
В поисках мифического Memex. Часть 1
Наша информационная эпоха, бурный рост и развитие которой мы имеем возможность сейчас переживать, дает не только бесчисленные возможности, но и таит в себе вполне реальные угрозы. Давление информации требует со стороны работника информационной эры особого подхода и тщательной упорядоченности во всем, чтобы не стать невольной жертвой информационного шума. Сегодня мы начинаем публикацию серии статей, посвященных рассмотрению передовых и наиболее интересных решений в области персональных инструментов управления информацией (этот класс программ, как правило, именуется PIM). При этом, отбирая лучших, для пущей универсальности рассмотрим и сравним ярких и необычных представителей из этой категории, принадлежащих как к миру Windows, так и Unix и Mac OS X.
Но прежде чем начать наш первый обзор из серии, давайте немного погрузимся в историко-методологический обзор, тем более что это пойдет на пользу рассматриваемым нами сегодня проблемам и позволит лучше понять принципиальные отличия в существующих подходах к реализации современных PIM (personal information manager). И, как легко видеть, в названии сегодняшней статьи неслучайно фигурирует упоминание о Memex (en.wikipedia.org/wiki/Memex) - мифической программе-устройстве, которая считается прообразом всех современных менеджеров информации. Название Memex, происходящее от слов memory (память) и index (индекс, список), - это концепция идеального запоминающего и категоризирующего устройства, которое могло бы помочь упорядочить всю имеющуюся информацию независимо от ее объема и разнородности, сделав максимально доступной для людей, с ней работающих. Впервые эта система была концептуально описана Ванневаром Бушем (en.wikipedia.org/wiki/Vannevar_Bush) в 1945 году в ставшей известной по тем временам статье «Как мы можем думать».
Фактически речь идет о самом настоящем описании гипертекста: описания взаимных тематических ссылок для плотной семантической связности всех данных. Кроме гиперссылок, там есть много опережающих то время предсказаний-предложений: это компьютерное распознавание речи, создание повсеместно доступных и самоорганизующихся силами самих читателей энциклопедий (сегодняшняя Wikipedia), создание глобальных сетей для всемирного доступа к данным (сегодняшний Интернет). Обширная статья была напечатана в известном журнале Fortune и тут же перепечатана в еще более массовом журнале Life. К сожалению, этот же номер Life рядом со смелыми озарениями ученого содержал горячий фоторепортаж о бомбардировке Хиросимы и Нагасаки - начиналось совсем другое, поствоенное время… Революционные предложения и идеи Ванневара Буша оказались быстро забытыми под натиском новой глобальной эпохи – началом холодной войны между странами НАТО и Варшавского договора.
Memex - король порядка
 Забытый всем миром Буш пишет в одиночестве в своей последней монографии, озаглавленной «Memex-2»: «Наступят времена, когда человечество полностью откажется от записи информации на бумаге - все будет храниться в виде электронных записей». И далее он предсказывает и вовсе фантастические для своих современников вещи, которые в эти тяжелые послевоенные годы лишены даже самого элементарного смысла: «Большие преобразования коснутся не только технологии хранения текстов, но и звука, кино, фотографий. Все будет храниться в едином электронном формате и будет доступно любому человеку мгновенно из любой точки мира».
Забытый всем миром Буш пишет в одиночестве в своей последней монографии, озаглавленной «Memex-2»: «Наступят времена, когда человечество полностью откажется от записи информации на бумаге - все будет храниться в виде электронных записей». И далее он предсказывает и вовсе фантастические для своих современников вещи, которые в эти тяжелые послевоенные годы лишены даже самого элементарного смысла: «Большие преобразования коснутся не только технологии хранения текстов, но и звука, кино, фотографий. Все будет храниться в едином электронном формате и будет доступно любому человеку мгновенно из любой точки мира».
Прошло много лет, и об идейном наследии Ванневара Буша в наше время вскользь вспоминают лишь в связи с историей практической реализации (а не изобретения, как это часто ошибочно утверждают) гипертекста, впервые реализованного в 90-х годах в проекте WWW сэром Тимом Бернес Ли (en.wikipedia.org/wiki/Tim_Berners-Lee).
И хотя это гораздо менее известно, есть и вторая идейная ветвь в сегодняшнем настоящем, которую дали работы этого ученого-футуриста, - его концепции «симиалитических индексов», которые в наше время стали гораздо более известны под термином «облако смысловых тегов».
