
Семантическая Паутина. Часть 1
Прогресс в IT похож на морские приливы: сначала волна энтузиазма штурмует берег обыденности и коммерческой целесообразности. Затем, будучи не в силах удержаться, волна отходит назад, с тем, чтобы набраться сил и спустя некоторое время попробовать еще раз захватить плацдарм. Сегодня я хочу поговорить о Семантической Паутине и микроформатах.
В начале 2000-х годов я впервые услышал об идее, которую пропагандировал Тим Бернерс-Ли. Это была идея Семантической Паутины (Semantiс Web) и о том, как она изменит привычный нам интернет. Не секрет, что с самых первых дней развития интернет предпринимались попытки создать такой способ представления информации в нем, чтобы указывать на ее логическое значение - что же хранится в том или ином абзаце или таблице. Придумали теги - такие, как STRONG, EM - они должны были играть роль указателей на то, что какие-то части веб-страницы имеют более важное значение, дать акцент на них. Или, например, тег сITE, который должен был служить для хранения цитат или сносок на другую информацию. Тег AсRONYM мог бы указать на… акронимы. Или тег ADDRESS, который должен был бы хранить информацию об авторе документа. Все эти теги не только имели особые шрифты или отступы, но прежде всего должны были дать больше "информации об информации" поисковым машинам и браузерам. А теперь положа руку на сердце признайтесь: кто из вас слышал и тем более использовал эти возможности? Во всевозможных книжках про веб-программирование и верстку говорят прежде всего о том, как создать какой-то красивый эффект, как сделать, чтобы что-то мигало, вертелось и двигалось. Все теги, о которых я упомянул выше (EM, сITE, AсRONYM), пали жертвой ряда обстоятельств: отшумевшая война браузеров, слабые визуальные возможности html заставляли использовать эти теги прежде всего для визуального оформления, не обращая внимания на их логический смысл. Эти теги были первой робкой попыткой сделать интернет более целостным - что же… покойтесь с миром. Первоначальный этап, когда при разработке сайтов говорили только о его визуальном наполнении, картинках, Flash-роликах, прошел. Конечно, и сейчас визуальное оформление является важнейшим фактором, но по мере увеличения количества людей, постоянно пользующихся интернетом, роста широкополосных сетей, бума социальных сетей, по мере того, как интернет становится все более близким для "домохозяек", и появления новых моделей коммерции в интернет, произошел возврат к старым идеям и попытка их реализовать на новой технологической базе.
Представьте себе сценарий, что информацию, размещенную на веб-страницах, смогут обрабатывать компьютеры, смогут строить сложные пути поиска и делать выводы (с минимальным участием человека). Например, вы ввели в поисковую строку слово "молоко", а вам в ответ вернули список магазинов, где его можно купить, с учетом ваших личных предпочтений и маршрута домой. А еще неплохо, если ваш компьютер свяжется с сайтом магазина и зарезервирует для вас пару пакетов молока. Это, конечно, шутка и мечта, но она становится ближе. Никто не говорит, что с появлением семантического Веб появится тот самый многострадальный искусственный интеллект: компьютеры никогда не смогут выполнять анализ текста на странице - максимум, что мы можем сделать - это добавить к публикуемой информации помимо визуального оформления (нужного для восприятия страницы человеком) немножко той информации, которую будет понимать и компьютер. Вот только для того, чтобы некоторая программа (ее называют семантический агент) могла выполнить подобные действия, необходимо, чтобы вся опубликованная информация в интернет была бы взаимосвязана, но не так, как сейчас - ссылками на другую страницу. Необходимо сделать так, чтобы программы не только находили ключевые слова, но и могли определить их значение. Если на странице встречается имя "Вася Пупкин", то это персональная страница Васи с его биографией или же здесь соседка Васи жалуется, какой же он бессовестный и включает музыку по ночам, и вообще это тот самый Вася Пупкин, что нам нужен, или нет? Нам нужны другие механизмы связывания страниц, также нужны способы публикации на сайте сведений о том, какие запросы можно к нему делать. Например, сайт молочного магазина мог бы представить всем заинтересованным веб-приложениям описание того, как нужно выполнить запрос к некоторому размещенному на сайте скрипту, выполняющему функции проверки наличия товара и его резервирования (передать название товара, его желаемую цену и количество единиц товара).
