Метакомпьютинг: вычислительная инфраструктура будущего
Есть все основания полагать — и это стимулирует всеобщий интерес, — что те существенные продвижения, которые уже были сделаны, и те ожидания, которые возлагаются на будущее, связаны не только собственно с областью высокопроизводительных вычислений. Предлагаемые подходы способны оказать глубокое влияние на компьютерную индустрию в целом, включая и то, что принято называть массовым рынком.
Направление, о котором идет речь, можно обозначить как использование компьютерных сетей для создания распределенной вычислительной инфраструктуры национального и мирового масштаба. На сегодня сети доказали беспрецендентную практическую полезность, выступая как средство глобальной доставки различных форм информации. Однако потециал сетей раскрыт не полностью: они могут стать еще и средством организации вычислений следующего поколения.
Что представляет собой Internet? Это множество узлов с собственными процессорами, оперативной и внешней памятью, устройствами ввода/вывода. Узлы соединены друг с другом коммутационным оборудованием и линиями передачи данных. Такая конструкция весьма напоминает многопроцессорную систему, в которой роль магистральных шин выполняет Сеть.
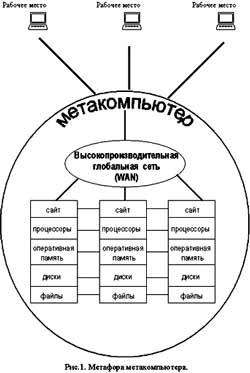
Центральное понятие метакомпьютера можно определить как метафору виртуального компьютера, динамически организующегося из географически распределенных ресурсов, соединенных высокоскоростными сетями передачи данных (рис.1). Отдельные установки являются составными частями метакомпьютера и в то же время служат точками подключения пользователей.
Необходимо подчеркнуть принципиальную разницу метакомпьютерного подхода и сегодняшних программных средств удаленного доступа. В метакомпьютере этот доступ прозрачен, то есть пользователь имеет полную иллюзию использования одной, но гораздо более мощной, чем та, что стоит на его столе, машины и может с ней работать в рамках той же модели, которая принята на его персональном вычислителе.
Прежде всего имеет смысл остановиться на вопросе: зачем может быть нужна такая среда? Как уже говорилось, непосредственные потребности исходят от высокопроизводительных приложений. В различных прикладных областях (космологии, гидрологии окружающей среды, молекулярной биологии и т.д.) поставлены весьма важные задачи, характеризующиеся, например [3], следующими требованиями к компьютерным ресурсам:
— 0.2 — 20 Tflops процессорной мощности;
— 100 — 200 GB оперативной памяти;
— 1— 2 TB дисковой памяти;
— 0.2 — 0.5 GB/sec ширина полосы пропускания ввода/вывода.
Нижняя граница таких запросов — это уникальные архитектуры типа SGI/CRAY Origin с тысячами процессоров. С другой стороны суммарный объем ресурсов в достаточно большом фрагменте Сети далеко превосходит эти цифры, вопрос в том, как эти ресурсы объединить и дать в руки реальному потребителю.
Такая постановка очень серьезно воспринимается во всем мире и в первую очередь в Соединенных Штатах. Здесь роль организующего начала взял на себя фонд Национальный научный фонд NSF — — National Science Foundation. Для NSF проект вычислительной сетевой среды стал естественным продолжением предыдущей общенациональной программы создания суперкомпьютерных центров, начатой в 1985 году и завершившейся в сентябре 1997.
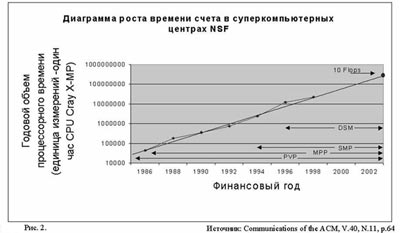
После того как в 1992 году в строй ввели 512 — процессорную CM?, количество проектов Национального центра суперкомпьютерных приложений (National Center for Supercomputing Applicaions — NCSA), потребляющих свыше 1000 процессорных часов в год (в единицах CRAY X-MP), увеличилось с 10 до 100 (рис.2). Желающие есть, были бы возможности.
