
Эффективная оцифровка печатной продукции в домашних условиях
Школьникам или студентам не раз приходилось сталкиваться с необходимостью быстрого переноса информации с книжных или журнальных страниц в цифровой формат. Научные статьи, тексты изложений или лекций — вот лишь небольшой перечень того, что приходится сканировать учащемуся. Тем не менее, если число листов в исходном документе переваливает за несколько десятков, возникают серьезные неудобства, потому как назвать сканирование и распознавание каждой страницы в отдельности с помощью FineReader, тем более на компьютере средней мощности и со средненьким сканером, быстрым занятием язык не поворачивается. Столкнувшись недавно с подобной проблемой, я решил поделиться с читателями опытом ее довольно эффективного решения. Итак…
Необходимые инструменты
 Для начала необходим сам сканер. Если у фотографов сканер менее чем за 200 у.е. сканером не является, то для наших целей теоретически подходит абсолютно любая модель. Но на практике, как всегда, есть свои "но". Во-первых, стоит обращать внимание на разрешение, которое может выдать аппарат. Чем выше физическое разрешение (т.е. реальное число светочувствительных элементов на дюйм), тем лучше будет проходить распознавание текста. Для букв крупного размера подойдет и 90 dpi, тогда как для научной статьи, написанной мелким шрифтом, нужно как минимум 300 dpi. Любой современный сканер способен выдать его без проблем, но если планируется использование какого-нибудь "дедушки", то об этом стоит подумать. Также не менее критичным параметром является скорость сканирования. Современные сканеры сканируют быстрее, поэтому они лучше подойдут для оцифровки большого объема.
Для начала необходим сам сканер. Если у фотографов сканер менее чем за 200 у.е. сканером не является, то для наших целей теоретически подходит абсолютно любая модель. Но на практике, как всегда, есть свои "но". Во-первых, стоит обращать внимание на разрешение, которое может выдать аппарат. Чем выше физическое разрешение (т.е. реальное число светочувствительных элементов на дюйм), тем лучше будет проходить распознавание текста. Для букв крупного размера подойдет и 90 dpi, тогда как для научной статьи, написанной мелким шрифтом, нужно как минимум 300 dpi. Любой современный сканер способен выдать его без проблем, но если планируется использование какого-нибудь "дедушки", то об этом стоит подумать. Также не менее критичным параметром является скорость сканирования. Современные сканеры сканируют быстрее, поэтому они лучше подойдут для оцифровки большого объема.
Кроме того, у них выше глубина резкости (параметр, который определяет, на каком расстоянии от стеклянной поверхности сканируемый объект еще будет оставаться более-менее резким), что является просто необходимым условием при сканировании книг с жестким переплетом. Кстати, вспомнив о глубине резкости, стоит отметить, что модели с CCD-приемником более предпочтительны, нежели CIS, т.к. у них эта характеристика всегда лучше. К тому же, цены на первые уже не так высоки, поэтому, покупая сканер для дома, такой девайс уже вполне можно себе позволить. Впрочем, если вы стремитесь к минимально затратному решению, можно приобрести простую современную CIS-модель за 60-70 у.е. Здесь чем проще, тем лучше. Ну, и замечу, что верхняя крышка желательно должна быть съемной, чтобы было комфортнее работать с толстыми книгами. Теперь поговорим о софте. Как известно, с любым компьютерным устройством в комплекте поставляется несколько дисков (либо один) с драйверами и прочими программами, "невероятно" нужными в работе, по мнению разработчиков. В частности, производители сканеров почти всегда снабжают свою продукцию собственной утилитой для сканирования, собственными программами для отсылки отсканированных изображений по электронной почте и т.д. Поверьте, без всего этого можно спокойно обойтись, поэтому при установке пакета программ к сканеру стоит пользоваться выборочным режимом и оставлять лишь драйверы. Все остальное уже включено в ваш дистрибутив Windows.
