроцессорная симметричная архитектура) с операционными системами Linux, Solaris, NT и т.д.
Очень важен правильный выбор аппаратуры, которая наилучшим образом соответствует вашим потребностям, и способа соединения серверов. Ряд технологий высокопроизводительной коммуникации пакетов и переключения могут быть использованы для соединения рабочих станций, ПК и серверов, входящих в кластеры. Но вместо этих технологий вы можете отдать предпочтение Ethernet, это зависит от производительности и уровня высокой готовности (high-availability) вашей вычислительной среды. Для повышения пропускной способности сети архитекторы/проектировщики могут выбирать между 100 Мбит/с-сетевыми картами и Gigabit Ethernet для получения нужной скорости передачи данных. Другие варианты — это Myrinet, SCI, FC-AL, Giganet, GigE и ATM, но в каждом из этих случаев цена кусается.
Также очень важно скомпоновать аппаратуру кластера наилучшим образом. Более сложно применение разнородных кластеров, аппаратура которых относится к различным архитектурам, так как узлы могут подсоединяться (и отключаться) к кластеру в разные моменты времени. Крайне желательна в аппаратных кластерах внешняя память со средствами зеркалирования (mirroring storage) для защиты от сбоев среды хранения данных. Например, в случае простого двухузлового кластера, совместно используемая внешняя память может состоять из диска с двумя портами (dual-ported disk), к которому можно обращаться обоих узлов. В этом случае также могут быть нужны специальные кабели для соединения сетевых карт/коммутаторов/хабов.
Если для защиты кластера от системного сбоя применяется “холодное” резервирование ("cold" standby), то необходимо ручное переключение от засбоившего основного сервера к запасному. Но такой подход приводит к прерыванию работы приложения на некоторое время, так как запасной сервер нужно запустить, а приложение перестартовать. “Горячее” резервирование включает автоматическое переключение с сбоившего основного сервера на запасной, который до этого не выполнял работы. В этом случае запасной сервер запускается автоматически и “перехватывает” нагрузку с основного.
Но ни один из этих двух (холодное, горячее) способов резервирования не исправляет повреждения корневой файловой системы (root file systems). Для разрешения этой проблемы в аппаратных кластерах иногда используют свои собственные загрузчики (boot drive), либо средства зеркалирования, реализованные на уровне аппаратуры. Так как приложения часто становятся недоступными в результате сбоев дисков, то системные администраторы, как правило, используют запасные серверы со средствами зеркалирования дисков, а также технологию RAID (Redundant Arrays of Independent Disks). В этом случае информация хранится на нескольких дисках, которые являются зеркалами друг друга. Важно понимать особенности различных архитектур аппаратных кластеров.
В архитектуре с совместно используемой оперативной памятью (shared-memory architecture) множество процессоров используют общую шину памяти, такие системы определяются как SMP-системы. В этой архитектуре пропускная способность шины часто становится проблемой по мере добавления узлов.
В архитектуре с совместно используемыми дисками (shared-disk architecture) множество SMP-серверов совместно используют дисковую память для повышения уровня готовности.
Архитектура без разделения ресурсов (shared-nothing architecture) предполагает, что у каждого узла своя собственная оперативная память, свои диски и процессоры. Преимуществом такого подхода является задействование большей пропускной способности по мере добавления узлов.
С течением времени аппаратные кластеры постепенно развиваются. В 80-х годах использовались векторные системы. Затем наступила эра суперкомпьютеров и MPP-систем, а теперь используются кластеры и сети распределенных вычислений (grids). Ряд поставщиков предлагают конкурирующие между собой платформы с различными уровнями поддержки для перечисленных выше архитектур аппаратных кластеров, а также параллелизма, чтобы сделать аппаратные кластеры реальностью. Но по прежнему создание больших аппаратных кластеров с N узлами требует тщательного продумывания и планирования, и немалого бюджета.
кластеры с балансировкой нагрузки
Технологии аппаратной кластеризации называются стратегиями “пещерного человека” ("caveman"), потому что они не очень развиты, наиболее легки в применении и дешевы. Если одна их них используется как единственное кластеризированное решение, то оно применимо только для простейших приложений типа презентаций. “Пещерная” кластеризация предполагает использование множества узлов (серверов с идентичными установками вашего приложения) плюс некая дополнительная аппаратура на серверных узлах для управления и распределения нагрузки.