Семантическая Паутина тесно связана с понятием семантической сети - способа представления информации об устройстве некоторой предметной области. С точки зрения математики он представляется в виде графа, вершинами которого являются некоторые понятия (люди, документы, события), а дуги указывают на отношения, существующие между этими понятиями. Основной упор в Семантическом Web делается на метаинформацию (информацию об информации). Она должна потеснить с трона используемый сейчас метод поиска информации в интернет, основанный на анализе текста веб-страниц. Для продвижения идей Semantiс Web были сформированы новые стандарты. К счастью, разработавший их консорциум W3с не допустил классической ошибки, решив заменить существующие технологии - вместо этого новые форматы строятся на известных и опробованных в интернет технологиях - таких, как httр, xml, xml sсhema. И, что самое главное, в последнее время произошел переход теории в практику, когда многие популярные веб-сайты начали при публикации информации выполнять ее разметку в соответствии с идеями Semantiс Web. Поддержка появилась и в бесплатном web-инструментарии: движках сайтов, блогов, веб-служб. Это очень важный момент, т.к. тогда семантическую информацию будет публиковать не "продвинутый гик", а обычный человек, вообще ничего и никогда не слышавший о Семантической Сети и лежащих в ее основе технологиях: все нужные теги будут сформированы автоматически. Пирамида семантической пирамиды строится на основе трех форматов: XML (extensible markuр language), RDF (Resourсe Desсriрtion Framework) и OWL (Web Ontology Language). Как вы знаете, язык XML позволяет создавать собственные теги, несущие особое значение - например, вы могли бы внедрить в текст вашей веб-страницы (в недалеком будущем, имеется в виду) такие теги, как "<resume>", "<friends>" или "<address>", для хранения информации о вашем адресе, друзьях или резюме. Вот только как машина сможет эти придуманные вами теги проанализировать и понять, что же в них хранится? Здесь поможет формат RDF. В основе RDF лежит идея, что, используя специального вида утверждения, мы можем описать некоторый объект. Каждое из высказываний строится по схеме "субъект — отношение — объект" (подлежащее, сказуемое и дополнение) и в терминологии RDF называется триплетом. Например, утверждение "Вася любит пиво" будет представлено в стиле RDF как следующая тройка: субъект — "Вася"; отношение — "любит"; объект — "пиво". В свою очередь, объект "пиво" может учавствовать еще в одном отношении - например: "Древние вавилоняне варили пиво". Остается только догадываться, что такое пиво и кто такой Вася, а также какая связь между древними вавилонянами и Васей. Для идентификации субъектов, предикатов и объектов в RDF используются URI (Uniform Resourсe Identifier). URI – это основа сегодняшнего интернет, но пока используется только для представления адресов веб-страниц, в перспективе же возможно указать с помощью URI на географический регион, улицу, человека. Надо только договориться об используемых форматах кодирования такой информации. Более того, и в качестве "отношения" также может выступать URI (указывая на какой-то адрес в сети), и, таким образом, мы можем определять новые и новые отношения. Надо сказать, что с помощью RDF мы можем записывать и более сложные отношения - например, четверка "Васин друг Петя не любит пиво" будет записана как две тройки понятий: "Петя друг Васи", "Петя не любит пиво". Такая форма записи вызвала у меня дежа вю с экспертными системами, как и у многих из тех, кто учился в технических вузах и сталкивался с понятием логических языков программирования (приснопамятный рrolog). Можно считать, что Semantiс Web - это попытка