 Разумеется, мы собираемся сканировать текст для того, чтобы потом его распознать, а потому нужна достойная программа, способная сделать это максимально качественно. И если насчет выбора какого-нибудь текстового редактора еще можно поспорить, то здесь существует единственно верное решение — ABBYY FineReader. Разработка этого приложения ведется уже много лет, и поэтому опыт, накопленный разработчиками в обработке и распознавании текста, огромен. Достаточно сказать, что FineReader (в особенности в последних версиях) совершенно безразличен к цвету отсканированного листа, мелким царапинам или точкам на его поверхности, наклону и пространственной ориентации, а также к печатному шрифту! Вы с одинаковым успехом распознаете текст, напечатанный как на принтере, так и на старинной печатной машинке. Не правда ли, здорово? К слову сказать, последние версии прекрасно справляются с распознаванием текста, сфотографированного с помощью цифрового фотоаппарата. Так что можно даже и без сканера обойтись:). FineReader часто идет в комплекте со сканером, однако почти всегда это какая-нибудь lite-версия для ознакомления. Будет значительно лучше, если вы достанете "нормальную" pro-версию с номером 7 или 8 (идеальный вариант), благо сделать это не так уж и сложно (www.mininova.org в помощь. Из уважения к труду программистов из ABBYY я не выкладываю прямой линк на торрент). За все время существования в FineReader выработалась целая концепция работы со сканируемым документом (понятие пакета), однако, на мой взгляд, она не очень удобна.
Разумеется, мы собираемся сканировать текст для того, чтобы потом его распознать, а потому нужна достойная программа, способная сделать это максимально качественно. И если насчет выбора какого-нибудь текстового редактора еще можно поспорить, то здесь существует единственно верное решение — ABBYY FineReader. Разработка этого приложения ведется уже много лет, и поэтому опыт, накопленный разработчиками в обработке и распознавании текста, огромен. Достаточно сказать, что FineReader (в особенности в последних версиях) совершенно безразличен к цвету отсканированного листа, мелким царапинам или точкам на его поверхности, наклону и пространственной ориентации, а также к печатному шрифту! Вы с одинаковым успехом распознаете текст, напечатанный как на принтере, так и на старинной печатной машинке. Не правда ли, здорово? К слову сказать, последние версии прекрасно справляются с распознаванием текста, сфотографированного с помощью цифрового фотоаппарата. Так что можно даже и без сканера обойтись:). FineReader часто идет в комплекте со сканером, однако почти всегда это какая-нибудь lite-версия для ознакомления. Будет значительно лучше, если вы достанете "нормальную" pro-версию с номером 7 или 8 (идеальный вариант), благо сделать это не так уж и сложно (www.mininova.org в помощь. Из уважения к труду программистов из ABBYY я не выкладываю прямой линк на торрент). За все время существования в FineReader выработалась целая концепция работы со сканируемым документом (понятие пакета), однако, на мой взгляд, она не очень удобна.
 Согласитесь, что лучше выполнить предварительную обработку графического изображения, например, удалив черные края или номера страниц, чем потом мучиться, занимаясь приведением текста в порядок в Microsoft Word. Кроме того, часто сканируемый источник нужно вернуть в краткие сроки, а потому сохранить оригинальное форматирование поможет только графический файл, а не текстовый. Можно, конечно, сканировать каждую отдельную страницу в отдельный графический файл, но есть куда более продвинутые способы. Для этих целей неплохо подходит формат pdf, не правда ли? Вот только как создать pdf-документ?.. Оказывается, это можно сделать с помощью программы Adobe Acrobat. Заметьте: не Acrobat Reader, а просто Acrobat. Компания Adobe выпускает этот пакет для профессиональной работы с pdf, в то время как Reader является лишь средством просмотра. Кстати, Reader, в отличие от своего "старшего" коллеги, бесплатен. Это хороший маркетинговый ход, который позволил формату pdf стать стандартом де-факто в документообороте. Найти Adobe Acrobat можно также на "Мининове", но сразу хочу предупредить, что размер у него нешуточный — около 200 Мб. Преимущество pdf-документа заключается еще и в том, что этот формат поддерживает сжатие изображения, а значит, в оперативной памяти оно будет занимать значительно меньше места при распознавании. Это существенно увеличит скорость процесса. Собственно, для быстрой и эффективной оцифровки больше ничего не потребуется (разве что прямые руки и светлая голова). Можно переходить к практической части.
Согласитесь, что лучше выполнить предварительную обработку графического изображения, например, удалив черные края или номера страниц, чем потом мучиться, занимаясь приведением текста в порядок в Microsoft Word. Кроме того, часто сканируемый источник нужно вернуть в краткие сроки, а потому сохранить оригинальное форматирование поможет только графический файл, а не текстовый. Можно, конечно, сканировать каждую отдельную страницу в отдельный графический файл, но есть куда более продвинутые способы. Для этих целей неплохо подходит формат pdf, не правда ли? Вот только как создать pdf-документ?.. Оказывается, это можно сделать с помощью программы Adobe Acrobat. Заметьте: не Acrobat Reader, а просто Acrobat. Компания Adobe выпускает этот пакет для профессиональной работы с pdf, в то время как Reader является лишь средством просмотра. Кстати, Reader, в отличие от своего "старшего" коллеги, бесплатен. Это хороший маркетинговый ход, который позволил формату pdf стать стандартом де-факто в документообороте. Найти Adobe Acrobat можно также на "Мининове", но сразу хочу предупредить, что размер у него нешуточный — около 200 Мб. Преимущество pdf-документа заключается еще и в том, что этот формат поддерживает сжатие изображения, а значит, в оперативной памяти оно будет занимать значительно меньше места при распознавании. Это существенно увеличит скорость процесса. Собственно, для быстрой и эффективной оцифровки больше ничего не потребуется (разве что прямые руки и светлая голова). Можно переходить к практической части.