В далеком 1945 году Ванневар Буш прозорливо предупреждал, что способы иерархической и линейной организации данных весьма ограничены и не всегда позволяют по-настоящему хорошо упорядочить данные - для этого он разработал теговую концепцию: стандартизированные смысловые метки, которые могут дополнительно помечать уже отсортированный по какой-либо традиционной схеме материал, этим самым радикально повышая качество его агрегации.
Поэтому, посвящая нашу серию обзоров современным настольным средствам управления и упорядочивания информации (PIM), важно знать и учитывать эти различные существующие подходы для выбора максимально эффективного инструмента PIM. Итак, воздав дань памяти идейному первопроходцу многих методов упорядочивания данных, о которых сегодня пойдет речь, давайте перейдем в практическую плоскость рассмотрения органайзеров. И раз уж мы начали с истории, давайте именно ею и закончим наше необходимое историческое вступление.
Как я уже упомянул выше, кроме гипертекста была и вторая ветвь наследия Ванневара Буша - это концепция смысловых тегов. Как ни странно, но впервые она была реализована в виде отдельной законченной программы довольно поздно - в 1998 году, специалистами в то время очень известного и крупного интернет-провайдера CompuServe, и называлась эта программа Personal Knowbase. Способ хранения и упорядочивания всех данных здесь впервые в истории был полностью построен на индексном (теговом) принципе. Но этой реализации идей Буша снова не повезло: крупнейший американский интернет-провайдер в 80-х, увлекшись изобретением «своего собственного, особого Интернета», не выдержал конкуренции со стороны традиционных провайдеров и открытых стандартов и был по большей части «съеден» и благополучно «прожеван» компанией AOL, перестав существовать в своем старом виде в конце 90-х.
Идея теговых органайзеров оказалась снова заброшенной. Но на этот раз бывшие разработчики CompuServe, к счастью, смогли самостоятельно самоорганизоваться, чтобы создать свою собственную, отдельную компанию Bitsmith Software, в которой вскоре и возобновили разработку этой замечательной программы. После чего вполне благополучно в середине 2000 года выпустили уже вторую ее версию - уже под флагом новой независимой фирмы.
Personal Knowbase: деревья vs. ключевые слова
 Как уже понятно из несколько затянутого смыслового подвода к теме, сейчас мы более подробно прощупаем эту программу с сугубо практической точки зрения. Но перед этим хочется еще раз подчеркнуть, что эта, в сущности, довольно маленькая и простая программка имеет не только очень богатую и солидную историю, но и до сих пор является в некотором смысле уникальной - настолько активно теговый способ самоорганизации информации пока не использует ни одна известная мне PIM (как минимум выполненная в традиционном десктоповом формате, хотя в Интернете, нужно признать, теговые облака получили просто превосходное распространение и популярность).
Как уже понятно из несколько затянутого смыслового подвода к теме, сейчас мы более подробно прощупаем эту программу с сугубо практической точки зрения. Но перед этим хочется еще раз подчеркнуть, что эта, в сущности, довольно маленькая и простая программка имеет не только очень богатую и солидную историю, но и до сих пор является в некотором смысле уникальной - настолько активно теговый способ самоорганизации информации пока не использует ни одна известная мне PIM (как минимум выполненная в традиционном десктоповом формате, хотя в Интернете, нужно признать, теговые облака получили просто превосходное распространение и популярность).
Приступая к знакомству с Personal Knowbase (www.bitsmithsoft.com), нужно сразу признать: эта программа вряд ли поразит вас своими графическими наворотами, большим количеством форм или окон с настройками. Программа представляет собой в чистом виде концепт, хотя и реализованный в виде полностью рабочей и практически пригодной для повседневных нужд программы-органайзера. Но в силу новизны и некоторой своей необычности она потребует какого-то начального навыка работы с ней, который все же, нужно признать, совсем не сложен, и после этой вводной статьи, я уверен, будет в полной мере уже сформирован. Остается лишь заметить, что мы приступаем к рассмотрению текущей версии - v3.2.2.
Основные возможности и ограничения
 Давайте традиционно для обзора программ сначала перечислим ее основные возможности, чтобы потом уже на практике посмотреть, как они реализованы в реальной жизни. Итак, в программе имеется:
Давайте традиционно для обзора программ сначала перечислим ее основные возможности, чтобы потом уже на практике посмотреть, как они реализованы в реальной жизни. Итак, в программе имеется:
. реализация простейшей булевой логики для ключевых слов;
. реализация как обычных гиперссылок, так и ссылок на внешние файлы и заметки внутри самой базы;
. возможность вкладывать вложения, которые могут быть как в виде внешних файлов, так и файлов, выложенных на некотором интернет-ресурсе; . возможность двухуровневой защиты всей информации паролем;
. возможность экспортировать хранимую информацию во внешние источники в различные форматы;
. возможность импорта информации из внешних источников также через различные форматы;
. реализация традиционных сортировок, а также полнотекстового поиска (я проверил - полностью рабочий и с русским языком), возможность метить отдельные записи значком;
. очень подробная качественная справочная информация.
