
Системы управления версиями для программистов, и не только. Часть 1
Я полагаю, что многие из тех, кто занят в сфере информационных технологий, слышали про системы управления версиями. Вот только список тех, кто активно использует эту технологию в своей практике, гораздо короче. Часто говорят, что системы управления версиями (далее СУВ) нужны только программистам, и только тем из них, кто работает в команде. Т.е. когда кодом владеет не один "избранный", а любой программист в команде может взять и внести в него изменения. Говорят, что разобраться в СУВ практически невозможно: все эти ветки, ревизии, теги, репозитории слишком сложны и непонятны. Я же, наоборот, утверждаю, что разобраться с СУВ очень легко, а после того, как вы поработали с СУВ несколько дней и перешли на новое рабочее место, где нет какой-либо из СУВ, у вас начнется настоящая ломка и боязнь, "как бы не запортить этот код". Это похоже на то, как если бы вы были монтажником-высотником, и у вас резко отняли страховочный пояс. Конечно, ваши "крутые" коллеги, предпочитающие жить без лишней страховки, могут смеяться над вами, но только до тех пор, пока кто-то из них не сорвется и не полетит вниз головой. Заканчивая столь занимательную аналогию, хочу сказать, что для того, чтобы получить настоящее удовольствие от работы с СУВ, необходимо, чтобы ваша среда разработки (среда написания кода, графический или какой-то еще редактор) поддерживали СУВ напрямую. Но даже если это не так, то на рынке достаточно много как платных, так и бесплатных программ для работы с СУВ, похожих на привычный вам total commander или непосредственно интегрирующихся в проводник windows. Из собственного опыта я могу вспомнить случай, когда научил девушек-секретарш хранить офисные файлы в svn- репозитории, и они были страшно довольны открывшимися возможностями.
Итак, что такое СУВ? СУВ — это программа, которая упрощает работу с постоянно меняющимися файлами (как текстовыми, так и двоичными). Существует некоторое "безопасное" место, где хранятся ваши документы. Каждый раз, когда вы создаете новую версию некоторого файла, он сохраняется не только на вашем компьютере, но и в этом репозитории, и ничего не теряется. "И всего-то?" — скажете вы. Ведь я и сам могу создавать копию своих файлов в конце рабочего дня. Да, можете, но единое место хранения, за которое отвечает специально выделенный сотрудник (системный администратор), гораздо лучше в плане надежности и резервного копирования. Централизованное хранилище кода очень удобно в ситуации, когда вы хотите что-то показать вашему другу, находящемуся в другой комнате: "эй, вот здесь в файле X.java в ревизии номер 999 странная ошибка — ты знаешь, что это может быть?" Ваш друг за пару кликов мышью извлекает из репозитория ваш пример и подсказывает, в чем дело. Это гораздо лучше, чем просить друга расшарить сетевую папку и затем копировать в нее файлы. В практике системы СУВ редко используются сами по себе — часто они интегрируются с другими системами, поддерживающими жизненный цикл разрабатываемой программы: средства моделирования, ведения журналов ошибок, написания документации и тестирования. Однако сегодня я говорю только о СУВ. Централизованное хранилище позволит вам легче "играться" с кодом. Например, вы создали новую версию программы (состоящую из трех файлов: A, B, C). Затем вы решили поэкспериментировать и внести изменения в один из них. Вы создаете резервную копию этого файла и делаете правки, которые затрагивают также файлы B и C (ну забылись вы, с кем не бывает). Затем, "поигравшись", вы решаете отменить изменения и замещаете файл A старой версией… Стоп, я же забыл сделать копию файлов B и C (надо было делать копию всего проекта — надеюсь, он не слишком большой). Еще раз стоп… Часть изменений, которые я внес в экспериментальную версию, могут пригодиться чуть позже: их нельзя потерять (сохраним их под именем "A12_new_4.java" и постараемся не забыть, что означает это головоломное имя). И чем больше файлов в проекте, и чем более экстремальны методы разработки (я про идеи экстремального программирования с их короткими итерациями), тем больше проблем. А как только код будете писать не только вы один, но и еще несколько человек (и, самое замечательное, если они территориально распределены), то проблемы из снежного кома превращаются в лавину, которая сметает все.
