
Разрушая велосипедные фабрики: доступ к базам данных из php. Часть 2
Сегодня мы продолжим разговор о различных методиках организации доступа к базам данных из php. Основной акцент я уделю не используемому языку, и даже не библиотекам (стандартным или сделанным сторонними компаниями или энтузиастами), а прежде всего сложившимся и зарекомендовавшим себя подходам, алгоритмам успеха применяя которые, в типовых ситуациях можно избежать типовых и (столь привычных) для новичков ошибок.
Пару лет назад считалось модным создавать для любого мало-мальского сайта собственную библиотечку для работы с БД. Фактически на идею данной серии статей меня толкнула ситуация, когда меня попросили разобраться и чуть-чуть подправить один старый сайт. В нем я столкнулся с таким "велосипедом" — еще одной попыткой написать собственную библиотеку для доступа к БД — и понял, что "наболело". С одной стороны, это хорошая тренировка в проектировании и программировании (особенно за счет заказчика), с другой стороны — нежелание познакомиться с пусть не де-юре (стандартными и встроенными в php средствами), так с де-факто библиотеками (интересными и используемыми серьезными разработчиками) и почерпнуть из них новые идеи. Не зря же сказал Ньютон: "Современные ученые — это карлики, стоящие на плечах гигантов".
В прошлый раз я остановился на том, что рассказал о паттернах проектирования. Рассказал об особом их семействе — паттерны доступа к данным. Сегодня мы продолжим рассмотрение средств, позволяющих упростить проектирование модели данных и доступа к ней, плюс (на этом будет один из основных акцентов) поговорим о безопасности. Первый паттерн — Table Data Gateway — заключался в том, чтобы создать набор функций, которые, будучи организованы в виде библиотеки, будут покрывать все множество типовых действий для вашей задачи — играть роль api. Так, создавая даже сайт — каталог товаров, вы реализуете функции, работающие с объектами каталога: товарами, секциями. Эти функции умеют почти все: поиск товаров, сортировку товаров, отбор товаров по заданному набору характеристик, также задачи редактирования информации, добавления новых товаров или удаления старых. Эти функции получают в качестве входных данных все необходимое для работы. А результаты этой работы отдают в максимально обобщенном виде второму слою вашего приложения, которое может представлять собой панель управления сайта (backside) — то, чем пользуется администрация для наполнения каталога информацией. Или для frontside — отобранную на первом слое информацию о товарах в разделе каталога следует на втором слое визуализировать согласно дизайну сайта. Слово "слой" я впервые употребил в прошлой статье. Так, разделяя приложение на слои (и избегая побочных связей между ними), вы получаете массу преимуществ: скорость разработки растет из-за снижения числа возможных ошибок, количество переделок, которые необходимо выполнить при изменении одной части проекта, не растет снежной лавиной по всему коду, а локализуется только в одном слое. Плюс можно грамотно разделить работу между несколькими участниками: код первого слоя пишут программисты — специалисты в области БД, второй слой создается html-кодерами с небольшими навыками в области программирования. Если грамотно согласовать интерфейс первого слоя — названия функций, их параметры, что они будут делать, — то вы можете запустить разработку этих двух слоев вашего приложения (сайта) параллельно. Для проекта, который планирует интенсивно развиваться, послойная организация дает лишние шансы на масштабируемость проекта, на смену используемой СУБД, дает возможность переделывать дизайн (работу второго слоя), не принуждая html-кодеров или дизайнеров лезть в топи первого слоя. Естественно, что о методиках такого разделения труда мечтают давно, разработаны и продолжают совершенствоваться различные паттерны (наиболее известен среди них MVC) и конкретные программные продукты. С другой стороны, на внедрение этих методик требуются начальные затраты и обучение персонала — так что, если вы планируете всю жизнь делать проекты трудоемкостью в пару дней (недель), и дальнейшего развития для них не предусматривается, то вам лучше перевернуть страницу и почитать про что-нибудь другое. Но довольно философии — давайте назовем конкретные имена библиотек, позволяющих реализовать паттерн Table Data Gateway. Итак… это абсолютно все библиотеки. Некоторые, правда, представляют собой дополнительную функциональность и реализуют другие паттерны: Row Gateway, ActiveRecord, DataMapper. Вы можете не искать очередную "серебряную пулю" в виде сторонней библиотеки, а взять стандартные функции mysql или mysqli расширения php. Они прекрасно решают свои задачи. Давайте переформулируем: нам нужна библиотека, которая должна позволять записывать компактно и локализуемо sql-выражения, позволять избегать основных ошибок набора — глупых опечаток, запись sql-команд должна быть удобочитаемой, библиотека не должна позволять забывать об элементарной безопасности кода перед попытками взлома "злобных" хакеров. Сегодня я расскажу о библиотеке dbSimple от Д. Котерова (сайт dklab.ru). Во вступлении к описанию своей библиотеки автор говорит, что пытается и чего не пытается делать его библиотека — просто добавлю пару своих копеек к его словам.
