
Сложные интерфейсы на javascript вместе c Yahoo UI. Часть 20
Эта статья завершит рассказ о компоненте TreeView. С его помощью мы можем отображать на веб-странице иерархическую информацию в форме дерева. Для простеньких сайтов мы вполне можем обойтись загрузкой информации из статического источника данных, т.е. данные встроены в саму веб-страницу. А вот для серьезных приложений, работающих с большими объемами информации, такая методика не подойдет: данные должны загружаться динамически, по мере необходимости – и это тема сегодняшней статьи.
Методики создания такого дерева TreeView, которое бы загружало информацию по мере необходимости, а не всю сразу, не особенно отличаются для разных языков или платформ. К примеру, всем нам знакомый windows explorer (не браузер). Хотя отображение структуры файловой системы в форме дерева очень удобно, но если бы нужная для него информация загружалась бы сразу и вся, то время запуска explorer-а было бы огромным. Ведь нужно просканировать все диски и все папки на них, найти для каждой папки все файлы (а это сотни и сотни тысяч объектов). Для веб-приложений нужно не только заботиться о минимизации нагрузки на сервер (ведь производительности всегда не хватает, особенно на "дешевых" virtual-ных хостингах), но еще нужно думать и об объеме трафика передаваемого по сети. С другой стороны видеть панацею в методике "грузим информацию по требованию" не стоит. Бич многих новичков, познакомившихся с идеями ajax в том, что они учитывают фактор накладных расходов на обслуживание каждого асинхронного запроса. К примеру, если вы разворачиваете узел дерева, тут же отправляя запрос на сервер за списком дочерних узлов к нему. То вот вопрос: будет ли это правильным, если количество возвращаемых узлов невелико, скажем 3-5 штук? Ведь каждый запрос на сервер требует время (пусть и незначительное) на установление подключения, на передачу данных, их кодирование и декодирование, не забывайте еще и о затратах времени на, собственно, обработку запроса и формирование ответа (те самые 3-5 узлов). Идеальным вариантом было бы совместить статическое и динамическое наполнение дерева информацией. Когда условная функция "getChildNodes (узел)" (вызываемая динамически с помощью ajax) возвращает не только список узлов, непосредственно вложенных внутрь узла, "по которому click-нул пользователь и хочет его раскрыть". Но также, если какой-то из дочерних узлов содержит небольшое количество подчиненных узлов, то и их перечень можно было вы вернуть заранее, не дожидаясь еще одного клика пользователя по дереву. В следующем примере я покажу, как создать TreeView, отображающий информацию из файловой системы. Первым уровнем вложенности будет перечень дисков; для простоты соответствующий набор узлов можно создать вручную, например, так:
tree = new YAHOO.widget.TreeView("treeplaceholder");
tree.setDynamicLoad(loadNodeData, 1);
var drive_d = new YAHOO.widget.TextNode("D:/", tree.getRoot());
var drive_e = new YAHOO.widget.TextNode("E:/", tree.getRoot());
drive_d.isLeaf = false;
drive_e.isLeaf = false;
tree.render ();
Первым шагом сразу после того как был создан объект TreeView, мне нужно установить правила, по которым будет выполняться загрузка содержимого узлов дерева. Вызвав функцию setDynamicLoad, я говорю, что теперь все узлы дерева будут подгружаться по мере того, как пользователь будет пытаться их разворачивать. А отвечать за это будет функция loadNodeData (ее я опишу чуть позже). Создав дерево, нужно наполнить его информацией: список узлов, соответствующих дискам компьютера – это переменные drive_d, drive_e. Напоминаю, что второй параметр конструктора класса TextNode "tree.getRoot()" – это ссылка на родительский узел всего дерева, т.е. узлы-диски будут на высшем уровне. Поскольку с вероятностью 99% на каждом из дисков компьютера есть хоть какие-то файлы или папки, то я хочу, чтобы изначально, при первом открытии страницы, узлы-диски имели бы расположенные рядом с ними иконки-пиктограммы, подсказывающие, что узел можно раскрыть. Чтобы включить такое поведение узла, нужно установить для него значение конфигурационной переменной isLeaf. Теперь перейдем к рассмотрению функции, загружающей для узла дерева его содержимое:
function loadNodeData (node, onLoadCompleteHandler){
var n = node;
var path2open = '';
while (n.parent){
path2open = n.label + '/' + path2open
n = n.parent; }
var callback = {