Как учат на вузовских лекциях физики, наиболее ярко физические модели (и их свойства) проявляются в их предельных состояниях. Поэтому давайте попробуем посмотреть на Personal Knowbase через призму граничных условий. Итак, в дополнение перечислим эти самые предельные возможности программы в форме вопроса и ответа.
. Какое количество тегов можно использовать при описании своих записей? Разработчики говорят, что неограниченное. И добавляют: мы тестировали работу программы при 10.000 тегов в базе - никаких проблем при этом в работе программы не обнаружили.
. Какие размеры максимальной статьи в базе? Ответ: 16 Мб. При этом очень советуют не использовать такие большие статьи в работе с Personal Knowbase, так как откровенно признаются, что программа будет очень сильно тормозить.
. Третий очень важный вопрос из этой серии: каков потолок по количеству статей в базе? Ответ разработчиков: теоретических ограничений внутри самой Personal Knowbase нет. При этом они делают вынужденное дополнение: учитывая ограничения на размер одного файла в файловой системе Windows (2 Гб), этот барьер преодолеть не удастся. Впрочем, что можно добавить по этому поводу от себя, так это то, что вряд ли вы захотите использовать эту мини-базу, если количество записей в ней будет превышать, скажем, 200.000 записей, так как для эффективной ориентации в такой действительно огромной базе данных одной концепции тегов будет, пожалуй, маловато.
. Следующее ограничение для использования программы в локальной сети: да, саму базу можно выложить на сетевой диск для использования ее другими, но при этом только один пользователь может одновременно работать с такой базой (для многопользовательского безопасного просмотра лучше использовать версию PK Reader, которая будет описана чуть ниже).
. Следующее ограничение: программа не поддерживает Unicode, поэтому с арабскими и азиатскими языками лично у вас могут быть проблемы. Кстати говоря, если еще в предыдущих версиях были проблемы и с кириллическими шрифтами, то сейчас, в самой последней версии, эти проблемы исчезли: ключи и записи на русском вполне нормально создаются и сортируются. Если же какие-то подобные проблемы и всплывут, просто попробуйте сменить шрифт.
. Этот органайзер не поддерживает внедрение в свои статьи графики или каких-то других объектов, кроме текста. Для обхода этого используйте внешние гиперссылки или возможность вложений.
. Следующее ограничение: в шапке заметки разрешается только одно вложение на одну статью (повторюсь, что вложение - это ссылка на некий внешний объект, как локальный файл, так и произвольный URL, то есть это фактически аналог ссылок). Но тут ничего страшного нет, так как внутри самой статьи (в ее теле) можно расставлять любое количество аналогичных ссылок.
Общий механизм работы
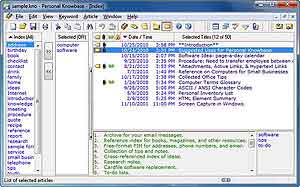
Фактически рабочее поле программы в состоянии «по умолчанию» разбито на три колонки. Левая крайняя колонка содержит линейный список всех ранее введенных тегов-меток; посередине расположена колонка для композиции булевого (логического) запроса, по результату которого динамически будет отсортирована третья, самая широкая, правая крайняя колонка - с линейным списком всех статей. Собственно, сочетая в разных комбинациях в средней колонке теги, а также меняя логический знак операций над тегами (OR, AND, NOT), щелкая для этого по заголовку этой колонки, мы формируем динамическую выборку отвечающих этим критериям статей в правом крайнем поле. Кроме такой теговой выборки также доступны и традиционные сортировки: как по дате статей или их названию, так и по признаку ранее отмеченных статей.
