Сможет ли IP достичь надежности TDM?
У нас не будет объединенных сетей до тех пор, пока операторы не смогут обеспечить достойный уровень передачи IP. В данном материале рассматривается именно этот вопрос и все, что с ним так или иначе связано.
С самого начала девяностых мысль о том, что объединенные сети и IP смогут с успехом заменить TDM-сети в нелегком деле передачи голоса и данных, некоторое время витала в умах специалистов, но затем, как-то неожиданно и незаметно, растворилась в воздухе. Основная причина была проста: сети передачи данных, и IP-сети в частности, считались слишком ненадежными для того, чтобы обеспечить достаточно высокие потребности пользователей, привыкших ко всем благам традиционных голосовых TDM-сетей.
Мы давно уже воспринимаем доступность и надежность голосовых сетей, как нечто должное, и во многих аспектах своей жизни ежедневно полагаемся на них. Ведь даже когда с электроэнергией случаются перебои во время бурь или ураганов, телефонная линия почти всегда продолжает работать (наши друзья, которые работают на местной электростанции, объяснили нам причину, по которой это происходит — электропровода располагаются на столбах выше всех остальных, и поэтому падающие деревья повреждают, в первую очередь, именно их) /* здесь и далее описаны реалии американские, а не наши — прим. ред. */
Ключевой термин, характеризующий степень доступности цифровых TDM-сетей — это “пять девяток” — 99,999 процентов доступности. Как скоро IP-сети, в своем продвижении по оси развития технологии, смогут достичь этой отметки? Ответ может удивить вас, но это истинно так — добротно построенные и управляемые на должном уровне IP-сети достигнут равнозначных показателей в ближайшие 18—24 месяца.
Основываясь на исследованиях, проводившихся для данной статьи, можно с полной уверенностью сказать, что данное равенство будет возможно только благодаря усовершенствованиям, обеспеченным использованием Multiprotocol Label Switching (MPLS) и расширенным возможностям таких протоколов, как IS-IS и OSPF, а также все более приспособленными к моментальному восстановлению после сбоев комбинациями аппаратуры и программного обеспечения.
Одновременно с накапливающейся базой общего опыта, касающегося управления IP-сетями, постепенно все части большой головоломки объединенных сетей становятся на свои места.
Путь к построению высоконадежных IP-сетей достаточно прост и не требует дополнительных пояснений, однако, некоторые шаги должны быть предприняты параллельно для того, чтобы повысить доступность этих сетей. Нам необходимо использовать на производстве лучшие IP-технологии, которые, что несколько парадоксально, требуют наличия традиционной телефонии для обеспечения максимально короткого периода восстановления после неполадок. В качестве временной меры, концепция параллельных сетей предлагает альтернативу — устойчивость через многообразие. Это предвещает эпоху, когда будут создаваться объединенные сети со способностью выживания, свойственной интернет-сетям. Это подразумевает возможность перенаправления коммуникационного потока в обход поврежденного участка сети.
формулировки
Когда мы говорим о высокой доступности или IP-сетях операторского класса, что мы при это имеем в виду? Общепринятое определение сводится к 99,999 процентам (или даже более того) — это приблизительно 5,3 минуты бездействия за год.
Важно отметить, что стандартные определения доступности для сетей TDM и сетей IP различаются, что не позволяет провести четкое их сравнение. Состояние, когда все каналы заняты (all circuits busy), к примеру, не рассматривается в качестве выхода из строя TDM-сети, тогда как в IP-сетях дело обстоит именно так.
Также мы должны сразу отметить, что речь идет о сетях, управляемых и контролируемых если не одним сервис-провайдером или компанией, то как минимум небольшим ограниченным числом субъектов. Мы не имеем в виду весь огромный неуправляемый Интернет. Даже ситуации, в которых присутствует несколько сетей или несколько производителей сетевого оборудования, — даже они по сути более контролируемы по сравнению с общедоступным Интернет.
Также для начала будет немаловажно понять и осознать основное равенство, которое используется для оценки факторов, влияющих на доступность. Общая доступность сети, в основных терминах, является продуктом нижеследующего равенства, применительно к каждому ее элементу:
% Availability = MTBF / (MTBF + MTTR) × 100%
Определив общее время, которое сетевой элемент находился в рабочем состоянии (среднее время между выходами из строя, MTBF), и поделив его на сумму времени работы и среднего времени восстановления (MTTR, или время, которое элемент сети находился в нерабочем состоянии), вы сможете определить то время, которое данный элемент был доступен — то есть то, каким количеством тех самых “девяток” он обладает. Также вы можете подставить в это уравнение “минуты, потерянные клиентами” и “общее количество доступных минут”. Определяя значение доступности для каждого отдельно взятого элемента сети, вы сможете определить и общую сетевую доступность.
миф и его происхождение
Компьютеры — бесконечно терпеливые создания. Люди же — наоборот. Компьютеры обладают только лишь теми ожиданиями, которые предписали им мы сами; человеческие же существа обладают огромным и постоянно растущим комплектом всевозможных ожиданий и надежд. Все это очень подходит к той ситуации, с которой сталкиваемся мы, пытаясь объединить голосовые сети и сети передачи данных.
Такие факторы, как неустойчивый сигнал или задержка не являются фатальными для процесса обмена данными, тогда как человеческие предпочтения в области голосовых коммуникаций немного другие. Задержки в более чем 50 миллисекунд создают неприятный для человеческого мозга эффект — когда сознание при всем при этом пытается уловить содержание того, о чем говорит абонент на другом конце провода.
Уже во времена, когда цифровая технология только начинала внедряться на голосовых сетях, в далеких семидесятых, разработчики уже знали о том, что им придется столкнуться с несколькими человеческими особенностями, к которым им предстоит приноровиться, так как бороться с ними не представляется возможным.
Тогда как эффективность передачи голоса посредством цифровых пакетов признается все более и более неоспоримой, создаются новые, прогрессивные технологии, которые в то же время представляют собой некий виртуальный эквивалент проводных “end-to-end” соединений старого образца, — то есть основной принцип, призванный поддерживать размеренную нить разговора, остается прежним. То, что сейчас мы используем TDM (Time Division Multiplexing, мультиплексирование с временным разделением) и обрабатываем данные других разговоров, в моменты, когда в текущем разговоре наступает долгая (с компьютерной точки зрения) тишина, ситуации не меняет.
Ранние преимущества в доступности цифровых TDM-сетей стали результатом таких вещей, как значительная модернизация и усовершенствования технологий мультиплексирования в «медных» сетях. Когда на рынок вышли оптоволоконные системы, качество снова увеличилось. В восьмидесятых, перемещение от асинхронных технологий к SONET также внесло свои коррективы, и планка качества поднялась снова.