Например, наиболее простая “пещерная” технология — это циклическая (round-robin) служба доменных имен DNS (domain name service), которая использует маршрутизатор и DNS-сервер для циклической рассылки различных пользовательских запросов по всем серверам приложений, так что ни один узел не отягощается Так как у каждого узла есть свой IP-адрес, то легко ввести последовательные URL справочные DNS-файлы и связать их с адресами всех узлов: www1.companyXYZ.com с 143.10.25.1, www2.company.com с 143.10.25.2 и т.д. Маршрутизатор затем распределит пользовательские запросы по списку URL циклическим образом. Масштабирование в этом случае реализуется достаточно легко: чтобы добавить новый сервер, просто дайте ему последовательный URL в справочном файле DNS-сервера и затем прикрепите этот URL к IP-адресу нового сервера.
Следующим шагом за циклической DNS было применение IP-распределителя (sprayer), устройства подобного маршрутизатору, которое располагается между входящими (inbound) пользовательскими запросами и узлами серверов приложений. Этот метод похож на циклическое решение, за исключением того, что IP-распределители “разбрасывают” или перенаправляют запросы к нескольким узлам. IP-распределители более динамичны и менее произвольны в выборе, чем циклические маршрутизаторы, так что недозагруженнные серверы могут быть использованы более эффективно. Однако, IP-распределители требуют применения SSL-декодеров в случае использования протокола SSL (Secure Sockets Layer — протокол защищенных сокетов, гарантирующий безопасную передачу данных по сети).
Еще одной альтернативой является применение реверсивных прокси (reverse-proxy) HTTP-серверов, которые используются в основном как защита от атак злоумышленников, но могут применяться и для балансировки нагрузки. Это способ требует использования кэширования, как правило, связываемого с доступом к веб-страницам, в оперативной памяти HTTP-серверов, чтобы снять нагрузку, насколько это возможно, с узлов серверов приложений. Реверс-прокси метод требует использования циклической кластеризации, чтобы предохранить HTTP-серверы от перегрузки.
Другие способы балансировки нагрузки — это единый IP-образ на стороне сервера (server-side single IP image) и трансляция сетевых адресов (network-address translation); оба эти способа дороже и сложнее и требуют изменений заголовков пакетов на основе особенностей нагрузки.
проблемы отказоустойчивости кластеров с балансировкой нагрузки
Основная проблема по части аппаратуры в разрешении вопросов кластеризации заключается в том, что никакая аппаратура не позволяет удовлетворительно справиться с сбоями узлов. Если компонент сервера (или приложения) засбоил в “пещерной” системе, то весьма вероятно, что пользователь подумает, что вышла из строя вся система. Например, предположим, что внезапно засбоил четвертый узел в циклической или реверс-прокси установке. Если этот узел включен список циклического опроса, то любой входящий пользователь, скорее всего, получит сообщение об ошибке DNS, так как этот сервер не сможет ответить. Чтобы продолжить работу, пользователь должен выйти из системы и в новом сеансе запустить маршрутизатор.
Кроме того, именно аппаратура балансировки нагрузки (DNS-сервер или IP-распределитель) может стать “узким местом” и, тем самым, той единой точкой отказа, выход из строя которой обрушивает всю систему. Поэтому никакая “пещерная” технология не подходит для таких приложений, в которых, например, пользовательские данные должны быть внесены экран за экраном (как в карточных приложениях обслуживания покупок). В случае же “пещерной” установки при выходе из строя узла, обслуживающего активного пользователя, теряется вся информация данной сессии.
Для “пещерных” систем характерны высокие цены. Технология RAID требует много устройств для работы с дисками, и эти расходы быстро растут по мере масштабирования как ваших приложений, так и самого кластера. Время простоя пользовательских приложений может слишком дорого стоить, особенно для жизненно-важных приложений. Итак, что касается технологий аппаратной кластеризации, самое главное заключается в том, что для них возможна только почти тотальная защита (но она очень дорога), и такие решения требуют наличия администраторов, которые умеют конфигурировать подобные системы, справляться со сбоями дисков, соединять компоненты кластеров, а также решать сложные сетевые проблемы.
программные решения: веб-кэшированная кластеризация
Возможно применить программное обеспечение для того, чтобы разрешить то, что по существу является аппаратной проблемой. Отказоустойчивые возможности такой программной инфраструктуры, какой, например, является Oracle9i Application Server (Oracle9iAS), могут обеспечить и динамическую балансировку нагрузки, и высокую готовность, необходимую для сложных и критичных приложений, и стоить только часть цены аппаратного кластера. Создание кластеров на базе Oracle9iAS Web Cache — это замечательный пример использования программного обеспечения для преодоления сбоев и управления трафиком приложений. Веб-кэш предшествует узлам-серверам и подобно обычному кэшу отвечает на все входящие HTTP-запросы и распределяет эти запросы согласно возможностям каждого веб-сервера. В гипотетическом кластере, состоящем из серверов A, B и C, мы сможем сконфигурировать Web Cache для распределения 30% всей нагрузки к веб-серверу A, других 30% к веб-серверу B и 40% к веб-серверу C.