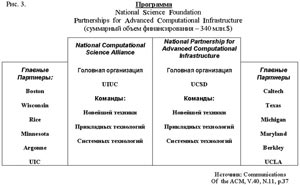
Она выполняется сразу двумя крупными научными объединениями: National Computational Science Aliance (далее Aliance) и National Partnership for Advanced Computational Infrastructure (NPACI) с суммарным финансированием в 340 миллионов долларов, осуществляемым NSF, DARPA, NASA, Министерством обороны (программа модернизации).
План Aliance ставит задачу (и за истекший период она достаточно успешно реализуется) создания Национальной Технологической Сети GRID, которая способна открыть доступ с рабочих мест к самой большой из когда—либо собранных вычислительных сред для решения сложнейших научных и инженерных задач. Термин GRID используется для обозначения вычислительной среды по аналогии с электрической сетью: включение в GRID пользователей должно быть столь же легким, как и включение бытовых приборов.
Имея штаб-квартиру в NCSA при Университете штата Иллинойс, Aliance объединяет исследователей из более чем 50 университетов, национальных лабораторий и промышленных организаций. Структуру проекта опрелеляют три главных направления (команды) — Новейшей техники (Advanced Hardware), Прикладных технологий (Application Technology) и Системных технологий (Enabling Technology). Включение в проект команды AT дает возможность двум другим отталкиваться от конкретных потребностей реальных задач, а также опробовать собственные решения на практике, так что GRID существует в виде постоянно действующего и развивающегося прототипа.
Формы метакомпьютера
По-видимому понятно, что проекты метакомпьютера не делаются за один день и требуют долговременных усилий в течение по крайней мере десятилетия (к примеру, Aliance предполагает оформить свою работу в виде прототипа), поэтому важно определить формы и этапы развития метакомпьютерной среды.
1. Настольный суперкомпьютер. Пользователь получает возможность запускать свои задачи на удаленных вычислительных установках с таким объемом вычислительных ресурсов, которые необходимы для успешного счета. При этом от пользователя не требуется искать подходящие не занятые мощности: распределять задачи в сети в соответствии с их запросами — функция метакомпьютера. В рамках метакомпьютинга разрабатываются схемы глобальных прав доступа, дающие возможность пользователю вступать во временное владение найденными ресурсами без персональной регистрации на исполнительной установке и одновременно гарантирующие надежную защиту.
Не следует понимать название "настольный суперкомпьютинг" слишком буквально
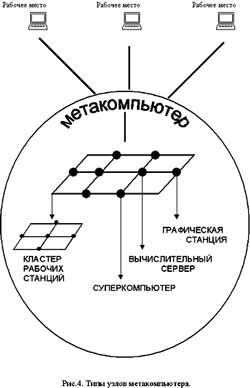
Кроме доступа к многопроцессорным комплексам для решения распараллеленных задач, этот режим полезен и для выхода на ресурсы других типов, например, на мощные графические станции со специализированными процессорами или на базы данных с большими объемами информации, которые по тем или иным причинам не могут быть тиражированы (рис.4).
Переход к работе в режиме настольного суперкомпьютинга достаточно безболезнен как для пользователей, так и для программистов. Фактически они работают со штатными ОС исполнительных установок. Этот режим, однако, представляется весьма важным этапом, открывающим реальные возможности освоения передовых компьютерных технологий всему научному и инженерному сообществу, независимо от расположения рабочих мест пользователей и необходимых им вычислительных ресурсов. Как результат, можно ожидать более эффективного использования уникального и дорогостоящего оборудования, резкого роста числа приложений, в которых находят применение самые передовые методы обработки данных.
2. Интеллектуальный инструментальный комплекс. Практический опыт из многих прикладных областей показывает, что быстро считать недостаточно: часто необходимо в реальном времени собирать большие объемы данных, поступающих с датчиков, производить анализ текущей ситуации, вырабатывать решения и выдавать управляющие воздействия. Все это требует тесной интеграции управления, обработки данных разного вида, моделирования процессов, визуализации в реальном времени. Вычислительные комплексы такого рода получили название интеллектуальных инструментов.
В качестве примера приведем схему мониторинга облачного покрова, реализованную в экспериментальном стенде I—WAY [3] (рис.5).
