
Пишем и тестируем код, работающий с БД, вместе с DBUnit & LiquiBase. Часть 1
Уверен, что никто не будет спорить с тем, что при разработке программного продукта одним из важнейших моментов является оценка его качества. Наличие даже самых небольших ошибок или несоответствий техническому заданию могут стать камнем преткновения и, если мы говорим о разработке коммерческого ПО, могут привести к убыткам, штрафам и закрытию проекта вообще. Частью процесса оценки качества является тестирование. Я уже поднимал этот вопрос в серии статей, посвященных тестированию веб-сайтов с помощью badboy и jmeter. Тогда же я рассказал об основных видах тестирования: юнит-тестировании (т.е. тестировании отдельных модулей, классов, функций — небольших строительных блоков, из которых по сути и состоит вся программа), интеграционном тестировании (когда мы собираем те самые кусочки воедино) и системном тестировании (именно этому виду были посвящены статьи про badboy и jmeter).
Сегодняшняя статья рассказывает о юнит-тестировании и такой его части, как тестирование кода, работающего с базой данных. Собственно говоря, больших проблем или страшных секретов здесь нет. Любое приложение можно условно разделить на несколько частей, модулей. Каждый из них нужно проверить сначала отдельно (юнит-тестирование), а затем вместе (интеграционное тестирование). Естественно, что при тестировании модулей возникает проблема "а этой части еще нет". Т.е. модули приложения не существуют отдельно, а зависят друг от друга, пользуются услугами "соседей". В этой ситуации используются mock'и, или имитации. Некоторую часть системы (возможно еще и не существующую) нужно заменить на ее суррогат, имитацию. Такой подход дает возможность не только разрабатывать часть модулей приложения параллельно, но и уменьшает количество ложных ошибок. Действительно, шанс того, что ошибка будет допущена в имитации (максимально упрощенной и не содержащей настоящей бизнес-логики), крайне мала. В состав почти всех известных и популярных библиотек и фреймворков входят подобные имитации. Например, чтобы проверить ваш код, работающий в рамках некоторой среды "X", вовсе не обязательно запускать веб-сервер, развертывать на нем веб-приложение, а затем имитировать запрос пользователя из браузера. Все эти операции, конечно, не составляют большой сложности, но требуют значительных временных затрат. Поэтому существует понятие "легких тестов". Т.е. когда мы говорим, что программа, предназначенная работать совместно с некоторой огромной и громоздкой инфраструктурой (сервером приложений, БД), может быть протестирована на имитации этой инфраструктуры. Условно говоря, можно создать объект "имитация_веб_сервера", поместить в него код вашего приложения, затем создать объект "имитация_запроса_клиента", а затем оценить, какие ошибки возникли и почему. Больших секретов я не раскрыл, да и не собирался этого делать, т.к. рассказ о таких методиках тестирования неизбежно связан с "узкими" технологиями, которые вряд ли будут интересны массовому читателю. Сегодняшняя тема рассказа — тестирование кода, работающего с базами данных, и средства, позволяющие упростить процесс эволюции структуры БД по ходу развития проекта. Те инструменты, о которых я расскажу, имеют общий характер и будут полезны любому из java-программистов без учета того, с каким конкретно framework'ом он работает (spring, jsf, webwork…). Также я предполагаю, что читатель знаком с таким универсальным инструментом тестирования в java как junit. Благо по этой теме есть достаточное количество информации (и даже на русском языке) как в электронной форме, так и на страницах КГ.