Подобно технологии реверс-прокси, данное решение обладает тем же ключевым преимуществом: если один из этих трех серверов выйдет из строя, Oracle9iAS Web Cache сможет автоматически перераспределять 50% нагрузки по двум остающимся в строю веб-серверам. Когда же засбоивший сервер вернется в строй, Web Cache вновь перераспределит нагрузку по всем трем серверам, и все это будет незаметно, прозрачно для пользователя.
Oracle9iAS Web Cache также поддерживает состояние сессий, не обременяя узлы серверов приложений. Он также обслуживает сайты, которые используют идентификаторы сессии (session ID) и жетоны (cookies). Но поддержка состояния сессий на уровне веб-сервера может быть обременительна, и лучшим решением будет обеспечение минимального, насколько это возможно, набора параметров состояния сессий и только на очень короткие промежутки времени. Для более долгих сессий и больших наборов подобных параметров стоит рассмотреть применение базы данных.
И еще один довод за создание кластеров на базе Oracle9iAS Web Cache — это возможность одного Web Cache взаимодействовать с другими кэшами на этом кластере, чтобы тем самым увеличить общую пропускную способность. Каждый Web Cache обнаруживает новый контент у своего “напарника” и может сохранить его в своем собственном кэше. Также отслеживается и случай выхода из строя “напарника”. Например, если кэш в одном центре данных засбоил, то другие кэши этого кластера могут взять на себя дополнительную нагрузку.
Oracle9iAS Web Cache может не только прозрачно справляться со сбоями узлов, но и также прозрачно управляться со своими собственными сбоями. Вот это по настоящему хорошо!
Кластеризация на уровне J2EE Oracle9iAS позволяет осуществить кластеризацию на отдельных уровнях J2EE (Java 2 Platform Enterprise Edition): клиентском, веб, EJB (Enterprise JavaBeans) и EIS (Enterpise Information System)—при условии, что приложение спроектировано и разработано в соответствии с четко определенными уровнями. Поэтому, например, приложения с бизнес-логикой на уровне EJB, реализованное с применением уровня JSP (Java Service Pages) не подходит для кластеризации.
Архитекторы/проектировщики всегда должны рассматривать возможность кластеризации на стадии проектирования своих J2EE-приложений. Расщепление уровня J2EE на отдельные уровни позже позволит и далее кластеризировать приложение, обеспечивая тем самым и более высокий уровень высокой готовности в случае сбоев. В недавнем онлайновом опросе об обеспечении максимально возможной высокой готовности J2EE-приложений, подавляющее большинство респондентов отметили, что они рекомендуют разработку приложений с Servlet и EJB на двух уровнях.
компоненты J2EE-кластеризации
Рассмотренные ранее способы кластеризации были сфокусированы на аспектах масштабирования и производительности кластеров, что само по себе очень важно. Но эти способы не решают жизненно важные проблемы отказоустойчивости (fault-tolerance) приложений, которые обрабатывают большие объемы пользовательских данных за время длительных сессий, иначе говоря, приложений с долго живущими сессиями (long-life session-state applications).
Представьте систему онлайновой торговли, которая требует от пользователей ввести их имена, информацию о счетах, об акциях, которые они хотят купить, и число акций для каждого заказа. И вдруг, когда нажимается кнопка Submit, пользователь получает сообщение об ошибке, так как какая-то ошибка вызвала сбой EJB. Повторный ввод всех этих данных — и потеря денег, так как приложение не может воспроизвести состояние сессии, и возможная потеря пользователя.
Для решения этой критической проблемы для приложений, обремененных обширными данными состояния, Oracle9iAS Containers for J2EE поддерживают "cluster islands" (кластерные острова), наборы серверов на уровне J2EE, на котором параметры состояния сессии могут быть значительно легче воспроизведены, обеспечивая, тем самым, прозрачное перенаправление запроса клиента к другому компоненту, который сможет обслужить этот запрос, если некоторый J2EE-компонент выйдет из строя.