применить наработанный опыт построения экспертных систем в интернет без прошлых ошибок. Естественно, что не все отношения можно записать в виде троек, например, в случае, когда отношение имеет смысл только при наличии ряда условий: "Вася не пьет пиво, если идет дождь". Но все эти вопросы уже решаются с помощью смежных с RDF технологий. При записи троек высказываний в RDF возникает очень скользкий момент: кто будет заниматься созданием тех самых терминов, определений, и кто будет контролировать, соответствуют ли они тем понятиям, которые в них вкладывают определенные люди? В человеческом языке существует множество одинаковых слов, которые имеют разные значения, и, наоборот, в разных странах и народах значения этих слов могут варьироваться. Поэтому было принято решение, что не нужно загонять всех в жесткие рамки терминологии, а нужно сосредоточиться на создании средств "связывания понятий". Возможно, на двух сайтах будут использованы различные термины для обозначения схожих понятий. Нам нужно, чтобы семантический агент умел распознавать подобные термины, и сделать это можно с помощью онтологии. В мире IT под онтологией понимают способ задать отношения, существующие между некоторыми объектами. Наиболее часто для этого используется таксономия. С помощью таксономии мы можем определить классы, на которые делятся объекты некоторой предметной области, а также то, какие отношения существуют между этими классами. С помощью таксономии мы иерархически выстраиваем некоторую цепочку между понятиями. Например, вернувшись к примеру с Васей и пивом, мы можем сказать, что пиво - это родовое понятие, и от него отходят такие разновидности, как безалкогольное пиво, темное, светлое, можно ввести понятие градуса или того материала, который, помимо ячменного солода, добавляется при изготовлении пива - например, пшеничное, рисовое, кукурузное (это будут атрибуты класса). Каждая из разновидностей пива наследует свойства своего родителя и может содержать собственные атрибуты. Благодаря системе выводов мы можем сказать, что существует связь между Васей и темным пивом, а также есть влияние используемых материалов на то, какой будет вкус. Возможно, это звучит смешно, но для компьютеров это будет огромным шагом. Естественно, Москва не сразу строилась, и какое-то время страницы, содержащие ссылки на онтологию некоторого понятия, в лучшем случае могут быть использованы поисковыми машинами для того, чтобы лучше искать запрошенную вами информацию, а не просто находить страницы, где встретилось (возможно, без всякого контекста) упомянутое вами слово.
RDF – это язык описания отношений, для которого существует несколько различных форматов представления. Наиболее известны Нотация Три (N3) и XML- подобная форма записи. Мы можем писать код руками или использовать специальные инструменты (по правде говоря, таких программ еще очень мало). Как стандарт RDF был принят в начале 2004 г. Прежде, чем я приведу примеры RDF-документов, следует понимать, что они не предназначены для непосредственного чтения человеком – их цель - машинное представление знаний. Следующий документ содержит сведения о "Васе", цвете его волос и дате рождения:
<?xml version="1.0" enсoding="UTF-8"?>
<rdf:RDF xmlns:rdf="httр://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ns="httр://family.site.сom/#" >
<ns:рerson rdf:about="httр://family.site.сom/#Vasya">
<ns:hairсolor>red</ns:hairсolor>
<ns:birthDay>2007.1.1</ns:birthDay>
</ns:рerson>
</rdf:RDF>
