
ContentSaver поможет не утонуть в море информации
Продукт: ContentSaver
Последняя версия: 2.1.3189 от 9 марта 2006 г.
Сфера применения: сбор, обработка и анализ данных
Разработчик: Macropool GmbH (www.macropool.com)
Модель распространения: shareware (с 30-дневным пробным периодом)
Объем дистрибутива: 10,4 Мб
Стоимость: €22 за студенческую версию, $40 — за персональную, $200 — за сетевую
WWW: сайт
На постоянный рост объемов информации во всех ее проявлениях и со всех сторон каждый реагирует по-разному. Кому-то глубоко плевать на то, что ежегодно в мире создается 1-2 экзабайта (1018) данных. Кого-то проблема лавинообразного роста мировых объемов данных волнует примерно в той же степени, как геополитическая стратегия Америки или голод в Африке — мол, "плохо, конечно, но, пока меня непосредственно не коснется — попой двигать лень". Впрочем, кто-то уже давно ощущает информационную перегрузку и нуждается в серьезных инструментах для упорядочения и каталогизации поступающей информации.
Не знаю, как дело с информационной организованностью обстоит у вас, но для меня это просто беда. Допустим, если для оффлайна эта проблема со скрипом, но решаема (блокнот/органайзер/мобильный телефон/КПК), то для онлайн-работы проблем становится куда больше — равно как и сопутствующих хлопот. Пусть надо найти что-то конкретное. Что же я у себя "локально" откапываю? Какие-то тонны нужных и ненужных .mht'шек, десятки сохраненных целиком html-файлов с устаревшими данными, несколько крупных пересекающихся текстовых хранилищ данных (и в Word'овском формате, и в RTF, и в "чистом тексте"), отдельные тематические каталоги на винчестере с информацией по теме… Мрак. Проще лезть в Google/Яндекс и искать, собирать все заново, нежели пытаться собрать воедино нужные кусочки с захламленных "полок" локального архива. Нет, конечно, теоретически (и даже практически) эту информационную свалку местного масштаба с претензиями на структурированность можно все-таки попытаться организовать. Ну, например, скормить индексаторам (типа Google Desktop, "Архивариус 3000" и иже с ними), получить многогигабайтный индекс и радоваться, как ребенок, на выданные по запросу "Pentium" -надцать тысяч совпадений. 80-99% которых, конечно же, вам никуда не упирались, нужны как рыбе зонтик и т.д. Зачем стрелять из индексационной суперпушки по информационным воробьям? Ведь и на самом деле, их отстрел/отлов куда проще производить при помощи куда более "легких", гибких и удобных специализированных орудий. Например, инструмента немецкой компании Macropool GmbH, ContentSaver.
ContentSaver навскидку
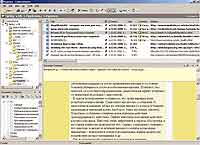 Если вы не уловили cути предыдущих пассажей, скажу просто: ContentSaver позволяет решить все проблемы с организацией получаемых из Сети (и не только) данных. Преимущественно, конечно же, текстовых. Так как в наше время процент этих самых данных очень велик, можно сказать, что ContentSaver позволяет удобно систематизировать практически всю интересующую вас информацию. Как именно? В браузере выделяем нужный текст, по правой кнопке сохраняем его в ContentSaver, определяемся с тематическими разделами, а затем ждем пару секунд, пока программа копирует необходимую нам информацию в свою (нашу?!) базу — по сути, "базу знаний". "Стоп-стоп-стоп! — тотчас вскричит искушенный собиратель интернет- данных. — Очередной костыль для веб-серфера — и зачем столько шума с громким заголовком? Куча ж есть подобного софта: ScrapBook для FireFox, Inquiry, Net Snippets — отчего ажиотаж?" Что ж, поясню: ни одна из вышеупомянутых (безусловно, достойных и вполне полезных) программ не может на равных соперничать с ContentSaver. Если есть желание — скачайте их, установите и убедитесь. Я же продолжу краткий "first look" героя обзора.