С обеспеченной таким образом “выживаемостью” разговора, путь, по которому текла нить разговора, мог быть изменен безо всякого ущерба и потери соединения — трафик автоматически переключался на запасной канал, причем происходило это настолько быстро, что участники разговора не пропускали ни единого звука.
Но цифровой TDM и SONET не с самого начала обеспечивали “пять девяток”; программное обеспечение для SONET, представленное в конце восьмидесятых, не было в достаточной мере стабильным еще два-три года, и по большому счету процесс достижения цифровыми TDM-сетями нужного уровня занял около 15 лет. Относительно надежности, IP также пойдет по пути постепенного взросления.
IP-сети: где мы сегодня
Начав с разработки программных коммутаторов в середине и конце девяностых, производители телекоммуникационных систем стали серьезно изучать проблему построения основанной на IP сети, которая могла бы обрабатывать голосовой трафик с качеством, к которому привыкли пользователи традиционных телефонных сетей. Важно заметить, что крупнейшие сервис-провайдеры планеты занимаются тестированием полного пакета чистых IP-технологий всего лишь на протяжении нескольких лет.
Но вместо 15-ти лет, которые ушли у цифрового TDM на достижение уровня “пяти девяток”, “взросление” IP, предположительно, достигнет цели в течение пяти лет, и это при том, что половина этого пути уже пройдена. Все более усовершенствованное оборудование, программное обеспечение, процессинг и сетевой менеджмент продолжат уменьшать цены и сложность. Несомненно, в достаточным образом контролируемых ситуациях — то есть, в сетях, работающих на оборудовании одного производителя — IP-сети могут достигать “пяти девяток” уже сегодня.
На Рисунке 1, мы сравнили две кривые роста. Это качественно иллюстрирует ту самую среднюю позицию, которая присутствует между менее и более консервативными взглядами на проблему. От разрыва между сегодняшними IP- и TDM-сетями уже удалось избавиться в теории, в лабораторных условиях и при альфа- и бета-тестировании. Что пока отсутствует — так это опыт работы оборудования в реальных условиях, посему здоровый скептицизм сервис-провайдеров и сетевых менеджеров пока еще не развеян. Конечно же, данный опыт накапливается.
Подвергая анализу доступность IP-сетей, а также постоянно увеличивая ее показатели, мы пришли к выводу, что весь процесс работы над этим вопросом необходимо разделить на несколько специальных категорий, которые, каждая по отдельности, по-своему влияют на сетевую доступность. В число этих категорий входят: рассмотрение железа, программного обеспечения, окружения, анализ конструкционных особенностей сети и последнее, но не менее важное, — комбинации технологического процесса и процента ошибок, вызванных так называемым “человеческим фактором”.
оборудование
Оборудование является, со сравнительной точки зрения, самым простым для предсказания, а следовательно — и для устранения неполадок, фактором, который всегда легко заставить работать максимально безотказно при наличии определенных ресурсов. Начиная с мельчайших компонентов каждого отдельного устройства, и заканчивая самыми высоко стоящими в иерархии деталями, мы вычисляем доступность каждого фрагмента сети, выводя тракт прохождения данных для каждого устройства, и далее — комбинируя из получившегося общую сетевую доступность. Поставщики оборудования разработали множество всевозможных программных инструментов для облегчения этой работы, и они хорошо знают наиболее распространенные ошибки. Здесь мы попробуем привести лишь самые основные факторы.
Прежде всего, вы должны разделить всю сеть на определенные сценарии, исходя из того, каким образом и каким путем данные циркулируют по сети к определенным пользователям.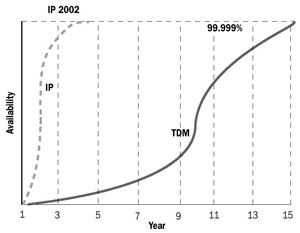
Рисунок 1 — Кривые роста.
Создавая скелетные схемы, представляющие все сетевые элементы и соответствующие тракты данных по каждому из них, вы сможете увидеть, какие из устройств подключены параллельно, а какие - последовательно. Затем вы сможете создать список типов устройств, изменения по которым смогут положительно повлиять на доступность всей сети.
А вот прямиком от этого момента начинается важный этап, касающийся того, каким способом скомбинировать доступность индивидуально по каждому сетевому устройству, включая и группы параллельно подключенных устройств, конвертированных в последовательно-доступные. Очевидно и не подлежит никакому сомнению, что результатом увеличения доступности отдельных компонентов сетевого окружения станет общее увеличение доступности сети.
После всех этих подсчетов вы столкнетесь с так называемым “эффектом бабочки,” как это называется в теории неструктурного программирования — когда мелкие факторы (такие как одна-единственная вышедшая из строя карта маршрутизатора, или плохо отлаженный процесс восстановления) могут иметь очень большое влияние на общую доступность. Безусловно, в этом всегда есть и вторая сторона. Устранив одно слабое место в аппаратной части сети или плохо отлаженный процесс, мы можем обеспечить прыжок показателя доступности сети от четырех девяток до пяти. Но в то же время это значит, что один непредвиденный или незамеченный выход из строя какого-нибудь мелкого компонента может стать причиной пятичасового отключения всей сети в целом.
Хорошие новости состоят в том, что мы знаем, как получить данные MTBF и MTTR. Их могут предоставить либо производители устройства, либо вы сами можете добыть их, ориентируясь на собственный опыт работы с сетями. Принимая это во внимание, проблемы с доступностью оборудования могут быть эффективно решены.
В завершение отметим, что самой распространенной ошибкой является мнение, которое заключается в том, что аппаратный фактор считается единственным фактором, который может повлиять на доступность IP-сети. Безусловно, это не так, ибо тщательный анализ доступности обычно только начинается с железа. Валари Гилберт, глава американского офиса Cisco, говорит по этому поводу вот что: “Наши данные свидетельствуют о том, что на железо обычно приходится около 40 процентов всех проблем с доступностью сетей. Для того, чтобы устранить основные неполадки, следует более тщательно присмотреться к восстановительным процедурам, конструкции сети, экономичному ее использованию, программному обеспечению и т.д.”
программное обеспечение
В IP-сетях существует два главных типа программного обеспечения: операционные системы отдельно взятых устройств (например, маршрутизаторов), и ПО, выполняющее в сети контрольные функции. Оба типа зачастую функционируют параллельно, внося свой немалый вклад в обеспечение доступности сети.