Как правило, проблема поддержки параметров состояния ведет к снижению производительности, независимо от того, находятся ли они в оперативной памяти или параметры состояния сессии хранились в базе данных (в этом случае снижение производительности является результатом выполнения операций ввода-вывода с внешними устройствами). Но поскольку “кластерные острова” (cluster islands) обеспечивают отказоустойчивость на уровне компонентов, параметры состояния могут быть воспроизведены и обеспечены на уровне J2EE без снижения производительности.
принятие решений
Располагая всеми этими возможностями кластеризации, архитекторы приложений способны принимать обоснованные бизнес-решения. Крайне важно различать способы кластеризации, опирающиеся на аппаратуру, и на программное обеспечение (включая аспекты сетевой инфраструктуры и инфраструктуры хранения данных, которые не были рассмотрены в этой статье).
Не менее важно определить расходы, связанные выходом приложений из строя. Ответственные приложения, такие как онлайновая торговля или обработка записей о пациентах госпиталей, в случае сбоев могут вызвать большие потери. С другой стороны, простые, презентационного типа приложения могут хорошо обслуживаться простыми “пещерными” технологиями.
Как архитектор приложений, вы должны рассмотреть ряд вопросов, связанных с кластеризацией: Что произойдет, если приложение выйдет из строя из-за какой-то своей ошибки или отключения питания или здание, в котором расположено ваше оборудование, сгорит? Что если откажет важный электронный компонент, или испортится корневая файловая система, приведя к краху резервные (standby) машины, или на вашем основном диске появились сбойные секторы? В какой защите нуждается ваше приложение, и как много вы готовы заплатить за такую защиту (или за ее отсутствие)?
Вопросы возможности кластеризации должны играть важную роль во всем процессе разработки приложения. В начале проекта проведите встречу со всеми заинтересованными сторонами, включая руководителей уровня C, чтобы определить критичность приложения и, соответственно, необходимость применения кластеризации. Привлекайте в ваши дискуссии администраторов — сетевых и баз данных, чтобы определить инфраструктуру, которая можно поддержать в рамках заданных ограничений по персоналу и бюджету.
И, наконец, приложения должны быть спроектированы и разработаны с использованием четко определенных уровней — клиент, веб-, EJB- и EIS- уровни (это очень хорошее правило в любых обстоятельствах). По мере развития приложения его потребности в кластеризации, вероятно, будут изменяться, так что старайтесь сохранять гибкость своих приложений, насколько это возможно.
Сквозная кластеризация Oracle9iAS предоставляет архитекторам приложений широкий набор готовых к развертыванию средств, которые помогут при решении в случаях сложной неочевидной кластеризации. Способы кластеризации простираются от простых “пещерных” методов для балансировки нагрузки до методов кэш-кластеризации приложений с богатых информационным содержанием. Кластеризация может быть организована на уровне веб-сервера и на J2EE- уровне. Архитекторы приложений могут даже выбрать кластеризацию на уровне отдельных компонентов J2EE, а с помощью “кластерных островов” (cluster islands) они могут поддерживать состояние сессий без потери производительности.
Кластеризация — это распределение аппаратуры и программного обеспечения по узлам, которые работают вместе как единая система с тем, чтобы гарантировать продолжение функционирования пользовательских приложений во время чрезмерных нагрузок, либо в случае выхода из строя одного из узлов кластера. Кластеризация становится все более популярной, благодаря недавним улучшениям программного обеспечения управления внешней памятью и приложений, что облегчает этот процесс и делает его более приемлемым в ценовом отношении. А это особенно важно сейчас, когда руководители организаций скупы в отношении расходов на ИТ. Конечно, наличие мощных и очень надежных серверов очень привлекательно, но они весьма дороги. Поэтому многие компании, включая Oracle, используют недорогие массово выпускаемые серверы. Но такой подход ведет к тому, что в сравнении с мощным сервером нагрузка на каждый “малый” сервер меньше и вероятность его сбоя выше.
Ключевым становится следующий вопрос: "Как обеспечить необходимую мощность и надежность уровня предприятия нашим приложениям при условии применения менее надежных серверов?" Ответ: решением будет эффективная кластеризация. Но, как говорится, дьявол таится в деталях. Сразу же возникает множество проблем, как, например, соответствие потребностям приложений, состав необходимой аппаратуры, структура программного обеспечения. Возможность кластеризации может быть учтена уже при проектировании программного обеспечения приложений. Мы рассмотрим различные способы создания кластеров и покажем, что построение эффективных кластеров не сводится к применению одного единственного подхода, необходимо рассмотрение ряда возможностей, из которых для реализации отбираются наиболее походящие для ваших приложений.
аппаратная кластеризация
Кластеры можно разделить по категориям в соответствии с назначением их основного использования.
