
URLGrabber. Собираем адреса
Каждый день выгребаешь из ящика (виртуального) кучу спама и вопишь благим матом: "Да откуда у них мой адрес, я ни разу на порносайтах не регистрировался?!" А ХХХ-сайты тут как раз таки ни при чем. Даже регистрируясь на нормальных сайтах, ты оставляешь свой е-мейл. Пишешь в гостевых книгах — оставляешь е-мейл. Пишешь на форумах с просьбой выслать редкий файл — и снова оставляешь адрес. И тут за дело берутся "спайдеры", которые ходят по сайтам и собирают адреса. Видел когда-нибудь что-то вроде: "Пишите мне на мыло: vasyapupkin (at) mail.ru"? Таким образом люди пытаются скрыть свой адрес от спайдеров, заменяя ключевой для е-мейла символ @ на что-то нейтральное — вариаций много. Но спамеры тоже не сидят сложа руки — современные спайдеры распознают десятки подобных уловок. А ты знаешь, как создать такого спайдера? Если нет, я тебя научу.
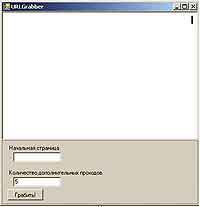 Естественно, мы таким гадким делом, как спам, заниматься не будем. Поэтому нам чужые адреса ни к чему. Я предлагаю собирать базу ссылок на ресурсы — мало ли для чего это может пригодиться. Например, сможешь хвастаться перед друзьями самой большой "линкотекой" в городе. Итак, общий план такой: запрашиваем у сервера страницу, в ответ получаем ее HTML-код. Проходимся по нему в поисках интересующей нас информации (ссылок) и записываем ее (информацию) себе. Для порядка сделаем так, чтобы ссылки не повторялись — ни к чему нам мусор. Ну, а в конце добавим циклический проход: зашли на сайт, вырезали из него ссылку, прошли по этой ссылке, зашли на сайт… и т.д. Писать будем на C# в MS Visual Studio 2005. Первое, что мы сделаем, — это визуальная часть. Бросай на форму панель и RichTextBox. На панель — кнопку, два текстовых поля и два Label. Панель растягивай на весь нижний край, RichTextBox — на все остальное пространство. Еще пригодится один таймер. У меня получилось так (рис. 1). Начальная страница — адрес, с которого мы будем начинать сбор, количество проходов — количество адресов, которое будет отбираться из полученных с начальной страницы для повтора процедуры. Как, думаю, понятно, по нажатию кнопки "Грабить!" мы будем делать наше черное дело. Теперь дадим ход графоманству. Открываем редактор кода и пишем функцию:
Естественно, мы таким гадким делом, как спам, заниматься не будем. Поэтому нам чужые адреса ни к чему. Я предлагаю собирать базу ссылок на ресурсы — мало ли для чего это может пригодиться. Например, сможешь хвастаться перед друзьями самой большой "линкотекой" в городе. Итак, общий план такой: запрашиваем у сервера страницу, в ответ получаем ее HTML-код. Проходимся по нему в поисках интересующей нас информации (ссылок) и записываем ее (информацию) себе. Для порядка сделаем так, чтобы ссылки не повторялись — ни к чему нам мусор. Ну, а в конце добавим циклический проход: зашли на сайт, вырезали из него ссылку, прошли по этой ссылке, зашли на сайт… и т.д. Писать будем на C# в MS Visual Studio 2005. Первое, что мы сделаем, — это визуальная часть. Бросай на форму панель и RichTextBox. На панель — кнопку, два текстовых поля и два Label. Панель растягивай на весь нижний край, RichTextBox — на все остальное пространство. Еще пригодится один таймер. У меня получилось так (рис. 1). Начальная страница — адрес, с которого мы будем начинать сбор, количество проходов — количество адресов, которое будет отбираться из полученных с начальной страницы для повтора процедуры. Как, думаю, понятно, по нажатию кнопки "Грабить!" мы будем делать наше черное дело. Теперь дадим ход графоманству. Открываем редактор кода и пишем функцию:
private void Execute(string Victim)
{
}
В этой функции и будет выполняться выдергивание адресов.Параметр Victim — адрес страницы, из которой в данный момент выдергиваются адреса. Едем дальше. Чтобы получить страницу, мы должны послать запрос. Для этого нужно создать объект типа HttpWebRequest и через объект типа Uri объснить ему, запрос на какую страницу мы будем посылать. Подключаем пространство имен System.Net и пишем:
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(new Uri(Victim));
Теперь нужно отправить этот запрос и получить ответ на него. В этом нам поможет объект типа HttpWebResponse.