Типичным примером выхода из строя IP-сети является неполадка в операционной системе маршрутизатора. Мы должны определить, насколько быстро маршрутизатор сможет самовосстановиться после этого события, перестроить свои таблицы маршрутизации и начать снова передавать данные — то есть, мы должны определить среднее время восстановления. Так мы можем подсчитать доступность для каждого устройства в понятиях программного обеспечения, адаптировать конструкцию сети так, как это необходимо — включая параллельный дизайн, dual homing для коммутаторов, и так далее — а затем попробовать уменьшить фактор воздействия неполадок ПО на общую сетевую доступность.
Хитрость заключается в том, что надежное ПО, которое специально работает для того, чтобы в нужный момент, во время выхода из строя основной программы, взять ее функции на себя, не добавляет времени к периоду простоя сети, параллельный элемент может помочь успешному продолжению выполнения программы — такая или похожая схема и есть то, что мы называем хорошо построенным механизмом восстановления после неполадок. Ключевое слово в данном случае — безотказность.
В этом случае может помочь как опыт других, так и ваш собственный опыт, включающий наблюдения за работой программы в тестовой ситуации. Также это может быть усилено возможностью возвращения к старой версии какой-либо программы после модернизации или обновления.
Нет какой-либо причины, по которой программное обеспечение для IP-сетей может быть менее надежным, чем ПО для TDM-сетей, поэтому всегда стоит учитывать, что уровень тестов для таких программ обязательно должен оставаться прежним. Также IP-сети могут во многом выиграть, если для их управления будет использоваться опыт администраторов TDM-сетей: самым главным правилом избежания сетевых неполадок, вызванных ошибками ПО, является планировка и жесткое управление процедурами апгрейда. Основные постулаты правильной политики в этой области таковы: апгрейды должны производиться в моменты, когда трафик в сети минимален, в этой работе должен участвовать наиболее опытный персонал, процесс апдейта должен предполагать возможность быстрого отката к ранее установленному ПО/конфигурации при возникновении проблем с новым.
анализ окружения
Эта тема не требует долгих рассуждений, и по одной очень простой причине: все исследования в этом плане фактически остались теми же, что и в TDM-сетях — и что касается голосовых коммутаторов, и других программных инструментов. Первое голосовое IP-оборудование не имело питания от сети, тогда как нынешние продукты для IP-телефонии все оснащены такой системой питания. Как и в традиционных сетях, концепция энергопитания основывается прежде всего на эквиваленте схемы, использующейся в центральном офисе, где происходят те же самые процессы и используются те же самые решения: резервная батарея питания, генераторы, и т.д.
Расчет необходимости происходит тоже традиционно — подсчитывается точное необходимое количество энергии, требующейся устройствам. При этом следует учитывать географические и другие зависящие от местоположения рабочего места факторы. Главная цель всего этого — обеспечить нужный баланс процессов и инструментов для достижения “пяти девяток”. Так как методы и исторический опыт такого процесса уже имеется, мы не будем подробно останавливаться на этой теме.
конструкция сети
Располагая хорошими данными по нынешней сетевой доступности, мы можем добавить в нашу сеть некоторые параллельные элементы, чтобы гарантированно довести ее доступность до “пяти девяток”. Тут следует напомнить, что параллельные конструкции требуют установки механизмов восстановления после неполадки (failover-механизмы), которые, согласно закону Мерфи, также могут ломаться. Несмотря на это, опыт как IP, так и TDM показывает, что параллельная сетевая архитектура — должным образом настроенная, обеспеченная и периодически проверяемая — может быть мощнейшим инструментом для достижения “пяти девяток” производительности сетей.
То, какие элементы должны вводиться параллельно, зависит от факторов, которые индивидуальны для каждой отдельно взятой сети и используемой в ней системы управления.
Некоторые маршрутизаторы могут иметь процессоры, работающие параллельно, или же, в ином случае, можно использовать сразу два отдельных устройства — каждое со своим процессором. Планировка устройств, которые присоединенных к сетевым узлам, может варьироваться, поэтому изменение уровня гарантированной доступности будет зависеть от того, как построены backup-системы.
В то время как параллельные конструкции увеличивают первоначальную стоимость сети, они также увеличивают доступность. Вот вам на заметку одно известное правило: путь от “четырех девяток” к ”пяти девяткам” удвоит ваши расходы, но доступность вашей сети при этом увеличится в 10 раз. Ключ к разгадке вопроса максимизации данного размена лежит в хронологических данных, анализ которых может показать, какие из устройств, присоединенных к сети будут наиболее эффективно способствовать этому.
Так какие же тенденции имеют место на рынке сегодня? Существует два фактора, которые препятствуют тому, чтобы история была рассказана уже сейчас. Во-первых, производители оборудования и сервис-провайдеры все еще не закончили составлять первый в этой истории план стандарта. Второй момент заключается в том, что каждая из этих компаний имеет свой собственный уникальный опыт в этой сфере, и никто не хочет делиться этой информацией с конкурентами. И так как спрос на объединенные сети все растет, и опытная база и практика их использования растет, какие-то общепринятые понятия, методы и правила в этой сфере обязательно должны появиться.
процессы и “человеческий фактор”
Эти две составляющие следует рассматривать только в единой связке, так как они чрезвычайным образом соотносятся и зависят друг от друга. Две ключевых области процессинга, которые следует проверять изначально, это, во-первых — комбинация процесса изменений в программном обеспечении и некое единообразие версий ПО; и второе — взаимосовместимые составляющие конфигураций устройств и платформ по всей сети.
“Для начала мы собираем все, так сказать, “низковисящие плоды”, на уровне клиентов и служащих, — это касается процессов, связанных с восстановительными и операционными процедурами, — рассказывает Гилберт. — Уже одно это само по себе может удвоить сетевую доступность. И только тогда, когда мы достигли этих небольших побед, мы начинаем думать о специфике конструкции, программной и управленческой составляющей, которая может повысить доступность.”
Шаги, которые могут быть предприняты в целях минимизации ошибок, происходящих благодаря “человеческому фактору” по сути такие же, как и те, которые предпринимаются для улучшения любого процесса — планирование, измерения, анализ просчетов, изменений и изменений в процессах управления. Так как это повторяющиеся процессы, они могут быть наглядно рассмотрены примерно так, как это сделано на рисунке 2.
Шаг 1 — Планирование. Начните с того, что продумайте и спланируйте показатели доступности, которыми должна обладать ваша сеть, а также предусмотрите равновесие всех остальных факторов. Это, в общем, тот самый процесс, о котором говорилось выше, и он включает замеры работы оборудования, программного обеспечения, факторов окружения и сетевой архитектуры.
Шаг 2 — Измерения. Отслеживайте с течением времени все причины выходов сети из строя, включая и те, которые произошли по человеческой вине или по вине сбоя в процессах. Также обращайте внимание и хронологизируйте общие показатели рабочего времени, число выходов из строя и время, которое сеть пребывала в нерабочем состоянии. Затем эти данные можно проанализировать (см. Шаг 3), и сравнить с исходными (см. Шаг 1).