 При коллективной разработке одна из наиболее часто встречающихся проблем — коллизия изменений. К примеру: программист Вася берет из хранилища файл A.java. Затем в то время, пока Вася сосредоточенно думает над кодом, программист Петя также берет из хранилища тот же файл и вносит в него правки, после чего сохраняет файл назад в репозиторий. И как только это было сделано, Вася завершает редактирование своей версии файла A.java и тоже сохраняет ее, затирая при этом все наработки, выполненные предыдущими участниками. Таким образом, СУВ не только играют роль архива, хранящего историю изменений, но и служат для обнаружения конфликтов и не позволяют кому-либо потерять результаты работы. В общем случае есть две методики обеспечения совместной работы двух людей над одним и тем же файлом без конфликтов. Первый подход называется "Lock-Modify-Unlock" ("захвати-отредактируй-освободи"). Здесь, когда программисту Васе нужно выполнить правки в файле, то он его монопольно "захватывает". Грубо говоря, у каждого файла есть флажок "свободен?" При попытке захвата файла значение этого флажка проверяется, затем, если флажок уже установлен (значит, кто-то успел раньше меня захватить файл), операция захвата завершается неудачей. И наш программист должен ждать, пока кто-то закончит редактирование этого файла, сохранит его, "освободит", затем повторить попытку захвата и самому продолжить редактирование. Методика очень проста и… плоха. В проектах со "свободным владением кода" возникают две основные проблемы: "забывчивость" и "лишние блокировки". "Забывчивость" рассмотрим на примере, когда Вася захватил файл и… уехал в отпуск. Значит, мы должны либо ждать, пока Вася вернется из отпуска и разблокирует файл, либо обратиться к администратору репозитория, чтобы он там "что-то подправил руками". Проблема "лишних блокировок" (мне она кажется признаком других проблем в планировании архитектуры проекта, но раз ее часто выделяют в специальной литературе, то расскажу). Предположим, у нас есть большой файл, где хранится текст программы, который состоит из (условно) двух функций: A и B. Программисту Васе нужно внести изменения в функцию A в то время, как программисту Пете — в функцию B. Хотя правки выполнятся над одним и тем же документом, но над разными его функциями (разными частями файла), а, следовательно, теоретически можно совместить работу Васи и Пети. Система "Lock-Modify-Unlock" это не позволяет. Помните, что СУВ не дают гарантии работоспособного кода. Фактически если код редактируется несколькими программистами, то есть вероятность того, что изменения, сделанные одним из них, будут несовместимыми с изменениями другого программиста (в одном файле или в нескольких — не важно). Повторю еще раз: СУВ надо использовать совместно с другими средствами поддержки Жизненного Цикла разрабатываемой программы. Например, если заранее написаны тесты, проверяющие работоспособность программы, и эти тесты запускаются регулярно (в идеале автоматизированно), то менеджер проекта быстро обнаружит, что "программа поломалась", затем глянет в репозиторий и узнает, кто последний вносил правки, и, соответственно, будет знать, кого "назначить виновным".