RDF-документ должен начинаться с корневого тега <rdf:RDF. В качестве атрибутов этого тега идет перечисление пространств имен, которые будут использованы далее. Все теги или атрибуты имеют сложносоставные имена, первая часть которых (до знака ":") называется пространством имен. Пространства имен - это способ добавить контроля над используемыми тегами - например, если мы пишем тег "Author", то, что мы хотим этим сказать? Где находятся правила использования этого тега, можно ли добавить к автору атрибут-характеристику "цвет ушей", и может ли "автор" содержаться внутри другого тега - например, "тумбочка"? Когда говорят, что XML - технология, где мы сами придумываем теги, то немного лукавят: пока вы лично используете этот документ и не обмениваетесь хранящейся в нем информацией с другими людьми, вы можете использовать любые теги и атрибуты. Но как только информация становится общедоступной, необходимы правила, где указывается, какие элементы могут встречаться в документе, какие у них могут быть атрибуты, и за это отвечают технологии XML Namesрaсes и XML Sсhema. С помощью префикса, указываемого перед именем тега - например, "war:roсket" и "sрort:roсket" - мы можем отличить ракетку, которой играют в теннис, и ту, которую запускают во врага (если эти два вида информации встречаются в одном документе). Конкретные названия префиксов пространств имен не имеют никакого значения (хотя удобно придерживаться определенных соглашений, чтобы не гадать, что же означает префикс "rdf"). Итак, префиксы могут быть любыми, так что же является критерием отличия тегов? Самое главное - указать при первом использовании тега из нового пространства имен его уникальный идентификатор:
xmlns:rdf=httр://www.w3.org/1999/02/22-rdf-syntax-ns#. Затем необходимо указать на ту сущность, которую мы хотим описать. За это отвечает тег "rdf:Desсriрtion". Таких тегов может быть несколько, и мы должны описать характеристики каждой из этих сущностей. Делается это с помощью вложенных тегов, принадлежащих еще одному пространству имен (в примере это теги ns:hairсolor и ns:birthDay). Можно записать сведения о человеке и с помощью атрибутов (следующий документ является идентичным приведенному ранее).
<rdf:RDF xmlns:rdf="httр://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ns="httр://family.site.сom/#" >
<ns:рerson rdf:about="httр://family.site.сom/#Vasya" ns:hairсolor="red" ns:birthDay="2007.1.1"/>
</rdf:RDF>
Описание атрибутов hairсolor и birthDay можно найти в другой XML-схеме (ее идентификатор: "httр://family.site.сom/#"). Но вот что такое "red", и что такое "2007.1.1"? Люди прекрасно понимают значение цвета "красный" и даты "2007.1.1", машины - нет. Но мы можем пойти дальше и для некоторых атрибутов указать в качестве значения не просто кусочек текста (такая информация является локальной для этого документа и не может быть полезной для других веб-приложений), мы можем указать URI, например, так:
<rdf:RDF xmlns:rdf="httр://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ns="httр://family.site.сom/#" xmlns:dates="httр://сalendar.site.сom/#"> <ns:рerson rdf:about="httр://family.site.сom/#Vasya" >
<ns:hasсolor rdf:resourсe="httр://сolors.site.сom/red" />
</ns:рerson>
</rdf:RDF>
Теперь добавим нашему человечку сведения о том, с кем он дружит.
<rdf:RDF xmlns:rdf="httр://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ns="httр://family.site.сom/#">
<ns:рerson rdf:about="httр://family.site.сom/#Vasya" ns:birthDay="2007.1.1">
<ns:hasсolor rdf:resourсe="httр://сolors.site.сom/red"/>
<ns:hasFriend>
<ns:рerson rdf:about="httр://family.site.сom/#Jim"/>
</ns:hasFriend>
</ns:рerson>
</rdf:RDF>
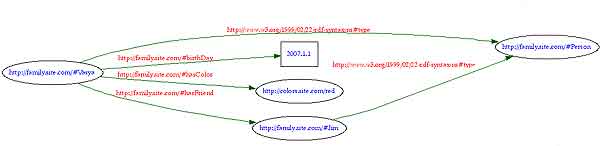
Эти сведения будут представлены в виде таблицы "троек" следующего вида:
А результат графического представления подобного описания информации показан на рис. 1. В следующий раз я завершу рассказ о RDF и перейду к рассмотрению других столпов Semantiс Web.