Выравнивание кода. Я крайне негативно отношусь к программным продуктам, которые ставят своей целью эмуляцию возможностей одной СУБД средствами другой или создания программной надстройки, выполняющей такую эмуляцию. Рекламный лозунг "вместе с нашей библиотекой утром вы работаете с oracle, в полдень — с mssql, а вечером — с mysql" глуп и смешон. Я понимаю историческую и коммерческую целесообразность разработчиков "серьезных" СУБД отойти от рекомендуемого для всех стандарта SQL разных ревизий. Понимаю, что унификация набирает темп, и то, что достичь ее никогда не удастся. Мой любимый пример с получением информации о наличных базах данных на сервере, таблицах, полях, ограничениях — все, что называется словом метаинформация. Так, ранее каждая СУБД предлагала свой набор ключевых слов для того, чтобы получить эти сведения. Сейчас же почти повсеместной стала поддержка INFORMATION_SCHEMA (грубо говоря, существует некоторая виртуальная база данных, таблицы которой содержат информацию о других, уже реальных, таблицах, полях, view и прочее). Смена используемой СУБД по определению не может обойтись малой кровью. Чтобы писать быстрый и качественный код, вы должны выжимать все соки из вашей СУБД, а не ограничиваться наиболее простыми, общими для многих СУБД командами. Итак, dbSimple не занимается выравниванием кода и не занимается эмулированием недостающих возможностей некоторой СУБД. Классический пример — постраничная выборка данных, когда мы говорим, что нам нужно не все содержимое таблицы товаров, а только с десятой по двадцатую позиции, и отброс лишних записей выполняется средствами СУБД. Как прекрасно эта функция реализована в mysql, так же ужасно в microsoft sql server до 2005 версии (но решение ведь все равно было). Так что, если вы все еще хотите библиотеку-выравниватель, то вам лучше еще раз перечитать книжку по вашей СУБД.
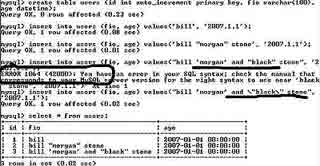 Кавычки, слэши и экранирование. Когда я рассказал одному знакомому о плане написать серию статей, посвященных php и базам данных, он скривил нос и заявил, что у php сложилась репутация примитивного и плохо спланированного языка, которому уже ничего не поможет — уж лучше бы я писал про java или ruby. Репутация действительно заслуженная — чего стоит одна история с экранированием спецсимволов. Спецсимволы — это символы, которые играют особую роль для некоторого приложения, библиотеки… Также под спецсимволами можно понимать символы, которые обозначают не сами себя, а некоторый другой символ — например, \n — для перевода строки или \t для символа табуляции. Применительно к php&mysql яркими представителями спецсимволов являются кавычки: двойные или одинарные. Именно внутрь кавычек мы заключаем строки текста, которые вносятся в базу данных. Но что делать, если вносимый текст содержит кавычки (или иные спецсимволы), которые мы хотим интерпретировать не как спецсимвол, а как обычный символ? Например, в ФИО нашего человека будет второе имя в кавычках (см. рис. 1). Обратите внимание на ошибку и последующий запрос с постановкой перед внутренними кавычками обратного слэша. Экранировка жизненно необходима при вставке данных в любую таблицу, и дело не только в возможной генерации ошибки, а в возможном взломе вашего сайта на основе sql-injеction. Подробнее про это можно узнать по адресу сайт или в журнале phpinside #5 ( сайт ). Суть взлома с помощью sql-injеction в том, чтобы манипулировать sql-кодом, внедрить в него опасную команду.