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Все, ответ у нас есть. И в этом ответе — HTML-код странички, которую мы попросили. Если будешь писать свой движок для браузера, с этого и начнешь. Но ответ этот еще надо получить в читаемой форме. Для этого прочитаем его в поток (объект типа Stream), а из потока — "читальщиком потоков" (дословный перевод типа StreamReade).
Stream responseStream = response.GetResponseStream();
StreamReader rdr = new StreamReader(responseStream);
Предварительно подключим пространство имен System.IO. Это пока еще не чистый текст, но до него один шаг — метод ReadToEnd() объекта rdr. Теперь нужно вырезать ссылки. Для этого воспользуемся регулярными выражениями. Грубо говоря, регулярное выражение — это некий шаблон для поиска информации определенного типа в тексте. Возвращаясь к спам-спайдерам: простеший спайдер должен уметь вырезать из текста строки типа: какие- то_символы@еще_символы.снова_символы. Если тебе нужно найти на своем жестком диске все файлы типа doc, ты пишешь в поиске "*.doc" — это тоже регулярное выражение. Досконально объяснять синтаксис регулярных выражений я не буду. Я покажу пример для поиска всех http-ссылок, остальное ты легко добавишь сам. Итак, для удобства запишем наше регулярное выражение в константу:
private string RegExForURL = " http://[a-zA-Z1-9//.]*";
Несколько слов по этому выражению:
1) "наши" строки начинаются с " http://" — нормальная ссылка на веб-документ;
2) далее может следовать строчная/прописная буква или точка; набор возможных символов следует писать в квадратных скобках; точка является частью синтаксиса регулярных выражений, поэтому ее надо "экранировать", т.е. поставить перед ней обратный слэш \, но, поскольку пишем мы на Си (пусть и Шарп), ставить необходимо два обратных слэша;
3) то, что мы написали в квадратных скобках — это относится лишь к одному символу, стоящему после "httр://" (т.е. один символ может быть или буквой, или точкой), но, поскольку адресов из одной буквы не бывает, мы должны поставить после скобки звездочку, показывая, что таких символов может быть сколь угодно много.
Теперь необходимо пройтись по тексту странички и вырезать из него все строки, подпадающие под наш шаблон. Для этого создаем объект типа RegEx (не забыв предварительно подключить пространство имен System.Text.RegularExpressions) и пробагаем по тексту:
Regex re = new Regex(RegExForURL);
foreach (Match url in re.Matches(rdr.ReadToEnd()))
{
if (new Regex(url.Value).Matches(richTextBox1.Text).Count == 0)
richTextBox1.AppendText(url.Value + "\n");
}
Сначала создаем объет "регулярное выражение", передавая в качестве параметра конструктора текст выражения. Затем говорим примерно следующее: "Для каждого найденнего совпадения: заносим совпадение в переменную url" (подробнее про конструкцию foreach читай в учебниках по C#). Совпадение в виде текста содержится в свойстве Value объекта url. Условие внутри цикла foreach реализует один из пунктов нашего плана — отсеивание одинаковых адресов. При помощи регулярного выражения, которым является найденный нами адрес, я проверяю, есть ли такой адрес в нашем списке (дословно: я проверяю количество совпадений; если оно равно 0 — значит, такого адреса еще не было). Если такого адреса не было, я заношу его в список, добавляя в конце символ перевода строки, чтобы адреса шли в столбик. По большому счету, осталось добавить всего одну строчку. Создавай обработчик события Click нашей кнопки и пиши там:
private void button1_Click(object sender, EventArgs e)
{
Execute(textBox1.Text);
}
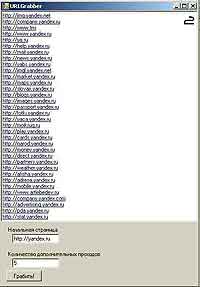 Пора проверить нашу программу. Запускаем, вводим в поле "Начальный адрес" какой-нибудь адрес (например, " http://yandex.ru") и нажимаем "Грабить!". Вот так получилось у меня (рис. 2). Красиво и правильно получилось. Но стоит ввести адрес, например, http://mail.ru, как мы тут же получим исключение с невнятным текстом "The server committed a protocol violation. Section=ResponseHeader Detail=CR must be followed by LF" и вывалимся в отладчик студии. Проблема в следующем: согласно документу RFC 822, любое интернет-сообщение должно завершаться символами CRLF, т.е. перевод каретки, затем перевод строки. Однако другой документ — RFC 2616 — "рекомендует" игнорировать символ CR и обращать внимание только на LF. Вот и получается, что одни приложения работают по первому стандарту, другие — по второму. Чтобы исправить положение, необходимо в папке с проектом создать файл "app.config" (если он есть — дописать в него) со следующим текстом:
Пора проверить нашу программу. Запускаем, вводим в поле "Начальный адрес" какой-нибудь адрес (например, " http://yandex.ru") и нажимаем "Грабить!". Вот так получилось у меня (рис. 2). Красиво и правильно получилось. Но стоит ввести адрес, например, http://mail.ru, как мы тут же получим исключение с невнятным текстом "The server committed a protocol violation. Section=ResponseHeader Detail=CR must be followed by LF" и вывалимся в отладчик студии. Проблема в следующем: согласно документу RFC 822, любое интернет-сообщение должно завершаться символами CRLF, т.е. перевод каретки, затем перевод строки. Однако другой документ — RFC 2616 — "рекомендует" игнорировать символ CR и обращать внимание только на LF. Вот и получается, что одни приложения работают по первому стандарту, другие — по второму. Чтобы исправить положение, необходимо в папке с проектом создать файл "app.config" (если он есть — дописать в него) со следующим текстом:
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<configSections>
</configSections>
<system.net>
<settings>
<httpWebRequest useUnsafeHeaderParsing="true" />
</settings>
</system.net>
</configuration>
А затем добавить его в проект (Add Existing Item). После этого все сайты будут обрабатываться корректно. Программа в основном готова, но разве интересно вводить адреса вручную? А у нас и в плане записано: "циклический проход". Так сделаем его. Сначала объявим глобальную переменную count типа int, в которой будем хранить количество проходов. Затем возвращаемся в обработчик события нажатия кнопки и дописываем после уже имеющейся там строчки:
count = Int32.Parse(textBox2.Text);
timer1.Enabled = true;
Сначала мы узнаем, сколько проходов нам надо сделать, затем активируем таймер. Теперь заходим в обработчик события таймера и пишем:
if (--count > 0)
Execute(richTextBox1.Lines[new Random(2343).Next(richTextBox1.Lines.Length — 1)]);
else
timer1.Enabled = false;
Ничего особо мудреного: уменьшаем счетчик, сравниваем его с нулем; если он больше нуля, то выбираем случайную строку из нашего списка и вызываем для нее нашу функцию сборки, иначе выключаем таймер. И последняя тонкость. Дело в том, что полученная нами ссылка может вести на несуществующую страницу. Естественно, программа не сможет ее обработать и покроет нас трехэтажным исключением. Поскольку у нас может быть оочеень много ссылок, и нет ничего страшного, если одна будет нерабочая, мы должны объяснить программе, что ее притензии нас не волнуют. Сделать это можно, если взять все содержимое функции Execute в блок try..catch:
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(new Uri(Victim));
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream responseStream = response.GetResponseStream();
StreamReader rdr = new StreamReader(responseStream);
Regex re = new Regex(RegExForURL);
foreach (Match url in re.Matches(rdr.ReadToEnd()))
{
if (new Regex(url.Value).Matches(richTextBox1.Text).Count == 0)
richTextBox1.AppendText(url.Value + "\n");
}
}
catch
{
}
Теперь исключения будут "проглатываться" функцией, и наш паровоз не остановится на полном ходу. Кстати, отлавливая определенное исключение в блоке catch, можно сделать отсеивание мертвых ссылок. Итак, программа готова. Для теста вбивай сайт http://www.milliondollarhomepage.com/ и ставь побольше проходов. Только сразу придумай, чем будешь платить за трафик;). Для увеличения удобства и производительности результаты можно писать в базу данных, но об этом расскажу как-нибудь потом, поскольку с одной базой возни больше, чем со всей остальной программой (зато это отличная возможность научиться работать с БД).