Если вы не уловили cути предыдущих пассажей, скажу просто: ContentSaver позволяет решить все проблемы с организацией получаемых из Сети (и не только) данных. Преимущественно, конечно же, текстовых. Так как в наше время процент этих самых данных очень велик, можно сказать, что ContentSaver позволяет удобно систематизировать практически всю интересующую вас информацию. Как именно? В браузере выделяем нужный текст, по правой кнопке сохраняем его в ContentSaver, определяемся с тематическими разделами, а затем ждем пару секунд, пока программа копирует необходимую нам информацию в свою (нашу?!) базу — по сути, "базу знаний". "Стоп-стоп-стоп! — тотчас вскричит искушенный собиратель интернет- данных. — Очередной костыль для веб-серфера — и зачем столько шума с громким заголовком? Куча ж есть подобного софта: ScrapBook для FireFox, Inquiry, Net Snippets — отчего ажиотаж?" Что ж, поясню: ни одна из вышеупомянутых (безусловно, достойных и вполне полезных) программ не может на равных соперничать с ContentSaver. Если есть желание — скачайте их, установите и убедитесь. Я же продолжу краткий "first look" героя обзора.
Так вот, ContentSaver позволяет работать с веб-контентом из браузеров Microsoft Internet Explorer (интеграция с MSIE субъективно реализована лучше всего), Opera, Firefox, а также браузеров-надстроек на движке MSIE. Можно сохранять как страницы (даже группы связанных страниц) целиком, так и отдельные фреймы либо отдельные кусочки текста/картинки. Имеется возможность напрямую редактировать страницы до помещения в базу (например, выделить самое важное "маркером", обрезать боковые колонки) и после того. При необходимости ContentSaver вырежет из сохраняемых данных рекламу, скрипты, картинки и другие "ненужности". Гибкий экспорт (Word, HTML, MHT и др.), импорт из OutLook (при помощи платной надстройки), возможность автоматического создания презентаций из выбранных страниц, система напоминаний ("вернуться к этому документу через определенное время"), удобные средства редактирования и аннотирования материалов, автосжатие и бэкап базы, мощнейшая система поиска с полноценной поддержкой русского языка… Все это — действительно "в одном флаконе", действительно здорово, полезно и удобно. Не только на бумаге, но и в действии. Убедил? Что ж, пока вы настраиваете свои "качалки" для вытягивания последней версии программы или просто скептически хмыкаете, думаю, не лишним будет рассказать про…
Работающий ContentSaver
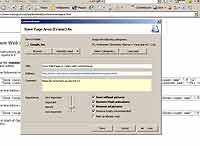
После инсталляции ContentSaver создает пустую базу знаний в собственном формате (.CSA — ContentSaver Archive) и интегрируется в MSIE — это выражается в появлении дополнительной настраиваемой панельки инструментов, а также новых опций в меню по правой кнопке. Для частичной интеграции в Opera понадобится править файл standard_menu.ini ( сайт ), а для работы с ContentSaver'ом через FireFox — скачать небольшое дополнение ( сайт ). Не сахар, конечно — поддержка альтернативных браузеров могла бы быть "роднее". Впрочем, на недостатках ContentSaver остановимся чуть позже, а пока стоит вернуться к изучению функциональных возможностей. Программа фактически состоит из двух частей: интегрирующаяся в браузеры половинка позволяет удобно и просто сохранять нужные данные, а автономная часть (само приложение ContentSaver) отвечает непосредственно за организацию данных, работу с базами, поиск, просмотр и остальные операции. Для пополнения "базы знаний" в браузере понадобится нажать буквально одну кнопку (при этом документ будет сохранен в "предбаннике" — папке New Documents). Если есть желание установить специфические настройки для сохранения или классифицировать документ сразу же — без проблем: выбираем в "правокнопочном" меню или на панели инструментов ContentSaver: Save [объект] As… (в роли объекта может выступать страница, фрейм, выделенный фрагмент, снимок экрана или URL-адрес) и настраиваем все параметры сохранения по собственному желанию. Можно сразу поменять название документа в базе (по умолчанию устанавливается заглавие страницы, для фрагментов — первое предложение из текста), установить критерий важности, выбрать варианты обработки (не сохранять картинки/флэш/баннеры/скрипты, пометить как уже прочитанное) и, наконец, определиться с "физическим" и "логическим" местоположением документа в базе.