Кавычки, слэши и экранирование. Когда я рассказал одному знакомому о плане написать серию статей, посвященных php и базам данных, он скривил нос и заявил, что у php сложилась репутация примитивного и плохо спланированного языка, которому уже ничего не поможет — уж лучше бы я писал про java или ruby. Репутация действительно заслуженная — чего стоит одна история с экранированием спецсимволов. Спецсимволы — это символы, которые играют особую роль для некоторого приложения, библиотеки… Также под спецсимволами можно понимать символы, которые обозначают не сами себя, а некоторый другой символ — например, \n — для перевода строки или \t для символа табуляции. Применительно к php&mysql яркими представителями спецсимволов являются кавычки: двойные или одинарные. Именно внутрь кавычек мы заключаем строки текста, которые вносятся в базу данных. Но что делать, если вносимый текст содержит кавычки (или иные спецсимволы), которые мы хотим интерпретировать не как спецсимвол, а как обычный символ? Например, в ФИО нашего человека будет второе имя в кавычках (см. рис. 1). Обратите внимание на ошибку и последующий запрос с постановкой перед внутренними кавычками обратного слэша. Экранировка жизненно необходима при вставке данных в любую таблицу, и дело не только в возможной генерации ошибки, а в возможном взломе вашего сайта на основе sql-injеction. Подробнее про это можно узнать по адресу сайт или в журнале phpinside #5 ( сайт ). Суть взлома с помощью sql-injеction в том, чтобы манипулировать sql-кодом, внедрить в него опасную команду.
Например, вы делаете сайт-каталог товаров, в нем страница, где по номеру или названию раздела отбираются вложенные товары. Страницы каталога запрашиваются по правилу: catalog.php?section=12
Здесь 12 — варьирующаяся переменная, которая задает номер раздела, в который зашел клиент, вы как программист пишете внутри страницы catalog.php примерно следующий запрос, отбирающий товары:
select * from articles where section_id = 12
Цифра 12 берется из параметра запроса. И вы подставляете это значение примерно так:
mysql_query ('select * from articles where section_id = ' . $_REQUEST['section'])
Если вы посмотрели на эту строку и согласно закивали головой: мол, все верно, я и сам так пишу, то вас нужно срочно увольнять, а код переписывать, ибо легким движением руки злобного хакера в адресную строку браузера вводится следующий адрес:
catalog.php?section=12;truncate articles
А, следовательно, будет выполнена уже следующая команда:
select * from articles where section_id =12;truncate articles
Символ ";" для mysql означает разделитель команд — значит, будут выполнены две команды: первая безобидная, отбирающая данные из таблицы товаров, а вторая (truncate) — удаляющая из этой таблицы все содержимое. Мир не идеален, и значит, все, абсолютно все данные, которые поступают на вход вашему скрипту и используются в работе (тем более с такой дорогой вещью, как база данных), нужно проверять. Хорошо если база вашего сайта представляет собой слепок с настоящей базы товаров, находящейся в офисе, и каждое утро вы копируете информацию на веб-сервер. А если та база, что находится в Веб, является первичной и единственной? Кто-то скажет: "да кому наш сайт нужен, кто его будет ломать?" Надеюсь, что это сказали не вы, а мы тем временем продолжаем. Как защититься от sql-injection? Я предпочитаю делать два слоя защиты: средствами собственно языка программирования — здесь нужно всего лишь все входные данные проверить на корректность. Получает скрипт в качестве параметра номер раздела каталога или товара — проверь: вдруг это не число. Нужно вставить в sql-запрос в условие отбора по названию товара полученную из html-формы строку с его названием — проверь строку на недопустимость ключевых слов sql (delete, truncate, select, update…) и обязательно заэкранируй все спецсимволы обратным слэшем. Второй уровень защиты — грамотно настроить политику безопасности. Если у вас сайт с каталогом товаров, который правится через веб-интерфейс администратором с одной стороны, и просматривается обычным посетителем сайта — с другой, создайте две учетные записи. При подсоединении от имени первой — полноправной — разрешены все операции с таблицами: правка, удаление, добавление данных. Вторая же запись — для клиента — будет "бесправной" — явно разрешите только те операции (отбор, но не изменение или удаление), и только для тех таблиц (общедоступные товары, но никак не таблица с секретными паролями или финансовыми сведениями клиентов), которые не могут повредить работе сайта. Поверьте, разобраться с политикой безопасности в mysql или mssql очень просто, и эти настройки доступны для любого, даже самого дешевого, хостинга. Что еще нужно от хорошей библиотеки работы с СУБД? Грамотная обработка ошибок, возможность так настроить систему, чтобы вы не могли даже при всем желании проигнорировать возникшую проблему. Мне иногда попадаются сайты, которые не просто не работают — действительно, с кем не бывает, — но при возникновении ошибки вываливают на страницу кучу отладочной информации (пароли, имена переменных, куски sql-кода). Сайты не проверяют, успешно или нет были выполнены запрошенные ими действия, а продолжают идти напролом, вызывая все больше и больше ошибок в других частях программы. Каждая ошибка должна быть отловлена, и вместо нее следует выводить стандартное, ничего не говорящее сообщение: "произошел сбой, зайдите позже".