PainKiller, q@sa-sec.org, SASecurity gr.
private void Execute(string Victim)
{
}
В этой функции и будет выполняться выдергивание адресов.Параметр Victim — адрес страницы, из которой в данный момент выдергиваются адреса. Едем дальше. Чтобы получить страницу, мы должны послать запрос. Для этого нужно создать объект типа HttpWebRequest и через объект типа Uri объснить ему, запрос на какую страницу мы будем посылать. Подключаем пространство имен System.Net и пишем:
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(new Uri(Victim));
Теперь нужно отправить этот запрос и получить ответ на него. В этом нам поможет объект типа HttpWebResponse.
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Все, ответ у нас есть. И в этом ответе — HTML-код странички, которую мы попросили. Если будешь писать свой движок для браузера, с этого и начнешь. Но ответ этот еще надо получить в читаемой форме. Для этого прочитаем его в поток (объект типа Stream), а из потока — "читальщиком потоков" (дословный перевод типа StreamReade).
Stream responseStream = response.GetResponseStream();
StreamReader rdr = new StreamReader(responseStream);
Предварительно подключим пространство имен System.IO. Это пока еще не чистый текст, но до него один шаг — метод ReadToEnd() объекта rdr. Теперь нужно вырезать ссылки. Для этого воспользуемся регулярными выражениями. Грубо говоря, регулярное выражение — это некий шаблон для поиска информации определенного типа в тексте. Возвращаясь к спам-спайдерам: простеший спайдер должен уметь вырезать из текста строки типа: какие- то_символы@еще_символы.снова_символы. Если тебе нужно найти на своем жестком диске все файлы типа doc, ты пишешь в поиске "*.doc" — это тоже регулярное выражение. Досконально объяснять синтаксис регулярных выражений я не буду. Я покажу пример для поиска всех http-ссылок, остальное ты легко добавишь сам. Итак, для удобства запишем наше регулярное выражение в константу:
private string RegExForURL = " http://[a-zA-Z1-9//.]*";
Несколько слов по этому выражению:
1) "наши" строки начинаются с " http://" — нормальная ссылка на веб-документ;
2) далее может следовать строчная/прописная буква или точка; набор возможных символов следует писать в квадратных скобках; точка является частью синтаксиса регулярных выражений, поэтому ее надо "экранировать", т.е. поставить перед ней обратный слэш \, но, поскольку пишем мы на Си (пусть и Шарп), ставить необходимо два обратных слэша;
3) то, что мы написали в квадратных скобках — это относится лишь к одному символу, стоящему после "httр://" (т.е. один символ может быть или буквой, или точкой), но, поскольку адресов из одной буквы не бывает, мы должны поставить после скобки звездочку, показывая, что таких символов может быть сколь угодно много.