Начну я с того, что расскажу об основных проблемах, которые возникают при разработке приложений, интенсивно работающих с СУБД, и их тестировании. Не секрет, что как можно раньше необходимо выполнять тесты на данных, максимально похожих на "настоящие". Большинство проблем возникают из-за того, что разработка программ и их тестирование ведется на не тех данных. То есть приложение, предназначенное для учета, скажем, товаров на крупном складе, оперирует тестовой БД размером в несколько десятков записей. А затем (в ходе эксплуатации созданной программы) начинаются проблемы: медленно строится отчет, графики показателей продаж превращаются в нечто визуально неудобочитаемое... Другой проблемой является то, что данные, внесенные в тестовую СУБД, не очень коррелируются с реальной жизнью: цены с потолка "помогут" пропустить ошибку переполнения, например, при расчете стоимости. А созданные для теста БД записи накладных на две-три позиции товаров наверняка принесут ряд "приятных" сюрпризов при печати на бланке накладной строгой отчетности, который содержит несколько десятков позиций. Подобных примеров можно привести еще очень много. Так что все согласятся с тем, что тестовые данные должны быть максимально полными и близкими к реальной жизни. Теперь предположим, что вы написали модуль перевода денег с одного счета на другой, а для теста в СУБД были подготовлены некоторые таблицы. Нам осталось только запустить тесты, а после их завершения проверить, чтобы состояние СУБД (результат работы вашего кода) совпал с эталонным, ожидаемым. Очевидно, что после запуска тестов состояние СУБД будет искажаться. И вы должны будете при повторном запуске теста (а таких пусков за день может быть добрый десяток) привести СУБД в изначальное состояние. В старые, "темные" времена это решалось созданием специального файла сценария, содержавшего sql-команды для удаления всей устаревшей информации и заполнения базы заново. Естественно, что на программисте/тестировщике лежала ответственность перед проведением теста "не забыть" запустить нужный сценарий подготовки. Ситуация усложнялась тем, что часто для каждого из тестов (а их в пакете могли быть сотни и тысячи) нужна была своя, особая среда окружения. Например, для теста №13 нужно, чтобы в таблице была запись о товаре "X", а для теста №113 запись должна, наоборот, отсутствовать. Таким образом возникла необходимость в создании средства, выполняющего рутинные действия по "созданию" тестовой среды и обязательно легко интегрирующегося с такими общими инструментами тестирования, как junut или testng. Решению именно этой проблемы будет посвящен dbUnit.
Вторая часть статьи рассказывает о LiquiBase. Что это такое и зачем нужно? Согласитесь, что ситуация, когда проект (да хоть тот же складской учет) сдан и больше в него изменений не вносится, крайне маловероятна. После того как заказчик получил программу и начал ею пользоваться, неизбежно будет приходить понимание того, что "здесь мы забыли", "а появилась новая потребность", "изменились законы"… Не секрет, что львиная доля стоимости ПО определяется затратами на его поддержку. И заказ на разработку новой программы чаще всего приходит тогда, когда затраты на поддержание и внесение изменений в старую версию становятся дороже, чем затраты на "выкинуть все старье на помойку и переписать программу заново". Мы принимаем заказ на доделку программы, вносим в нее изменения и (вот она суть проблемы!) вынуждены менять структуру БД. Правки могут быть как простыми (например, добавить новое поле в таблицу товаров), так и более сложными (скажем, информацию из старой таблицы разнести по нескольким новым, обновить значения определенных полей в таблицах...). Затем наступает ответственный момент, когда администратор СУБД начинает сравнивать структуру базы данных " у клиента" с той, которая "у нас", и определяет, какие правки нужно выполнить для миграции с одной версии БД на другую. Наконец в пятницу, ровно в полночь (или любое другое время, когда заказчик не работает), база данных "разбирается" и "собирается" заново. Данный процесс не сложен, но требует крайней внимательности, ведь допущенная ошибка приведет к тому, что нужно будет восстанавливать БД из резервной копии, а на это уйдут драгоценные часы, и когда часы пробьют ровно двенадцать, карета превратится в… Одним словом, вы не успели: время на миграцию БД исчерпано, задача не выполнена, начинается новый рабочий день, а простои в нем не допустимы. Особый вкус задача внесения правок в БД приобретает, когда ведется параллельная разработка нескольких очень похожих версий для разных заказчиков. Здесь уже не обойтись старым добрым текстовым файлом с указанием на какую дату, для какой обновленной функции программы и какие правки нужно сделать в БД, чтобы все заработало. Для решения подобной проблемы предназначен второй инструмент сегодняшнего обзора — LiquiBase. Однако довольно слов, давайте перейдем к делу.
Начнем с dbUnit (в примерах везде используется mysql, но никакой разницы между ним и любой другой СУБД с точки зрения dbUnit нет).
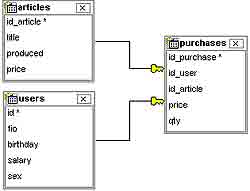 Предположим, что вы успешно загрузили библиотеку dbUnit с сайта сайт (для корректной работы dbunit могут потребоваться дополнительные библиотеки, которые можно найти на сайте сайт ). Теперь нужно спроектировать БД и написать код, ее использующий. В БД будут две таблицы-справочника: одна с перечислением покупателей, вторая с перечнем товаров, а третья таблица будет играть роль промежуточной, т.е. хранящей сведения о покупках (см. рис. 1).