После такого длительного введения в суть проблемы вернемся к php и нашим кавычкам. Говорят (и я этому даже верю), что разработчики языка php, будучи не в силах заставить основную массу php-программистов писать качественный код, решили позаботиться о безопасности наших СУБД и ввели автоматическое добавление слэшей перед спецсимволами. Слэши добавляются на основании директив php.ini (magic_quotes_gpc и magic_quotes_runtime). Директивы имеют общее название "волшебные кавычки", я же зову их "адские кавычки". Действительно, в грамотно написанном приложении необходимость в автоматическом закавычивании отсутствует, более того: лишние кавычки мешают, и их приходится удалять. Первая директива — magic_quotes_gpc — означает, что PHP автоматически добавляет слэши к данным, пришедшим от пользователя — из POST-, GET-запросов и cookies. Вторая переменная — magic_quotes_runtime — означает, что слэши добавляются к данным, полученным во время исполнения скрипта — например, из файла или базы данных. Так, некоторые функции, представляющие подобную информацию, выполняют ее закавычивание. Если вы хотите отказаться от столь навязчивого сервиса, то либо вы (в той редкой и счастливой ситуации, когда вы полновластный владелец сервера) в файле php.ini отключаете эти конфигурационные переменные, либо (если вы, конечно, не размещаете сайт на бесплатном хостинге) вы можете внести изменения в файл .htaccess. Это файл, в котором находятся локальные — для одного каталога, а не для всего сервера — настройки apache. И добавьте в него следующие строки:
php_flag magic_quotes_gpc 0
php_flag magic_quotes_runtime 0
Внимание: когда вы формируете запрос, вносящий данные в СУБД, и выполнили добавление экранирующих слэшей, то эти слэши будут автоматически удалены сервером СУБД при сохранении изменений, поэтому частая ошибка начинающих в том, чтобы удалять слэши после получения (select выборки) данных из СУБД. Итак, как итог: когда вы записываете команду sql, не забывайте все строки помещать в кавычки и выполнять экранирование самих строк — не полагайтесь на "адские кавычки". Для экранирования спецсимволов следует применять только и только функцию mysql_real_escape_string — эта функция представляет несколько дополнительных сервисов по сравнению со своими младшими братьями, "закавычивающими" addslashes или addcslashes. Прежде всего, эта функция может работать только после установления соединения с mysql-сервером и в своей работе ориентируется на особенности настроек mysql, учитывает кодировку базы данных, кодировку соединения, правильно обрабатывает unicode-строки. Таким образом, конструирование строки запроса должно выглядеть так:
$sql="SELECT * FROM articles WHERE category_name = ' ".mysql_real_escape_string($_REQUEST['category']) . "' ";
Ага, скажут читатели, это же громоздко. Конечно, громоздко, а когда у вас будет в одном запросе использоваться десятка с два полей одновременно, то станет и неудобочитаемым. А неудобочитаемость приводит к потере контроля кода и риску забыть какое-нибудь поле плюс проблема переработки кода. Если на каком-то шаге вы внесли изменения в СУБД, переименовав поле или изменив его тип данных, то следует найти все эти неудобочитаемые куски sql-кода и подправить. Поэтому Д. Котеров (конечно, не первый в мире) предложил и реализовал в своей библиотеке DbSimple концепцию placeholder'ов. Вы пишете запрос, не думая о кавычках, экранировании, но помечаете места, куда должны вставляться данные с помощью специального значка — placeholder'а (обозначающего место). А затем вместо этих placeholder'oв будут вставлены собственно данные, с кавычками по краям и корректно экранированные. Запросы получаются очень компактными — например, так:
SELECT * FROM ?_user where fio = ? LIMIT ?d, ?d
Здесь placeholder — это знак "?", после которого идет некоторый уточняющий символ. Увы, но детально рассказать об placeholder'ах я сегодня никак не успеваю — придется в следующий раз.