Шаг 3 — Анализ просчетов. Сравните запланированные вами показатели (из Шага 1) с реальными (из Шага 2). Следует искать коренные причины, которые приводят к проблемам процессинга, пробовать рассматривать их абстрактно или как минимум начинать с них поиск иных проблем.
Шаг 4 — Изменения/Управление изменениями. Постарайтесь создать методы решения проблем таким образом, чтобы это в то же время не создало новых проблем.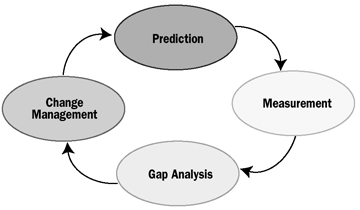
Рисунок 2. Анализ и человеческие ошибки.
Если модернизация программного обеспечения обязательна, к примеру, убедитесь, что предусмотрена возможность при случае вернуться к старому программному обеспечению. Создайте расписание модернизации ПО и следуйте ему.
что дальше
Большое количество работы было проделано Группой по проектированию Интернет (IETF) и многими другими для того, чтобы вывести IP-протоколы на более высокий уровень завершенности. Источники в больших компаниях, занимающихся предоставлением услуг связи убеждены в том, что протоколы достигнут нужного уровня зрелости уже в ближайшие 24 месяца. Одна из причин, по которой они столь оптимистичны — это MPLS, который позволяет использвать в IP-сетях такие виды управления трафиком, какие пытаются внедрить в TDM-сети вот уже на протяжении многих лет. MPLS выделяет особые пути для определенных последовательностей пакетов посредством пометки их таким образом, что маршрутизаторы получают возможность передавать их более оперативно. В OSI-модели это означает пересылку большинства пакетов по уровню 2, нежели по уровню 3. Также это способствует внедрению QOS, устанавливая прииоритеты для различных типов трафика — к примеру, наделяя большей степенью срочности чувствительный к задержкам голосовой трафик, нежели почтовый.
Конечно, MPLS помогает еще и в том, что касается восстановления сети. Fast Reroute, LSP (Label Switched Path) и Backup Record Route каждый в своей степени полагаются на различные методы обеспечения моментального восстановления сети, что с успехом и используется сегодня в ATM и SONET. Каждый из них имеет свои “за и против”, и каждый из них сейчас переживает болезненный процесс эволюции стандартов — как при поддержке оффициальных структур, таких как IETF и ITU, так при посредстве компаний-производителей оборудования, которые всегда следуют реальным необходимостям рынка и постоянно испытывают на себе его давление.
Параллельно с работой над самим по себе IP-стандартом ведутся не такие явные работы по разработке новой технологии, которая бы сделала IP-сети более надежными. В число проблем, которые занимают организации, ведущие разработки таких проектов, входят:
·Наличие дополнительного оборудования и программного обеспечения в IP-сети, которое автоматически переключается на альтернативные каналы, если основные каким-то образом выходят из строя. Это может случаться довольно часто, так что при всем при том процесс переключения должен быть незаметным для тех, кто разговаривает в этот момент по телефону (то, что сегодня успешно реализовано в TDM-сетях). Все крупнейшие производители маршрутизаторов и коммутаторов работают над этой проблемой.
·Наличие маршрутизаторов, коммутаторов и другого оборудования, которое может обновлять свое ПО без необходимости отключения на более чем 15-45 минут, как это происходит сегодня.
Эти основные направления, по которым должно вестись развитие технологии маршрутизирования, призваны наделить IP-устройства возможностями переключаться на запасное оборудование незаметно и неощутимо для потока данных, а уж тем более для конечных пользователей. Например, модули-платы маршрутизаторов будут способны самостоятельно перезагружаться без какого-либо влияния на остальные компоненты, находящиеся в одном корпусе с ними. Переключение на резервные маршрутизирующие процессоры таким способом сделает возможным преодоление неполадки еще на уровне 3, что вполне достаточно для того, чтобы не прерывать голосовой разговор.
Пока мы концентрируемся на уровне IP, следует заметить, что такой же прогресс происходит и на физическом уровне, в оптических технологиях следующего поколения. Множество современных оптических компонентов с успехом предоставляют доступность на все “пять девяток”. Также как и в случае с IP, новые сетевые архитектуры и конструкции коммутаторов уже используются в некотором оборудовании. Вместе с будущими версиями современных протоколов, это должно обеспечить мгновенное (менее 50 миллисекунд) переключение на альтернативное устройство, необходимое для голосовых коммуникаций. Будучи скомбинированным с прогрессивными решениями на уровне IP, о которых говорилось выше, эта технология обеспечит IP нужным потенциалом для того, чтобы перепрыгнуть TDM — так как тогда уже не будет необходимости в какой-то дополнительной сети для обеспечения надежной связи (как в SONET, к примеру). Примерами протоколов, которые должны быть усовершенствованы, являются такие протоколы, как Border Gateway Protocol (BGP), Hot Standby Routing Protocol (HSRP), Intermediate System to Intermediate System (IS-IS), Open Shortest Path First (OSPF) и Resource Reservation Protocol (RSVP).
заключение
Если говорить об эволюции высокодоступных, объединенных мультисервисных IP-сетей, то мы стоим перед классической дилеммой “яйца и курицы”. Без гарантий того, что производственные IP-сети будут работать так же, как и сети TDM, сервис-провайдеры и промышленные предприятия не станут сильно на них полагаться. Также как без соответствующего окружения и реальных данных такие сети не смогут как следует развиваться, и прогресс будет протекать очень медленно.
К счастью, видимо, индустрия понемногу выползает из этой трясины. ATM и frame relay сети, аналогичные, но не идентичные чистому IP, не только достигли, но и превзошли по доступности цифровой TDM в производственном окружении. Некоторые из широко освещавшихся проблем вызвали нужный отклик и обеспечили более четкое понимание проблем, связанных с реальными условиями, особенно с влиянием ошибок в процессах и человеческих недочетов. Более того, ведущие сервис-провайдеры внедряют у себя IP-оборудование для объединенных сетей, несмотря на то, что они не очень-то афишируют такие свои инициативы. Все это вполне понятная ситуация, которая традиционна для ранних стадий эволюции сетевой технологии, и так как у каждого при этом свой собственный путь, то каждый в отдельности и приобретает свой собственный опыт в обращении с объединенными сетями.