Кластеры высокой готовности (high-availability clusters), или отказоустойчивые (failover),применяются для того, чтобы не допустить прекращения обслуживания в случае выхода из строя основного сервера. Как правило, в этом случае используется дублирующий сервер.
Кластеры с балансировкой нагрузки (load-balancing clusters)обеспечивают более эффективное использование ресурсов вычислительной системы. В случае высоких нагрузок на серверы, запросы перенаправляются на наименее загруженные серверы.Кластеры высокой производительности (high-performancesters clusters) обычно применяются для достижения высокой скорости вычислений. Типичные для этого случая приложения: прогнозирование, в том числе погоды, и научные вычисления. Для получения результатов за короткий промежуток необходимо параллелизировать вычисления. С этой целью первыми были использованы кластерные системы с массивно-параллельной обработкой данных (massively parallel processing (MPP)). На уровне аппаратуры можно и далее продолжить классификацию: кластер из ПК, кластер из рабочих станций, кластер из SMP-серверов (SMP — symmetric multiprocessing, многопроцессорная симметричная архитектура) с операционными системами Linux, Solaris, NT и т.д.
Очень важен правильный выбор аппаратуры, которая наилучшим образом соответствует вашим потребностям, и способа соединения серверов. Ряд технологий высокопроизводительной коммуникации пакетов и переключения могут быть использованы для соединения рабочих станций, ПК и серверов, входящих в кластеры. Но вместо этих технологий вы можете отдать предпочтение Ethernet, это зависит от производительности и уровня высокой готовности (high-availability) вашей вычислительной среды. Для повышения пропускной способности сети архитекторы/проектировщики могут выбирать между 100 Мбит/с-сетевыми картами и Gigabit Ethernet для получения нужной скорости передачи данных. Другие варианты — это Myrinet, SCI, FC-AL, Giganet, GigE и ATM, но в каждом из этих случаев цена кусается.
Также очень важно скомпоновать аппаратуру кластера наилучшим образом. Более сложно применение разнородных кластеров, аппаратура которых относится к различным архитектурам, так как узлы могут подсоединяться (и отключаться) к кластеру в разные моменты времени. Крайне желательна в аппаратных кластерах внешняя память со средствами зеркалирования (mirroring storage) для защиты от сбоев среды хранения данных. Например, в случае простого двухузлового кластера, совместно используемая внешняя память может состоять из диска с двумя портами (dual-ported disk), к которому можно обращаться обоих узлов. В этом случае также могут быть нужны специальные кабели для соединения сетевых карт/коммутаторов/хабов.
Если для защиты кластера от системного сбоя применяется “холодное” резервирование ("cold" standby), то необходимо ручное переключение от засбоившего основного сервера к запасному. Но такой подход приводит к прерыванию работы приложения на некоторое время, так как запасной сервер нужно запустить, а приложение перестартовать. “Горячее” резервирование включает автоматическое переключение с сбоившего основного сервера на запасной, который до этого не выполнял работы. В этом случае запасной сервер запускается автоматически и “перехватывает” нагрузку с основного.
Но ни один из этих двух (холодное, горячее) способов резервирования не исправляет повреждения корневой файловой системы (root file systems). Для разрешения этой проблемы в аппаратных кластерах иногда используют свои собственные загрузчики (boot drive), либо средства зеркалирования, реализованные на уровне аппаратуры. Так как приложения часто становятся недоступными в результате сбоев дисков, то системные администраторы, как правило, используют запасные серверы со средствами зеркалирования дисков, а также технологию RAID (Redundant Arrays of Independent Disks). В этом случае информация хранится на нескольких дисках, которые являются зеркалами друг друга. Важно понимать особенности различных архитектур аппаратных кластеров.
В архитектуре с совместно используемой оперативной памятью (shared-memory architecture) множество процессоров используют общую шину памяти, такие системы определяются как SMP-системы. В этой архитектуре пропускная способность шины часто становится проблемой по мере добавления узлов.
В архитектуре с совместно используемыми дисками (shared-disk architecture) множество SMP-серверов совместно используют дисковую память для повышения уровня готовности.
Архитектура без разделения ресурсов (shared-nothing architecture) предполагает, что у каждого узла своя собственная оперативная память, свои диски и процессоры. Преимуществом такого подхода является задействование большей пропускной способности по мере добавления узлов.