Теперь необходимо пройтись по тексту странички и вырезать из него все строки, подпадающие под наш шаблон. Для этого создаем объект типа RegEx (не забыв предварительно подключить пространство имен System.Text.RegularExpressions) и пробагаем по тексту:
Regex re = new Regex(RegExForURL);
foreach (Match url in re.Matches(rdr.ReadToEnd()))
{
if (new Regex(url.Value).Matches(richTextBox1.Text).Count == 0)
richTextBox1.AppendText(url.Value + "\n");
}
Сначала создаем объет "регулярное выражение", передавая в качестве параметра конструктора текст выражения. Затем говорим примерно следующее: "Для каждого найденнего совпадения: заносим совпадение в переменную url" (подробнее про конструкцию foreach читай в учебниках по C#). Совпадение в виде текста содержится в свойстве Value объекта url. Условие внутри цикла foreach реализует один из пунктов нашего плана — отсеивание одинаковых адресов. При помощи регулярного выражения, которым является найденный нами адрес, я проверяю, есть ли такой адрес в нашем списке (дословно: я проверяю количество совпадений; если оно равно 0 — значит, такого адреса еще не было). Если такого адреса не было, я заношу его в список, добавляя в конце символ перевода строки, чтобы адреса шли в столбик. По большому счету, осталось добавить всего одну строчку. Создавай обработчик события Click нашей кнопки и пиши там:
private void button1_Click(object sender, EventArgs e)
{
Execute(textBox1.Text);
}
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<configSections>
</configSections>
<system.net>
<settings>
<httpWebRequest useUnsafeHeaderParsing="true" />
</settings>
</system.net>
</configuration>
А затем добавить его в проект (Add Existing Item). После этого все сайты будут обрабатываться корректно. Программа в основном готова, но разве интересно вводить адреса вручную? А у нас и в плане записано: "циклический проход". Так сделаем его. Сначала объявим глобальную переменную count типа int, в которой будем хранить количество проходов. Затем возвращаемся в обработчик события нажатия кнопки и дописываем после уже имеющейся там строчки:
count = Int32.Parse(textBox2.Text);
timer1.Enabled = true;
Сначала мы узнаем, сколько проходов нам надо сделать, затем активируем таймер. Теперь заходим в обработчик события таймера и пишем:
if (--count > 0)
Execute(richTextBox1.Lines[new Random(2343).Next(richTextBox1.Lines.Length — 1)]);
else
timer1.Enabled = false;
Ничего особо мудреного: уменьшаем счетчик, сравниваем его с нулем; если он больше нуля, то выбираем случайную строку из нашего списка и вызываем для нее нашу функцию сборки, иначе выключаем таймер. И последняя тонкость. Дело в том, что полученная нами ссылка может вести на несуществующую страницу. Естественно, программа не сможет ее обработать и покроет нас трехэтажным исключением. Поскольку у нас может быть оочеень много ссылок, и нет ничего страшного, если одна будет нерабочая, мы должны объяснить программе, что ее притензии нас не волнуют. Сделать это можно, если взять все содержимое функции Execute в блок try..catch:
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(new Uri(Victim));
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream responseStream = response.GetResponseStream();
StreamReader rdr = new StreamReader(responseStream);
Regex re = new Regex(RegExForURL);
foreach (Match url in re.Matches(rdr.ReadToEnd()))
{
if (new Regex(url.Value).Matches(richTextBox1.Text).Count == 0)
richTextBox1.AppendText(url.Value + "\n");
}
}
catch
{
}
Теперь исключения будут "проглатываться" функцией, и наш паровоз не остановится на полном ходу. Кстати, отлавливая определенное исключение в блоке catch, можно сделать отсеивание мертвых ссылок. Итак, программа готова. Для теста вбивай сайт http://www.milliondollarhomepage.com/ и ставь побольше проходов. Только сразу придумай, чем будешь платить за трафик;). Для увеличения удобства и производительности результаты можно писать в базу данных, но об этом расскажу как-нибудь потом, поскольку с одной базой возни больше, чем со всей остальной программой (зато это отличная возможность научиться работать с БД).
PainKiller, q@sa-sec.org, SASecurity gr.
Компьютерная газета. Статья была опубликована в номере 15 за 2008 год в рубрике интернет