Это - почти все базовые возможности программы. Эффективность работы с ней будет в первую очередь зависеть от вашей способности с помощью тегов точно и емко разметить все ваши материалы, ну и также, конечно, не потонуть в самих тегах, если в процессе этого упорядочивания их список вдруг станет длиннее, чем список из самих хранимых статей. Поэтому тут нужно чувство некоторого баланса и умения, чтобы ловко раскидать все свои заметки по категориям, при этом достаточно метко и емко пометив их тегами (для чего, безусловно, нужна некая собственная система именования, в следовании которой нужно заранее условиться с самим собой), чтобы сохранить к ним быстрый и логичный доступ впоследствии. Кстати, о быстроте доступа…
Понятно, что, как правило, какие-то сложные явления или предметы помечаются и раскладываются на спектр из соответствующих иерархических тегов. Например, одна-единственная статья вполне может быть помечена следующей логической вереницей тегов:
программирование, php, сеть, сокеты, примеры, важно, неразобрано, изинтернета.
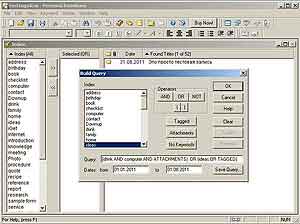
Если у вас есть часто повторяемые нетривиальные запросы (а со временем, по мере того как программа обрастет информацией, они обязательно появятся), порождающие среди таких многомерных теговых описаний какие-то свои сложные выборки, можно запросто сохранить их в специальном редакторе запросов, функциональность которого логически состоит из трех окон: Build Query, Run Saved Query и Manage Saved Queries (все они доступны в меню Edit). По названию понятен смысл каждого окна из этой группы, но мы немного остановимся на первом из них, так как там и сосредоточены все основные возможности редактора запросов. Очень важно сразу заметить, что редактор позволяет создавать расширенные по возможностям запросы, которые превосходят те возможности по выборке, которые присутствуют в главном окне программы в визуальной форме: при группировке тегов и их перетягиванию мышкой. Здесь можно задать и сохранить куда более изощренные запросы к базе заметок, при этом, конечно, сам язык запросов не требует никакого дополнительного изучения (как, например, в случае с SQL), в то же самое время позволяя динамически извлекать массивы отобранных записей согласно ранее заданным жестким и порой весьма изощренным критериям.
Цена выхода из игры
Обычно «плохие органайзеры» сразу можно легко определить по одному критерию: они не уважают святое право – право свободы выбора своих пользователей. Это проявляется, как правило, в том, что программа имеет ОГРОМНОЕ количество форматов для импорта в родной формат органайзера и не имеет вообще или имеет крайне урезанную возможность выгрузить данные из этой базы, чтобы мигрировать в некий другой PIM, тем самым предполагая намертво и до последнего вздоха держать пользователя в своих крепких и потому не всегда приятных объятьях. Безусловно, это слабость, и если эта слабость имеет место быть, это должно настораживать, потому что, как правило, для этого есть все основания (в самой «поделке- органайзере»). Как обстоят дела с этим в Personal Knowbase?
Сначала разберемся с импортом. Тут все выглядит очень пристойно.
Поддерживаются: текстовый формат, формат документов в RTF, нераспространенные у нас Card Files (*.crd), *.tab- и *.csv-файлы, .doc-файлы (при установленном соответствующем плагине), а также реально очень интересная фишка под названием «Менеджер произвольного формата», который позволяет настроить импорт текстового файла с произвольным форматом, позволяя худо-бедно разметить его для загрузки (что позволило мне корректно загрузить свои .xml- и .ini-файлы, правда, потратив на это 3 часа). Также обратите внимание на копку Options в главном диалоге мастера Import, которая позволяет дополнительно более точно настроить импорт, если автоматический вариант вас по какой-либо причине не устроит.
Теперь посмотрим на противоположный мастер - Export, который должен обеспечить пути отхода, если вдруг после, например, года работы на этом органайзере вы обнаружите, что он не очень-то и подходит вам (а такое, к сожалению, сплошь и рядом встречается со многими продуктами в наше время и даже с людьми, их создающими, - статистика разводов в последнее время красноречиво иллюстрирует этот факт). Хитро сощурив глаз, открываем меню Export и видим там поддержку следующего списка форматов: html, txt, crd, rtf, csv. Предварительное окно экспорта заботливо уточнит, что именно и в каком объеме вы хотите выгрузить, позволив вам выбрать из всех полей птичками то, что вы собираетесь унести отсюда с собой навсегда. Что ж, должен признать со всей откровенностью - паритет возможностей импорта и экспорта полностью соблюден, что лично у меня вызывает только симпатии.