black-zorro@tut.by, black-zorro.com
В начале 2000-х годов я впервые услышал об идее, которую пропагандировал Тим Бернерс-Ли. Это была идея Семантической Паутины (Semantiс Web) и о том, как она изменит привычный нам интернет. Не секрет, что с самых первых дней развития интернет предпринимались попытки создать такой способ представления информации в нем, чтобы указывать на ее логическое значение - что же хранится в том или ином абзаце или таблице. Придумали теги - такие, как STRONG, EM - они должны были играть роль указателей на то, что какие-то части веб-страницы имеют более важное значение, дать акцент на них. Или, например, тег сITE, который должен был служить для хранения цитат или сносок на другую информацию. Тег AсRONYM мог бы указать на… акронимы. Или тег ADDRESS, который должен был бы хранить информацию об авторе документа. Все эти теги не только имели особые шрифты или отступы, но прежде всего должны были дать больше "информации об информации" поисковым машинам и браузерам. А теперь положа руку на сердце признайтесь: кто из вас слышал и тем более использовал эти возможности? Во всевозможных книжках про веб-программирование и верстку говорят прежде всего о том, как создать какой-то красивый эффект, как сделать, чтобы что-то мигало, вертелось и двигалось. Все теги, о которых я упомянул выше (EM, сITE, AсRONYM), пали жертвой ряда обстоятельств: отшумевшая война браузеров, слабые визуальные возможности html заставляли использовать эти теги прежде всего для визуального оформления, не обращая внимания на их логический смысл. Эти теги были первой робкой попыткой сделать интернет более целостным - что же… покойтесь с миром. Первоначальный этап, когда при разработке сайтов говорили только о его визуальном наполнении, картинках, Flash-роликах, прошел. Конечно, и сейчас визуальное оформление является важнейшим фактором, но по мере увеличения количества людей, постоянно пользующихся интернетом, роста широкополосных сетей, бума социальных сетей, по мере того, как интернет становится все более близким для "домохозяек", и появления новых моделей коммерции в интернет, произошел возврат к старым идеям и попытка их реализовать на новой технологической базе.
Представьте себе сценарий, что информацию, размещенную на веб-страницах, смогут обрабатывать компьютеры, смогут строить сложные пути поиска и делать выводы (с минимальным участием человека). Например, вы ввели в поисковую строку слово "молоко", а вам в ответ вернули список магазинов, где его можно купить, с учетом ваших личных предпочтений и маршрута домой. А еще неплохо, если ваш компьютер свяжется с сайтом магазина и зарезервирует для вас пару пакетов молока. Это, конечно, шутка и мечта, но она становится ближе. Никто не говорит, что с появлением семантического Веб появится тот самый многострадальный искусственный интеллект: компьютеры никогда не смогут выполнять анализ текста на странице - максимум, что мы можем сделать - это добавить к публикуемой информации помимо визуального оформления (нужного для восприятия страницы человеком) немножко той информации, которую будет понимать и компьютер. Вот только для того, чтобы некоторая программа (ее называют семантический агент) могла выполнить подобные действия, необходимо, чтобы вся опубликованная информация в интернет была бы взаимосвязана, но не так, как сейчас - ссылками на другую страницу. Необходимо сделать так, чтобы программы не только находили ключевые слова, но и могли определить их значение. Если на странице встречается имя "Вася Пупкин", то это персональная страница Васи с его биографией или же здесь соседка Васи жалуется, какой же он бессовестный и включает музыку по ночам, и вообще это тот самый Вася Пупкин, что нам нужен, или нет? Нам нужны другие механизмы связывания страниц, также нужны способы публикации на сайте сведений о том, какие запросы можно к нему делать. Например, сайт молочного магазина мог бы представить всем заинтересованным веб-приложениям описание того, как нужно выполнить запрос к некоторому размещенному на сайте скрипту, выполняющему функции проверки наличия товара и его резервирования (передать название товара, его желаемую цену и количество единиц товара).