Предположим, что вы успешно загрузили библиотеку dbUnit с сайта сайт (для корректной работы dbunit могут потребоваться дополнительные библиотеки, которые можно найти на сайте сайт ). Теперь нужно спроектировать БД и написать код, ее использующий. В БД будут две таблицы-справочника: одна с перечислением покупателей, вторая с перечнем товаров, а третья таблица будет играть роль промежуточной, т.е. хранящей сведения о покупках (см. рис. 1).
CREATE TABLE 'users' ( 'id_user' int NOT NULL AUTO_INCREMENT, 'fio' varchar(100), 'birthday' date, 'sex' enum('m','f'), PRIMARY KEY ('id_user')) ENGINE=InnoDB
CREATE TABLE 'articles' ( 'id_article' int NOT NULL AUTO_INCREMENT, 'title' varchar(100), 'produced' date, 'price' float, PRIMARY KEY ('id_article')) ENGINE=InnoDB
CREATE TABLE 'purchases' ( 'id_purchase' int NOT NULL AUTO_INCREMENT,
'id_user' int(11) NOT NULL, 'id_article' int(11) NOT NULL, 'price' float DEFAULT NULL, 'qty' int(11) DEFAULT NULL, PRIMARY KEY ('id_purchase'),
FOREIGN KEY ('id_user') REFERENCES 'users' ('id') ON DELETE CASCADE,
FOREIGN KEY ('id_good') REFERENCES 'articles' ('id') ON DELETE CASCADE ON UPDATE CASCADE) ENGINE=InnoDB
Перед написанием тестов необходимо создать файл-сценарий для dbUnit, который будет содержать набор тестовых данных. Есть несколько альтернатив формата для этого файла: можно использовать xml, csv, excel. Начнем с xml, вот его пример:
<?xml version='1.0' encoding='UTF-8'?>
<dataset>
<users id="1" fio="Jim" birthday="1999-01-01" sex="m"/>
<users id="2" fio="Tom" birthday="1989-01-01" sex="m"/>
<users id="3" fio="Marta" birthday="1959-01-01" sex="f"/>
</dataset>
Как видите, ничего сложного: внутри корневого элемента dataset находятся записи, соответствующие каждой из таблиц, которую нужно заполнить. Имя таблицы задано как имя тега, а атрибуты этого тега соответствуют полям таблицы (если значение какого-либо из атрибутов отсутствует, то в таблицу будет вставлено значение по-умолчанию). В случае, если у вас уже есть БД, наполненная тестовой информацией, то можно воспользоваться следующим примером кода, который выгрузит эту базу в xml-файл:
// загружаем драйвер для работы с mysql
Class.forName("com.mysql.jdbc.Driver");
// получаем подключение к серверу СУБД
Connection jdbcConnection = DriverManager.getConnection( "jdbc:mysql://localhost/dbutest?useUnicode=true&characterSet=UTF-8", "root", ""); IDatabaseConnection iConnection = new DatabaseConnection(jdbcConnection);
// экспортируем часть базы данных
QueryDataSet partialDataSet = new QueryDataSet(iConnection);
// экспорт таблицы, но не всей, а только определенных записей
partialDataSet.addTable("users", "SELECT * FROM users where sex = 'm' ");
// экспорт всей таблицы
partialDataSet.addTable("articles");
// сохраняем изменения в файл
FlatXmlDataSet.write(partialDataSet, new FileOutputStream("users-and-articles-dataset.xml"));
// экспорт всей базы данных полностью
IDataSet fullDataSet = iConnection.createDataSet();
FlatXmlDataSet.write(fullDataSet, new FileOutputStream("all-tables-dataset.xml"));
В ходе работы данного кода на экран будут выводиться сообщения об ошибках, но на них не стоит обращать внимания: файлы xml с данными для экспорта все равно будут созданы. Условно код состоит из следующих шагов:
1. Создать подключение к БД с помощью старого доброго JDBC и "обернуть" это подключение объектом IDatabaseConnection.
2. Создать объект DataSet и наполнить его правилами "что подлежит экспорту".
3. Выполнить запись DataSet в файл с помощью объекта FlatXmlWriter (в этом примере создание FlatXMLWriter выполняется прозрачно, но в последующих примерах нам потребуется явно записать код создания Writer'a).