И, как всегда, нелишним будет заранее провентилировать нештатные ситуации, когда с основной базой что-то случится. Для бэкапа базы нужно всего лишь скопировать в безопасное место файлы «*.kn*» из вашей рабочей папки программы (обычно там они находятся по умолчанию). А вот для добавления содержимого одной базы в другую (объединения двух баз в единую) нужно просто открыть первую базу (которая будет принимать новое содержимое), а затем через меню File->Import указать другой файл базы (выберите тип файла для отображения *.kno), из которого будут перекачиваться данные. В появившемся при открытии окне с выбором индексов нужно просто нажать OК для переноса всего содержимого (или выбрать только определенные ключи- теги для переноса только помеченных или отобранных записей).
На десерт
В заключение хотелось бы рассмотреть две приятные примочки, которые будут очень кстати, если вы решитесь на покупку этой, все всяких сомнений, очень интересной программы. Во-первых, это бесплатный вьювер (называемый PK Reader) к базе данных, созданной вами в основной программе. Теоретически теперь вы можете переслать любому человеку вашу базу, дав ему ссылку на бесплатный ее вьювер, - и теперь ему доступны абсолютно все возможности программы (в том числе поиск, экспорт и печать данных), кроме возможностей по изменению и любому редактированию базы. Кроме того, этот вьювер изначально сделан в виде портабельного приложения, что позволяет носить свою базу, например, на флэшке или разместить ее на общем сетевом диске вашего предприятия.
Вторая приятная особенность - это наличие плагинной архитектуры и, как пример ее реализации, с сайта производителя можно скачать бесплатный плагин для MS Word, который позволяет прозрачно импортировать содержимое ваших doc-файлов (при установке плагина программа автоматически добавит новый тип доступных файлов в меню File -> Import File Dialog).
Справочная информация о программе:
Personal Knowbase, размер дистрибутива - 4.5Мб
http://www.bitsmithsoft.com/product.htm
shareware, стоимость 50 долларов
Работает на всех версиях Windows
Игорь Савчук Softkey.info
Но прежде чем начать наш первый обзор из серии, давайте немного погрузимся в историко-методологический обзор, тем более что это пойдет на пользу рассматриваемым нами сегодня проблемам и позволит лучше понять принципиальные отличия в существующих подходах к реализации современных PIM (personal information manager). И, как легко видеть, в названии сегодняшней статьи неслучайно фигурирует упоминание о Memex (en.wikipedia.org/wiki/Memex) - мифической программе-устройстве, которая считается прообразом всех современных менеджеров информации. Название Memex, происходящее от слов memory (память) и index (индекс, список), - это концепция идеального запоминающего и категоризирующего устройства, которое могло бы помочь упорядочить всю имеющуюся информацию независимо от ее объема и разнородности, сделав максимально доступной для людей, с ней работающих. Впервые эта система была концептуально описана Ванневаром Бушем (en.wikipedia.org/wiki/Vannevar_Bush) в 1945 году в ставшей известной по тем временам статье «Как мы можем думать».
Фактически речь идет о самом настоящем описании гипертекста: описания взаимных тематических ссылок для плотной семантической связности всех данных. Кроме гиперссылок, там есть много опережающих то время предсказаний-предложений: это компьютерное распознавание речи, создание повсеместно доступных и самоорганизующихся силами самих читателей энциклопедий (сегодняшняя Wikipedia), создание глобальных сетей для всемирного доступа к данным (сегодняшний Интернет). Обширная статья была напечатана в известном журнале Fortune и тут же перепечатана в еще более массовом журнале Life. К сожалению, этот же номер Life рядом со смелыми озарениями ученого содержал горячий фоторепортаж о бомбардировке Хиросимы и Нагасаки - начиналось совсем другое, поствоенное время… Революционные предложения и идеи Ванневара Буша оказались быстро забытыми под натиском новой глобальной эпохи – началом холодной войны между странами НАТО и Варшавского договора.
Memex - король порядка
Прошло много лет, и об идейном наследии Ванневара Буша в наше время вскользь вспоминают лишь в связи с историей практической реализации (а не изобретения, как это часто ошибочно утверждают) гипертекста, впервые реализованного в 90-х годах в проекте WWW сэром Тимом Бернес Ли (en.wikipedia.org/wiki/Tim_Berners-Lee).
И хотя это гораздо менее известно, есть и вторая идейная ветвь в сегодняшнем настоящем, которую дали работы этого ученого-футуриста, - его концепции «симиалитических индексов», которые в наше время стали гораздо более известны под термином «облако смысловых тегов».