Теперь поговорим о проблеме "хочу массив". Дело в том, что стандартные функции php-mysql, получив строку запроса, возвращают вам не собственно набор отобранных данных, а некоторый ресурс — указатель, по которому с помощью других функций можно получить собственно значения полей. Это хорошо и плохо одновременно. Хорошо "тюнингом", оптимизацией программы, экономией ресурсов памяти и CPU. Плохо тем, что требуется выполнять рутинные и однообразные действия по преобразованию данных в формат, привычный для php: массивы, А-массивы (ассоциативный массив). Так вот, dbSimple содержит ряд функций для отбора данных, которые возвращают записи в виде массива, состоящего из А-массивов — каждая запись таблицы в виде А-массива. Есть функции для отбора скалярных величин.
Но об этом в следующий раз, когда я продолжу рассказ о DbSimple. Нас также ждет следующая порция теории о паттернах доступа к данным и практика с парочкой интересных библиотек.
black zorro, black-zorro.jino-net.ru
Пару лет назад считалось модным создавать для любого мало-мальского сайта собственную библиотечку для работы с БД. Фактически на идею данной серии статей меня толкнула ситуация, когда меня попросили разобраться и чуть-чуть подправить один старый сайт. В нем я столкнулся с таким "велосипедом" — еще одной попыткой написать собственную библиотеку для доступа к БД — и понял, что "наболело". С одной стороны, это хорошая тренировка в проектировании и программировании (особенно за счет заказчика), с другой стороны — нежелание познакомиться с пусть не де-юре (стандартными и встроенными в php средствами), так с де-факто библиотеками (интересными и используемыми серьезными разработчиками) и почерпнуть из них новые идеи. Не зря же сказал Ньютон: "Современные ученые — это карлики, стоящие на плечах гигантов".
В прошлый раз я остановился на том, что рассказал о паттернах проектирования. Рассказал об особом их семействе — паттерны доступа к данным. Сегодня мы продолжим рассмотрение средств, позволяющих упростить проектирование модели данных и доступа к ней, плюс (на этом будет один из основных акцентов) поговорим о безопасности. Первый паттерн — Table Data Gateway — заключался в том, чтобы создать набор функций, которые, будучи организованы в виде библиотеки, будут покрывать все множество типовых действий для вашей задачи — играть роль api. Так, создавая даже сайт — каталог товаров, вы реализуете функции, работающие с объектами каталога: товарами, секциями. Эти функции умеют почти все: поиск товаров, сортировку товаров, отбор товаров по заданному набору характеристик, также задачи редактирования информации, добавления новых товаров или удаления старых. Эти функции получают в качестве входных данных все необходимое для работы. А результаты этой работы отдают в максимально обобщенном виде второму слою вашего приложения, которое может представлять собой панель управления сайта (backside) — то, чем пользуется администрация для наполнения каталога информацией. Или для frontside — отобранную на первом слое информацию о товарах в разделе каталога следует на втором слое визуализировать согласно дизайну сайта. Слово "слой" я впервые употребил в прошлой статье. Так, разделяя приложение на слои (и избегая побочных связей между ними), вы получаете массу преимуществ: скорость разработки растет из-за снижения числа возможных ошибок, количество переделок, которые необходимо выполнить при изменении одной части проекта, не растет снежной лавиной по всему коду, а локализуется только в одном слое. Плюс можно грамотно разделить работу между несколькими участниками: код первого слоя пишут программисты — специалисты в области БД, второй слой создается html-кодерами с небольшими навыками в области программирования. Если грамотно согласовать интерфейс первого слоя — названия функций, их параметры, что