Возвращаясь к примеру, в первом случае я выполняю экспорт только двух таблиц из БД. Более того, для таблицы users я задал sql-код запроса, так что в файл со "снимком" будут помещены только те записи, для которых выполнено условие "sex='m'". Вторая таблица — articles — была помещена в файл без ограничений. Кроме того, я создал снимок всей БД и поместил его в файл "all-tables-dataset.xml". Именно рассматривая данный файл, можно столкнуться с проблемой:
<dataset>
<articles id_article="1" title="milk" produced="2008-01-01" price="100.0"/>
<purchases id_purchase="1" id_user="1" id_article="1" price="2000.0" qty="3"/>
<users id_user="1" fio="Jim" birthday="1999-01-01" sex="m"/>
</dataset>
Видите, в каком порядке перечислены операции по вставке данных в БД? Сначала товары, затем покупки и напоследок сведения о покупателях. Довольно забавно: как можно создать запись о покупке, ссылающейся на некоторого пользователя #1, если этот пользователь будет добавлен только спустя какое-то время? Нам нужен механизм упорядочения порядка вставки записей. В dbUnit за это отвечает интерфейс ITableFilter и несколько классов, его реализующих. Например, класс SequenceTableFilter. При его создании в качестве параметра конструктору нужно передать список имен таблиц; именно в таком порядке таблицы будут экспортированы в xml-файл. В случае, если вы хотите отобрать не все записи из таблиц и при этом не можете обойтись простым sql-запросом, то можно попробовать использовать PrimaryKeyFilter. В качестве параметра конструктора для этого класса передается "карта" (map), в качестве ключей которой используются имена таблиц, а значениями являются списки допустимых значений первичного ключа. Класс ExcludeTableFilter служит для того, чтобы исключить из списка экспортируемых из БД таблиц те, имена которых переданы как параметр конструктору класса. И, наконец, самый полезный класс — DatabaseSequenceFilter, именно он и отвечает за процесс автоматического упорядочения таблиц при экспорте, основываясь на связях между ними. Вот пример использования этого класса:
ITableFilter filter = new DatabaseSequenceFilter(iConnection);
IDataSet fullDataSet = new FilteredDataSet(filter, iConnection.createDataSet());
FlatXmlDataSet.write(fullDataSet, new FileOutputStream("all-tables-dataset.xml"));
Результирующий xml-файл уже выглядит приемлемо: сначала идет вставка данных из таблицы articles, затем users и последней идет purchases. К сожалению, всех проблем, связанных с "правильным порядком вставки записей", так не решить: остается открытым вопрос со вставкой рекурсивных данных. Неприятности появятся и при очистке содержимого таблиц с отключенными каскадными обновлениями/удалениями. Поэтому я предпочитаю самостоятельно в процедуре подключения к СУБД отключить на время связи между таблицами. Для mysql, например, это делается так:
// так мы отключаем
SET FOREIGN_KEY_CHECKS =0
// а так включаем, после того как данные были внесены в БД
SET FOREIGN_KEY_CHECKS =1
При экспорте данных может пригодиться и следующий фрагмент кода. Его назначение — выгрузить в xml-файл содержимое таблицы purchases и всех таблиц, от которых она зависит (dependency).
String[] deps = TablesDependencyHelper.getAllDependentTables(iConnection, "purchases");
IDataSet depsDS = iConnection.createDataSet(deps);
FlatXmlDataSet.write(depsDS, new FileOutputStream("deps.xml"));
Теперь разберемся с тем, как dbUnit на стадии импорта данных в БД определяет то, как должна выглядеть структура целевых таблиц. В общем случае никаких секретов здесь нет: на основании файла с примерами импортируемых данных (точнее на примере первой записи в этом файле) dbUnit принимает решение, какие поля должны быть в таблице. Это не совсем правильно, если первая запись экспортированных данных не содержит значения всех полей (атрибутов). В этом случае имеет смысл сгенерировать DTD-файл, он не только решает описанную выше проблему, но и позволяет проверить xml-файл с данными на предмет корректности на стадии импорта данных в БД.