В далеком 1945 году Ванневар Буш прозорливо предупреждал, что способы иерархической и линейной организации данных весьма ограничены и не всегда позволяют по-настоящему хорошо упорядочить данные - для этого он разработал теговую концепцию: стандартизированные смысловые метки, которые могут дополнительно помечать уже отсортированный по какой-либо традиционной схеме материал, этим самым радикально повышая качество его агрегации.
Поэтому, посвящая нашу серию обзоров современным настольным средствам управления и упорядочивания информации (PIM), важно знать и учитывать эти различные существующие подходы для выбора максимально эффективного инструмента PIM. Итак, воздав дань памяти идейному первопроходцу многих методов упорядочивания данных, о которых сегодня пойдет речь, давайте перейдем в практическую плоскость рассмотрения органайзеров. И раз уж мы начали с истории, давайте именно ею и закончим наше необходимое историческое вступление.
Как я уже упомянул выше, кроме гипертекста была и вторая ветвь наследия Ванневара Буша - это концепция смысловых тегов. Как ни странно, но впервые она была реализована в виде отдельной законченной программы довольно поздно - в 1998 году, специалистами в то время очень известного и крупного интернет-провайдера CompuServe, и называлась эта программа Personal Knowbase. Способ хранения и упорядочивания всех данных здесь впервые в истории был полностью построен на индексном (теговом) принципе. Но этой реализации идей Буша снова не повезло: крупнейший американский интернет-провайдер в 80-х, увлекшись изобретением «своего собственного, особого Интернета», не выдержал конкуренции со стороны традиционных провайдеров и открытых стандартов и был по большей части «съеден» и благополучно «прожеван» компанией AOL, перестав существовать в своем старом виде в конце 90-х.
Идея теговых органайзеров оказалась снова заброшенной. Но на этот раз бывшие разработчики CompuServe, к счастью, смогли самостоятельно самоорганизоваться, чтобы создать свою собственную, отдельную компанию Bitsmith Software, в которой вскоре и возобновили разработку этой замечательной программы. После чего вполне благополучно в середине 2000 года выпустили уже вторую ее версию - уже под флагом новой независимой фирмы.
Personal Knowbase: деревья vs. ключевые слова
Приступая к знакомству с Personal Knowbase (www.bitsmithsoft.com), нужно сразу признать: эта программа вряд ли поразит вас своими графическими наворотами, большим количеством форм или окон с настройками. Программа представляет собой в чистом виде концепт, хотя и реализованный в виде полностью рабочей и практически пригодной для повседневных нужд программы-органайзера. Но в силу новизны и некоторой своей необычности она потребует какого-то начального навыка работы с ней, который все же, нужно признать, совсем не сложен, и после этой вводной статьи, я уверен, будет в полной мере уже сформирован. Остается лишь заметить, что мы приступаем к рассмотрению текущей версии - v3.2.2.
Основные возможности и ограничения
. реализация простейшей булевой логики для ключевых слов;
. реализация как обычных гиперссылок, так и ссылок на внешние файлы и заметки внутри самой базы;
. возможность вкладывать вложения, которые могут быть как в виде внешних файлов, так и файлов, выложенных на некотором интернет-ресурсе; . возможность двухуровневой защиты всей информации паролем;
. возможность экспортировать хранимую информацию во внешние источники в различные форматы;
. возможность импорта информации из внешних источников также через различные форматы;
. реализация традиционных сортировок, а также полнотекстового поиска (я проверил - полностью рабочий и с русским языком), возможность метить отдельные записи значком;
. очень подробная качественная справочная информация.
Как учат на вузовских лекциях физики, наиболее ярко физические модели (и их свойства) проявляются в их предельных состояниях. Поэтому давайте попробуем посмотреть на Personal Knowbase через призму граничных условий. Итак, в дополнение перечислим эти самые предельные возможности программы в форме вопроса и ответа.
. Какое количество тегов можно использовать при описании своих записей? Разработчики говорят, что неограниченное. И добавляют: мы тестировали работу программы при 10.000 тегов в базе - никаких проблем при этом в работе программы не обнаружили.
. Какие размеры максимальной статьи в базе? Ответ: 16 Мб. При этом очень советуют не использовать такие большие статьи в работе с Personal Knowbase, так как откровенно признаются, что программа будет очень сильно тормозить.