С течением времени аппаратные кластеры постепенно развиваются. В 80-х годах использовались векторные системы. Затем наступила эра суперкомпьютеров и MPP-систем, а теперь используются кластеры и сети распределенных вычислений (grids). Ряд поставщиков предлагают конкурирующие между собой платформы с различными уровнями поддержки для перечисленных выше архитектур аппаратных кластеров, а также параллелизма, чтобы сделать аппаратные кластеры реальностью. Но по прежнему создание больших аппаратных кластеров с N узлами требует тщательного продумывания и планирования, и немалого бюджета.
кластеры с балансировкой нагрузки
Технологии аппаратной кластеризации называются стратегиями “пещерного человека” ("caveman"), потому что они не очень развиты, наиболее легки в применении и дешевы. Если одна их них используется как единственное кластеризированное решение, то оно применимо только для простейших приложений типа презентаций. “Пещерная” кластеризация предполагает использование множества узлов (серверов с идентичными установками вашего приложения) плюс некая дополнительная аппаратура на серверных узлах для управления и распределения нагрузки.
Например, наиболее простая “пещерная” технология — это циклическая (round-robin) служба доменных имен DNS (domain name service), которая использует маршрутизатор и DNS-сервер для циклической рассылки различных пользовательских запросов по всем серверам приложений, так что ни один узел не отягощается Так как у каждого узла есть свой IP-адрес, то легко ввести последовательные URL справочные DNS-файлы и связать их с адресами всех узлов: www1.companyXYZ.com с 143.10.25.1, www2.company.com с 143.10.25.2 и т.д. Маршрутизатор затем распределит пользовательские запросы по списку URL циклическим образом. Масштабирование в этом случае реализуется достаточно легко: чтобы добавить новый сервер, просто дайте ему последовательный URL в справочном файле DNS-сервера и затем прикрепите этот URL к IP-адресу нового сервера.
Следующим шагом за циклической DNS было применение IP-распределителя (sprayer), устройства подобного маршрутизатору, которое располагается между входящими (inbound) пользовательскими запросами и узлами серверов приложений. Этот метод похож на циклическое решение, за исключением того, что IP-распределители “разбрасывают” или перенаправляют запросы к нескольким узлам. IP-распределители более динамичны и менее произвольны в выборе, чем циклические маршрутизаторы, так что недозагруженнные серверы могут быть использованы более эффективно. Однако, IP-распределители требуют применения SSL-декодеров в случае использования протокола SSL (Secure Sockets Layer — протокол защищенных сокетов, гарантирующий безопасную передачу данных по сети).
Еще одной альтернативой является применение реверсивных прокси (reverse-proxy) HTTP-серверов, которые используются в основном как защита от атак злоумышленников, но могут применяться и для балансировки нагрузки. Это способ требует использования кэширования, как правило, связываемого с доступом к веб-страницам, в оперативной памяти HTTP-серверов, чтобы снять нагрузку, насколько это возможно, с узлов серверов приложений. Реверс-прокси метод требует использования циклической кластеризации, чтобы предохранить HTTP-серверы от перегрузки.
Другие способы балансировки нагрузки — это единый IP-образ на стороне сервера (server-side single IP image) и трансляция сетевых адресов (network-address translation); оба эти способа дороже и сложнее и требуют изменений заголовков пакетов на основе особенностей нагрузки.
проблемы отказоустойчивости кластеров с балансировкой нагрузки
Основная проблема по части аппаратуры в разрешении вопросов кластеризации заключается в том, что никакая аппаратура не позволяет удовлетворительно справиться с сбоями узлов. Если компонент сервера (или приложения) засбоил в “пещерной” системе, то весьма вероятно, что пользователь подумает, что вышла из строя вся система. Например, предположим, что внезапно засбоил четвертый узел в циклической или реверс-прокси установке. Если этот узел включен список циклического опроса, то любой входящий пользователь, скорее всего, получит сообщение об ошибке DNS, так как этот сервер не сможет ответить. Чтобы продолжить работу, пользователь должен выйти из системы и в новом сеансе запустить маршрутизатор.
Кроме того, именно аппаратура балансировки нагрузки (DNS-сервер или IP-распределитель) может стать “узким местом” и, тем самым, той единой точкой отказа, выход из строя которой обрушивает всю систему. Поэтому никакая “пещерная” технология не подходит для таких приложений, в которых, например, пользовательские данные должны быть внесены экран за экраном (как в карточных приложениях обслуживания покупок). В случае же “пещерной” установки при выходе из строя узла, обслуживающего активного пользователя, теряется вся информация данной сессии.