На последней возможности, пожалуй, стоит остановиться подробнее. ContentSaver, в отличие от подавляющего большинства других "сохранялок", позволяет организовывать контент на двух уровнях. Первый уровень организации — банальный набор внутренних папок в базе, где хранится документ. Рекомендую не проявлять излишнего усердия, а создать просто набор папок с максимально широким тематическим охватом (типа "Железо", "Софт", "Политика", "История" и т.д.), куда можно было бы быстро определять всех "новоприбывших". Второй уровень — это категории документа, позволяющие относить документ сразу к нескольким виртуальным секциям, классифицируя его по многим темам/признакам одновременно. Вот тут уже все зависит от вас и вашей дотошности — ориентируясь на предложенный разработчиками вариант, и создайте наиболее подходящий для собственных нужд классификатор. Как это будет выглядеть? Ну, например, документ с данными тестов новейших процессоров AMD и Intel, расположившийся в подпапке Процессоры папки Железо, можно определить в десяток различных категорий и подкатегорий (обозначены слэшем): "Проверить достоверность", "Компании/Intel", "Процессоры Intel/Conroe", "Компании/AMD", "Процессоры AMD/X2", "Тип документа/Данные тестов", "Вечные темы/AMDvsIntel", "Источники/Непроверенные" и т.д. Теперь, когда вам в один прекрасный день понадобится найти, скажем, все документы со сравнительными тестами процессоров Intel и AMD, вам нужно будет сделать буквально несколько кликов — выделить в окошке поиска категории "Компании/Intel", "Компании/AMD", а также "Тип документа/Данные тестов" — вуаля — найденные странички ContentSaver услужливо поместит в служебную папку с результатами поиска (Search Results). Кроме нее, кстати, имеется также служебная папка с адресами веб-страничек (Internet Adresses) — продвинутая альтернатива внутрибраузерным Favourites, мусорная корзина с удаленными данными (Deleted Documents) и папка с новыми документами (New Documents) — туда попадает весь контент, который вы поленились сразу классифицировать. Пожалуй, эта лень ("человеческий фактор") — главная проблема подобного тщательного подхода к организации информации. Стоит лишь пару дней/недель/месяцев полениться аккуратно расставлять сохраняемые ContentSaver'ом данные по полочкам, и все: размеры New Documents растут как на дрожжах, а сама папка быстро превращается в обычную инфопомойку вроде бумажного блокнота…
 На остальных возможностях вряд ли стоит подробно останавливаться — надеюсь, что "sapienti sat", т.е. умному будет достаточно названий функций и их описаний прямо в интерфейсе. Ну, а тем, кто не "sapienti", тому вряд ли ContentSaver вообще понадобится;). Единственный минус — все на английском (немецком), и русификаторов/language pack'ов пока не попадалось. Считаю, что дружащим с английским пользоваться ContentSaver'ом будет действительно удобно: интерфейс явно делался ровными руками в тандеме с неглупой головой (что, к сожалению, ныне редкость), благодаря чему получился весьма и весьма достойным. Все, что может быть хоть чуточку неинтуитивным, поясняется тут же, не отходя от кассы. Все вышесказанное относится к персональной версии ContentSaver — а ведь существует еще "сетевая версия", CS Server, позволяющая удобно управлять процессом сбора информации в крупных коллективах и организациях! При этом сами данные централизованно хранятся в базе данных (движок — MS SQL Server).
На остальных возможностях вряд ли стоит подробно останавливаться — надеюсь, что "sapienti sat", т.е. умному будет достаточно названий функций и их описаний прямо в интерфейсе. Ну, а тем, кто не "sapienti", тому вряд ли ContentSaver вообще понадобится;). Единственный минус — все на английском (немецком), и русификаторов/language pack'ов пока не попадалось. Считаю, что дружащим с английским пользоваться ContentSaver'ом будет действительно удобно: интерфейс явно делался ровными руками в тандеме с неглупой головой (что, к сожалению, ныне редкость), благодаря чему получился весьма и весьма достойным. Все, что может быть хоть чуточку неинтуитивным, поясняется тут же, не отходя от кассы. Все вышесказанное относится к персональной версии ContentSaver — а ведь существует еще "сетевая версия", CS Server, позволяющая удобно управлять процессом сбора информации в крупных коллективах и организациях! При этом сами данные централизованно хранятся в базе данных (движок — MS SQL Server).