Главная мысль здесь проста: для того, чтобы IP-сети сегодня достигли “пяти девяток” доступности, необходим целый комплекс наработок — в области теоретического понимания, оборудования, программного обеспечения, процессов и, что самое главное, опыта работы со всем этим в реальных условиях. Все, что должно быть сделано, может классифицироваться на следующие три категории:
С самого начала девяностых мысль о том, что объединенные сети и IP смогут с успехом заменить TDM-сети в нелегком деле передачи голоса и данных, некоторое время витала в умах специалистов, но затем, как-то неожиданно и незаметно, растворилась в воздухе. Основная причина была проста: сети передачи данных, и IP-сети в частности, считались слишком ненадежными для того, чтобы обеспечить достаточно высокие потребности пользователей, привыкших ко всем благам традиционных голосовых TDM-сетей.
Мы давно уже воспринимаем доступность и надежность голосовых сетей, как нечто должное, и во многих аспектах своей жизни ежедневно полагаемся на них. Ведь даже когда с электроэнергией случаются перебои во время бурь или ураганов, телефонная линия почти всегда продолжает работать (наши друзья, которые работают на местной электростанции, объяснили нам причину, по которой это происходит — электропровода располагаются на столбах выше всех остальных, и поэтому падающие деревья повреждают, в первую очередь, именно их) /* здесь и далее описаны реалии американские, а не наши — прим. ред. */
Ключевой термин, характеризующий степень доступности цифровых TDM-сетей — это “пять девяток” — 99,999 процентов доступности. Как скоро IP-сети, в своем продвижении по оси развития технологии, смогут достичь этой отметки? Ответ может удивить вас, но это истинно так — добротно построенные и управляемые на должном уровне IP-сети достигнут равнозначных показателей в ближайшие 18—24 месяца.
Основываясь на исследованиях, проводившихся для данной статьи, можно с полной уверенностью сказать, что данное равенство будет возможно только благодаря усовершенствованиям, обеспеченным использованием Multiprotocol Label Switching (MPLS) и расширенным возможностям таких протоколов, как IS-IS и OSPF, а также все более приспособленными к моментальному восстановлению после сбоев комбинациями аппаратуры и программного обеспечения.
Одновременно с накапливающейся базой общего опыта, касающегося управления IP-сетями, постепенно все части большой головоломки объединенных сетей становятся на свои места.
Путь к построению высоконадежных IP-сетей достаточно прост и не требует дополнительных пояснений, однако, некоторые шаги должны быть предприняты параллельно для того, чтобы повысить доступность этих сетей. Нам необходимо использовать на производстве лучшие IP-технологии, которые, что несколько парадоксально, требуют наличия традиционной телефонии для обеспечения максимально короткого периода восстановления после неполадок. В качестве временной меры, концепция параллельных сетей предлагает альтернативу — устойчивость через многообразие. Это предвещает эпоху, когда будут создаваться объединенные сети со способностью выживания, свойственной интернет-сетям. Это подразумевает возможность перенаправления коммуникационного потока в обход поврежденного участка сети.
формулировки
Когда мы говорим о высокой доступности или IP-сетях операторского класса, что мы при это имеем в виду? Общепринятое определение сводится к 99,999 процентам (или даже более того) — это приблизительно 5,3 минуты бездействия за год.
Важно отметить, что стандартные определения доступности для сетей TDM и сетей IP различаются, что не позволяет провести четкое их сравнение. Состояние, когда все каналы заняты (all circuits busy), к примеру, не рассматривается в качестве выхода из строя TDM-сети, тогда как в IP-сетях дело обстоит именно так.
Также мы должны сразу отметить, что речь идет о сетях, управляемых и контролируемых если не одним сервис-провайдером или компанией, то как минимум небольшим ограниченным числом субъектов. Мы не имеем в виду весь огромный неуправляемый Интернет. Даже ситуации, в которых присутствует несколько сетей или несколько производителей сетевого оборудования, — даже они по сути более контролируемы по сравнению с общедоступным Интернет.
Также для начала будет немаловажно понять и осознать основное равенство, которое используется для оценки факторов, влияющих на доступность. Общая доступность сети, в основных терминах, является продуктом нижеследующего равенства, применительно к каждому ее элементу:
% Availability = MTBF / (MTBF + MTTR) × 100%
Определив общее время, которое сетевой элемент находился в рабочем состоянии (среднее время между выходами из строя, MTBF), и поделив его на сумму времени работы и среднего времени восстановления (MTTR, или время, которое элемент сети находился в нерабочем состоянии), вы сможете определить то время, которое данный элемент был доступен — то есть то, каким количеством тех самых “девяток” он обладает. Также вы можете подставить в это уравнение “минуты, потерянные клиентами” и “общее количество доступных минут”. Определяя значение доступности для каждого отдельно взятого элемента сети, вы сможете определить и общую сетевую доступность.
миф и его происхождение
Компьютеры — бесконечно терпеливые создания. Люди же — наоборот. Компьютеры обладают только лишь теми ожиданиями, которые предписали им мы сами; человеческие же существа обладают огромным и постоянно растущим комплектом всевозможных ожиданий и надежд. Все это очень подходит к той ситуации, с которой сталкиваемся мы, пытаясь объединить голосовые сети и сети передачи данных.
Такие факторы, как неустойчивый сигнал или задержка не являются фатальными для процесса обмена данными, тогда как человеческие предпочтения в области голосовых коммуникаций немного другие. Задержки в более чем 50 миллисекунд создают неприятный для человеческого мозга эффект — когда сознание при всем при этом пытается уловить содержание того, о чем говорит абонент на другом конце провода.
Уже во времена, когда цифровая технология только начинала внедряться на голосовых сетях, в далеких семидесятых, разработчики уже знали о том, что им придется столкнуться с несколькими человеческими особенностями, к которым им предстоит приноровиться, так как бороться с ними не представляется возможным.
Тогда как эффективность передачи голоса посредством цифровых пакетов признается все более и более неоспоримой, создаются новые, прогрессивные технологии, которые в то же время представляют собой некий виртуальный эквивалент проводных “end-to-end” соединений старого образца, — то есть основной принцип, призванный поддерживать размеренную нить разговора, остается прежним. То, что сейчас мы используем TDM (Time Division Multiplexing, мультиплексирование с временным разделением) и обрабатываем данные других разговоров, в моменты, когда в текущем разговоре наступает долгая (с компьютерной точки зрения) тишина, ситуации не меняет.
Ранние преимущества в доступности цифровых TDM-сетей стали результатом таких вещей, как значительная модернизация и усовершенствования технологий мультиплексирования в «медных» сетях. Когда на рынок вышли оптоволоконные системы, качество снова увеличилось. В восьмидесятых, перемещение от асинхронных технологий к SONET также внесло свои коррективы, и планка качества поднялась снова.