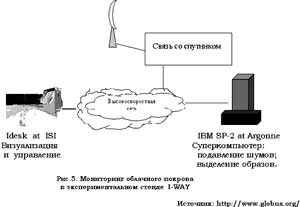
Здесь со спутника производится съемка облачного покрова, большой объем собранных данных передается на Землю на суперкомпьютер, выполняющий подавление шумов и выделение образов. Затем по скоростным линиям информация поступает на удаленный графический суперкомпьютер, производящий рендеринг и генерирующий наблюдаемую панораму. В конце концов графическое изображение попадает на рабочее место исследователей, которые управляют сенсорами спутника в реальном времени.
Этот вариант метакомпьютера характеризуется распределением обработки по Сети, а следовательно требует высокопроизводительных линий связи. Кроме того, создание таких приложений требует разработки специальных средств для реализации взаимодействия программных компонентов, выполняющихся на разнесенных вычислительных системах.
3. Сетевой суперкомпьютер. При таком подходе идея метакомпьютинга доводится до логической завершенности, а именно: масштабирование всех возможных вычислительных ресурсов путем прозрачного безшовного объединения посредством сети отдельных вычислительных установок разной мощности. Составляющими элементами такой конструкции могут быть суперкомпьютеры, серверы, рабочие станции и даже персональные компьютеры. Отличительной особенностью этой формы является то, что суммарные ресурсы агрегированной архитектуры могут быть использованы в рамках одной задачи.
В такой форме можно выделить два уровня. Первый применим как альтернатива суперкомпьютеру "в ящике". Сетевой суперкомпьютер создается из относительно недорогих компонентов (серверов — рабочих станций) путем их соединения локальной сетью. Известно, что стоимость такого решения даже на базе дорогого и мощного сетевого оборудования все же на порядок меньше цены готового суперкомпьютера (а это миллионы долларов) при сопоставимых характеристиках процессорной производительности.
Второй уровень — для тех, кто имеет Суперузлы, то есть настоящие или сетевые суперкомпьютеры. Объединение их в региональном и национальном масштабах скоростными глобальными линиями связи способно дать беспрецендентные мощности. Собственно этот уровень масшабирования точно соответствует термину метакомпьютинг.
Сопоставляя приведенные четыре формы метакомпьютинга, следует сказать, что полезность их в конкретных условиях в большой степени определяется степенью развитости сетевой инфраструктуры и наличием (или отсутствием) высокопроизводительной техники. Представляется, что в наших условиях (отсутствие суперкомпьютеров и качественных линий связи) ценность метакомпьютерного подхода не только не уменьшается, а напротив возрастает, нужны только правиьные и достижимые приоритеты. Правильная последовательность шагов видится следующим образом:
— обеспечение дистанционного доступа к крупным корпоративным вычислительным центрам (настольный суперкомпьютинг);
— создание единой вычислительной среды в тех же центрах с помощью локальных сетей (сетевой суперкомпьютер);
— по мере развития аппаратной инфраструктуры агрегация вычислительных центров в региональном и далее в национальном масштабе (интеллектуальные инструменты и метакомпьютер).
проблемы создания метакомпьютера
Распространение метакомпьютерных технологий может произойти только при гармоничном сочетании двух направлений: развития технической базы и создания программного обеспечения нового поколения.

Вычислительную основу составляют Суперузлы, представляющие собой крупные вычислительные центры с одним или несколькими мощными суперкомпьютерами. На 1998 в GRID входили:
— SGI/CRAY Origin2000 512 процессоров HP Exemplar-2000 64 процессора в NCSA (Иллинойский университет)
— IBM SP 400 процессоров в High Perfomance Computing Centre (Maui)
— SGI/CRAY Triton 4 процессора SGI/CRAY T3E 128 процессоров в Суперкомпьютерном Центре Огайо
— IBM SP 160 процессоров в Аргонне
— SGI/CRAY Origin2000 128 процессоров в Бостонском университете
— HP Exemplar? 64 процессора в университете Кентукки
— пул 500 рабочих станций Unix (Condor) в университете Висконсин.
Как видно из списка, география очень широкая, и для совместной работы Суперузлы должны быть соединены быстрыми линиями связи. По американским оценкам их коммерческий Internet реально дает производительность: днем несколько сотен Кбит/сек., а ночью 2? Мбит/сек. Для вычислений этого конечно недостаточно.