При коллективной разработке одна из наиболее часто встречающихся проблем — коллизия изменений. К примеру: программист Вася берет из хранилища файл A.java. Затем в то время, пока Вася сосредоточенно думает над кодом, программист Петя также берет из хранилища тот же файл и вносит в него правки, после чего сохраняет файл назад в репозиторий. И как только это было сделано, Вася завершает редактирование своей версии файла A.java и тоже сохраняет ее, затирая при этом все наработки, выполненные предыдущими участниками. Таким образом, СУВ не только играют роль архива, хранящего историю изменений, но и служат для обнаружения конфликтов и не позволяют кому-либо потерять результаты работы. В общем случае есть две методики обеспечения совместной работы двух людей над одним и тем же файлом без конфликтов. Первый подход называется "Lock-Modify-Unlock" ("захвати-отредактируй-освободи"). Здесь, когда программисту Васе нужно выполнить правки в файле, то он его монопольно "захватывает". Грубо говоря, у каждого файла есть флажок "свободен?" При попытке захвата файла значение этого флажка проверяется, затем, если флажок уже установлен (значит, кто-то успел раньше меня захватить файл), операция захвата завершается неудачей. И наш программист должен ждать, пока кто-то закончит редактирование этого файла, сохранит его, "освободит", затем повторить попытку захвата и самому продолжить редактирование. Методика очень проста и… плоха. В проектах со "свободным владением кода" возникают две основные проблемы: "забывчивость" и "лишние блокировки". "Забывчивость" рассмотрим на примере, когда Вася захватил файл и… уехал в отпуск. Значит, мы должны либо ждать, пока Вася вернется из отпуска и разблокирует файл, либо обратиться к администратору репозитория, чтобы он там "что-то подправил руками". Проблема "лишних блокировок" (мне она кажется признаком других проблем в планировании архитектуры проекта, но раз ее часто выделяют в специальной литературе, то расскажу). Предположим, у нас есть большой файл, где хранится текст программы, который состоит из (условно) двух функций: A и B. Программисту Васе нужно внести изменения в функцию A в то время, как программисту Пете — в функцию B. Хотя правки выполнятся над одним и тем же документом, но над разными его функциями (разными частями файла), а, следовательно, теоретически можно совместить работу Васи и Пети. Система "Lock-Modify-Unlock" это не позволяет. Помните, что СУВ не дают гарантии работоспособного кода. Фактически если код редактируется несколькими программистами, то есть вероятность того, что изменения, сделанные одним из них, будут несовместимыми с изменениями другого программиста (в одном файле или в нескольких — не важно). Повторю еще раз: СУВ надо использовать совместно с другими средствами поддержки Жизненного Цикла разрабатываемой программы. Например, если заранее написаны тесты, проверяющие работоспособность программы, и эти тесты запускаются регулярно (в идеале автоматизированно), то менеджер проекта быстро обнаружит, что "программа поломалась", затем глянет в репозиторий и узнает, кто последний вносил правки, и, соответственно, будет знать, кого "назначить виновным".
Вторая стратегия организации коллективной работы называется "Copy-Modify-Merge" ("скопируй себе, измени код, объедини свои изменения с основным проектом"). Рассмотрим сценарий с общим файлом для редактирования и двумя программистами. Вася взял из репозитория файл (просто взял — никаких запретов для других пользователей репозитория не появилось). Затем, пока Вася думает над кодом, Петя также взял из репозитория файл, быстренько внес в него правки и сохранил обратно в репозиторий. Вася тем временем закончил редактировать файл и хочет сохранить его в репозиторий. А он ему и говорит: мол, так и так, пока ты что-то там делал, файл был изменен другим программистом, и я не позволю тебе сохранить файл до тех пор, пока ты не просмотришь выполненные Петей правки и не отредактируешь файл заново. Такой сценарий вовсе не означает, что программисты только тем и занимаются, что разрешают конфликты и изучают чужой код (кстати, очень неплохое занятие). В практике 99% правок выполняются без конфликтов, и только в оставшемся одном проценте вам требуется встать, подойти к столу, где сидит Петя, и обсудить с ним, что с этим конфликтующим кодом делать дальше. А если вы внесли правки в место, отличное от того, где правил Петя, конфликт разрешается еще проще.