С обеспеченной таким образом “выживаемостью” разговора, путь, по которому текла нить разговора, мог быть изменен безо всякого ущерба и потери соединения — трафик автоматически переключался на запасной канал, причем происходило это настолько быстро, что участники разговора не пропускали ни единого звука.
Но цифровой TDM и SONET не с самого начала обеспечивали “пять девяток”; программное обеспечение для SONET, представленное в конце восьмидесятых, не было в достаточной мере стабильным еще два-три года, и по большому счету процесс достижения цифровыми TDM-сетями нужного уровня занял около 15 лет. Относительно надежности, IP также пойдет по пути постепенного взросления.
IP-сети: где мы сегодня
Начав с разработки программных коммутаторов в середине и конце девяностых, производители телекоммуникационных систем стали серьезно изучать проблему построения основанной на IP сети, которая могла бы обрабатывать голосовой трафик с качеством, к которому привыкли пользователи традиционных телефонных сетей. Важно заметить, что крупнейшие сервис-провайдеры планеты занимаются тестированием полного пакета чистых IP-технологий всего лишь на протяжении нескольких лет.
Но вместо 15-ти лет, которые ушли у цифрового TDM на достижение уровня “пяти девяток”, “взросление” IP, предположительно, достигнет цели в течение пяти лет, и это при том, что половина этого пути уже пройдена. Все более усовершенствованное оборудование, программное обеспечение, процессинг и сетевой менеджмент продолжат уменьшать цены и сложность. Несомненно, в достаточным образом контролируемых ситуациях — то есть, в сетях, работающих на оборудовании одного производителя — IP-сети могут достигать “пяти девяток” уже сегодня.
На Рисунке 1, мы сравнили две кривые роста. Это качественно иллюстрирует ту самую среднюю позицию, которая присутствует между менее и более консервативными взглядами на проблему. От разрыва между сегодняшними IP- и TDM-сетями уже удалось избавиться в теории, в лабораторных условиях и при альфа- и бета-тестировании. Что пока отсутствует — так это опыт работы оборудования в реальных условиях, посему здоровый скептицизм сервис-провайдеров и сетевых менеджеров пока еще не развеян. Конечно же, данный опыт накапливается.
Подвергая анализу доступность IP-сетей, а также постоянно увеличивая ее показатели, мы пришли к выводу, что весь процесс работы над этим вопросом необходимо разделить на несколько специальных категорий, которые, каждая по отдельности, по-своему влияют на сетевую доступность. В число этих категорий входят: рассмотрение железа, программного обеспечения, окружения, анализ конструкционных особенностей сети и последнее, но не менее важное, — комбинации технологического процесса и процента ошибок, вызванных так называемым “человеческим фактором”.
оборудование
Оборудование является, со сравнительной точки зрения, самым простым для предсказания, а следовательно — и для устранения неполадок, фактором, который всегда легко заставить работать максимально безотказно при наличии определенных ресурсов. Начиная с мельчайших компонентов каждого отдельного устройства, и заканчивая самыми высоко стоящими в иерархии деталями, мы вычисляем доступность каждого фрагмента сети, выводя тракт прохождения данных для каждого устройства, и далее — комбинируя из получившегося общую сетевую доступность. Поставщики оборудования разработали множество всевозможных программных инструментов для облегчения этой работы, и они хорошо знают наиболее распространенные ошибки. Здесь мы попробуем привести лишь самые основные факторы.
Прежде всего, вы должны разделить всю сеть на определенные сценарии, исходя из того, каким образом и каким путем данные циркулируют по сети к определенным пользователям.
Рисунок 1 — Кривые роста.
Создавая скелетные схемы, представляющие все сетевые элементы и соответствующие тракты данных по каждому из них, вы сможете увидеть, какие из устройств подключены параллельно, а какие - последовательно. Затем вы сможете создать список типов устройств, изменения по которым смогут положительно повлиять на доступность всей сети.
А вот прямиком от этого момента начинается важный этап, касающийся того, каким способом скомбинировать доступность индивидуально по каждому сетевому устройству, включая и группы параллельно подключенных устройств, конвертированных в последовательно-доступные. Очевидно и не подлежит никакому сомнению, что результатом увеличения доступности отдельных компонентов сетевого окружения станет общее увеличение доступности сети.
После всех этих подсчетов вы столкнетесь с так называемым “эффектом бабочки,” как это называется в теории неструктурного программирования — когда мелкие факторы (такие как одна-единственная вышедшая из строя карта маршрутизатора, или плохо отлаженный процесс восстановления) могут иметь очень большое влияние на общую доступность. Безусловно, в этом всегда есть и вторая сторона. Устранив одно слабое место в аппаратной части сети или плохо отлаженный процесс, мы можем обеспечить прыжок показателя доступности сети от четырех девяток до пяти. Но в то же время это значит, что один непредвиденный или незамеченный выход из строя какого-нибудь мелкого компонента может стать причиной пятичасового отключения всей сети в целом.
Хорошие новости состоят в том, что мы знаем, как получить данные MTBF и MTTR. Их могут предоставить либо производители устройства, либо вы сами можете добыть их, ориентируясь на собственный опыт работы с сетями. Принимая это во внимание, проблемы с доступностью оборудования могут быть эффективно решены.
В завершение отметим, что самой распространенной ошибкой является мнение, которое заключается в том, что аппаратный фактор считается единственным фактором, который может повлиять на доступность IP-сети. Безусловно, это не так, ибо тщательный анализ доступности обычно только начинается с железа. Валари Гилберт, глава американского офиса Cisco, говорит по этому поводу вот что: “Наши данные свидетельствуют о том, что на железо обычно приходится около 40 процентов всех проблем с доступностью сетей. Для того, чтобы устранить основные неполадки, следует более тщательно присмотреться к восстановительным процедурам, конструкции сети, экономичному ее использованию, программному обеспечению и т.д.”
программное обеспечение
В IP-сетях существует два главных типа программного обеспечения: операционные системы отдельно взятых устройств (например, маршрутизаторов), и ПО, выполняющее в сети контрольные функции. Оба типа зачастую функционируют параллельно, внося свой немалый вклад в обеспечение доступности сети.
Типичным примером выхода из строя IP-сети является неполадка в операционной системе маршрутизатора. Мы должны определить, насколько быстро маршрутизатор сможет самовосстановиться после этого события, перестроить свои таблицы маршрутизации и начать снова передавать данные — то есть, мы должны определить среднее время восстановления. Так мы можем подсчитать доступность для каждого устройства в понятиях программного обеспечения, адаптировать конструкцию сети так, как это необходимо — включая параллельный дизайн, dual homing для коммутаторов, и так далее — а затем попробовать уменьшить фактор воздействия неполадок ПО на общую сетевую доступность.