. Третий очень важный вопрос из этой серии: каков потолок по количеству статей в базе? Ответ разработчиков: теоретических ограничений внутри самой Personal Knowbase нет. При этом они делают вынужденное дополнение: учитывая ограничения на размер одного файла в файловой системе Windows (2 Гб), этот барьер преодолеть не удастся. Впрочем, что можно добавить по этому поводу от себя, так это то, что вряд ли вы захотите использовать эту мини-базу, если количество записей в ней будет превышать, скажем, 200.000 записей, так как для эффективной ориентации в такой действительно огромной базе данных одной концепции тегов будет, пожалуй, маловато.
. Следующее ограничение для использования программы в локальной сети: да, саму базу можно выложить на сетевой диск для использования ее другими, но при этом только один пользователь может одновременно работать с такой базой (для многопользовательского безопасного просмотра лучше использовать версию PK Reader, которая будет описана чуть ниже).
. Следующее ограничение: программа не поддерживает Unicode, поэтому с арабскими и азиатскими языками лично у вас могут быть проблемы. Кстати говоря, если еще в предыдущих версиях были проблемы и с кириллическими шрифтами, то сейчас, в самой последней версии, эти проблемы исчезли: ключи и записи на русском вполне нормально создаются и сортируются. Если же какие-то подобные проблемы и всплывут, просто попробуйте сменить шрифт.
. Этот органайзер не поддерживает внедрение в свои статьи графики или каких-то других объектов, кроме текста. Для обхода этого используйте внешние гиперссылки или возможность вложений.
. Следующее ограничение: в шапке заметки разрешается только одно вложение на одну статью (повторюсь, что вложение - это ссылка на некий внешний объект, как локальный файл, так и произвольный URL, то есть это фактически аналог ссылок). Но тут ничего страшного нет, так как внутри самой статьи (в ее теле) можно расставлять любое количество аналогичных ссылок.
Общий механизм работы
Фактически рабочее поле программы в состоянии «по умолчанию» разбито на три колонки. Левая крайняя колонка содержит линейный список всех ранее введенных тегов-меток; посередине расположена колонка для композиции булевого (логического) запроса, по результату которого динамически будет отсортирована третья, самая широкая, правая крайняя колонка - с линейным списком всех статей. Собственно, сочетая в разных комбинациях в средней колонке теги, а также меняя логический знак операций над тегами (OR, AND, NOT), щелкая для этого по заголовку этой колонки, мы формируем динамическую выборку отвечающих этим критериям статей в правом крайнем поле. Кроме такой теговой выборки также доступны и традиционные сортировки: как по дате статей или их названию, так и по признаку ранее отмеченных статей.
Это - почти все базовые возможности программы. Эффективность работы с ней будет в первую очередь зависеть от вашей способности с помощью тегов точно и емко разметить все ваши материалы, ну и также, конечно, не потонуть в самих тегах, если в процессе этого упорядочивания их список вдруг станет длиннее, чем список из самих хранимых статей. Поэтому тут нужно чувство некоторого баланса и умения, чтобы ловко раскидать все свои заметки по категориям, при этом достаточно метко и емко пометив их тегами (для чего, безусловно, нужна некая собственная система именования, в следовании которой нужно заранее условиться с самим собой), чтобы сохранить к ним быстрый и логичный доступ впоследствии. Кстати, о быстроте доступа…
Понятно, что, как правило, какие-то сложные явления или предметы помечаются и раскладываются на спектр из соответствующих иерархических тегов. Например, одна-единственная статья вполне может быть помечена следующей логической вереницей тегов:
программирование, php, сеть, сокеты, примеры, важно, неразобрано, изинтернета.
Если у вас есть часто повторяемые нетривиальные запросы (а со временем, по мере того как программа обрастет информацией, они обязательно появятся), порождающие среди таких многомерных теговых описаний какие-то свои сложные выборки, можно запросто сохранить их в специальном редакторе запросов, функциональность которого логически состоит из трех окон: Build Query, Run Saved Query и Manage Saved Queries (все они доступны в меню Edit). По названию понятен смысл каждого окна из этой группы, но мы немного остановимся на первом из них, так как там и сосредоточены все основные возможности редактора запросов. Очень важно сразу заметить, что редактор позволяет создавать расширенные по возможностям запросы, которые превосходят те возможности по выборке, которые присутствуют в главном окне программы в визуальной форме: при группировке тегов и их перетягиванию мышкой. Здесь можно задать и сохранить куда более изощренные запросы к базе заметок, при этом, конечно, сам язык запросов не требует никакого дополнительного изучения (как, например, в случае с SQL), в то же самое время позволяя динамически извлекать массивы отобранных записей согласно ранее заданным жестким и порой весьма изощренным критериям.