Идеальный ContentSaver
Идеалов не бывает, сами понимаете. И, конечно же, рассматриваемая программа — не более чем одинокий путник (все остальные круто отстали) на трудной стезе к званию "идеальный хранитель-систематизатор веб-контента". Да-да, пришла пора поговорить о недостатках и нереализованных (но нужных — по моему скромному мнению) возможностях ContentSaver. Благо и тех, и тех хватает. В первую очередь, остановлюсь на важнейшем концептуальном недостатке — базах собственного формата ContentSaver. Конечно, здорово, когда все хранится в одном месте, а также удобно систематизируется, но ведь и "гикнуться" нажитые непосильным браузерным трудом сотни мегабайт могут в один момент! Конечно, различные автоматические (и ручные — не пренебрегайте ими!) бэкап-процедуры позволяют сильно снизить вероятность такого малоприятного исхода, но… Но все же недостаток остается таковым — пусть даже без него были бы невозможны и многие достоинства. Второй, куда более приземленный, минус ContentSaver'а — его глюки. В частности, нередки вылеты как "браузерной", так и самостоятельной частей программы: моя версия продукта завершалась с ошибкой практически всегда, когда я пытался открыть во весь экран из базы данных сохраненную только что страничку. К тому же, случалось, программа подвисала и во время сохранения… В общем, по направлению отлова багов разработчикам скучать не придется. Среди проблем рангом пониже — далеко не идеальная интеграция с Opera/Firefox, нередко искажаемая при сохранении разметка страничек, а также наличие ряда малозаметных, но столь же малоприятных огрехов в интерфейсе вроде невозможности вручную напрямую расставлять порядок следования документов в папке. Кроме борьбы с ошибками, есть и буквально напрашивающиеся пути расширения функциональности ContentSaver: синхронизация информации между различными базами, шифрование архивов-баз и закрытие их паролем. Кроме того, не удержусь и озвучу свою голубую мечту, за качественную реализацию которой и 50, и 100 долларов не жалко было бы отдать: хотелось бы автоматической интеллектуальной и полноценной классификации документов без участия пользователя. Нажимаете кнопочку Сохранить, а программа автоматически расставляет документ по категориям — вам остается лишь подтвердить либо подкорректировать работу ее искусственного интеллекта… Э-э-эх, мечты-мечты! Пора все же возвращаться в реальный мир и подводить итоги.
Итоги
Несмотря на то, что программа далека от идеала, трудно (если вообще возможно) найти что-то более функциональное и удобное для хранения и классификации интернет-данных. Если вы не просто бесцельно шаритесь по Сети, забывая о том, что просматривали три минуты назад, а предпочитаете накапливать и впоследствии активно пользоваться cобранной информацией, то лучшего электронного помощника, чем этот, вам не сыскать. Воплощенное в ContentSaver педантичное изысканное немецкое качество, поверьте, стоит своих денег. Ведь ценность информации без возможности своевременного и полноценного к ней доступа стремится к нулю, а в наш век от работы с информацией никуда не денешься. Так что берите программу на заметку, качайте и пользуйтесь — надеюсь, она будет вам столь же полезна, сколь оказалась полезна мне и десяткам тысяч пользователей по всему миру.
P.S. Поговаривают, что файл WINDISK:\Documents and Settings\All Users\Application Data\Microsoft\HTML Help\mshtml8.bin каким-то образом связан с расчетом оставшегося trial-срока… Попробуйте поэкспериментировать, если вдруг 30 дней окажется мало для всестороннего тестирования ContentSaver и/или поиска n-ой суммы в инвалюте;).
[+] Продуманная и четкая система систематизации контента.
[+] Гибкость настроек и удобство пользования.
[+] Прекрасный уровень интеграции с Internet Explorer.
[-] Не всегда корректное сохранение структуры и оформления веб-страниц.