Список доступных для использования СУВ достаточно велик, в нем есть платные и бесплатные продукты. Цели, которые ставятся перед СУВ, совпадают лишь в перечне базовых требований (их я описал выше: "безопасность", "все сохранено", "нет конфликтам"). Есть и дополнительные требования, связанные часто со спецификой тех проектов для управления, которым предназначены конкретные СУВ. В своей практике я работал только с SVN и Perforce — вот о них и буду рассказывать. Сегодня я начну рассказ о SVN. На самом деле правильнее называть ее не SVN, а Subversion (дело в том, что svn — название главной утилиты, с помощью которой и выполняется работа с Subversion-репозиторием). Итак: Subversion — это централизованная система (ага, есть и нецентрализованные), в которой хранятся файлы проекта и "всякая всячина" о версиях файлов. Кто, когда и что редактировал, также хранится на сервере. Фактически вы можете придти на любую машину, ввести в командной строке одну-единственную строку, и к вам на компьютер будут скопированы нужные для работы файлы проекта. Давайте разберем основную терминологию: есть "SVN-репозиторий и его адрес", "рабочая копия", "дерево ревизий". Чтобы создать репозиторий и разрешить к нему доступ по сети (на самом деле svn-репозиторий может быть и локальным — только для вас и ни для кого более), нам нужны специальные программы (найти их можно на сайте сайт ). Итак, вы скачали и установили ее в какую-то папку. Затем вы заходите в папку bin и видите там все нужные для работы как svn-сервера, так и svn-клиента программы (в папке doc находится просто замечательная книжка "svn-book.chm" — настоятельно советую использовать ее как справочник, когда что-то не будет получаться). Для удобства работы я добавил в переменную среды окружения PATH путь к каталогу bin. Начнем мы с создания локального репозитория. Для этого нужно запустить следующую команду (все команды администратора SVN формируются по сходному принципу: "svnadmin команда путь_к_репозиторию"):
svnadmin create SVN2
svnadmin create "h:/docs_xp/SVN/"
Две приведенные команды полностью эквивалентны, однако в первом случае предполагается, что каталог репозитория будет создан как подпапка текущего каталога с именем SVN2. Во втором же случае я указал полный путь к каталогу, где будет храниться репозиторий. Хотя наш репозиторий пуст, давайте сразу разберем несколько полезных функций. Прежде всего, проверка репозитория на целостность (в примере предполагается, что я зашел в каталог репозитория, и поэтому могу использовать в качестве пути к репозиторию точку — текущий каталог).
svnadmin verify .
В случае сбоев вы можете восстановить репозиторий с помощью команды "recover" (а вообще не забывайте о резервном копировании, ведь в одном репозитории будут храниться данные всех программистов и, возможно, не одного проекта, так что "смерть" жесткого диска сервера будет страшна). Для переноса репозитория из одного места в другое можно выполнить прямое копирование. Хотя это не самый лучший способ, например, из-за возможных "висящих" блокировок файлов или различных версий svn на источнике и приемнике (маловероятно, т.к. последние версии svn не "грешат" несовместимостью форматов). Кроме того, в ходе переноса имеет смысл избавиться от части "устаревшей" информации (например, сохранить только последние 10 правок файлов). В этом случае вы можете использовать функцию предварительного экспорта содержимого репозитория в специальный файл "dump" с последующим восстановлением из этого файла репозитория на новой машине.
svnadmin dump svn > dumpfile
В результате этой команды вы создадите полную копию репозитория внутри файла dumpfile (файл похож на текстовый — всего лишь похож — его содержимое можно просмотреть с помощью того же блокнота, вот только править и сохранять его не стоит). Затем я импортирую данный файл в другой репозиторий.
