
Что день грядущий (в лице Intel) нам готовит, или по следам московского Intel Developer Forum 2003
Что день грядущий (в лице Intel) нам готовит,
или по следам московского Intel Developer Forum 2003
Отгремел IDF, и пришло время свести воедино всю информацию с форума, его технических сессий и других источников о новых технологиях Intel и совсем уже близком будущем IT-индустрии. Azalia, WiMAX, La-Grande, Vanderpool, Mani-toba — что стоит за этими красивыми названиями? О них (и не только о них) читайте в этой статье.
Не стану утомлять вас длинными предисловиями и переливаниями из пустого в порожнее — cразу перейду к делу. Но для начала стоит немного познакомить вас со структурой материала. В первой части я расскажу о технологиях ("T"-s) от Intel: как уже известных (Hyperthre-ading, Centrino), так и достаточно недавно появившихся на слуху LaGrande и Vanderpool. Завершит "первую часть" статьи интервью с Викторией Жислиной из команды разработчиков набора технологий "3D Talking Heads" (Нижегородский Центр Исследований и Разработки ПО Intel). Во второй части статьи разговор пойдет о новой, активно продвигаемой Intel, шине PCI Express, стандартах Serial ATA I и II, организации WiMAX для продвижения услуг и оборудования сетей 802.16a, интегрированной звуковой системе Azalia, а также продуктах Intel для наладонников (чипы серии PXA, базирующиеся на RISC ядре XScale). В заключении поговорим о планах Intel по производству процессоров для настольных систем, а также новых технологиях по дальнейшей миниатюризации чипов. Ну что, приступим?
"T"-s: Hyperthreading, Centrino, LaGrande, Vanderpool
За грубой силой (количеством гигагерцев) стоят функциональные возможности систем. Технологии ("T"-s) Intel призваны улучшить производительность, функциональность, "мобильность" и защищенность настольных/мобильных/серверных систем. Поговорим о каждой из них по порядку. Про Hyperthreading Technology (HT) слышали если не все, то, уверен, многие. Это технология логической двухпроцессорности, впервые реализованная в дорогих процессорах Xeon, нынче ставшая доступной "простым смертным" в топовых процессорах Intel Pentium 4. Физический процессор в большинстве случаев загружен не на 100% и постоянно переключается между выполнением различных задач (потоков). Intel реализовала технологию Hyperthreading, которая позволяет операционной системе "разбрасывать" потоки на два логических процессора, что, в теории, может увеличить производительность системы на треть, максимально эффективно задействовав вычислительные возможности процессора. На практике результат выглядит скромнее: 5-15% прироста в лучшем случае и падение производительности (до 10% и более) — в худшем. Дело в том, что для эффективного использования возможностей, предоставляемых HT, программное обеспечение должно быть написано с учетом особенностей технологии. Старый софт не использует специальной команды (pause) в режиме ожидания, и поэтому его потоки при простое блокируют определенные ресурсы процессора. Кстати, написанию приложений, эффективно использующих многопоточность в сочетании с HТ, было уделено особое внимание на тематических семинарах. Соответствующие компиляторы с оптимизацией под HT от Intel давно готовы, и программистам остается лишь перекомпилировать свои приложения. После должной оптимизации цифра в 30% прироста может стать вполне реальной. С одной стороны, даже теперешние 5%-15% прироста — немного, но если учесть, что эта разница в производительности достается нам практически "бесплатно", то становится очень приятно;) С постепенной оптимизацией ПО под Hyperthreading Technology, думаю, выгода от ее использования значительно возрастет.