Оцифровка
Итак, предположим, что вы установили все необходимое и готовы к оцифровке. Опишем последовательность наших действий:
1. Создаем электронную копию бумажного источника в формате pdf.
2. Проводим начальное редактирование, отрезая края и ненужные черные полосы.
3. Загружаем готовый pdf-документ в FineReader и распознаем сразу весь документ.
4. Экспортируем полученный текст в MS Word для финальной обработки.
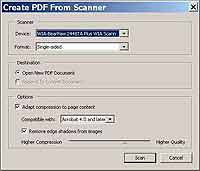
 Шаг 1. Подключаем сканер и кладем в него первую страницу документа. Если сканируется книга, старайтесь, чтобы каждая страница была строго в определенном месте на стеклянной поверхности. Т.к. страницы книги всегда имеют нестандартный размер, а тратить время на предварительный просмотр и определение диапазонов сканирования мы не имеем права по определению, то одинаковое положение листа на изображении поможет в обрезке черных краев. Теперь запускаем Adobe Acrobat и выбираем File -> Create PDF -> From Scanner. Перед вами появится диалоговое окно настроек сканирования. Сразу же отмечаем птицей Remove edge shadows (Убирать тени с краев), в списке Compatible with выбираем Adobe Acrobat 4.0 and later (это уменьшит размер), а ползунок качества/компрессии лучше установить в положение 2/3 от начала, т.е. больше в сторону качества. Теперь можно нажать кнопку Scan. Запустится программа, которая ассоциируется в системе как мастер работы с TWAIN-интерфейсом. Если вы не устанавливали сканирующего агента с прилагаемого диска, то это будет стандартный виндовский апплет WIA. Он хоть и прост как грабли, но зато для наших целей подходит идеально. В появившемся окне сразу жмем на "Настроить качество сканированного изображения". Нам дадут отрегулировать яркость/контрастность, если требуется, а также выставить разрешение и выбрать один из четырех типов изображения.
Шаг 1. Подключаем сканер и кладем в него первую страницу документа. Если сканируется книга, старайтесь, чтобы каждая страница была строго в определенном месте на стеклянной поверхности. Т.к. страницы книги всегда имеют нестандартный размер, а тратить время на предварительный просмотр и определение диапазонов сканирования мы не имеем права по определению, то одинаковое положение листа на изображении поможет в обрезке черных краев. Теперь запускаем Adobe Acrobat и выбираем File -> Create PDF -> From Scanner. Перед вами появится диалоговое окно настроек сканирования. Сразу же отмечаем птицей Remove edge shadows (Убирать тени с краев), в списке Compatible with выбираем Adobe Acrobat 4.0 and later (это уменьшит размер), а ползунок качества/компрессии лучше установить в положение 2/3 от начала, т.е. больше в сторону качества. Теперь можно нажать кнопку Scan. Запустится программа, которая ассоциируется в системе как мастер работы с TWAIN-интерфейсом. Если вы не устанавливали сканирующего агента с прилагаемого диска, то это будет стандартный виндовский апплет WIA. Он хоть и прост как грабли, но зато для наших целей подходит идеально. В появившемся окне сразу жмем на "Настроить качество сканированного изображения". Нам дадут отрегулировать яркость/контрастность, если требуется, а также выставить разрешение и выбрать один из четырех типов изображения.
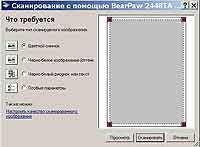
Если книга черно-белая, то выбираете "Черно-белый рисунок или текст" и в зависимости от размера шрифта выставляете разрешение (от 100 для крупного текста до 300 для мелкого). Осталось нажать кнопку Сканировать, чтобы сканируемое изображение начало передаваться в Adobe Acrobat. По окончании процесса передачи появится маленький диалог, в котором можно завершить работу (кнопка Done) либо, нажав Next, отсканировать следующий лист. Естественно, нажимаем Next и вновь оказываемся в WIA. Теперь достаточно только поставить переключатель на "Особые параметры", потому как установленные вами настройки сохраняются в течение всего сеанса, и нажать Сканировать. Повторяем эту операцию сколько нужно раз и нажимаем Done в Acrobat'e по окончанию.