svnadmin load svn2 < ../dumpfile
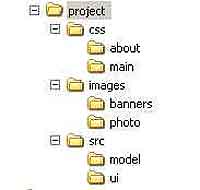
В ходе выполнения этой команды на экран выводится журнал выполняемых действий: какие файлы/каталоги были импортированы. Остальные команды svnadmin имеет смысл рассматривать уже после того, как у нас хранилище будет наполнено содержимым. Для этого я создал псевдопроект со структурой, показанной на рис. 1. В корень каталога project я поместил текстовый файл (about.txt) с кратким примечанием к проекту. Теперь необходимо поместить этот каталог в созданный на предыдущем шаге репозиторий. Это и все последующие действия выполняются с помощью утилиты svn. svn import project file:///h:/docs_xp/SVN/test/project -m"initial import"
Эту команду я выполнил, находясь в каталоге, родительском для project. В ходе импорта внутри хранилища SVN были созданы подкаталоги test и project, куда и были скопированы все файлы проекта. Параметр "-m" служит для указания некоторого текста примечания к создаваемому проекту (комментарий должен быть обязательно). После импорта проекта в репозиторий мы должны его извлечь (этот шаг обязателен). Ради эксперимента удалите каталог project (не бойтесь, все сохранилось) и выполните следующую команду:
svn checkout file:///h:/docs_xp/SVN/test/project
В результате каталог project со всем его содержимым будет воссоздан, а кроме того в каждый из каталогов и подкаталогов проекта еще попадет "странный" каталог с именем ".svn". Не трогайте его: это служебный каталог, внутри которого хранятся сведения о том, из какого репозитория был загружен проект, сведения о текущей ревизии и так называемая "Pristine Copy". Создадим рядом с файлом about.txt еще один файл test.txt с каким- либо текстом, затем внесем внутрь файла about.txt пару строчек текста (имитация редактирования) и удалим каталог css/main. Будем считать, что мы сегодня изрядно поработали и теперь хотим сохранить наработки в репозиторий и пойти домой. Команда commit отправляет изменения в репозиторий с некоторым примечанием:
svn commit project -m"first changes"
Что получилось? Да ошибка получилась, вот такая:
svn: Commit failed (details follow):
svn: Directory 'H:\docs_xp\My temps\svzone\project\css\main' is missing
Дело в том, что проект, обслуживаемый svn — это не просто папка с файлами, с которыми вы что хотите, то и делаете — это часть процесса разработки, и просто так удалить файл, каталог, добавить файл и каталог нельзя. Необходимо сообщить svn-репозиторию о своем намерении удалить или добавить файл — иначе никак. Отменяем удаление каталога css/main, удалив весь каталог project и заново извлекая (checkout) его из репозитория. Теперь делаем все правильно: прежде всего, сообщим svn о намерении удалить каталог.
svn delete project/css/main
D project\css\main
Проверим, удалился ли каталог css/main. Нет, каталог остался на месте. Где-то ошибка? Ошибки нет, т.к. SVN использует понятие "планируемого пожелания". Команды добавления и удаления файлов/каталогов не приводят к непосредственному изменению вашего проекта. Все эти "пожелания" планируются к исполнению спустя некоторое время, и для того, чтобы их выполнить, нужно отправить команду commit (подтверждение изменений).
svn commit project -m"deleted dir"
Deleting project\css\main
Committed revision 14.
Нам сообщили, что операция удаления была выполнена, и текущее состояние проекта было сохранено как ревизия номер 14. Стоп. Так что, каждое изменение (даже удаление одного файла или каталога) приводит к созданию новой копии проекта, ведь так репозиторий скоро станет просто огромного размера? Нет, не станет. В SVN используется хитрая методика хранения информации, когда очередная ревизия является не просто копией файла, а определяется его разницей с предыдущим состоянием. Если вы добавили в файл одну строку, то размер репозитория станет больше не на величину файла, а на размер только одной этой строки. Теперь попробуем добавить новый файл в репозиторий. Попытка просто создать файл test.txt и выполнить команду commit завершится… удачей. Так что, я снова где-то обманываю? Нет, все гораздо хитрее. Хотя команда commit завершилась удачно, но кто сказал, что файл test.txt попал в репозиторий? Файла на самом деле нет. Попробуйте для проверки удалить проект и заново извлечь его из репозитория. Файл появился? То-то же, нам нужно после физического создания нового файла сообщить svn, что этот файл тоже является частью проекта и должен быть помещен в репозиторий. Такой подход, несмотря на некоторое неудобство, оправдан, т.к. часто в состав проекта входят файлы, которые хранить в репозитории не имеет смысла или из-за их гигантского размера, или из-за того, что этот файл формируется динамически, или что-то еще. Пробуем добавить файл и сохранить изменения — теперь все должно получиться:
svn add project/test.txt
A project\test.txt
svn commit project -m"new file"
Adding project\test.txt
Transmitting file data .
Committed revision 15.