Centrino Mobile Technology (CMT) — первый случай объединения компанией Intel нескольких технологий (в данном случае — "мобильных") под одной торговой маркой. Технологий, обеспечивающих снижение энергопотребления, увеличение производительности и качественную беспроводную связь (Wi-Fi, 802.11b). Строго говоря, Centrino представляет собой сочетание процессора Pentium M, набора системной логики Intel 855 (855GM — со встроенной графикой, 855PM — со внешней) и сетевого интерфейса Intel PRO/Wireless 2100. Pentium M (шина — 400 Mhz) производится по 0.13-микронной технологии и очень эффективно управляет собственным энергопотреблением (Intel SpeedStep), причем, малая "прожорливость" отнюдь не мешает ему показывать высокие результаты по быстродействию. Чипсет также поддерживает Intel SpeedStep, а также режим "глубокой спячки" Deeper Sleep и другие усовершенствования, направленные на снижение энергопотребления. Intel 855 поддерживает до 2 GB PC2100 DDR памяти и USB 2.0. Intel PRO/Wireless 2100 отвечает за связь с точками доступа 802.11b Wi-Fi и призван также минимизировать помехи от использования продуктов на Bluetooth. Основной упор в Centrino, как вы уже поняли, сделан на "мобильность" (беспроводной Wi-Fi доступ) и увеличение длительности "жизни" ноутбука при питании от батарей.
Защиту данных на аппаратном уровне должна обеспечить новая архитектура LaGrande Technology (LT). LaGrande используется для защиты конфиденциальных данных, в основном, от программных атак на сети и системы, а также для нейтрализации "шпионского" ПО (вроде кейлоггеров). В TPM (Trusted Platform Module, микросхеме на материнской плате) хранится информация о кодировании данных, необходимая для воздвижения "кирпичной стены" (организации защищенной области) вокруг приложения и его данных в памяти. Вдобавок организуются защищенные ("доверительные") каналы между приложениями и средствами ввода/вывода. Для реализации фирменной доменной структуры (аппаратно-программная защита областей памяти от несанкционированного доступа), чтобы LaGrande проявила себя, понадобится процессор и чипсет с поддержкой этой технологии, TPM версии 1.2 (в этом чипе находится аутентификационная информация, сертификаты, ключи и т.п.), а также видеокарта с клавиатурой, поддерживающие "защищенный канал" между ПО и графической подсистемой/подсистемой ввода. Честно говоря, не знаю, насколько это будет оправдано и когда введено в строй. Даже если компоненты с поддержкой LT будут продаваться по доступной цене, в ближайшее время, думаю, массового перехода на LT не произойдет. Так или иначе, будем ждать дальнейших новостей о технологии.
О Vanderpool Technology (VT) до сих пор не было сказано ничего конкретного (правда, технология была уже несколько раз продемонстрирована: перезагрузка одной "виртуальной машины" никак не помешала другой проигрывать мультфильмы с DVD). Из всех "Т"-s она остается самой таинственной, что ли:) Судя по всему, Vanderpool будет аппаратно-программной технологией, позволяющей создавать нечто вроде виртуальных независимых друг от друга машин ("разделов") на одном компьютере. Об особенностях ее реализации вы обязательно узнаете, когда Intel соблаговолит открыть карты.
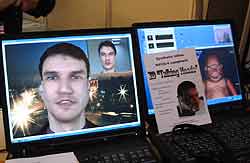
"3D Talking Heads"
Весьма любопытный, на мой взгляд, набор технологий для распознавания и визуализации мимики представил Нижегородский Центр Исследований и Разработки ПО Intel. Виктория Жислина из команды разработчиков "3D Talking Heads" любезно согласилась ответить на мои вопросы о продукте:
КГ: Добрый день, Виктория! Расскажите, пожалуйста, нашим читателям о вашей разработке, технологии "3D Talking Heads".
Виктория Жислина: "3D Talking Heads" ("Трехмерные Говорящие Головы") — это сокращенное название проекта, осуществленного в Нижегородском Центре Исследований и Разработки п\о компании INTEL(iNNL). Полное название нашей разработки "Synthetic Video: MPEG4 compliant 3D Talking Heads" (Синтетическое видео: MPEG4 совместимые 3D Говорящие Головы). А сама разработка представляет собой набор независимых технологий, которые могут быть использованы как совместно, так и по отдельности во многих приложениях, связанных с созданием и анимированием синтетических трехмерных говорящих персонажей.