они будут делать, — то вы можете запустить разработку этих двух слоев вашего приложения (сайта) параллельно. Для проекта, который планирует интенсивно развиваться, послойная организация дает лишние шансы на масштабируемость проекта, на смену используемой СУБД, дает возможность переделывать дизайн (работу второго слоя), не принуждая html-кодеров или дизайнеров лезть в топи первого слоя. Естественно, что о методиках такого разделения труда мечтают давно, разработаны и продолжают совершенствоваться различные паттерны (наиболее известен среди них MVC) и конкретные программные продукты. С другой стороны, на внедрение этих методик требуются начальные затраты и обучение персонала — так что, если вы планируете всю жизнь делать проекты трудоемкостью в пару дней (недель), и дальнейшего развития для них не предусматривается, то вам лучше перевернуть страницу и почитать про что-нибудь другое. Но довольно философии — давайте назовем конкретные имена библиотек, позволяющих реализовать паттерн Table Data Gateway. Итак… это абсолютно все библиотеки. Некоторые, правда, представляют собой дополнительную функциональность и реализуют другие паттерны: Row Gateway, ActiveRecord, DataMapper. Вы можете не искать очередную "серебряную пулю" в виде сторонней библиотеки, а взять стандартные функции mysql или mysqli расширения php. Они прекрасно решают свои задачи. Давайте переформулируем: нам нужна библиотека, которая должна позволять записывать компактно и локализуемо sql-выражения, позволять избегать основных ошибок набора — глупых опечаток, запись sql-команд должна быть удобочитаемой, библиотека не должна позволять забывать об элементарной безопасности кода перед попытками взлома "злобных" хакеров. Сегодня я расскажу о библиотеке dbSimple от Д. Котерова (сайт dklab.ru). Во вступлении к описанию своей библиотеки автор говорит, что пытается и чего не пытается делать его библиотека — просто добавлю пару своих копеек к его словам.
Выравнивание кода. Я крайне негативно отношусь к программным продуктам, которые ставят своей целью эмуляцию возможностей одной СУБД средствами другой или создания программной надстройки, выполняющей такую эмуляцию. Рекламный лозунг "вместе с нашей библиотекой утром вы работаете с oracle, в полдень — с mssql, а вечером — с mysql" глуп и смешон. Я понимаю историческую и коммерческую целесообразность разработчиков "серьезных" СУБД отойти от рекомендуемого для всех стандарта SQL разных ревизий. Понимаю, что унификация набирает темп, и то, что достичь ее никогда не удастся. Мой любимый пример с получением информации о наличных базах данных на сервере, таблицах, полях, ограничениях — все, что называется словом метаинформация. Так, ранее каждая СУБД предлагала свой набор ключевых слов для того, чтобы получить эти сведения. Сейчас же почти повсеместной стала поддержка INFORMATION_SCHEMA (грубо говоря, существует некоторая виртуальная база данных, таблицы которой содержат информацию о других, уже реальных, таблицах, полях, view и прочее). Смена используемой СУБД по определению не может обойтись малой кровью. Чтобы писать быстрый и качественный код, вы должны выжимать все соки из вашей СУБД, а не ограничиваться наиболее простыми, общими для многих СУБД командами. Итак, dbSimple не занимается выравниванием кода и не занимается эмулированием недостающих возможностей некоторой СУБД. Классический пример — постраничная выборка данных, когда мы говорим, что нам нужно не все содержимое таблицы товаров, а только с десятой по двадцатую позиции, и отброс лишних записей выполняется средствами СУБД. Как прекрасно эта функция реализована в mysql, так же ужасно в microsoft sql server до 2005 версии (но решение ведь все равно было). Так что, если вы все еще хотите библиотеку-выравниватель, то вам лучше еще раз перечитать книжку по вашей СУБД.