Хитрость заключается в том, что надежное ПО, которое специально работает для того, чтобы в нужный момент, во время выхода из строя основной программы, взять ее функции на себя, не добавляет времени к периоду простоя сети, параллельный элемент может помочь успешному продолжению выполнения программы — такая или похожая схема и есть то, что мы называем хорошо построенным механизмом восстановления после неполадок. Ключевое слово в данном случае — безотказность.
В этом случае может помочь как опыт других, так и ваш собственный опыт, включающий наблюдения за работой программы в тестовой ситуации. Также это может быть усилено возможностью возвращения к старой версии какой-либо программы после модернизации или обновления.
Нет какой-либо причины, по которой программное обеспечение для IP-сетей может быть менее надежным, чем ПО для TDM-сетей, поэтому всегда стоит учитывать, что уровень тестов для таких программ обязательно должен оставаться прежним. Также IP-сети могут во многом выиграть, если для их управления будет использоваться опыт администраторов TDM-сетей: самым главным правилом избежания сетевых неполадок, вызванных ошибками ПО, является планировка и жесткое управление процедурами апгрейда. Основные постулаты правильной политики в этой области таковы: апгрейды должны производиться в моменты, когда трафик в сети минимален, в этой работе должен участвовать наиболее опытный персонал, процесс апдейта должен предполагать возможность быстрого отката к ранее установленному ПО/конфигурации при возникновении проблем с новым.
анализ окружения
Эта тема не требует долгих рассуждений, и по одной очень простой причине: все исследования в этом плане фактически остались теми же, что и в TDM-сетях — и что касается голосовых коммутаторов, и других программных инструментов. Первое голосовое IP-оборудование не имело питания от сети, тогда как нынешние продукты для IP-телефонии все оснащены такой системой питания. Как и в традиционных сетях, концепция энергопитания основывается прежде всего на эквиваленте схемы, использующейся в центральном офисе, где происходят те же самые процессы и используются те же самые решения: резервная батарея питания, генераторы, и т.д.
Расчет необходимости происходит тоже традиционно — подсчитывается точное необходимое количество энергии, требующейся устройствам. При этом следует учитывать географические и другие зависящие от местоположения рабочего места факторы. Главная цель всего этого — обеспечить нужный баланс процессов и инструментов для достижения “пяти девяток”. Так как методы и исторический опыт такого процесса уже имеется, мы не будем подробно останавливаться на этой теме.
конструкция сети
Располагая хорошими данными по нынешней сетевой доступности, мы можем добавить в нашу сеть некоторые параллельные элементы, чтобы гарантированно довести ее доступность до “пяти девяток”. Тут следует напомнить, что параллельные конструкции требуют установки механизмов восстановления после неполадки (failover-механизмы), которые, согласно закону Мерфи, также могут ломаться. Несмотря на это, опыт как IP, так и TDM показывает, что параллельная сетевая архитектура — должным образом настроенная, обеспеченная и периодически проверяемая — может быть мощнейшим инструментом для достижения “пяти девяток” производительности сетей.
То, какие элементы должны вводиться параллельно, зависит от факторов, которые индивидуальны для каждой отдельно взятой сети и используемой в ней системы управления.
Некоторые маршрутизаторы могут иметь процессоры, работающие параллельно, или же, в ином случае, можно использовать сразу два отдельных устройства — каждое со своим процессором. Планировка устройств, которые присоединенных к сетевым узлам, может варьироваться, поэтому изменение уровня гарантированной доступности будет зависеть от того, как построены backup-системы.
В то время как параллельные конструкции увеличивают первоначальную стоимость сети, они также увеличивают доступность. Вот вам на заметку одно известное правило: путь от “четырех девяток” к ”пяти девяткам” удвоит ваши расходы, но доступность вашей сети при этом увеличится в 10 раз. Ключ к разгадке вопроса максимизации данного размена лежит в хронологических данных, анализ которых может показать, какие из устройств, присоединенных к сети будут наиболее эффективно способствовать этому.
Так какие же тенденции имеют место на рынке сегодня? Существует два фактора, которые препятствуют тому, чтобы история была рассказана уже сейчас. Во-первых, производители оборудования и сервис-провайдеры все еще не закончили составлять первый в этой истории план стандарта. Второй момент заключается в том, что каждая из этих компаний имеет свой собственный уникальный опыт в этой сфере, и никто не хочет делиться этой информацией с конкурентами. И так как спрос на объединенные сети все растет, и опытная база и практика их использования растет, какие-то общепринятые понятия, методы и правила в этой сфере обязательно должны появиться.
процессы и “человеческий фактор”
Эти две составляющие следует рассматривать только в единой связке, так как они чрезвычайным образом соотносятся и зависят друг от друга. Две ключевых области процессинга, которые следует проверять изначально, это, во-первых — комбинация процесса изменений в программном обеспечении и некое единообразие версий ПО; и второе — взаимосовместимые составляющие конфигураций устройств и платформ по всей сети.
“Для начала мы собираем все, так сказать, “низковисящие плоды”, на уровне клиентов и служащих, — это касается процессов, связанных с восстановительными и операционными процедурами, — рассказывает Гилберт. — Уже одно это само по себе может удвоить сетевую доступность. И только тогда, когда мы достигли этих небольших побед, мы начинаем думать о специфике конструкции, программной и управленческой составляющей, которая может повысить доступность.”
Шаги, которые могут быть предприняты в целях минимизации ошибок, происходящих благодаря “человеческому фактору” по сути такие же, как и те, которые предпринимаются для улучшения любого процесса — планирование, измерения, анализ просчетов, изменений и изменений в процессах управления. Так как это повторяющиеся процессы, они могут быть наглядно рассмотрены примерно так, как это сделано на рисунке 2.
Шаг 1 — Планирование. Начните с того, что продумайте и спланируйте показатели доступности, которыми должна обладать ваша сеть, а также предусмотрите равновесие всех остальных факторов. Это, в общем, тот самый процесс, о котором говорилось выше, и он включает замеры работы оборудования, программного обеспечения, факторов окружения и сетевой архитектуры.
Шаг 2 — Измерения. Отслеживайте с течением времени все причины выходов сети из строя, включая и те, которые произошли по человеческой вине или по вине сбоя в процессах. Также обращайте внимание и хронологизируйте общие показатели рабочего времени, число выходов из строя и время, которое сеть пребывала в нерабочем состоянии. Затем эти данные можно проанализировать (см. Шаг 3), и сравнить с исходными (см. Шаг 1).
Шаг 3 — Анализ просчетов. Сравните запланированные вами показатели (из Шага 1) с реальными (из Шага 2). Следует искать коренные причины, которые приводят к проблемам процессинга, пробовать рассматривать их абстрактно или как минимум начинать с них поиск иных проблем.