Расскажите, пожалуйста, о технологиях набора поподробнее...
Первая технология — это автоматическое распознавание и слежение (так называемый трекинг) за мимикой и движениями головы человека на видеопоследовательности. Эта технология представлена в двух вариантах: режим реального времени (25 кадров в секунду на процессоре Pentium 4 1.7GHz), когда отслеживается человек, непосредственно стоящий перед видеокамерой, соединенной с компьютером; и оффлайн режим (со скоростью 1 кадр в секунду). В этом режиме распознавание и трекинг проходят по предварительно записанному видеофрагменту. При этом в реальном времени отслеживается динамика изменения положения/состояния человеческого лица. Мы можем приблизительно оценить углы поворота и наклона головы во всех плоскостях, примерную степень открывания и растяжения рта, поднятия бровей, распознать моргание. Для некоторых приложений такой приблизительной оценки достаточно, но, если нужно точно отследить мимику человека, то необходимы более сложные алгоритмы, а значит, увы, более медленные. В оффлайн режиме наша технология позволяет оценить не только положение головы в целом, но также абсолютно точно распознать и отследить внешние и внутренние контуры губ и зубов при разговоре, положение бровей, степень прикрытия глаз и даже смещение зрачков (направление взгляда).
Как это реализовано?
Для распознавания и слежения мы используем комбинацию общеизвестных алгоритмов (часть из которых реализована в библиотеке OpenCV) и собственных оригинальных методов. На основе полученных данных мы вычисляем параметры анимации лица, которые полностью соответствуют Facial Animation Parameters (FAP) стандарта MPEG-4. Здесь необходимо сказать несколько слов про стандарт MPEG-4. Немногие знают, что, помимо кодирования (сжатия) реальных аудио и видео потоков, этот стандарт предусматривает кодирование информации о синтетических объектах и их анимации (синтетическое видео). Одним из таких объектов и является человеческое лицо, заданное в виде 3D (триангулированной поверхности (сетки) в 3D пространстве). MPEG-4 определяет на лице человека особые точки — уголки и середины губ, глаз, бровей и т.д. К этим особым точкам (или ко всей модели в целом) и применяются анимационные параметры (FAP), описывающие изменение положения и выражения лица по сравнению с нейтральным состоянием. То есть, описание каждого кадра выглядит как набор параметров, по которым MPEG-4 декодер должен анимировать модель.
Это все было о первой технологии. А что с остальными?
Вторая наша технология имеет непосредственное отношение к MPEG-4 — это автоматическая анимация в реальном времени произвольных трехмерных моделей голов в соответствии с имеющимися параметрами анимации, полученными при помощи наших алгоритмов распознавания и трекинга или из любых других источников (например, TextTo-Speech). При этом, единственное требование, накладываемое на модель — ее соответствие MPEG-4 стандарту. И, наконец, третья технология — автоматическое создание фотореалистичной модели головы конкретного человека (прототипа), персонализация существующей "модели абстрактного человека" с использованием либо двух фотографий человека-прототипа (вид спереди и сбоку), либо видеопоследовательности, на которой человек поворачивает голову от одного плеча к другому. Персонализация выполняется в оффлайн режиме (занимает порядка 10 минут), ее алгоритмы разработаны совместно с исследовательской группой Московского Государственного Университета.
А как эта "сумма технологий" будет применяться на практике?