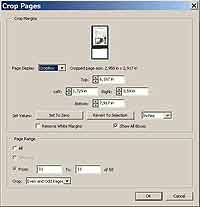
Шаг 2. Теперь нужно подравнять края у страниц, чтобы их отсканированные копии напоминали оригинал. Хотя возможности редактирования изображений в Adobe Acrobat невероятно скудны, инструмент Crop (обрезка) все же реализован (находится на специальной панельке, которую можно вызвать, нажав кнопку Advanced Editing). Им мы и будем орудовать в дальнейшем. Итак, выбираем инструмент и выделяем область, которую нужно оставить. Теперь щелкаем по ней два раза и переходим в диалоговое окно кроппинга. Обратите внимание, насколько продвинутым может быть кроппинг в Adobe Acrobat: мы можем устанавливать границы обрезки в миллиметрах и применять ее сразу ко всем страницам в документе. Помните, я говорил, что страницы книги желательно располагать на одном месте на сканируемой поверхности? Так вот, если вы так делали, то теперь черные границы уберутся со всех страниц автоматически легким движением руки — достаточно в диалоговом окне установить переключатель Page Range в положение All и нажать ОК. Если страницы имеют неравные края, можно дополнительно обработать Crop'ом каждую из них. Теперь необходимо сохранить полученный pdf-документ. Для этого достаточно всего лишь нажать кнопку Save… Все оптимизации размера файла программа произведет за вас.
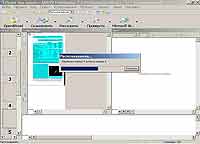
Шаг 3. Следующим шагом необходимо распознать полученный документ. Для начала запускаем FineReader и в меню кнопки Scan&Read выбираем пункт "Открыть и распознать". После выбора нашего документа начнется процесс экспортирования pdf-файла в формат FineReader'a, а затем непосредственно процесс распознавания. На время от компьютера можно отойти, потому что анализ даже пары десятков страниц может занять продолжительное время. Вскоре процесс завершится. Осталось передать полученный текст в текстовый редактор.
Шаг 4. Для экспорта в MS Word в FineReader существует одноименная кнопка. Нажав ее, вы получите оцифрованный текст, который можно редактировать в привычном для вас "Ворде":). Замечу, что при распознавании картинки отделяются от текста и помещаются в финальный документ. Это особенно удобно, т.к. сканировать их повторно вручную не придется. Кстати, если по какой-то причине автоматика сработала неправильно, то можно выделить текстовые блоки в FineReader вручную с помощью одноименного инструмента.
Заключение
Собственно, на сегодня это все. Описанная мной схема оцифровки была успешно опробована на примере перевода в электронный формат двухсотстраничной книги на следующей конфигурации: Duron 1200+, 320 Mb RAM, ABBYY FineReader Professional 7, Adobe Acrobat 6.0. Результатами по отношению к затраченному времени я остался доволен. Однако замечу, что это не единственный способ быстрой оцифровки, поэтому буду рад, если кто- то предложит что-то более совершенное. Всего доброго и до скорых встреч!
Алексей Голованов, AlekseyGolovanov@mail.ru
Необходимые инструменты
Кроме того, у них выше глубина резкости (параметр, который определяет, на каком расстоянии от стеклянной поверхности сканируемый объект еще будет оставаться более-менее резким), что является просто необходимым условием при сканировании книг с жестким переплетом. Кстати, вспомнив о глубине резкости, стоит отметить, что модели с CCD-приемником более предпочтительны, нежели CIS, т.к. у них эта характеристика всегда лучше. К тому же, цены на первые уже не так высоки, поэтому, покупая сканер для дома, такой девайс уже вполне можно себе позволить. Впрочем, если вы стремитесь к минимально затратному решению, можно приобрести простую современную CIS-модель за 60-70 у.е. Здесь чем проще, тем лучше. Ну, и замечу, что верхняя крышка желательно должна быть съемной, чтобы было комфортнее работать с толстыми книгами. Теперь поговорим о софте. Как известно, с любым компьютерным устройством в комплекте поставляется несколько дисков (либо один) с драйверами и прочими программами, "невероятно" нужными в работе, по мнению разработчиков. В частности, производители сканеров почти всегда снабжают свою продукцию собственной утилитой для сканирования, собственными программами для отсылки отсканированных изображений по электронной почте и т.д. Поверьте, без всего этого можно спокойно обойтись, поэтому при установке пакета программ к сканеру стоит пользоваться выборочным режимом и оставлять лишь драйверы. Все остальное уже включено в ваш дистрибутив Windows.