success: function(oResponse) {
var json = YAHOO.lang.JSON.parse (oResponse.responseText);
for (var i = 0; i < json.length; i++){
var fnode = new YAHOO.widget.TextNode(json[i].file, node);
fnode.isLeaf = json[i].type == 'file' || json[i].children == 0; }
onLoadCompleteHandler();
},
failure: function(oResponse) {
alert (oResponse.responseText);
onLoadCompleteHandler(); }
/*
argument: {
"node": node,
"onLoadCompleteHandler": onLoadCompleteHandler
} */
};
YAHOO.util.Connect.asyncRequest('POST', 'loadtree.php', callback, "path2open="+ path2open ); }
Входные параметры для loadNodeData говорят сами за себя. Первый из них – node – это ссылка на узел, который начинает разворачивать пользователь и для которого нужно загрузить содержимое. Т.к. загрузка полностью возложена на нас (мы можем даже не загружать список дочерних узлов с сервера, а, например, сгенерировать их по какому-то хитрому закону), то нужен какой-то механизм, чтобы сообщить YUI о том, что все данные были загружены и помещены внутрь дерева. Если мы используем загрузку данных с помощью ajax, то момент "данные готовы" отдален во времени от того момента, когда мы начали разворачивание узла. На все это время YUI поменяет внешний вид TreeView: напротив разворачиваемого узла появится анимированная картинка, подсказывающая клиенту, что, мол, нужно подождать, пока данные не будут загружены. А мы, как только процедура загрузки данных будет завершена (и не важно, удачно или нет), должны сигнализировать об этом YUI, вызвав функцию onLoadCompleteHandler.
Теперь идем дальше: к отправке запроса на сервер. Для этого нужно вычислить полный путь к каталогу, который хочет открыть пользователь. Подчеркиваю, полный путь к каталогу. А у нас надпись узла содержит вовсе не полный путь к каталогу, а только его кусочек. Следовательно, мне нужно "подняться" от текущего узла до самого верха дерева и "склеить" надписи всех узлов в единую строку, что я и сделал внутри цикла while. Для отправки асинхронного запроса на сервер необходимо подготовить для YUI специальный объект callback. Внутри которого хранятся ссылки на две функции: первая из них (success) будет вызвана в случае, если никаких ошибок в ходе выполнения запроса не произойдет, а вторая (failure) – если какой-то сбой все же произошел. В любом случае, обе эти функции получают на вход единственный параметр oResponse, хранящий сведения о результате выполнения запроса: так, переменная responseText содержит текст ответа сервера. Если произошел сбой, то я просто вывожу на экран alert-ом текст ответа сервера и обязательно вызываю функцию onLoadCompleteHandler: ведь нужно обозначить тот факт, что запрос к серверу хоть как-то, но завершился. Если же ошибок нет, то внутри функции success я преобразую строки ответа сервера в массив записей JSON.
Каждая запись хранит сведения о файле или каталоге: свойство file хранит имя файла, свойство type принимает одно из двух значений (file или dir), обозначая тип текущего узла. А переменная children хранит число файлов или подкаталогов, находящихся внутри текущего узла. На основании этих данных я создаю новый узел дерева. Обратите внимание на второй параметр конструктора класса TextNode. Как я уже отмечал, он должен быть равен ссылке на тот узел дерева, к которому будет добавлено новый дочерний узел. Есть две стратегии того, как из функции обработчика асинхронного события "пришли данные для узла" узнать то, к какому узлу относятся эти данные (хм… звучит довольно громоздко). В простейшем случае (как было это показано в примере) я смело обращаюсь к переменной node, поскольку знаю, что она сохранила свое значение благодаря "замыканию". В том случае, если функция обработчик события "пришли данные" представлена не в виде анонимной функции (а обычной функции, определенной в области видимости, например, window), то можно поместить внутрь объекта callback еще одно свойство argument (в примере закомментировано). Тогда для обращения к "списку аргументов" используем запись "oResponse.argument.переменная". Последнее, на что я обращу ваше внимание перед переходом к рассмотрению php-скрипта, формирующего данные, – это назначение свойства isLeaf для каждого из новых узлов. Дело в том, что я хочу, чтобы иконки со значком плюса (узел можно раскрыть) были поставлены в соответствие только тем узлам, которые являются каталогами и внутри которых есть хотя бы один дочерний файл или подкаталог.