Цена выхода из игры
Обычно «плохие органайзеры» сразу можно легко определить по одному критерию: они не уважают святое право – право свободы выбора своих пользователей. Это проявляется, как правило, в том, что программа имеет ОГРОМНОЕ количество форматов для импорта в родной формат органайзера и не имеет вообще или имеет крайне урезанную возможность выгрузить данные из этой базы, чтобы мигрировать в некий другой PIM, тем самым предполагая намертво и до последнего вздоха держать пользователя в своих крепких и потому не всегда приятных объятьях. Безусловно, это слабость, и если эта слабость имеет место быть, это должно настораживать, потому что, как правило, для этого есть все основания (в самой «поделке- органайзере»). Как обстоят дела с этим в Personal Knowbase?
Сначала разберемся с импортом. Тут все выглядит очень пристойно.
Поддерживаются: текстовый формат, формат документов в RTF, нераспространенные у нас Card Files (*.crd), *.tab- и *.csv-файлы, .doc-файлы (при установленном соответствующем плагине), а также реально очень интересная фишка под названием «Менеджер произвольного формата», который позволяет настроить импорт текстового файла с произвольным форматом, позволяя худо-бедно разметить его для загрузки (что позволило мне корректно загрузить свои .xml- и .ini-файлы, правда, потратив на это 3 часа). Также обратите внимание на копку Options в главном диалоге мастера Import, которая позволяет дополнительно более точно настроить импорт, если автоматический вариант вас по какой-либо причине не устроит.
Теперь посмотрим на противоположный мастер - Export, который должен обеспечить пути отхода, если вдруг после, например, года работы на этом органайзере вы обнаружите, что он не очень-то и подходит вам (а такое, к сожалению, сплошь и рядом встречается со многими продуктами в наше время и даже с людьми, их создающими, - статистика разводов в последнее время красноречиво иллюстрирует этот факт). Хитро сощурив глаз, открываем меню Export и видим там поддержку следующего списка форматов: html, txt, crd, rtf, csv. Предварительное окно экспорта заботливо уточнит, что именно и в каком объеме вы хотите выгрузить, позволив вам выбрать из всех полей птичками то, что вы собираетесь унести отсюда с собой навсегда. Что ж, должен признать со всей откровенностью - паритет возможностей импорта и экспорта полностью соблюден, что лично у меня вызывает только симпатии.
И, как всегда, нелишним будет заранее провентилировать нештатные ситуации, когда с основной базой что-то случится. Для бэкапа базы нужно всего лишь скопировать в безопасное место файлы «*.kn*» из вашей рабочей папки программы (обычно там они находятся по умолчанию). А вот для добавления содержимого одной базы в другую (объединения двух баз в единую) нужно просто открыть первую базу (которая будет принимать новое содержимое), а затем через меню File->Import указать другой файл базы (выберите тип файла для отображения *.kno), из которого будут перекачиваться данные. В появившемся при открытии окне с выбором индексов нужно просто нажать OК для переноса всего содержимого (или выбрать только определенные ключи- теги для переноса только помеченных или отобранных записей).
На десерт
В заключение хотелось бы рассмотреть две приятные примочки, которые будут очень кстати, если вы решитесь на покупку этой, все всяких сомнений, очень интересной программы. Во-первых, это бесплатный вьювер (называемый PK Reader) к базе данных, созданной вами в основной программе. Теоретически теперь вы можете переслать любому человеку вашу базу, дав ему ссылку на бесплатный ее вьювер, - и теперь ему доступны абсолютно все возможности программы (в том числе поиск, экспорт и печать данных), кроме возможностей по изменению и любому редактированию базы. Кроме того, этот вьювер изначально сделан в виде портабельного приложения, что позволяет носить свою базу, например, на флэшке или разместить ее на общем сетевом диске вашего предприятия.
Вторая приятная особенность - это наличие плагинной архитектуры и, как пример ее реализации, с сайта производителя можно скачать бесплатный плагин для MS Word, который позволяет прозрачно импортировать содержимое ваших doc-файлов (при установке плагина программа автоматически добавит новый тип доступных файлов в меню File -> Import File Dialog).
Справочная информация о программе:
Personal Knowbase, размер дистрибутива - 4.5Мб
http://www.bitsmithsoft.com/product.htm
shareware, стоимость 50 долларов
Работает на всех версиях Windows
Игорь Савчук Softkey.info
Компьютерная газета. Статья была опубликована в номере 36 за 2011 год в рубрике soft