Оцифровка
Итак, предположим, что вы установили все необходимое и готовы к оцифровке. Опишем последовательность наших действий:
1. Создаем электронную копию бумажного источника в формате pdf.
2. Проводим начальное редактирование, отрезая края и ненужные черные полосы.
3. Загружаем готовый pdf-документ в FineReader и распознаем сразу весь документ.
4. Экспортируем полученный текст в MS Word для финальной обработки.
Если книга черно-белая, то выбираете "Черно-белый рисунок или текст" и в зависимости от размера шрифта выставляете разрешение (от 100 для крупного текста до 300 для мелкого). Осталось нажать кнопку Сканировать, чтобы сканируемое изображение начало передаваться в Adobe Acrobat. По окончании процесса передачи появится маленький диалог, в котором можно завершить работу (кнопка Done) либо, нажав Next, отсканировать следующий лист. Естественно, нажимаем Next и вновь оказываемся в WIA. Теперь достаточно только поставить переключатель на "Особые параметры", потому как установленные вами настройки сохраняются в течение всего сеанса, и нажать Сканировать. Повторяем эту операцию сколько нужно раз и нажимаем Done в Acrobat'e по окончанию.
Шаг 2. Теперь нужно подравнять края у страниц, чтобы их отсканированные копии напоминали оригинал. Хотя возможности редактирования изображений в Adobe Acrobat невероятно скудны, инструмент Crop (обрезка) все же реализован (находится на специальной панельке, которую можно вызвать, нажав кнопку Advanced Editing). Им мы и будем орудовать в дальнейшем. Итак, выбираем инструмент и выделяем область, которую нужно оставить. Теперь щелкаем по ней два раза и переходим в диалоговое окно кроппинга. Обратите внимание, насколько продвинутым может быть кроппинг в Adobe Acrobat: мы можем устанавливать границы обрезки в миллиметрах и применять ее сразу ко всем страницам в документе. Помните, я говорил, что страницы книги желательно располагать на одном месте на сканируемой поверхности? Так вот, если вы так делали, то теперь черные границы уберутся со всех страниц автоматически легким движением руки — достаточно в диалоговом окне установить переключатель Page Range в положение All и нажать ОК. Если страницы имеют неравные края, можно дополнительно обработать Crop'ом каждую из них. Теперь необходимо сохранить полученный pdf-документ. Для этого достаточно всего лишь нажать кнопку Save… Все оптимизации размера файла программа произведет за вас.
Шаг 3. Следующим шагом необходимо распознать полученный документ. Для начала запускаем FineReader и в меню кнопки Scan&Read выбираем пункт "Открыть и распознать". После выбора нашего документа начнется процесс экспортирования pdf-файла в формат FineReader'a, а затем непосредственно процесс распознавания. На время от компьютера можно отойти, потому что анализ даже пары десятков страниц может занять продолжительное время. Вскоре процесс завершится. Осталось передать полученный текст в текстовый редактор.
Шаг 4. Для экспорта в MS Word в FineReader существует одноименная кнопка. Нажав ее, вы получите оцифрованный текст, который можно редактировать в привычном для вас "Ворде":). Замечу, что при распознавании картинки отделяются от текста и помещаются в финальный документ. Это особенно удобно, т.к. сканировать их повторно вручную не придется. Кстати, если по какой-то причине автоматика сработала неправильно, то можно выделить текстовые блоки в FineReader вручную с помощью одноименного инструмента.
Заключение
Собственно, на сегодня это все. Описанная мной схема оцифровки была успешно опробована на примере перевода в электронный формат двухсотстраничной книги на следующей конфигурации: Duron 1200+, 320 Mb RAM, ABBYY FineReader Professional 7, Adobe Acrobat 6.0. Результатами по отношению к затраченному времени я остался доволен. Однако замечу, что это не единственный способ быстрой оцифровки, поэтому буду рад, если кто- то предложит что-то более совершенное. Всего доброго и до скорых встреч!
Алексей Голованов, AlekseyGolovanov@mail.ru
Компьютерная газета. Статья была опубликована в номере 39 за 2006 год в рубрике soft