Устройство php-скрипта, формирующего массив файлов внутри каталога, тривиально:
$path2open = iconv("UTF-8", "WINDOWS-1251", $_REQUEST['path2open']);
function scan ($path2open, $level = 0){
$dh = opendir ($path2open);
$final = array ();
while (($file = readdir($dh)) !== false){
if ($file == '..' || $file == '.') continue;
$fullname = $path2open . '/' . $file;
$type = is_dir ($fullname)?'dir':'file';
$children = 0;
if ($type == 'dir' && $level == 0)
$children = count(scan ($fullname, 1)) > 0;
$final [] = array ('file' => iconv("WINDOWS-1251", "UTF-8", $file), 'type' => $type, 'children' => $children );
}
closedir ($dh);
return $final;
}
print json_encode (scan ($path2open, 0) )
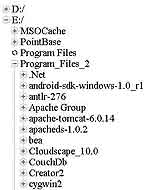 Первым шагом я прочитал из параметров запроса путь к каталогу, который нужно просканировать. Потом преобразовал его кодировку из UTF-8 в windows- 1251 (т.к. php для windows xp требует указания путей к файлам и каталогам на диске именно в этой кодировке). Затем я создал функцию scan, которая получает в качестве параметра путь к каталогу, который нужно просканировать, и возвращает массив записей. Каждая запись соответствует отдельному файлу или подкаталогу и хранит его имя, тип, а также для каталогов признак того, есть ли внутри него дочерние объекты. Алгоритм сканирования каталога, честно скажу, не идеален, поэтому в качестве тренировки попробуйте переписать функцию scan так, чтобы значительно ускорить ее работу. Последнее, на что обращу ваше внимание: необходимо все данные, поступающие на вход функции кодирования в json перед отправкой клиенту, обязательно перекодировать из windows-1251 кодировки в utf-8 (функция iconv). То, что у меня получилось, показано на рис. 1. На этой картинке я поймал момент обработки запроса и то, как выглядит узел дерева в промежутке между отправкой запроса и приходом ответа (иконка анимации).
Первым шагом я прочитал из параметров запроса путь к каталогу, который нужно просканировать. Потом преобразовал его кодировку из UTF-8 в windows- 1251 (т.к. php для windows xp требует указания путей к файлам и каталогам на диске именно в этой кодировке). Затем я создал функцию scan, которая получает в качестве параметра путь к каталогу, который нужно просканировать, и возвращает массив записей. Каждая запись соответствует отдельному файлу или подкаталогу и хранит его имя, тип, а также для каталогов признак того, есть ли внутри него дочерние объекты. Алгоритм сканирования каталога, честно скажу, не идеален, поэтому в качестве тренировки попробуйте переписать функцию scan так, чтобы значительно ускорить ее работу. Последнее, на что обращу ваше внимание: необходимо все данные, поступающие на вход функции кодирования в json перед отправкой клиенту, обязательно перекодировать из windows-1251 кодировки в utf-8 (функция iconv). То, что у меня получилось, показано на рис. 1. На этой картинке я поймал момент обработки запроса и то, как выглядит узел дерева в промежутке между отправкой запроса и приходом ответа (иконка анимации).