[-] Глючность, далекая от идеала интеграция с Opera.
[=] Изящное, мощное и гибкое решение для ведения персональной "базы знаний".
Николай "Nickky" Щетько, me@nickky.com
Последняя версия: 2.1.3189 от 9 марта 2006 г.
Сфера применения: сбор, обработка и анализ данных
Разработчик: Macropool GmbH (www.macropool.com)
Модель распространения: shareware (с 30-дневным пробным периодом)
Объем дистрибутива: 10,4 Мб
Стоимость: €22 за студенческую версию, $40 — за персональную, $200 — за сетевую
WWW: сайт
На постоянный рост объемов информации во всех ее проявлениях и со всех сторон каждый реагирует по-разному. Кому-то глубоко плевать на то, что ежегодно в мире создается 1-2 экзабайта (1018) данных. Кого-то проблема лавинообразного роста мировых объемов данных волнует примерно в той же степени, как геополитическая стратегия Америки или голод в Африке — мол, "плохо, конечно, но, пока меня непосредственно не коснется — попой двигать лень". Впрочем, кто-то уже давно ощущает информационную перегрузку и нуждается в серьезных инструментах для упорядочения и каталогизации поступающей информации.
Не знаю, как дело с информационной организованностью обстоит у вас, но для меня это просто беда. Допустим, если для оффлайна эта проблема со скрипом, но решаема (блокнот/органайзер/мобильный телефон/КПК), то для онлайн-работы проблем становится куда больше — равно как и сопутствующих хлопот. Пусть надо найти что-то конкретное. Что же я у себя "локально" откапываю? Какие-то тонны нужных и ненужных .mht'шек, десятки сохраненных целиком html-файлов с устаревшими данными, несколько крупных пересекающихся текстовых хранилищ данных (и в Word'овском формате, и в RTF, и в "чистом тексте"), отдельные тематические каталоги на винчестере с информацией по теме… Мрак. Проще лезть в Google/Яндекс и искать, собирать все заново, нежели пытаться собрать воедино нужные кусочки с захламленных "полок" локального архива. Нет, конечно, теоретически (и даже практически) эту информационную свалку местного масштаба с претензиями на структурированность можно все-таки попытаться организовать. Ну, например, скормить индексаторам (типа Google Desktop, "Архивариус 3000" и иже с ними), получить многогигабайтный индекс и радоваться, как ребенок, на выданные по запросу "Pentium" -надцать тысяч совпадений. 80-99% которых, конечно же, вам никуда не упирались, нужны как рыбе зонтик и т.д. Зачем стрелять из индексационной суперпушки по информационным воробьям? Ведь и на самом деле, их отстрел/отлов куда проще производить при помощи куда более "легких", гибких и удобных специализированных орудий. Например, инструмента немецкой компании Macropool GmbH, ContentSaver.
ContentSaver навскидку
Так вот, ContentSaver позволяет работать с веб-контентом из браузеров Microsoft Internet Explorer (интеграция с MSIE субъективно реализована лучше всего), Opera, Firefox, а также браузеров-надстроек на движке MSIE. Можно сохранять как страницы (даже группы связанных страниц) целиком, так и отдельные фреймы либо отдельные кусочки текста/картинки. Имеется возможность напрямую редактировать страницы до помещения в базу (например, выделить самое важное "маркером", обрезать боковые колонки) и после того. При необходимости ContentSaver вырежет из сохраняемых данных рекламу, скрипты, картинки и другие "ненужности". Гибкий экспорт (Word, HTML, MHT и др.), импорт из OutLook (при помощи платной надстройки), возможность автоматического создания презентаций из выбранных страниц, система напоминаний ("вернуться к этому документу через определенное время"), удобные средства редактирования и аннотирования материалов, автосжатие и бэкап базы, мощнейшая система поиска с полноценной поддержкой русского языка… Все это — действительно "в одном флаконе", действительно здорово, полезно и удобно. Не только на бумаге, но и в действии. Убедил? Что ж, пока вы настраиваете свои "качалки" для вытягивания последней версии программы или просто скептически хмыкаете, думаю, не лишним будет рассказать про…
Работающий ContentSaver