Например, вы делаете сайт-каталог товаров, в нем страница, где по номеру или названию раздела отбираются вложенные товары. Страницы каталога запрашиваются по правилу: catalog.php?section=12
Здесь 12 — варьирующаяся переменная, которая задает номер раздела, в который зашел клиент, вы как программист пишете внутри страницы catalog.php примерно следующий запрос, отбирающий товары:
select * from articles where section_id = 12
Цифра 12 берется из параметра запроса. И вы подставляете это значение примерно так:
mysql_query ('select * from articles where section_id = ' . $_REQUEST['section'])
Если вы посмотрели на эту строку и согласно закивали головой: мол, все верно, я и сам так пишу, то вас нужно срочно увольнять, а код переписывать, ибо легким движением руки злобного хакера в адресную строку браузера вводится следующий адрес:
catalog.php?section=12;truncate articles
А, следовательно, будет выполнена уже следующая команда:
select * from articles where section_id =12;truncate articles
Символ ";" для mysql означает разделитель команд — значит, будут выполнены две команды: первая безобидная, отбирающая данные из таблицы товаров, а вторая (truncate) — удаляющая из этой таблицы все содержимое. Мир не идеален, и значит, все, абсолютно все данные, которые поступают на вход вашему скрипту и используются в работе (тем более с такой дорогой вещью, как база данных), нужно проверять. Хорошо если база вашего сайта представляет собой слепок с настоящей базы товаров, находящейся в офисе, и каждое утро вы копируете информацию на веб-сервер. А если та база, что находится в Веб, является первичной и единственной? Кто-то скажет: "да кому наш сайт нужен, кто его будет ломать?" Надеюсь, что это сказали не вы, а мы тем временем продолжаем. Как защититься от sql-injection? Я предпочитаю делать два слоя защиты: средствами собственно языка программирования — здесь нужно всего лишь все входные данные проверить на корректность. Получает скрипт в качестве параметра номер раздела каталога или товара — проверь: вдруг это не число. Нужно вставить в sql-запрос в условие отбора по названию товара полученную из html-формы строку с его названием — проверь строку на недопустимость ключевых слов sql (delete, truncate, select, update…) и обязательно заэкранируй все спецсимволы обратным слэшем. Второй уровень защиты — грамотно настроить политику безопасности. Если у вас сайт с каталогом товаров, который правится через веб-интерфейс администратором с одной стороны, и просматривается обычным посетителем сайта — с другой, создайте две учетные записи. При подсоединении от имени первой — полноправной — разрешены все операции с таблицами: правка, удаление, добавление данных. Вторая же запись — для клиента — будет "бесправной" — явно разрешите только те операции (отбор, но не изменение или удаление), и только для тех таблиц (общедоступные товары, но никак не таблица с секретными паролями или финансовыми сведениями клиентов), которые не могут повредить работе сайта. Поверьте, разобраться с политикой безопасности в mysql или mssql очень просто, и эти настройки доступны для любого, даже самого дешевого, хостинга. Что еще нужно от хорошей библиотеки работы с СУБД? Грамотная обработка ошибок, возможность так настроить систему, чтобы вы не могли даже при всем желании проигнорировать возникшую проблему. Мне иногда попадаются сайты, которые не просто не работают — действительно, с кем не бывает, — но при возникновении ошибки вываливают на страницу кучу отладочной информации (пароли, имена переменных, куски sql-кода). Сайты не проверяют, успешно или нет были выполнены запрошенные ими действия, а продолжают идти напролом, вызывая все больше и больше ошибок в других частях программы. Каждая ошибка должна быть отловлена, и вместо нее следует выводить стандартное, ничего не говорящее сообщение: "произошел сбой, зайдите позже".