Следующим шагом улучшения примера будет настройка индивидуального внешнего вида для каждого из узлов. Так, узлы, соответствующие каталогам, должны иметь картинки-иконки в виде папок. А узлы, соответствующие файлам, получат пиктограммы, соответствующие типу файла (т.е. файлы word, excel и архивы будут иметь различный внешний вид). Первая часть задания (с картинками каталогов) решается на счет раз-два: YUI компоненты поддерживают скины, и в составе YUI есть уже подготовленный css-файл assets/css/folders/tree.css (он идет вместе с одним из примеров TreeView). Сначала я скопировал всю папку assets с css-стилями и файлами картинок в папку с примером. Затем для удобства я переопределил все css-правила в css-файле следующим образом: было .ygtvloading и стало .folder .ygtvloading. Хотя YUI имеет стандартизированную методику создания css-скинов и их загрузки с помощью YUI-loader, но в большинстве случаев, когда необходимо на одной странице разместить несколько одинаковых компонентов (те же два TreeView), но при этом имеющие различное оформление, то лучше подправить файлы css-стилей. Например, добавив для всех стилей, используемых для оформления компонента TreeView, префикс (в моем примере .folder). Это даст нам возможность избирательно применять css-скины для различных компонентов, просто создав на html-странице блок div с css-классом folder, и разместив внутри которого TreeView:
// подключаем стили
<link rel="stylesheet" type="text/css" href="assets/css/folders/tree.css">
<div class="folder"> <!—применяем их -->
<div id="treeplaceholder"></div>
</div>
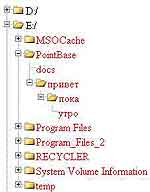 То, что у меня получилось, показано на рис. 2. Хотя TreeView смотрится гораздо лучше, но есть еще куда стремиться. Первое улучшение связано с тем, что в YUI TreeView нет такого стандартного css-стиля, который назначался бы в иконке узла, являющегося каталогом, но при этом не содержащего внутри себя других узлов (хотя это обычная ситуация для файловой системы, когда каталог пустой). К счастью, в YUI предусмотрены инструменты, позволяющие настроить внешний вид для каждого из узлов дерева индивидуально. Для этого нужно сразу после создания узла дерева назначить ему свойство labelStyle и contentStyle (к сожалению, contentStyle может быть применен к узлам типа HtmlNode). Так, вернувшись к старому примеру, я немного поменял код создания узлов дерева. Теперь, если узел соответствует каталогу, но внутри него нет дочерних файлов и подкаталогов, то узел получает специальный css-стиль:
То, что у меня получилось, показано на рис. 2. Хотя TreeView смотрится гораздо лучше, но есть еще куда стремиться. Первое улучшение связано с тем, что в YUI TreeView нет такого стандартного css-стиля, который назначался бы в иконке узла, являющегося каталогом, но при этом не содержащего внутри себя других узлов (хотя это обычная ситуация для файловой системы, когда каталог пустой). К счастью, в YUI предусмотрены инструменты, позволяющие настроить внешний вид для каждого из узлов дерева индивидуально. Для этого нужно сразу после создания узла дерева назначить ему свойство labelStyle и contentStyle (к сожалению, contentStyle может быть применен к узлам типа HtmlNode). Так, вернувшись к старому примеру, я немного поменял код создания узлов дерева. Теперь, если узел соответствует каталогу, но внутри него нет дочерних файлов и подкаталогов, то узел получает специальный css-стиль:
if (json[i].type == 'dir' && json[i].children == 0)
fnode.contentStyle = 'folder_leaf';
 Определение стиля folder_leaf примитивное до невозможности: я подготовил небольшую картинку-пиктограмму, изображающую папку каталога в закрытом виде и без расположенного слева маркера "эту папку можно раскрыть". Также я подправил стиль .ygtvlabel (это стиль текстовой надписи, расположенной рядом с картинкой узла) так, чтобы был больший отступ между именем каталога и его изображением (то, что получилось, показано на рис. 3).
Определение стиля folder_leaf примитивное до невозможности: я подготовил небольшую картинку-пиктограмму, изображающую папку каталога в закрытом виде и без расположенного слева маркера "эту папку можно раскрыть". Также я подправил стиль .ygtvlabel (это стиль текстовой надписи, расположенной рядом с картинкой узла) так, чтобы был больший отступ между именем каталога и его изображением (то, что получилось, показано на рис. 3).