Для “пещерных” систем характерны высокие цены. Технология RAID требует много устройств для работы с дисками, и эти расходы быстро растут по мере масштабирования как ваших приложений, так и самого кластера. Время простоя пользовательских приложений может слишком дорого стоить, особенно для жизненно-важных приложений. Итак, что касается технологий аппаратной кластеризации, самое главное заключается в том, что для них возможна только почти тотальная защита (но она очень дорога), и такие решения требуют наличия администраторов, которые умеют конфигурировать подобные системы, справляться со сбоями дисков, соединять компоненты кластеров, а также решать сложные сетевые проблемы.
программные решения: веб-кэшированная кластеризация
Возможно применить программное обеспечение для того, чтобы разрешить то, что по существу является аппаратной проблемой. Отказоустойчивые возможности такой программной инфраструктуры, какой, например, является Oracle9i Application Server (Oracle9iAS), могут обеспечить и динамическую балансировку нагрузки, и высокую готовность, необходимую для сложных и критичных приложений, и стоить только часть цены аппаратного кластера. Создание кластеров на базе Oracle9iAS Web Cache — это замечательный пример использования программного обеспечения для преодоления сбоев и управления трафиком приложений. Веб-кэш предшествует узлам-серверам и подобно обычному кэшу отвечает на все входящие HTTP-запросы и распределяет эти запросы согласно возможностям каждого веб-сервера. В гипотетическом кластере, состоящем из серверов A, B и C, мы сможем сконфигурировать Web Cache для распределения 30% всей нагрузки к веб-серверу A, других 30% к веб-серверу B и 40% к веб-серверу C.
Подобно технологии реверс-прокси, данное решение обладает тем же ключевым преимуществом: если один из этих трех серверов выйдет из строя, Oracle9iAS Web Cache сможет автоматически перераспределять 50% нагрузки по двум остающимся в строю веб-серверам. Когда же засбоивший сервер вернется в строй, Web Cache вновь перераспределит нагрузку по всем трем серверам, и все это будет незаметно, прозрачно для пользователя.
Oracle9iAS Web Cache также поддерживает состояние сессий, не обременяя узлы серверов приложений. Он также обслуживает сайты, которые используют идентификаторы сессии (session ID) и жетоны (cookies). Но поддержка состояния сессий на уровне веб-сервера может быть обременительна, и лучшим решением будет обеспечение минимального, насколько это возможно, набора параметров состояния сессий и только на очень короткие промежутки времени. Для более долгих сессий и больших наборов подобных параметров стоит рассмотреть применение базы данных.
И еще один довод за создание кластеров на базе Oracle9iAS Web Cache — это возможность одного Web Cache взаимодействовать с другими кэшами на этом кластере, чтобы тем самым увеличить общую пропускную способность. Каждый Web Cache обнаруживает новый контент у своего “напарника” и может сохранить его в своем собственном кэше. Также отслеживается и случай выхода из строя “напарника”. Например, если кэш в одном центре данных засбоил, то другие кэши этого кластера могут взять на себя дополнительную нагрузку.
Oracle9iAS Web Cache может не только прозрачно справляться со сбоями узлов, но и также прозрачно управляться со своими собственными сбоями. Вот это по настоящему хорошо!
Кластеризация на уровне J2EE Oracle9iAS позволяет осуществить кластеризацию на отдельных уровнях J2EE (Java 2 Platform Enterprise Edition): клиентском, веб, EJB (Enterprise JavaBeans) и EIS (Enterpise Information System)—при условии, что приложение спроектировано и разработано в соответствии с четко определенными уровнями. Поэтому, например, приложения с бизнес-логикой на уровне EJB, реализованное с применением уровня JSP (Java Service Pages) не подходит для кластеризации.
Архитекторы/проектировщики всегда должны рассматривать возможность кластеризации на стадии проектирования своих J2EE-приложений. Расщепление уровня J2EE на отдельные уровни позже позволит и далее кластеризировать приложение, обеспечивая тем самым и более высокий уровень высокой готовности в случае сбоев. В недавнем онлайновом опросе об обеспечении максимально возможной высокой готовности J2EE-приложений, подавляющее большинство респондентов отметили, что они рекомендуют разработку приложений с Servlet и EJB на двух уровнях.
компоненты J2EE-кластеризации
Рассмотренные ранее способы кластеризации были сфокусированы на аспектах масштабирования и производительности кластеров, что само по себе очень важно. Но эти способы не решают жизненно важные проблемы отказоустойчивости (fault-tolerance) приложений, которые обрабатывают большие объемы пользовательских данных за время длительных сессий, иначе говоря, приложений с долго живущими сессиями (long-life session-state applications).