// создаем объект DataSet с правилами "что нужно экспортировать"
IDataSet allDataSet = iConnection.createDataSet();
// записываем эти сведения внутрь dtd-файал
FlatDtdDataSet.write(allDataSet, new FileOutputStream("db.dtd"));
// теперь создаем объект xml-writer-а
FlatXmlWriter DTDwriter = new FlatXmlWriter(new FileOutputStream("with-dtd-dataset.xml"));
// нам нужно указать в качестве параметров имя dtd-файла
DTDwriter.setDocType("db.dtd");
// экспортируем содержимое БД в xml-файл
DTDwriter.write(allDataSet);
Последний полезный прием при экспорте содержимого БД во внешний xml-файл — настройка streaming. Streaming — механизм, позволяющий эффективно работать с большими по объему наборами данных при экспорте:
DatabaseConfig config = iConnection.getConfig();
config.setProperty(DatabaseConfig.PROPERTY_RESULTSET_TABLE_FACTORY, new ForwardOnlyResultSetTableFactory());
В следующий раз я завершу рассказ о dbUnit. Нам осталось разобраться с тем, как импортировать данные из xml-файла и интегрировать dbUnit с jUnit. Затем я расскажу о том, как помогает "развивать" структуру БД LiquiBase.
black-zorro@tut.by black-zorro.com
Сегодняшняя статья рассказывает о юнит-тестировании и такой его части, как тестирование кода, работающего с базой данных. Собственно говоря, больших проблем или страшных секретов здесь нет. Любое приложение можно условно разделить на несколько частей, модулей. Каждый из них нужно проверить сначала отдельно (юнит-тестирование), а затем вместе (интеграционное тестирование). Естественно, что при тестировании модулей возникает проблема "а этой части еще нет". Т.е. модули приложения не существуют отдельно, а зависят друг от друга, пользуются услугами "соседей". В этой ситуации используются mock'и, или имитации. Некоторую часть системы (возможно еще и не существующую) нужно заменить на ее суррогат, имитацию. Такой подход дает возможность не только разрабатывать часть модулей приложения параллельно, но и уменьшает количество ложных ошибок. Действительно, шанс того, что ошибка будет допущена в имитации (максимально упрощенной и не содержащей настоящей бизнес-логики), крайне мала. В состав почти всех известных и популярных библиотек и фреймворков входят подобные имитации. Например, чтобы проверить ваш код, работающий в рамках некоторой среды "X", вовсе не обязательно запускать веб-сервер, развертывать на нем веб-приложение, а затем имитировать запрос пользователя из браузера. Все эти операции, конечно, не составляют большой сложности, но требуют значительных временных затрат. Поэтому существует понятие "легких тестов". Т.е. когда мы говорим, что программа, предназначенная работать совместно с некоторой огромной и громоздкой инфраструктурой (сервером приложений, БД), может быть протестирована на имитации этой инфраструктуры. Условно говоря, можно создать объект "имитация_веб_сервера", поместить в него код вашего приложения, затем создать объект "имитация_запроса_клиента", а затем оценить, какие ошибки возникли и почему. Больших секретов я не раскрыл, да и не собирался этого делать, т.к. рассказ о таких методиках тестирования неизбежно связан с "узкими" технологиями, которые вряд ли будут интересны массовому читателю. Сегодняшняя тема рассказа — тестирование кода, работающего с базами данных, и средства, позволяющие упростить процесс эволюции структуры БД по ходу развития проекта. Те инструменты, о которых я расскажу, имеют общий характер и будут полезны любому из java-программистов без учета того, с каким конкретно framework'ом он работает (spring, jsf, webwork…). Также я предполагаю, что читатель знаком с таким универсальным инструментом тестирования в java как junit. Благо по этой теме есть достаточное количество информации (и даже на русском языке) как в электронной форме, так и на страницах КГ.