После инсталляции ContentSaver создает пустую базу знаний в собственном формате (.CSA — ContentSaver Archive) и интегрируется в MSIE — это выражается в появлении дополнительной настраиваемой панельки инструментов, а также новых опций в меню по правой кнопке. Для частичной интеграции в Opera понадобится править файл standard_menu.ini ( сайт ), а для работы с ContentSaver'ом через FireFox — скачать небольшое дополнение ( сайт ). Не сахар, конечно — поддержка альтернативных браузеров могла бы быть "роднее". Впрочем, на недостатках ContentSaver остановимся чуть позже, а пока стоит вернуться к изучению функциональных возможностей. Программа фактически состоит из двух частей: интегрирующаяся в браузеры половинка позволяет удобно и просто сохранять нужные данные, а автономная часть (само приложение ContentSaver) отвечает непосредственно за организацию данных, работу с базами, поиск, просмотр и остальные операции. Для пополнения "базы знаний" в браузере понадобится нажать буквально одну кнопку (при этом документ будет сохранен в "предбаннике" — папке New Documents). Если есть желание установить специфические настройки для сохранения или классифицировать документ сразу же — без проблем: выбираем в "правокнопочном" меню или на панели инструментов ContentSaver: Save [объект] As… (в роли объекта может выступать страница, фрейм, выделенный фрагмент, снимок экрана или URL-адрес) и настраиваем все параметры сохранения по собственному желанию. Можно сразу поменять название документа в базе (по умолчанию устанавливается заглавие страницы, для фрагментов — первое предложение из текста), установить критерий важности, выбрать варианты обработки (не сохранять картинки/флэш/баннеры/скрипты, пометить как уже прочитанное) и, наконец, определиться с "физическим" и "логическим" местоположением документа в базе.
На последней возможности, пожалуй, стоит остановиться подробнее. ContentSaver, в отличие от подавляющего большинства других "сохранялок", позволяет организовывать контент на двух уровнях. Первый уровень организации — банальный набор внутренних папок в базе, где хранится документ. Рекомендую не проявлять излишнего усердия, а создать просто набор папок с максимально широким тематическим охватом (типа "Железо", "Софт", "Политика", "История" и т.д.), куда можно было бы быстро определять всех "новоприбывших". Второй уровень — это категории документа, позволяющие относить документ сразу к нескольким виртуальным секциям, классифицируя его по многим темам/признакам одновременно. Вот тут уже все зависит от вас и вашей дотошности — ориентируясь на предложенный разработчиками вариант, и создайте наиболее подходящий для собственных нужд классификатор. Как это будет выглядеть? Ну, например, документ с данными тестов новейших процессоров AMD и Intel, расположившийся в подпапке Процессоры папки Железо, можно определить в десяток различных категорий и подкатегорий (обозначены слэшем): "Проверить достоверность", "Компании/Intel", "Процессоры Intel/Conroe", "Компании/AMD", "Процессоры AMD/X2", "Тип документа/Данные тестов", "Вечные темы/AMDvsIntel", "Источники/Непроверенные" и т.д. Теперь, когда вам в один прекрасный день понадобится найти, скажем, все документы со сравнительными тестами процессоров Intel и AMD, вам нужно будет сделать буквально несколько кликов — выделить в окошке поиска категории "Компании/Intel", "Компании/AMD", а также "Тип документа/Данные тестов" — вуаля — найденные странички ContentSaver услужливо поместит в служебную папку с результатами поиска (Search Results). Кроме нее, кстати, имеется также служебная папка с адресами веб-страничек (Internet Adresses) — продвинутая альтернатива внутрибраузерным Favourites, мусорная корзина с удаленными данными (Deleted Documents) и папка с новыми документами (New Documents) — туда попадает весь контент, который вы поленились сразу классифицировать. Пожалуй, эта лень ("человеческий фактор") — главная проблема подобного тщательного подхода к организации информации. Стоит лишь пару дней/недель/месяцев полениться аккуратно расставлять сохраняемые ContentSaver'ом данные по полочкам, и все: размеры New Documents растут как на дрожжах, а сама папка быстро превращается в обычную инфопомойку вроде бумажного блокнота…