.folder_leaf { background:transparent url(img/folder_leaf.png) no-repeat; }
.folder_leaf .ygtvlabel { margin-left: 20px !important; }
Как небольшое задание попробуйте сами модифицировать код javascript раннего примера так, чтобы он анализировал расширение файла и назначал бы такому узлу индивидуальную иконку (css-стиль). Я настоятельно рекомендую обратиться к примерам, идущим вместе с YUI, так как там вы найдете не только очень ну очень похожий пример, но и рассмотрите еще одну полезную методику: css-sprites. В Интернете есть множество статей, рассказывающих об идеях, положенных в основу css-sprites, но вкратце можно сказать, что с ее помощью мы можем уменьшить время загрузки страницы (точнее, ее графических ресурсов). В прошлой статье, начиная рассказ об TreeeView, я перечислил доступные типы узлов: TextNode, HtmlNode, MenuNode. Также я сказал, что мы можем создавать собственные типы узлов, в случаях, когда мы хотим не только создать новый внешний вид узла (ведь здесь можно было бы обойтись, например, HtmlNode), но хотим еще и создать правила, по которым узел реагирует на действия пользователя. Еще раз я советую открыть официальную документацию по YUI, и среди множества примеров вы найдете демонстрацию дерева, каждый из узлов которого представлен в виде checkbox. Этот checkbox может находиться в трех состояниях в зависимости от того, в каких состояниях находятся дочерние по отношению к нему узлы. Так, узел может быть отмечен или включен, если и он, и все дочерние узлы отмечены. Если ни один из дочерних узлов не отмечен, то родительский узел принимает второе состояние – не отмечен. И третье состояние соответствует ситуации, когда часть дочерних узлов отмечена и часть — нет.
Подводя некоторые итоги и завершая рассказ об YUI, я хотел бы обратить ваше внимание на одну из самых полезных методик по созданию веб- интерфейсов – это создание собственных надстроек над стандартными классами. Дело в том, что даже если мы не создаем классы, расширяющие возможности стандартных компонентов YUI, то все равно объем кода, занимающегося конфигурированием компонентов, очень велик. Этот код включает в себя и настройку внешнего вида, и функции обработчика различных событий. Объединив все это вместе, мы представляем страницу не в виде: компонент DataTable, настроенный для отображения списка товаров, плюс еще один DataTable, настроенный для … Вместо этого мы создадим js-файл, назовем его goods.js, внутри этого файла создадим собственный класс GoodsTable производный от DataTable. Конструктор такого класса будет принимать в качестве параметра уже не информацию о колонках, их render-ах, ширине и заголовках, а более общие параметры: html элемент страницы, внутрь которого нужно поместить DataTable, путь к php-скрипту, поставляющему данные. Так как компоненты на странице должны взаимодействовать, то мы создадим собственную систему обмена сообщениями, не тривиальными, вроде "была выделена строка", а высокоуровневыми или бизнес-событиями. Например, были внесены изменения в запись или была завершена загрузка информации для очередной страницы DataTable. Таким образом, мы создадим self-contained модули или строительные блоки, из которых можно собрать веб-интерфейс. Эти блоки можно будет тестировать и разрабатывать независимо друг от друга, распределять эту работу между несколькими членами команды и, самое важное, повторно использовать в нескольких проектах.
black-zorro@tut.by black-zorro.com
Методики создания такого дерева TreeView, которое бы загружало информацию по мере необходимости, а не всю сразу, не особенно отличаются для разных языков или платформ. К примеру, всем нам знакомый windows explorer (не браузер). Хотя отображение структуры файловой системы в форме дерева очень удобно, но если бы нужная для него информация загружалась бы сразу и вся, то время запуска explorer-а было бы огромным. Ведь нужно просканировать все диски и все папки на них, найти для каждой папки все файлы (а это сотни и сотни тысяч объектов). Для веб-приложений нужно не только заботиться о минимизации нагрузки на сервер (ведь производительности всегда не хватает, особенно на "дешевых" virtual-ных хостингах), но еще нужно думать и об объеме трафика передаваемого по сети. С другой стороны видеть панацею в методике "грузим информацию по требованию" не стоит. Бич многих новичков, познакомившихся с идеями ajax в том, что они учитывают фактор накладных