Начну я с того, что расскажу об основных проблемах, которые возникают при разработке приложений, интенсивно работающих с СУБД, и их тестировании. Не секрет, что как можно раньше необходимо выполнять тесты на данных, максимально похожих на "настоящие". Большинство проблем возникают из-за того, что разработка программ и их тестирование ведется на не тех данных. То есть приложение, предназначенное для учета, скажем, товаров на крупном складе, оперирует тестовой БД размером в несколько десятков записей. А затем (в ходе эксплуатации созданной программы) начинаются проблемы: медленно строится отчет, графики показателей продаж превращаются в нечто визуально неудобочитаемое... Другой проблемой является то, что данные, внесенные в тестовую СУБД, не очень коррелируются с реальной жизнью: цены с потолка "помогут" пропустить ошибку переполнения, например, при расчете стоимости. А созданные для теста БД записи накладных на две-три позиции товаров наверняка принесут ряд "приятных" сюрпризов при печати на бланке накладной строгой отчетности, который содержит несколько десятков позиций. Подобных примеров можно привести еще очень много. Так что все согласятся с тем, что тестовые данные должны быть максимально полными и близкими к реальной жизни. Теперь предположим, что вы написали модуль перевода денег с одного счета на другой, а для теста в СУБД были подготовлены некоторые таблицы. Нам осталось только запустить тесты, а после их завершения проверить, чтобы состояние СУБД (результат работы вашего кода) совпал с эталонным, ожидаемым. Очевидно, что после запуска тестов состояние СУБД будет искажаться. И вы должны будете при повторном запуске теста (а таких пусков за день может быть добрый десяток) привести СУБД в изначальное состояние. В старые, "темные" времена это решалось созданием специального файла сценария, содержавшего sql-команды для удаления всей устаревшей информации и заполнения базы заново. Естественно, что на программисте/тестировщике лежала ответственность перед проведением теста "не забыть" запустить нужный сценарий подготовки. Ситуация усложнялась тем, что часто для каждого из тестов (а их в пакете могли быть сотни и тысячи) нужна была своя, особая среда окружения. Например, для теста №13 нужно, чтобы в таблице была запись о товаре "X", а для теста №113 запись должна, наоборот, отсутствовать. Таким образом возникла необходимость в создании средства, выполняющего рутинные действия по "созданию" тестовой среды и обязательно легко интегрирующегося с такими общими инструментами тестирования, как junut или testng. Решению именно этой проблемы будет посвящен dbUnit.
Вторая часть статьи рассказывает о LiquiBase. Что это такое и зачем нужно? Согласитесь, что ситуация, когда проект (да хоть тот же складской учет) сдан и больше в него изменений не вносится, крайне маловероятна. После того как заказчик получил программу и начал ею пользоваться, неизбежно будет приходить понимание того, что "здесь мы забыли", "а появилась новая потребность", "изменились законы"… Не секрет, что львиная доля стоимости ПО определяется затратами на его поддержку. И заказ на разработку новой программы чаще всего приходит тогда, когда затраты на поддержание и внесение изменений в старую версию становятся дороже, чем затраты на "выкинуть все старье на помойку и переписать программу заново". Мы принимаем заказ на доделку программы, вносим в нее изменения и (вот она суть проблемы!) вынуждены менять структуру БД. Правки могут быть как простыми (например, добавить новое поле в таблицу товаров), так и более сложными (скажем, информацию из старой таблицы разнести по нескольким новым, обновить значения определенных полей в таблицах...). Затем наступает ответственный момент, когда администратор СУБД начинает сравнивать структуру базы данных " у клиента" с той, которая "у нас", и определяет, какие правки нужно выполнить для миграции с одной версии БД на другую. Наконец в пятницу, ровно в полночь (или любое другое время, когда заказчик не работает), база данных "разбирается" и "собирается" заново. Данный процесс не сложен, но требует крайней внимательности, ведь допущенная ошибка приведет к тому, что нужно будет восстанавливать БД из резервной копии, а на это уйдут драгоценные часы, и когда часы пробьют ровно двенадцать, карета превратится в… Одним словом, вы не успели: время на миграцию БД исчерпано, задача не выполнена, начинается новый рабочий день, а простои в нем не допустимы. Особый вкус задача внесения правок в БД приобретает, когда ведется параллельная разработка нескольких очень похожих версий для разных заказчиков. Здесь уже не обойтись старым добрым текстовым файлом с указанием на какую дату, для какой обновленной функции программы и какие правки нужно сделать в БД, чтобы все заработало. Для решения подобной проблемы предназначен второй инструмент сегодняшнего обзора — LiquiBase. Однако довольно слов, давайте перейдем к делу.
Начнем с dbUnit (в примерах везде используется mysql, но никакой разницы между ним и любой другой СУБД с точки зрения dbUnit нет).