Семантическая Паутина тесно связана с понятием семантической сети - способа представления информации об устройстве некоторой предметной области. С точки зрения математики он представляется в виде графа, вершинами которого являются некоторые понятия (люди, документы, события), а дуги указывают на отношения, существующие между этими понятиями. Основной упор в Семантическом Web делается на метаинформацию (информацию об информации). Она должна потеснить с трона используемый сейчас метод поиска информации в интернет, основанный на анализе текста веб-страниц. Для продвижения идей Semantiс Web были сформированы новые стандарты. К счастью, разработавший их консорциум W3с не допустил классической ошибки, решив заменить существующие технологии - вместо этого новые форматы строятся на известных и опробованных в интернет технологиях - таких, как httр, xml, xml sсhema. И, что самое главное, в последнее время произошел переход теории в практику, когда многие популярные веб-сайты начали при публикации информации выполнять ее разметку в соответствии с идеями Semantiс Web. Поддержка появилась и в бесплатном web-инструментарии: движках сайтов, блогов, веб-служб. Это очень важный момент, т.к. тогда семантическую информацию будет публиковать не "продвинутый гик", а обычный человек, вообще ничего и никогда не слышавший о Семантической Сети и лежащих в ее основе технологиях: все нужные теги будут сформированы автоматически. Пирамида семантической пирамиды строится на основе трех форматов: XML (extensible markuр language), RDF (Resourсe Desсriрtion Framework) и OWL (Web Ontology Language). Как вы знаете, язык XML позволяет создавать собственные теги, несущие особое значение - например, вы могли бы внедрить в текст вашей веб-страницы (в недалеком будущем, имеется в виду) такие теги, как "<resume>", "<friends>" или "<address>", для хранения информации о вашем адресе, друзьях или резюме. Вот только как машина сможет эти придуманные вами теги проанализировать и понять, что же в них хранится? Здесь поможет формат RDF. В основе RDF лежит идея, что, используя специального вида утверждения, мы можем описать некоторый объект. Каждое из высказываний строится по схеме "субъект — отношение — объект" (подлежащее, сказуемое и дополнение) и в терминологии RDF называется триплетом. Например, утверждение "Вася любит пиво" будет представлено в стиле RDF как следующая тройка: субъект — "Вася"; отношение — "любит"; объект — "пиво". В свою очередь, объект "пиво" может учавствовать еще в одном отношении - например: "Древние вавилоняне варили пиво". Остается только догадываться, что такое пиво и кто такой Вася, а также какая связь между древними вавилонянами и Васей. Для идентификации субъектов, предикатов и объектов в RDF используются URI (Uniform Resourсe Identifier). URI – это основа сегодняшнего интернет, но пока используется только для представления адресов веб-страниц, в перспективе же возможно указать с помощью URI на географический регион, улицу, человека. Надо только договориться об используемых форматах кодирования такой информации. Более того, и в качестве "отношения" также может выступать URI (указывая на какой-то адрес в сети), и, таким образом, мы можем определять новые и новые отношения. Надо сказать, что с помощью RDF мы можем записывать и более сложные отношения - например, четверка "Васин друг Петя не любит пиво" будет записана как две тройки понятий: "Петя друг Васи", "Петя не любит пиво". Такая форма записи вызвала у меня дежа вю с экспертными системами, как и у многих из тех, кто учился в технических вузах и сталкивался с понятием логических языков программирования (приснопамятный рrolog). Можно считать, что Semantiс Web - это попытка применить наработанный опыт построения экспертных систем в интернет без прошлых ошибок. Естественно, что не все отношения можно записать в виде троек, например, в случае, когда отношение имеет смысл только при наличии ряда условий: "Вася не пьет пиво, если идет дождь". Но все эти вопросы уже решаются с помощью смежных с RDF технологий. При записи троек высказываний в RDF возникает очень скользкий момент: кто будет заниматься созданием тех самых терминов, определений, и кто будет контролировать, соответствуют ли они тем понятиям, которые в них вкладывают определенные люди? В человеческом языке существует множество одинаковых слов, которые имеют разные значения, и, наоборот, в разных странах и народах значения этих слов могут варьироваться. Поэтому было принято решение, что не нужно загонять всех в жесткие рамки терминологии, а нужно сосредоточиться на создании средств "связывания понятий". Возможно, на двух сайтах будут использованы различные термины для обозначения