В следующий раз я продолжу рассказ о SVN, и мы рассмотрим методики правки файлов, обнаружения коллизий и разрешения конфликтов.
black-zorro@tut.by, black-zorro.com
Итак, что такое СУВ? СУВ — это программа, которая упрощает работу с постоянно меняющимися файлами (как текстовыми, так и двоичными). Существует некоторое "безопасное" место, где хранятся ваши документы. Каждый раз, когда вы создаете новую версию некоторого файла, он сохраняется не только на вашем компьютере, но и в этом репозитории, и ничего не теряется. "И всего-то?" — скажете вы. Ведь я и сам могу создавать копию своих файлов в конце рабочего дня. Да, можете, но единое место хранения, за которое отвечает специально выделенный сотрудник (системный администратор), гораздо лучше в плане надежности и резервного копирования. Централизованное хранилище кода очень удобно в ситуации, когда вы хотите что-то показать вашему другу, находящемуся в другой комнате: "эй, вот здесь в файле X.java в ревизии номер 999 странная ошибка — ты знаешь, что это может быть?" Ваш друг за пару кликов мышью извлекает из репозитория ваш пример и подсказывает, в чем дело. Это гораздо лучше, чем просить друга расшарить сетевую папку и затем копировать в нее файлы. В практике системы СУВ редко используются сами по себе — часто они интегрируются с другими системами, поддерживающими жизненный цикл разрабатываемой программы: средства моделирования, ведения журналов ошибок, написания документации и тестирования. Однако сегодня я говорю только о СУВ. Централизованное хранилище позволит вам легче "играться" с кодом. Например, вы создали новую версию программы (состоящую из трех файлов: A, B, C). Затем вы решили поэкспериментировать и внести изменения в один из них. Вы создаете резервную копию этого файла и делаете правки, которые затрагивают также файлы B и C (ну забылись вы, с кем не бывает). Затем, "поигравшись", вы решаете отменить изменения и замещаете файл A старой версией… Стоп, я же забыл сделать копию файлов B и C (надо было делать копию всего проекта — надеюсь, он не слишком большой). Еще раз стоп… Часть изменений, которые я внес в экспериментальную версию, могут пригодиться чуть позже: их нельзя потерять (сохраним их под именем "A12_new_4.java" и постараемся не забыть, что означает это головоломное имя). И чем больше файлов в проекте, и чем более экстремальны методы разработки (я про идеи экстремального программирования с их короткими итерациями), тем больше проблем. А как только код будете писать не только вы один, но и еще несколько человек (и, самое замечательное, если они территориально распределены), то проблемы из снежного кома превращаются в лавину, которая сметает все.
Вторая стратегия организации коллективной работы называется "Copy-Modify-Merge" ("скопируй себе, измени код, объедини свои изменения с основным проектом"). Рассмотрим сценарий с общим файлом для редактирования и двумя программистами. Вася взял из репозитория файл (просто взял — никаких запретов для других пользователей репозитория не появилось). Затем, пока Вася думает над кодом, Петя также взял из репозитория файл, быстренько внес в него правки и сохранил обратно в репозиторий. Вася тем временем закончил редактировать файл и хочет сохранить его в репозиторий. А он ему и говорит: мол, так и так, пока ты что-то там делал, файл был изменен другим программистом, и я не позволю тебе сохранить файл до тех пор, пока ты не просмотришь выполненные Петей правки и не отредактируешь файл заново. Такой сценарий вовсе не означает, что программисты только тем и занимаются, что разрешают конфликты и изучают чужой код (кстати, очень неплохое занятие). В практике 99% правок выполняются без конфликтов, и только в оставшемся одном проценте вам требуется встать, подойти к столу, где сидит Петя, и обсудить с ним, что с этим конфликтующим кодом делать дальше. А если вы внесли правки в место, отличное от того, где правил Петя, конфликт разрешается еще проще.