CREATE TABLE 'users' ( 'id_user' int NOT NULL AUTO_INCREMENT, 'fio' varchar(100), 'birthday' date, 'sex' enum('m','f'), PRIMARY KEY ('id_user')) ENGINE=InnoDB
CREATE TABLE 'articles' ( 'id_article' int NOT NULL AUTO_INCREMENT, 'title' varchar(100), 'produced' date, 'price' float, PRIMARY KEY ('id_article')) ENGINE=InnoDB
CREATE TABLE 'purchases' ( 'id_purchase' int NOT NULL AUTO_INCREMENT,
'id_user' int(11) NOT NULL, 'id_article' int(11) NOT NULL, 'price' float DEFAULT NULL, 'qty' int(11) DEFAULT NULL, PRIMARY KEY ('id_purchase'),
FOREIGN KEY ('id_user') REFERENCES 'users' ('id') ON DELETE CASCADE,
FOREIGN KEY ('id_good') REFERENCES 'articles' ('id') ON DELETE CASCADE ON UPDATE CASCADE) ENGINE=InnoDB
Перед написанием тестов необходимо создать файл-сценарий для dbUnit, который будет содержать набор тестовых данных. Есть несколько альтернатив формата для этого файла: можно использовать xml, csv, excel. Начнем с xml, вот его пример:
<?xml version='1.0' encoding='UTF-8'?>
<dataset>
<users id="1" fio="Jim" birthday="1999-01-01" sex="m"/>
<users id="2" fio="Tom" birthday="1989-01-01" sex="m"/>
<users id="3" fio="Marta" birthday="1959-01-01" sex="f"/>
</dataset>
Как видите, ничего сложного: внутри корневого элемента dataset находятся записи, соответствующие каждой из таблиц, которую нужно заполнить. Имя таблицы задано как имя тега, а атрибуты этого тега соответствуют полям таблицы (если значение какого-либо из атрибутов отсутствует, то в таблицу будет вставлено значение по-умолчанию). В случае, если у вас уже есть БД, наполненная тестовой информацией, то можно воспользоваться следующим примером кода, который выгрузит эту базу в xml-файл:
// загружаем драйвер для работы с mysql
Class.forName("com.mysql.jdbc.Driver");
// получаем подключение к серверу СУБД
Connection jdbcConnection = DriverManager.getConnection( "jdbc:mysql://localhost/dbutest?useUnicode=true&characterSet=UTF-8", "root", ""); IDatabaseConnection iConnection = new DatabaseConnection(jdbcConnection);
// экспортируем часть базы данных
QueryDataSet partialDataSet = new QueryDataSet(iConnection);
// экспорт таблицы, но не всей, а только определенных записей
partialDataSet.addTable("users", "SELECT * FROM users where sex = 'm' ");
// экспорт всей таблицы
partialDataSet.addTable("articles");
// сохраняем изменения в файл
FlatXmlDataSet.write(partialDataSet, new FileOutputStream("users-and-articles-dataset.xml"));
// экспорт всей базы данных полностью
IDataSet fullDataSet = iConnection.createDataSet();
FlatXmlDataSet.write(fullDataSet, new FileOutputStream("all-tables-dataset.xml"));
В ходе работы данного кода на экран будут выводиться сообщения об ошибках, но на них не стоит обращать внимания: файлы xml с данными для экспорта все равно будут созданы. Условно код состоит из следующих шагов:
1. Создать подключение к БД с помощью старого доброго JDBC и "обернуть" это подключение объектом IDatabaseConnection.
2. Создать объект DataSet и наполнить его правилами "что подлежит экспорту".
3. Выполнить запись DataSet в файл с помощью объекта FlatXmlWriter (в этом примере создание FlatXMLWriter выполняется прозрачно, но в последующих примерах нам потребуется явно записать код создания Writer'a).