Шаг 4 — Изменения/Управление изменениями. Постарайтесь создать методы решения проблем таким образом, чтобы это в то же время не создало новых проблем.
Рисунок 2. Анализ и человеческие ошибки.
Если модернизация программного обеспечения обязательна, к примеру, убедитесь, что предусмотрена возможность при случае вернуться к старому программному обеспечению. Создайте расписание модернизации ПО и следуйте ему.
что дальше
Большое количество работы было проделано Группой по проектированию Интернет (IETF) и многими другими для того, чтобы вывести IP-протоколы на более высокий уровень завершенности. Источники в больших компаниях, занимающихся предоставлением услуг связи убеждены в том, что протоколы достигнут нужного уровня зрелости уже в ближайшие 24 месяца. Одна из причин, по которой они столь оптимистичны — это MPLS, который позволяет использвать в IP-сетях такие виды управления трафиком, какие пытаются внедрить в TDM-сети вот уже на протяжении многих лет. MPLS выделяет особые пути для определенных последовательностей пакетов посредством пометки их таким образом, что маршрутизаторы получают возможность передавать их более оперативно. В OSI-модели это означает пересылку большинства пакетов по уровню 2, нежели по уровню 3. Также это способствует внедрению QOS, устанавливая прииоритеты для различных типов трафика — к примеру, наделяя большей степенью срочности чувствительный к задержкам голосовой трафик, нежели почтовый.
Конечно, MPLS помогает еще и в том, что касается восстановления сети. Fast Reroute, LSP (Label Switched Path) и Backup Record Route каждый в своей степени полагаются на различные методы обеспечения моментального восстановления сети, что с успехом и используется сегодня в ATM и SONET. Каждый из них имеет свои “за и против”, и каждый из них сейчас переживает болезненный процесс эволюции стандартов — как при поддержке оффициальных структур, таких как IETF и ITU, так при посредстве компаний-производителей оборудования, которые всегда следуют реальным необходимостям рынка и постоянно испытывают на себе его давление.
Параллельно с работой над самим по себе IP-стандартом ведутся не такие явные работы по разработке новой технологии, которая бы сделала IP-сети более надежными. В число проблем, которые занимают организации, ведущие разработки таких проектов, входят:
·Наличие дополнительного оборудования и программного обеспечения в IP-сети, которое автоматически переключается на альтернативные каналы, если основные каким-то образом выходят из строя. Это может случаться довольно часто, так что при всем при том процесс переключения должен быть незаметным для тех, кто разговаривает в этот момент по телефону (то, что сегодня успешно реализовано в TDM-сетях). Все крупнейшие производители маршрутизаторов и коммутаторов работают над этой проблемой.
·Наличие маршрутизаторов, коммутаторов и другого оборудования, которое может обновлять свое ПО без необходимости отключения на более чем 15-45 минут, как это происходит сегодня.
Эти основные направления, по которым должно вестись развитие технологии маршрутизирования, призваны наделить IP-устройства возможностями переключаться на запасное оборудование незаметно и неощутимо для потока данных, а уж тем более для конечных пользователей. Например, модули-платы маршрутизаторов будут способны самостоятельно перезагружаться без какого-либо влияния на остальные компоненты, находящиеся в одном корпусе с ними. Переключение на резервные маршрутизирующие процессоры таким способом сделает возможным преодоление неполадки еще на уровне 3, что вполне достаточно для того, чтобы не прерывать голосовой разговор.
Пока мы концентрируемся на уровне IP, следует заметить, что такой же прогресс происходит и на физическом уровне, в оптических технологиях следующего поколения. Множество современных оптических компонентов с успехом предоставляют доступность на все “пять девяток”. Также как и в случае с IP, новые сетевые архитектуры и конструкции коммутаторов уже используются в некотором оборудовании. Вместе с будущими версиями современных протоколов, это должно обеспечить мгновенное (менее 50 миллисекунд) переключение на альтернативное устройство, необходимое для голосовых коммуникаций. Будучи скомбинированным с прогрессивными решениями на уровне IP, о которых говорилось выше, эта технология обеспечит IP нужным потенциалом для того, чтобы перепрыгнуть TDM — так как тогда уже не будет необходимости в какой-то дополнительной сети для обеспечения надежной связи (как в SONET, к примеру). Примерами протоколов, которые должны быть усовершенствованы, являются такие протоколы, как Border Gateway Protocol (BGP), Hot Standby Routing Protocol (HSRP), Intermediate System to Intermediate System (IS-IS), Open Shortest Path First (OSPF) и Resource Reservation Protocol (RSVP).
заключение
Если говорить об эволюции высокодоступных, объединенных мультисервисных IP-сетей, то мы стоим перед классической дилеммой “яйца и курицы”. Без гарантий того, что производственные IP-сети будут работать так же, как и сети TDM, сервис-провайдеры и промышленные предприятия не станут сильно на них полагаться. Также как без соответствующего окружения и реальных данных такие сети не смогут как следует развиваться, и прогресс будет протекать очень медленно.
К счастью, видимо, индустрия понемногу выползает из этой трясины. ATM и frame relay сети, аналогичные, но не идентичные чистому IP, не только достигли, но и превзошли по доступности цифровой TDM в производственном окружении. Некоторые из широко освещавшихся проблем вызвали нужный отклик и обеспечили более четкое понимание проблем, связанных с реальными условиями, особенно с влиянием ошибок в процессах и человеческих недочетов. Более того, ведущие сервис-провайдеры внедряют у себя IP-оборудование для объединенных сетей, несмотря на то, что они не очень-то афишируют такие свои инициативы. Все это вполне понятная ситуация, которая традиционна для ранних стадий эволюции сетевой технологии, и так как у каждого при этом свой собственный путь, то каждый в отдельности и приобретает свой собственный опыт в обращении с объединенными сетями.
Главная мысль здесь проста: для того, чтобы IP-сети сегодня достигли “пяти девяток” доступности, необходим целый комплекс наработок — в области теоретического понимания, оборудования, программного обеспечения, процессов и, что самое главное, опыта работы со всем этим в реальных условиях. Все, что должно быть сделано, может классифицироваться на следующие три категории:
- опыт обращения с новейшими версиями MPLS и связанными с ним протоколами;
- разработка значительного числа решений, представляющих собой комбинации hardware/software с мгновенной возможностью преодоления неполадок;
- разработка новых, подходящих процессов управления.
Дэвид Едвэб и Крис Тэлботт, перевод Дениса Матвеева.
обсуждение статьи
Сетевые решения. Статья была опубликована в номере 01 за 2003 год в рубрике технологии