Список доступных для использования СУВ достаточно велик, в нем есть платные и бесплатные продукты. Цели, которые ставятся перед СУВ, совпадают лишь в перечне базовых требований (их я описал выше: "безопасность", "все сохранено", "нет конфликтам"). Есть и дополнительные требования, связанные часто со спецификой тех проектов для управления, которым предназначены конкретные СУВ. В своей практике я работал только с SVN и Perforce — вот о них и буду рассказывать. Сегодня я начну рассказ о SVN. На самом деле правильнее называть ее не SVN, а Subversion (дело в том, что svn — название главной утилиты, с помощью которой и выполняется работа с Subversion-репозиторием). Итак: Subversion — это централизованная система (ага, есть и нецентрализованные), в которой хранятся файлы проекта и "всякая всячина" о версиях файлов. Кто, когда и что редактировал, также хранится на сервере. Фактически вы можете придти на любую машину, ввести в командной строке одну-единственную строку, и к вам на компьютер будут скопированы нужные для работы файлы проекта. Давайте разберем основную терминологию: есть "SVN-репозиторий и его адрес", "рабочая копия", "дерево ревизий". Чтобы создать репозиторий и разрешить к нему доступ по сети (на самом деле svn-репозиторий может быть и локальным — только для вас и ни для кого более), нам нужны специальные программы (найти их можно на сайте сайт ). Итак, вы скачали и установили ее в какую-то папку. Затем вы заходите в папку bin и видите там все нужные для работы как svn-сервера, так и svn-клиента программы (в папке doc находится просто замечательная книжка "svn-book.chm" — настоятельно советую использовать ее как справочник, когда что-то не будет получаться). Для удобства работы я добавил в переменную среды окружения PATH путь к каталогу bin. Начнем мы с создания локального репозитория. Для этого нужно запустить следующую команду (все команды администратора SVN формируются по сходному принципу: "svnadmin команда путь_к_репозиторию"):
svnadmin create SVN2
svnadmin create "h:/docs_xp/SVN/"
Две приведенные команды полностью эквивалентны, однако в первом случае предполагается, что каталог репозитория будет создан как подпапка текущего каталога с именем SVN2. Во втором же случае я указал полный путь к каталогу, где будет храниться репозиторий. Хотя наш репозиторий пуст, давайте сразу разберем несколько полезных функций. Прежде всего, проверка репозитория на целостность (в примере предполагается, что я зашел в каталог репозитория, и поэтому могу использовать в качестве пути к репозиторию точку — текущий каталог).
svnadmin verify .
В случае сбоев вы можете восстановить репозиторий с помощью команды "recover" (а вообще не забывайте о резервном копировании, ведь в одном репозитории будут храниться данные всех программистов и, возможно, не одного проекта, так что "смерть" жесткого диска сервера будет страшна). Для переноса репозитория из одного места в другое можно выполнить прямое копирование. Хотя это не самый лучший способ, например, из-за возможных "висящих" блокировок файлов или различных версий svn на источнике и приемнике (маловероятно, т.к. последние версии svn не "грешат" несовместимостью форматов). Кроме того, в ходе переноса имеет смысл избавиться от части "устаревшей" информации (например, сохранить только последние 10 правок файлов). В этом случае вы можете использовать функцию предварительного экспорта содержимого репозитория в специальный файл "dump" с последующим восстановлением из этого файла репозитория на новой машине.
svnadmin dump svn > dumpfile
В результате этой команды вы создадите полную копию репозитория внутри файла dumpfile (файл похож на текстовый — всего лишь похож — его содержимое можно просмотреть с помощью того же блокнота, вот только править и сохранять его не стоит). Затем я импортирую данный файл в другой репозиторий.