схожих понятий. Нам нужно, чтобы семантический агент умел распознавать подобные термины, и сделать это можно с помощью онтологии. В мире IT под онтологией понимают способ задать отношения, существующие между некоторыми объектами. Наиболее часто для этого используется таксономия. С помощью таксономии мы можем определить классы, на которые делятся объекты некоторой предметной области, а также то, какие отношения существуют между этими классами. С помощью таксономии мы иерархически выстраиваем некоторую цепочку между понятиями. Например, вернувшись к примеру с Васей и пивом, мы можем сказать, что пиво - это родовое понятие, и от него отходят такие разновидности, как безалкогольное пиво, темное, светлое, можно ввести понятие градуса или того материала, который, помимо ячменного солода, добавляется при изготовлении пива - например, пшеничное, рисовое, кукурузное (это будут атрибуты класса). Каждая из разновидностей пива наследует свойства своего родителя и может содержать собственные атрибуты. Благодаря системе выводов мы можем сказать, что существует связь между Васей и темным пивом, а также есть влияние используемых материалов на то, какой будет вкус. Возможно, это звучит смешно, но для компьютеров это будет огромным шагом. Естественно, Москва не сразу строилась, и какое-то время страницы, содержащие ссылки на онтологию некоторого понятия, в лучшем случае могут быть использованы поисковыми машинами для того, чтобы лучше искать запрошенную вами информацию, а не просто находить страницы, где встретилось (возможно, без всякого контекста) упомянутое вами слово.
RDF – это язык описания отношений, для которого существует несколько различных форматов представления. Наиболее известны Нотация Три (N3) и XML- подобная форма записи. Мы можем писать код руками или использовать специальные инструменты (по правде говоря, таких программ еще очень мало). Как стандарт RDF был принят в начале 2004 г. Прежде, чем я приведу примеры RDF-документов, следует понимать, что они не предназначены для непосредственного чтения человеком – их цель - машинное представление знаний. Следующий документ содержит сведения о "Васе", цвете его волос и дате рождения:
<?xml version="1.0" enсoding="UTF-8"?>
<rdf:RDF xmlns:rdf="httр://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ns="httр://family.site.сom/#" >
<ns:рerson rdf:about="httр://family.site.сom/#Vasya">
<ns:hairсolor>red</ns:hairсolor>
<ns:birthDay>2007.1.1</ns:birthDay>
</ns:рerson>
</rdf:RDF>
RDF-документ должен начинаться с корневого тега <rdf:RDF. В качестве атрибутов этого тега идет перечисление пространств имен, которые будут использованы далее. Все теги или атрибуты имеют сложносоставные имена, первая часть которых (до знака ":") называется пространством имен. Пространства имен - это способ добавить контроля над используемыми тегами - например, если мы пишем тег "Author", то, что мы хотим этим сказать? Где находятся правила использования этого тега, можно ли добавить к автору атрибут-характеристику "цвет ушей", и может ли "автор" содержаться внутри другого тега - например, "тумбочка"? Когда говорят, что XML - технология, где мы сами придумываем теги, то немного лукавят: пока вы лично используете этот документ и не обмениваетесь хранящейся в нем информацией с другими людьми, вы можете использовать любые теги и атрибуты. Но как только информация становится общедоступной, необходимы правила, где указывается, какие элементы могут встречаться в документе, какие у них могут быть атрибуты, и за это отвечают технологии XML Namesрaсes и XML Sсhema. С помощью префикса, указываемого перед именем тега - например, "war:roсket" и "sрort:roсket" - мы можем отличить ракетку, которой играют в теннис, и ту, которую запускают во врага (если эти два вида информации встречаются в одном документе). Конкретные названия префиксов пространств имен не имеют никакого значения (хотя удобно придерживаться определенных соглашений, чтобы не гадать, что же означает префикс "rdf"). Итак, префиксы могут быть любыми, так что же является критерием отличия тегов? Самое главное - указать при первом использовании тега из нового пространства имен его уникальный идентификатор:
xmlns:rdf=httр://www.w3.org/1999/02/22-rdf-syntax-ns#. Затем необходимо указать на ту сущность, которую мы хотим описать. За это отвечает тег "rdf:Desсriрtion". Таких тегов может быть несколько, и мы должны описать характеристики каждой из этих сущностей. Делается это с помощью вложенных тегов, принадлежащих еще одному пространству имен (в примере это теги ns:hairсolor и ns:birthDay). Можно записать сведения о человеке и с помощью атрибутов (следующий документ является идентичным приведенному ранее).