расходов на обслуживание каждого асинхронного запроса. К примеру, если вы разворачиваете узел дерева, тут же отправляя запрос на сервер за списком дочерних узлов к нему. То вот вопрос: будет ли это правильным, если количество возвращаемых узлов невелико, скажем 3-5 штук? Ведь каждый запрос на сервер требует время (пусть и незначительное) на установление подключения, на передачу данных, их кодирование и декодирование, не забывайте еще и о затратах времени на, собственно, обработку запроса и формирование ответа (те самые 3-5 узлов). Идеальным вариантом было бы совместить статическое и динамическое наполнение дерева информацией. Когда условная функция "getChildNodes (узел)" (вызываемая динамически с помощью ajax) возвращает не только список узлов, непосредственно вложенных внутрь узла, "по которому click-нул пользователь и хочет его раскрыть". Но также, если какой-то из дочерних узлов содержит небольшое количество подчиненных узлов, то и их перечень можно было вы вернуть заранее, не дожидаясь еще одного клика пользователя по дереву. В следующем примере я покажу, как создать TreeView, отображающий информацию из файловой системы. Первым уровнем вложенности будет перечень дисков; для простоты соответствующий набор узлов можно создать вручную, например, так:
tree = new YAHOO.widget.TreeView("treeplaceholder");
tree.setDynamicLoad(loadNodeData, 1);
var drive_d = new YAHOO.widget.TextNode("D:/", tree.getRoot());
var drive_e = new YAHOO.widget.TextNode("E:/", tree.getRoot());
drive_d.isLeaf = false;
drive_e.isLeaf = false;
tree.render ();
Первым шагом сразу после того как был создан объект TreeView, мне нужно установить правила, по которым будет выполняться загрузка содержимого узлов дерева. Вызвав функцию setDynamicLoad, я говорю, что теперь все узлы дерева будут подгружаться по мере того, как пользователь будет пытаться их разворачивать. А отвечать за это будет функция loadNodeData (ее я опишу чуть позже). Создав дерево, нужно наполнить его информацией: список узлов, соответствующих дискам компьютера – это переменные drive_d, drive_e. Напоминаю, что второй параметр конструктора класса TextNode "tree.getRoot()" – это ссылка на родительский узел всего дерева, т.е. узлы-диски будут на высшем уровне. Поскольку с вероятностью 99% на каждом из дисков компьютера есть хоть какие-то файлы или папки, то я хочу, чтобы изначально, при первом открытии страницы, узлы-диски имели бы расположенные рядом с ними иконки-пиктограммы, подсказывающие, что узел можно раскрыть. Чтобы включить такое поведение узла, нужно установить для него значение конфигурационной переменной isLeaf. Теперь перейдем к рассмотрению функции, загружающей для узла дерева его содержимое:
function loadNodeData (node, onLoadCompleteHandler){
var n = node;
var path2open = '';
while (n.parent){
path2open = n.label + '/' + path2open
n = n.parent; }
var callback = {
success: function(oResponse) {
var json = YAHOO.lang.JSON.parse (oResponse.responseText);
for (var i = 0; i < json.length; i++){
var fnode = new YAHOO.widget.TextNode(json[i].file, node);
fnode.isLeaf = json[i].type == 'file' || json[i].children == 0; }
onLoadCompleteHandler();
},
failure: function(oResponse) {
alert (oResponse.responseText);
onLoadCompleteHandler(); }
/*
argument: {
"node": node,
"onLoadCompleteHandler": onLoadCompleteHandler
} */
};
YAHOO.util.Connect.asyncRequest('POST', 'loadtree.php', callback, "path2open="+ path2open ); }
Входные параметры для loadNodeData говорят сами за себя. Первый из них – node – это ссылка на узел, который начинает разворачивать пользователь и для которого нужно загрузить содержимое. Т.к. загрузка полностью возложена на нас (мы можем даже не загружать список дочерних узлов с сервера, а, например, сгенерировать их по какому-то хитрому закону), то нужен какой-то механизм, чтобы сообщить YUI о том, что все данные были загружены и помещены внутрь дерева. Если мы используем загрузку данных с помощью ajax, то момент "данные готовы" отдален во времени от того момента, когда мы начали разворачивание узла. На все это время YUI поменяет внешний вид TreeView: напротив разворачиваемого узла появится анимированная картинка, подсказывающая клиенту, что, мол, нужно подождать, пока данные не будут загружены. А мы, как только процедура загрузки данных будет завершена (и не важно, удачно или нет), должны сигнализировать об этом YUI, вызвав функцию onLoadCompleteHandler.