svnadmin load svn2 < ../dumpfile
В ходе выполнения этой команды на экран выводится журнал выполняемых действий: какие файлы/каталоги были импортированы. Остальные команды svnadmin имеет смысл рассматривать уже после того, как у нас хранилище будет наполнено содержимым. Для этого я создал псевдопроект со структурой, показанной на рис. 1. В корень каталога project я поместил текстовый файл (about.txt) с кратким примечанием к проекту. Теперь необходимо поместить этот каталог в созданный на предыдущем шаге репозиторий. Это и все последующие действия выполняются с помощью утилиты svn. svn import project file:///h:/docs_xp/SVN/test/project -m"initial import"
Эту команду я выполнил, находясь в каталоге, родительском для project. В ходе импорта внутри хранилища SVN были созданы подкаталоги test и project, куда и были скопированы все файлы проекта. Параметр "-m" служит для указания некоторого текста примечания к создаваемому проекту (комментарий должен быть обязательно). После импорта проекта в репозиторий мы должны его извлечь (этот шаг обязателен). Ради эксперимента удалите каталог project (не бойтесь, все сохранилось) и выполните следующую команду:
svn checkout file:///h:/docs_xp/SVN/test/project
В результате каталог project со всем его содержимым будет воссоздан, а кроме того в каждый из каталогов и подкаталогов проекта еще попадет "странный" каталог с именем ".svn". Не трогайте его: это служебный каталог, внутри которого хранятся сведения о том, из какого репозитория был загружен проект, сведения о текущей ревизии и так называемая "Pristine Copy". Создадим рядом с файлом about.txt еще один файл test.txt с каким- либо текстом, затем внесем внутрь файла about.txt пару строчек текста (имитация редактирования) и удалим каталог css/main. Будем считать, что мы сегодня изрядно поработали и теперь хотим сохранить наработки в репозиторий и пойти домой. Команда commit отправляет изменения в репозиторий с некоторым примечанием:
svn commit project -m"first changes"
Что получилось? Да ошибка получилась, вот такая:
svn: Commit failed (details follow):
svn: Directory 'H:\docs_xp\My temps\svzone\project\css\main' is missing
Дело в том, что проект, обслуживаемый svn — это не просто папка с файлами, с которыми вы что хотите, то и делаете — это часть процесса разработки, и просто так удалить файл, каталог, добавить файл и каталог нельзя. Необходимо сообщить svn-репозиторию о своем намерении удалить или добавить файл — иначе никак. Отменяем удаление каталога css/main, удалив весь каталог project и заново извлекая (checkout) его из репозитория. Теперь делаем все правильно: прежде всего, сообщим svn о намерении удалить каталог.
svn delete project/css/main
D project\css\main
Проверим, удалился ли каталог css/main. Нет, каталог остался на месте. Где-то ошибка? Ошибки нет, т.к. SVN использует понятие "планируемого пожелания". Команды добавления и удаления файлов/каталогов не приводят к непосредственному изменению вашего проекта. Все эти "пожелания" планируются к исполнению спустя некоторое время, и для того, чтобы их выполнить, нужно отправить команду commit (подтверждение изменений).
svn commit project -m"deleted dir"
Deleting project\css\main
Committed revision 14.
Нам сообщили, что операция удаления была выполнена, и текущее состояние проекта было сохранено как ревизия номер 14. Стоп. Так что, каждое изменение (даже удаление одного файла или каталога) приводит к созданию новой копии проекта, ведь так репозиторий скоро станет просто огромного размера? Нет, не станет. В SVN используется хитрая методика хранения информации, когда очередная ревизия является не просто копией файла, а определяется его разницей с предыдущим состоянием. Если вы добавили в файл одну строку, то размер репозитория станет больше не на величину файла, а на размер только одной этой строки. Теперь попробуем добавить новый файл в репозиторий. Попытка просто создать файл test.txt и выполнить команду commit завершится… удачей. Так что, я снова где-то обманываю? Нет, все гораздо хитрее. Хотя команда commit завершилась удачно, но кто сказал, что файл test.txt попал в репозиторий? Файла на самом деле нет. Попробуйте для проверки удалить проект и заново извлечь его из репозитория. Файл появился? То-то же, нам нужно после физического создания нового файла сообщить svn, что этот файл тоже является частью проекта и должен быть помещен в репозиторий. Такой подход, несмотря на некоторое неудобство, оправдан, т.к. часто в состав проекта входят файлы, которые хранить в репозитории не имеет смысла или из-за их гигантского размера, или из-за того, что этот файл формируется динамически, или что-то еще. Пробуем добавить файл и сохранить изменения — теперь все должно получиться:
svn add project/test.txt
A project\test.txt
svn commit project -m"new file"
Adding project\test.txt
Transmitting file data .
Committed revision 15.
В следующий раз я продолжу рассказ о SVN, и мы рассмотрим методики правки файлов, обнаружения коллизий и разрешения конфликтов.
black-zorro@tut.by, black-zorro.com
Компьютерная газета. Статья была опубликована в номере 12 за 2008 год в рубрике программирование