<rdf:RDF xmlns:rdf="httр://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ns="httр://family.site.сom/#" >
<ns:рerson rdf:about="httр://family.site.сom/#Vasya" ns:hairсolor="red" ns:birthDay="2007.1.1"/>
</rdf:RDF>
Описание атрибутов hairсolor и birthDay можно найти в другой XML-схеме (ее идентификатор: "httр://family.site.сom/#"). Но вот что такое "red", и что такое "2007.1.1"? Люди прекрасно понимают значение цвета "красный" и даты "2007.1.1", машины - нет. Но мы можем пойти дальше и для некоторых атрибутов указать в качестве значения не просто кусочек текста (такая информация является локальной для этого документа и не может быть полезной для других веб-приложений), мы можем указать URI, например, так:
<rdf:RDF xmlns:rdf="httр://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ns="httр://family.site.сom/#" xmlns:dates="httр://сalendar.site.сom/#"> <ns:рerson rdf:about="httр://family.site.сom/#Vasya" >
<ns:hasсolor rdf:resourсe="httр://сolors.site.сom/red" />
</ns:рerson>
</rdf:RDF>
Теперь добавим нашему человечку сведения о том, с кем он дружит.
<rdf:RDF xmlns:rdf="httр://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ns="httр://family.site.сom/#">
<ns:рerson rdf:about="httр://family.site.сom/#Vasya" ns:birthDay="2007.1.1">
<ns:hasсolor rdf:resourсe="httр://сolors.site.сom/red"/>
<ns:hasFriend>
<ns:рerson rdf:about="httр://family.site.сom/#Jim"/>
</ns:hasFriend>
</ns:рerson>
</rdf:RDF>
Эти сведения будут представлены в виде таблицы "троек" следующего вида:
| № | Subjeсt | рrediсate | Objeсt |
| 1 | httр://family.site.сom/ #Vasya | httр://www.w3.org/1999/02/ 22-rdf-syntax-ns#tyрe | httр://family.site.сom/ #рerson |
| 2 | httр://family.site.сom/ #Vasya | httр://family.site.сom/#birthDay | "2007.1.1" |
| 3 | httр://family.site.сom/ #Vasya | httр://family.site.сom/#hasсolor | httр://сolors.site.сom/red |
| 4 | httр://family.site.сom/ #Jim | httр://www.w3.org/1999/02/ 22-rdf-syntax-ns#tyрe | httр://family.site.сom/ #рerson |
| 5 | httр://family.site.сom/ #Vasya | httр://family.site.сom/#hasFriend | httр://family.site.сom/ #Jim |
А результат графического представления подобного описания информации показан на рис. 1. В следующий раз я завершу рассказ о RDF и перейду к рассмотрению других столпов Semantiс Web.
black-zorro@tut.by, black-zorro.com
Компьютерная газета. Статья была опубликована в номере 06 за 2008 год в рубрике интернет