Развитие GRID ориентировано на сети второго поколения. В первую очередь это магистрали vBNS (NSF), ESNet (Министерство энергетики), DREN (Министерство обороны), NASA Science Internet, Internet2. В этих сетях используются протоколы от DS? с пропускной полосой 45 Mb/sec до OC
?(622 Mb/sec). Планы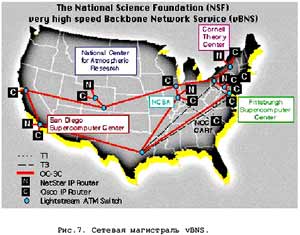
Aliance ставят задачу довести производительность до 38,4 Gb/sec, и параллельно производится подключение участников проекта к магистралям такого рода (рис.7).
Оценивая задачи разработки ПО метакомпьютинга, можно увидеть, что они способны стимулировать революционные изменения в способах организации вычислений и методах программирования. Фактически предстоит переход от операционных сред, расчитанных на обслуживание автономных установок и нескольких пользователей, к интегрированной программно-аппаратной инфраструктуре коллективного пользования. Масштабируемое ПО метакомпьютера должно сделать доступным все ресурсы Сети и при этом полностью скрыть наличие сетевых коммуникаций, включая и присущие им недостатки: нестабильность, высокую вероятность аварий, ограничения по производительности.
Достаточно ясно, что метафора метакомпьютинга затрагивает все базовые подсистемы современных ОС: управление памятью, процессами и файлами, ввод/вывод, безопасность. На современном уровне оказываются затронутыми и общераспространенная модель программирования, и традиционные интерфейсы (но это к сожалению, как раз этого хотелось бы избежать).
В некоторых аспектах трансформация ОС в сетевую среду может быть реализована прозрачно, пример чему дает управление памятью. Можно организовать сверхбольшое адресное пространство для задач, используя виртуальную память нескольких машин. При подкачке страницы может происходить ее пересылка по сети с узла, на котором она размещается в данный момент, на узел, где выполняется задача. Такая схема реализована в программах (TreadMarks [4]), эмулирующих аппаратные архитектуры типа DSM (распределенной общей памяти) и действующих на уровне механизмов ОС совершенно прозрачно для любых приложений. Даже в готовые приложения не требуется вносить каких-либо изменений — они получают большую память бесплатно.
Пример противоположного сорта демонстрирует механизм безопасности. В современных ОС (и Unix, и Windows) он основан на персональной регистрации каждого пользователя, получающего доступ к машине. Этот метод практически непригоден в динамически организующейся среде метакомпьютера, в которой каждый пользователь может претендовать на "чужие" ресурсы. В такой ситуации нужен принципиально иной подход, сохраняющий за каждым административным доменом право проводить собственную политику безопасности и гарантирующий надежность, но в то же время предполагающий однократную регистрацию пользователей в общей распределенной среде.
Реальное положение дел приводит к необходимости реализации упрощенных механизмов управления метакомпьютером. По аналогии с сетевой виртуальной памятью можно бы было обходиться и с процессами: если задача порождает несколько параллельных процессов, некоторые можно переслать на другой узел и выполнить там. Однако, чтобы это имело смысл, нужно знать, какова вычислительная сложность каждого процесса, каковы возможности сетевого канала между узлами. Если такой информации нет, можно не ускорить, а замедлить ход выполнения всей задачи.
Поэтому в области высокопроизводительных приложений применяется "промежуточное" решение — кластерные системы пакетной обработки заданий для управления вычислительным процессом в многоузловых системах, объединяющих локальной сетью многопроцессорные установки и рабочие станции Unix. Пользователи могут запускать задания не на конкретную машину, а на кластер в целом. Задания оформляются обычным образом с добавлением паспорта требуемых ресурсов: времени счета, объема памяти и дискового пространства, количества процессоров и т.д. Система пакетной обработки ведет очереди заданий и выполняет их распределение по наличным ресурсам, оптимально балансируя нагрузку на узлы.
Помогая пользователем, кластерные системы сильно облегчают жизнь администраторам вычислительной техники, упорядочивая их взаимотношения с пользователями. Поэтому, независимо от проблем метакомпьютинга, их можно рекомендовать для организаций, заинтересованных в эффективной организации вычислительного процесса. Например, простаивающие по ночам персональные машины могут загружаться долговременными расчетами в пакетном режиме.