Возвращаясь к примеру, в первом случае я выполняю экспорт только двух таблиц из БД. Более того, для таблицы users я задал sql-код запроса, так что в файл со "снимком" будут помещены только те записи, для которых выполнено условие "sex='m'". Вторая таблица — articles — была помещена в файл без ограничений. Кроме того, я создал снимок всей БД и поместил его в файл "all-tables-dataset.xml". Именно рассматривая данный файл, можно столкнуться с проблемой:
<dataset>
<articles id_article="1" title="milk" produced="2008-01-01" price="100.0"/>
<purchases id_purchase="1" id_user="1" id_article="1" price="2000.0" qty="3"/>
<users id_user="1" fio="Jim" birthday="1999-01-01" sex="m"/>
</dataset>
Видите, в каком порядке перечислены операции по вставке данных в БД? Сначала товары, затем покупки и напоследок сведения о покупателях. Довольно забавно: как можно создать запись о покупке, ссылающейся на некоторого пользователя #1, если этот пользователь будет добавлен только спустя какое-то время? Нам нужен механизм упорядочения порядка вставки записей. В dbUnit за это отвечает интерфейс ITableFilter и несколько классов, его реализующих. Например, класс SequenceTableFilter. При его создании в качестве параметра конструктору нужно передать список имен таблиц; именно в таком порядке таблицы будут экспортированы в xml-файл. В случае, если вы хотите отобрать не все записи из таблиц и при этом не можете обойтись простым sql-запросом, то можно попробовать использовать PrimaryKeyFilter. В качестве параметра конструктора для этого класса передается "карта" (map), в качестве ключей которой используются имена таблиц, а значениями являются списки допустимых значений первичного ключа. Класс ExcludeTableFilter служит для того, чтобы исключить из списка экспортируемых из БД таблиц те, имена которых переданы как параметр конструктору класса. И, наконец, самый полезный класс — DatabaseSequenceFilter, именно он и отвечает за процесс автоматического упорядочения таблиц при экспорте, основываясь на связях между ними. Вот пример использования этого класса:
ITableFilter filter = new DatabaseSequenceFilter(iConnection);
IDataSet fullDataSet = new FilteredDataSet(filter, iConnection.createDataSet());
FlatXmlDataSet.write(fullDataSet, new FileOutputStream("all-tables-dataset.xml"));
Результирующий xml-файл уже выглядит приемлемо: сначала идет вставка данных из таблицы articles, затем users и последней идет purchases. К сожалению, всех проблем, связанных с "правильным порядком вставки записей", так не решить: остается открытым вопрос со вставкой рекурсивных данных. Неприятности появятся и при очистке содержимого таблиц с отключенными каскадными обновлениями/удалениями. Поэтому я предпочитаю самостоятельно в процедуре подключения к СУБД отключить на время связи между таблицами. Для mysql, например, это делается так:
// так мы отключаем
SET FOREIGN_KEY_CHECKS =0
// а так включаем, после того как данные были внесены в БД
SET FOREIGN_KEY_CHECKS =1
При экспорте данных может пригодиться и следующий фрагмент кода. Его назначение — выгрузить в xml-файл содержимое таблицы purchases и всех таблиц, от которых она зависит (dependency).
String[] deps = TablesDependencyHelper.getAllDependentTables(iConnection, "purchases");
IDataSet depsDS = iConnection.createDataSet(deps);
FlatXmlDataSet.write(depsDS, new FileOutputStream("deps.xml"));
Теперь разберемся с тем, как dbUnit на стадии импорта данных в БД определяет то, как должна выглядеть структура целевых таблиц. В общем случае никаких секретов здесь нет: на основании файла с примерами импортируемых данных (точнее на примере первой записи в этом файле) dbUnit принимает решение, какие поля должны быть в таблице. Это не совсем правильно, если первая запись экспортированных данных не содержит значения всех полей (атрибутов). В этом случае имеет смысл сгенерировать DTD-файл, он не только решает описанную выше проблему, но и позволяет проверить xml-файл с данными на предмет корректности на стадии импорта данных в БД.
// создаем объект DataSet с правилами "что нужно экспортировать"
IDataSet allDataSet = iConnection.createDataSet();
// записываем эти сведения внутрь dtd-файал
FlatDtdDataSet.write(allDataSet, new FileOutputStream("db.dtd"));
// теперь создаем объект xml-writer-а
FlatXmlWriter DTDwriter = new FlatXmlWriter(new FileOutputStream("with-dtd-dataset.xml"));
// нам нужно указать в качестве параметров имя dtd-файла
DTDwriter.setDocType("db.dtd");
// экспортируем содержимое БД в xml-файл
DTDwriter.write(allDataSet);
Последний полезный прием при экспорте содержимого БД во внешний xml-файл — настройка streaming. Streaming — механизм, позволяющий эффективно работать с большими по объему наборами данных при экспорте:
DatabaseConfig config = iConnection.getConfig();
config.setProperty(DatabaseConfig.PROPERTY_RESULTSET_TABLE_FACTORY, new ForwardOnlyResultSetTableFactory());
В следующий раз я завершу рассказ о dbUnit. Нам осталось разобраться с тем, как импортировать данные из xml-файла и интегрировать dbUnit с jUnit. Затем я расскажу о том, как помогает "развивать" структуру БД LiquiBase.
black-zorro@tut.by black-zorro.com
Компьютерная газета. Статья была опубликована в номере 25 за 2008 год в рубрике программирование