Теперь идем дальше: к отправке запроса на сервер. Для этого нужно вычислить полный путь к каталогу, который хочет открыть пользователь. Подчеркиваю, полный путь к каталогу. А у нас надпись узла содержит вовсе не полный путь к каталогу, а только его кусочек. Следовательно, мне нужно "подняться" от текущего узла до самого верха дерева и "склеить" надписи всех узлов в единую строку, что я и сделал внутри цикла while. Для отправки асинхронного запроса на сервер необходимо подготовить для YUI специальный объект callback. Внутри которого хранятся ссылки на две функции: первая из них (success) будет вызвана в случае, если никаких ошибок в ходе выполнения запроса не произойдет, а вторая (failure) – если какой-то сбой все же произошел. В любом случае, обе эти функции получают на вход единственный параметр oResponse, хранящий сведения о результате выполнения запроса: так, переменная responseText содержит текст ответа сервера. Если произошел сбой, то я просто вывожу на экран alert-ом текст ответа сервера и обязательно вызываю функцию onLoadCompleteHandler: ведь нужно обозначить тот факт, что запрос к серверу хоть как-то, но завершился. Если же ошибок нет, то внутри функции success я преобразую строки ответа сервера в массив записей JSON.
Каждая запись хранит сведения о файле или каталоге: свойство file хранит имя файла, свойство type принимает одно из двух значений (file или dir), обозначая тип текущего узла. А переменная children хранит число файлов или подкаталогов, находящихся внутри текущего узла. На основании этих данных я создаю новый узел дерева. Обратите внимание на второй параметр конструктора класса TextNode. Как я уже отмечал, он должен быть равен ссылке на тот узел дерева, к которому будет добавлено новый дочерний узел. Есть две стратегии того, как из функции обработчика асинхронного события "пришли данные для узла" узнать то, к какому узлу относятся эти данные (хм… звучит довольно громоздко). В простейшем случае (как было это показано в примере) я смело обращаюсь к переменной node, поскольку знаю, что она сохранила свое значение благодаря "замыканию". В том случае, если функция обработчик события "пришли данные" представлена не в виде анонимной функции (а обычной функции, определенной в области видимости, например, window), то можно поместить внутрь объекта callback еще одно свойство argument (в примере закомментировано). Тогда для обращения к "списку аргументов" используем запись "oResponse.argument.переменная". Последнее, на что я обращу ваше внимание перед переходом к рассмотрению php-скрипта, формирующего данные, – это назначение свойства isLeaf для каждого из новых узлов. Дело в том, что я хочу, чтобы иконки со значком плюса (узел можно раскрыть) были поставлены в соответствие только тем узлам, которые являются каталогами и внутри которых есть хотя бы один дочерний файл или подкаталог.
Устройство php-скрипта, формирующего массив файлов внутри каталога, тривиально:
$path2open = iconv("UTF-8", "WINDOWS-1251", $_REQUEST['path2open']);
function scan ($path2open, $level = 0){
$dh = opendir ($path2open);
$final = array ();
while (($file = readdir($dh)) !== false){
if ($file == '..' || $file == '.') continue;
$fullname = $path2open . '/' . $file;
$type = is_dir ($fullname)?'dir':'file';
$children = 0;
if ($type == 'dir' && $level == 0)
$children = count(scan ($fullname, 1)) > 0;
$final [] = array ('file' => iconv("WINDOWS-1251", "UTF-8", $file), 'type' => $type, 'children' => $children );
}
closedir ($dh);
return $final;
}
print json_encode (scan ($path2open, 0) )
Следующим шагом улучшения примера будет настройка индивидуального внешнего вида для каждого из узлов. Так, узлы, соответствующие каталогам, должны иметь картинки-иконки в виде папок. А узлы, соответствующие файлам, получат пиктограммы, соответствующие типу файла (т.е. файлы word, excel и архивы будут иметь различный внешний вид). Первая часть задания (с картинками каталогов) решается на счет раз-два: YUI компоненты поддерживают скины, и в составе YUI есть уже подготовленный css-файл assets/css/folders/tree.css (он идет вместе с одним из примеров TreeView). Сначала я скопировал всю папку assets с css-стилями и файлами картинок в папку с примером. Затем для удобства я переопределил все css-правила в css-файле следующим образом: было .ygtvloading и стало .folder .ygtvloading. Хотя YUI имеет стандартизированную методику создания css-скинов и их загрузки с помощью YUI-loader, но в большинстве случаев, когда необходимо на одной странице разместить несколько одинаковых компонентов (те же два TreeView), но при этом имеющие различное оформление, то лучше подправить файлы css-стилей. Например, добавив для всех стилей, используемых для оформления компонента TreeView, префикс (в моем примере .folder). Это даст нам возможность избирательно применять css-скины для различных компонентов, просто создав на html-странице блок div с css-классом folder, и разместив внутри которого TreeView:
// подключаем стили
<link rel="stylesheet" type="text/css" href="assets/css/folders/tree.css">
<div class="folder"> <!—применяем их -->
<div id="treeplaceholder"></div>
</div>
if (json[i].type == 'dir' && json[i].children == 0)
fnode.contentStyle = 'folder_leaf';
.folder_leaf { background:transparent url(img/folder_leaf.png) no-repeat; }
.folder_leaf .ygtvlabel { margin-left: 20px !important; }
Как небольшое задание попробуйте сами модифицировать код javascript раннего примера так, чтобы он анализировал расширение файла и назначал бы такому узлу индивидуальную иконку (css-стиль). Я настоятельно рекомендую обратиться к примерам, идущим вместе с YUI, так как там вы найдете не только очень ну очень похожий пример, но и рассмотрите еще одну полезную методику: css-sprites. В Интернете есть множество статей, рассказывающих об идеях, положенных в основу css-sprites, но вкратце можно сказать, что с ее помощью мы можем уменьшить время загрузки страницы (точнее, ее графических ресурсов). В прошлой статье, начиная рассказ об TreeeView, я перечислил доступные типы узлов: TextNode, HtmlNode, MenuNode. Также я сказал, что мы можем создавать собственные типы узлов, в случаях, когда мы хотим не только создать новый внешний вид узла (ведь здесь можно было бы обойтись, например, HtmlNode), но хотим еще и создать правила, по которым узел реагирует на действия пользователя. Еще раз я советую открыть официальную документацию по YUI, и среди множества примеров вы найдете демонстрацию дерева, каждый из узлов которого представлен в виде checkbox. Этот checkbox может находиться в трех состояниях в зависимости от того, в каких состояниях находятся дочерние по отношению к нему узлы. Так, узел может быть отмечен или включен, если и он, и все дочерние узлы отмечены. Если ни один из дочерних узлов не отмечен, то родительский узел принимает второе состояние – не отмечен. И третье состояние соответствует ситуации, когда часть дочерних узлов отмечена и часть — нет.
Подводя некоторые итоги и завершая рассказ об YUI, я хотел бы обратить ваше внимание на одну из самых полезных методик по созданию веб- интерфейсов – это создание собственных надстроек над стандартными классами. Дело в том, что даже если мы не создаем классы, расширяющие возможности стандартных компонентов YUI, то все равно объем кода, занимающегося конфигурированием компонентов, очень велик. Этот код включает в себя и настройку внешнего вида, и функции обработчика различных событий. Объединив все это вместе, мы представляем страницу не в виде: компонент DataTable, настроенный для отображения списка товаров, плюс еще один DataTable, настроенный для … Вместо этого мы создадим js-файл, назовем его goods.js, внутри этого файла создадим собственный класс GoodsTable производный от DataTable. Конструктор такого класса будет принимать в качестве параметра уже не информацию о колонках, их render-ах, ширине и заголовках, а более общие параметры: html элемент страницы, внутрь которого нужно поместить DataTable, путь к php-скрипту, поставляющему данные. Так как компоненты на странице должны взаимодействовать, то мы создадим собственную систему обмена сообщениями, не тривиальными, вроде "была выделена строка", а высокоуровневыми или бизнес-событиями. Например, были внесены изменения в запись или была завершена загрузка информации для очередной страницы DataTable. Таким образом, мы создадим self-contained модули или строительные блоки, из которых можно собрать веб-интерфейс. Эти блоки можно будет тестировать и разрабатывать независимо друг от друга, распределять эту работу между несколькими членами команды и, самое важное, повторно использовать в нескольких проектах.
black-zorro@tut.by black-zorro.com
Компьютерная газета. Статья была опубликована в номере 07 за 2009 год в рубрике программирование