Примерно такая же идеология управления ресурсами, но уже на уровне глобальных сетей типа Internet поддерживается программной метакомпьютерной средой Globus [5], развиваемой в рамках проекта PACI. Эдесь пул ресурсов формируется из крупных сайтов, разбросанных по всему миру. Информация об их состоянии динамически собирается на выделенном сервере, к которому могут обращаться все сертифицированные пользователи. Потенциально можно запустить задание на суперкомпьютер, расположенный, скажем, в Бостонском университете и получить результат на свое рабочее место. Уже в сегодняшнем состоянии Globus представляет собой развитую среду, в которую входят средства управления сетевой передачей, дистанционного доступа к файлам, обеспечения безопасности и т.д.
сегодняшняя архитектура метакомпьютерной среды

Подводя итог рассмотрению проблем создания метакомпьютерного ПО, можно сделать вывод о реальной на сегодняшний день архитектуре (рис.8). Это два уровня, первый, локальный, включает:
— систему управления пакетной обработкой (LSF, LoadLeveler, Condor, DQS, PBS)[6,7];
— распределенную файловую систему (NFS, DFS, AFS) [8];
— систему эмуляции распределенной общей памяти.
На роль второго, глобального уровня претендует Globus, интегрирующий функции управления ресурсами, запуска заданий, глобальной файловой системы и безопасности. Однако, эта далеко не завершенная среда, практически все из перечисленных подсистем нуждаются в существенной доработке и, возможно, в новых подходах
взаимосвязь метакомпьютинга с общими проблемами развития системного ПО
Общее соображение, обосновывающее общезначимость технологий, развиваемых в рамках метакомпьютерного направления, состоит в том, что современные ОС во все большей степени становятся завязаны на Сеть, ориентирусь на коллективные и мобильные формы работы пользователей с прямым доступом к общей информации и ПО. Это определяет общую направленность движения.
Во-вторых, на массовом рынке наметилась тенденция в сторону параллелизации и серийно выпускаемых архитектур (рядовыми стали многопроцессорные RISC-серверы и ПК с 4 — 8 процессорами Intel), и ОС, и работающих в них приложений. Все ведущие производители, выпуская свои ОС, делают одну версию для всего ряда машин — от рабочих станций до суперкомпьютеров, так что фактически даже на простейших однопроцессорных компьютерах есть как базовая, так и инструментальная поддержка параллельных вычислений.
Сетевые технологии коммерческих ОС — JAVA, удаленный вызов процедур RPC, объектные методы доступа CORBA, DCOM, система X Window, прикладные протоколы HTTP и FTP, модель клиент—сервер — сыграли колоссальную роль, показав возможности сетей и введя их в повседневную практику. Становится, однако, понятно, что они решают далеко не все проблемы, а часть средств оказалась чрезмерно ориентированной на конкретные приложения (к примеру протокол HTTP).
Метакомпьютерный подход, ставя проблему создания полной среды и инфраструктуры для сетевых вычислений, определяет один из возможных контекстов, в которым перечисленные методы могут занять свое место. Конкретно, интерес представляют работы по: глобальным файловым системам, системам сертификации и авторизации пользователей, оптимизации сетевой передачи данных, управлению ресурсами, планированию и диспетчеризации процессов.
Это подтверждается и тем, что хотя в проекте PACI в основном участвуют исследователи из академических учреждений, они работают в тесном сотрудничестве с промышленными разработчиками новой техники и ПО. Кроме того, ряд самых известных компаний (Sun, IBM и даже Microsoft) инвестируют в собственные проекты по очень похожим темам.
В качестве заключения: сейчас условия для участия в общем движении в области метакомпьютинга достаточно благоприятны — тексты разработанного ПО обычно открыты, есть оперативный доступ по WWW к планам разработчиков и документации, можно принимать участие в обсуждении проблем по электронной почте. Чтобы опять не бежать за поездом, стоит включиться не откладывая.
Корягин Д.А., Коваленко В.Н.
ИПМ им. М.В.Келдыша РАН
Сетевые решения. Статья была опубликована в номере 11 за 2000 год в рубрике технологии