Идеальный ContentSaver
Идеалов не бывает, сами понимаете. И, конечно же, рассматриваемая программа — не более чем одинокий путник (все остальные круто отстали) на трудной стезе к званию "идеальный хранитель-систематизатор веб-контента". Да-да, пришла пора поговорить о недостатках и нереализованных (но нужных — по моему скромному мнению) возможностях ContentSaver. Благо и тех, и тех хватает. В первую очередь, остановлюсь на важнейшем концептуальном недостатке — базах собственного формата ContentSaver. Конечно, здорово, когда все хранится в одном месте, а также удобно систематизируется, но ведь и "гикнуться" нажитые непосильным браузерным трудом сотни мегабайт могут в один момент! Конечно, различные автоматические (и ручные — не пренебрегайте ими!) бэкап-процедуры позволяют сильно снизить вероятность такого малоприятного исхода, но… Но все же недостаток остается таковым — пусть даже без него были бы невозможны и многие достоинства. Второй, куда более приземленный, минус ContentSaver'а — его глюки. В частности, нередки вылеты как "браузерной", так и самостоятельной частей программы: моя версия продукта завершалась с ошибкой практически всегда, когда я пытался открыть во весь экран из базы данных сохраненную только что страничку. К тому же, случалось, программа подвисала и во время сохранения… В общем, по направлению отлова багов разработчикам скучать не придется. Среди проблем рангом пониже — далеко не идеальная интеграция с Opera/Firefox, нередко искажаемая при сохранении разметка страничек, а также наличие ряда малозаметных, но столь же малоприятных огрехов в интерфейсе вроде невозможности вручную напрямую расставлять порядок следования документов в папке. Кроме борьбы с ошибками, есть и буквально напрашивающиеся пути расширения функциональности ContentSaver: синхронизация информации между различными базами, шифрование архивов-баз и закрытие их паролем. Кроме того, не удержусь и озвучу свою голубую мечту, за качественную реализацию которой и 50, и 100 долларов не жалко было бы отдать: хотелось бы автоматической интеллектуальной и полноценной классификации документов без участия пользователя. Нажимаете кнопочку Сохранить, а программа автоматически расставляет документ по категориям — вам остается лишь подтвердить либо подкорректировать работу ее искусственного интеллекта… Э-э-эх, мечты-мечты! Пора все же возвращаться в реальный мир и подводить итоги.
Итоги
Несмотря на то, что программа далека от идеала, трудно (если вообще возможно) найти что-то более функциональное и удобное для хранения и классификации интернет-данных. Если вы не просто бесцельно шаритесь по Сети, забывая о том, что просматривали три минуты назад, а предпочитаете накапливать и впоследствии активно пользоваться cобранной информацией, то лучшего электронного помощника, чем этот, вам не сыскать. Воплощенное в ContentSaver педантичное изысканное немецкое качество, поверьте, стоит своих денег. Ведь ценность информации без возможности своевременного и полноценного к ней доступа стремится к нулю, а в наш век от работы с информацией никуда не денешься. Так что берите программу на заметку, качайте и пользуйтесь — надеюсь, она будет вам столь же полезна, сколь оказалась полезна мне и десяткам тысяч пользователей по всему миру.
P.S. Поговаривают, что файл WINDISK:\Documents and Settings\All Users\Application Data\Microsoft\HTML Help\mshtml8.bin каким-то образом связан с расчетом оставшегося trial-срока… Попробуйте поэкспериментировать, если вдруг 30 дней окажется мало для всестороннего тестирования ContentSaver и/или поиска n-ой суммы в инвалюте;).
[+] Продуманная и четкая система систематизации контента.
[+] Гибкость настроек и удобство пользования.
[+] Прекрасный уровень интеграции с Internet Explorer.
[-] Не всегда корректное сохранение структуры и оформления веб-страниц.
[-] Глючность, далекая от идеала интеграция с Opera.
[=] Изящное, мощное и гибкое решение для ведения персональной "базы знаний".
Николай "Nickky" Щетько, me@nickky.com
Компьютерная газета. Статья была опубликована в номере 11 за 2006 год в рубрике софт