После такого длительного введения в суть проблемы вернемся к php и нашим кавычкам. Говорят (и я этому даже верю), что разработчики языка php, будучи не в силах заставить основную массу php-программистов писать качественный код, решили позаботиться о безопасности наших СУБД и ввели автоматическое добавление слэшей перед спецсимволами. Слэши добавляются на основании директив php.ini (magic_quotes_gpc и magic_quotes_runtime). Директивы имеют общее название "волшебные кавычки", я же зову их "адские кавычки". Действительно, в грамотно написанном приложении необходимость в автоматическом закавычивании отсутствует, более того: лишние кавычки мешают, и их приходится удалять. Первая директива — magic_quotes_gpc — означает, что PHP автоматически добавляет слэши к данным, пришедшим от пользователя — из POST-, GET-запросов и cookies. Вторая переменная — magic_quotes_runtime — означает, что слэши добавляются к данным, полученным во время исполнения скрипта — например, из файла или базы данных. Так, некоторые функции, представляющие подобную информацию, выполняют ее закавычивание. Если вы хотите отказаться от столь навязчивого сервиса, то либо вы (в той редкой и счастливой ситуации, когда вы полновластный владелец сервера) в файле php.ini отключаете эти конфигурационные переменные, либо (если вы, конечно, не размещаете сайт на бесплатном хостинге) вы можете внести изменения в файл .htaccess. Это файл, в котором находятся локальные — для одного каталога, а не для всего сервера — настройки apache. И добавьте в него следующие строки:
php_flag magic_quotes_gpc 0
php_flag magic_quotes_runtime 0
Внимание: когда вы формируете запрос, вносящий данные в СУБД, и выполнили добавление экранирующих слэшей, то эти слэши будут автоматически удалены сервером СУБД при сохранении изменений, поэтому частая ошибка начинающих в том, чтобы удалять слэши после получения (select выборки) данных из СУБД. Итак, как итог: когда вы записываете команду sql, не забывайте все строки помещать в кавычки и выполнять экранирование самих строк — не полагайтесь на "адские кавычки". Для экранирования спецсимволов следует применять только и только функцию mysql_real_escape_string — эта функция представляет несколько дополнительных сервисов по сравнению со своими младшими братьями, "закавычивающими" addslashes или addcslashes. Прежде всего, эта функция может работать только после установления соединения с mysql-сервером и в своей работе ориентируется на особенности настроек mysql, учитывает кодировку базы данных, кодировку соединения, правильно обрабатывает unicode-строки. Таким образом, конструирование строки запроса должно выглядеть так:
$sql="SELECT * FROM articles WHERE category_name = ' ".mysql_real_escape_string($_REQUEST['category']) . "' ";
Ага, скажут читатели, это же громоздко. Конечно, громоздко, а когда у вас будет в одном запросе использоваться десятка с два полей одновременно, то станет и неудобочитаемым. А неудобочитаемость приводит к потере контроля кода и риску забыть какое-нибудь поле плюс проблема переработки кода. Если на каком-то шаге вы внесли изменения в СУБД, переименовав поле или изменив его тип данных, то следует найти все эти неудобочитаемые куски sql-кода и подправить. Поэтому Д. Котеров (конечно, не первый в мире) предложил и реализовал в своей библиотеке DbSimple концепцию placeholder'ов. Вы пишете запрос, не думая о кавычках, экранировании, но помечаете места, куда должны вставляться данные с помощью специального значка — placeholder'а (обозначающего место). А затем вместо этих placeholder'oв будут вставлены собственно данные, с кавычками по краям и корректно экранированные. Запросы получаются очень компактными — например, так:
SELECT * FROM ?_user where fio = ? LIMIT ?d, ?d
Здесь placeholder — это знак "?", после которого идет некоторый уточняющий символ. Увы, но детально рассказать об placeholder'ах я сегодня никак не успеваю — придется в следующий раз.
Теперь поговорим о проблеме "хочу массив". Дело в том, что стандартные функции php-mysql, получив строку запроса, возвращают вам не собственно набор отобранных данных, а некоторый ресурс — указатель, по которому с помощью других функций можно получить собственно значения полей. Это хорошо и плохо одновременно. Хорошо "тюнингом", оптимизацией программы, экономией ресурсов памяти и CPU. Плохо тем, что требуется выполнять рутинные и однообразные действия по преобразованию данных в формат, привычный для php: массивы, А-массивы (ассоциативный массив). Так вот, dbSimple содержит ряд функций для отбора данных, которые возвращают записи в виде массива, состоящего из А-массивов — каждая запись таблицы в виде А-массива. Есть функции для отбора скалярных величин.
Но об этом в следующий раз, когда я продолжу рассказ о DbSimple. Нас также ждет следующая порция теории о паттернах доступа к данным и практика с парочкой интересных библиотек.
black zorro, black-zorro.jino-net.ru
Компьютерная газета. Статья была опубликована в номере 41 за 2007 год в рубрике программирование