Представьте систему онлайновой торговли, которая требует от пользователей ввести их имена, информацию о счетах, об акциях, которые они хотят купить, и число акций для каждого заказа. И вдруг, когда нажимается кнопка Submit, пользователь получает сообщение об ошибке, так как какая-то ошибка вызвала сбой EJB. Повторный ввод всех этих данных — и потеря денег, так как приложение не может воспроизвести состояние сессии, и возможная потеря пользователя.
Для решения этой критической проблемы для приложений, обремененных обширными данными состояния, Oracle9iAS Containers for J2EE поддерживают "cluster islands" (кластерные острова), наборы серверов на уровне J2EE, на котором параметры состояния сессии могут быть значительно легче воспроизведены, обеспечивая, тем самым, прозрачное перенаправление запроса клиента к другому компоненту, который сможет обслужить этот запрос, если некоторый J2EE-компонент выйдет из строя.
Как правило, проблема поддержки параметров состояния ведет к снижению производительности, независимо от того, находятся ли они в оперативной памяти или параметры состояния сессии хранились в базе данных (в этом случае снижение производительности является результатом выполнения операций ввода-вывода с внешними устройствами). Но поскольку “кластерные острова” (cluster islands) обеспечивают отказоустойчивость на уровне компонентов, параметры состояния могут быть воспроизведены и обеспечены на уровне J2EE без снижения производительности.
принятие решений
Располагая всеми этими возможностями кластеризации, архитекторы приложений способны принимать обоснованные бизнес-решения. Крайне важно различать способы кластеризации, опирающиеся на аппаратуру, и на программное обеспечение (включая аспекты сетевой инфраструктуры и инфраструктуры хранения данных, которые не были рассмотрены в этой статье).
Не менее важно определить расходы, связанные выходом приложений из строя. Ответственные приложения, такие как онлайновая торговля или обработка записей о пациентах госпиталей, в случае сбоев могут вызвать большие потери. С другой стороны, простые, презентационного типа приложения могут хорошо обслуживаться простыми “пещерными” технологиями.
Как архитектор приложений, вы должны рассмотреть ряд вопросов, связанных с кластеризацией: Что произойдет, если приложение выйдет из строя из-за какой-то своей ошибки или отключения питания или здание, в котором расположено ваше оборудование, сгорит? Что если откажет важный электронный компонент, или испортится корневая файловая система, приведя к краху резервные (standby) машины, или на вашем основном диске появились сбойные секторы? В какой защите нуждается ваше приложение, и как много вы готовы заплатить за такую защиту (или за ее отсутствие)?
Вопросы возможности кластеризации должны играть важную роль во всем процессе разработки приложения. В начале проекта проведите встречу со всеми заинтересованными сторонами, включая руководителей уровня C, чтобы определить критичность приложения и, соответственно, необходимость применения кластеризации. Привлекайте в ваши дискуссии администраторов — сетевых и баз данных, чтобы определить инфраструктуру, которая можно поддержать в рамках заданных ограничений по персоналу и бюджету.
И, наконец, приложения должны быть спроектированы и разработаны с использованием четко определенных уровней — клиент, веб-, EJB- и EIS- уровни (это очень хорошее правило в любых обстоятельствах). По мере развития приложения его потребности в кластеризации, вероятно, будут изменяться, так что старайтесь сохранять гибкость своих приложений, насколько это возможно.
Сквозная кластеризация Oracle9iAS предоставляет архитекторам приложений широкий набор готовых к развертыванию средств, которые помогут при решении в случаях сложной неочевидной кластеризации. Способы кластеризации простираются от простых “пещерных” методов для балансировки нагрузки до методов кэш-кластеризации приложений с богатых информационным содержанием. Кластеризация может быть организована на уровне веб-сервера и на J2EE- уровне. Архитекторы приложений могут даже выбрать кластеризацию на уровне отдельных компонентов J2EE, а с помощью “кластерных островов” (cluster islands) они могут поддерживать состояние сессий без потери производительности.
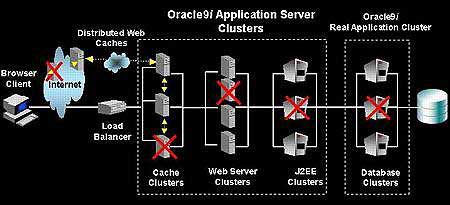
Рисунок 1. Сквозная кластеризация Кластеризация на базе Oracle9iAS позволяет архитекторам приложений защититься от серверных сбоев, независимо от того, где эти сбои имели место.
Sudhakar Ramakrishnan
Сетевые решения. Статья была опубликована в номере 06 за 2003 год в рубрике решения