Один из возможных способов использования наших технологий был продемонстрирован на IDF: синтетическая видеоконференция в реальном времени, включающая в себя автоматическое распознавание и отслеживание мимики и движений головы говорящего человека, расчет и передачу по сети параметров анимации лица, анимацию и визуализацию произвольной модели в соответствии с полученными параметрами анимации. Стоит отметить, что, в отличие от обычной видеоконференции, которая требует большой пропускной способности сети (передается все изображение каждого кадра), синтетическая видеоконференция рассчитана на работу в условиях очень низкой пропускной способности сети — достаточно всего 2 Кбод (ведь каждый кадр описывается всего несколькими числами-параметрами анимации). Поэтому, синтетическое видео — это хорошее решение для различных мобильных устройств или модемных линий, где пропускная способность канала передачи физически ограничена.
Существуют ли у вашей разработки аналоги в мире?
Есть масса компаний, которые занимаются как распознаванием и слежением за лицом, так и персонализацией и анимацией "говорящих голов". Назовем только несколько самых известных имен: BioVirtual, Eyematic, face2face, Famous3D, Matrox&Digimask, SeeStorm, Haptek. У всех этих компаний, безусловно, есть достижения в некоторых областях: у кого-то отличного качества модели, кто-то показывает очень реалистичную анимацию, кто-то достиг успехов в распознавании и слежении за лицом. Но, во-первых, почти все компании используют в своей работе над созданием модели и ее анимацией ручной труд художников (аниматоров), а во-вторых, большинство показывает свои модели в маленьком окне без возможности увеличить или повернуть модель. Наши же модели и анимация создаются полностью автоматически. Наши алгоритмы распознавания и слежения за лицом не требуют нанесения на лицо никаких специальных датчиков, меток или косметики, необходимой для корректной работы приложений наших конкурентов. И, наконец, насколько нам известно, ни одна компания не предлагает всего набора технологий, позволяющего полностью автоматически создать синтетическое видео, на котором модель, очень похожая на свой прототип, хорошо копирует его мимику и движения.
Как возникла идея создания технологии и сколько в итоге занял процесс разработки?
Идея проекта принадлежит менеджеру группы разработчиков Intel Валерию Курякину и возникла сперва как часть реализации библиотеки MPEG Processing Library, которая в свое время разрабатывалась в Intel, а потом — как комбинированный продукт, который способен служить как хорошим тестом, так и демонстрацией возможностей платформ Intel. Разработки начались в 2000 и были полностью завершены в июле 2003 года, в разное время над проектом работало от 3 до 7 человек.
В чем заключались основные сложности при разработке технологии? Алгоритм для анализа мимики в реальном времени? Что-то еще?
Сложным было все. MPEG-4 описывает только параметры анимации лица, но не методы их получения и не алгоритмы анимации и не технику визуализации. Не сказано в стандарте MPEG-4 и про алгоритмы персонализации абстрактной модели под конкретного человека. Все эти методы нам приходилось разрабатывать самим методом проб и ошибок. Еще одна трудность — это оценка конечного результата. Ведь термины "похоже и не похоже" — не математические, они зависят от восприятия конкретного человека, и понять, насколько наша синтетическая модель и ее анимация отличаются от прототипа, сложно. Кому-то нравится, кому-то нет. Хотя, если три года назад наши модели вызывали у посторонних зрителей смех или ужас, то теперь посетителям IDF приходилось объяснять, в каком окне реальное видео, а в каком — синтетическое. Но, конечно, недостатки еще есть, и в дальнейшем эти технологии могут быть усовершенствованы.
Каковы минимальные требования к аппаратной части "сервера" и "клиента"?
"Сервер" в нашей технологии — это компьютер, к которому присоединена видеокамера и который производит расчет параметров анимации — распознавание и слежение за мимикой и движениями головы человека. Этот процесс весьма ресурсоемкий. Для работы в реальном времени он требует процессора не менее Pentium4 1.7GHz, с достаточным количеством памяти -128Mb. "Клиент" — это компьютер, который демонстрирует синтетическое видео — анимирует и визуализирует трехмерную модель. Для работы в реальном времени ему не нужен мощный процессор (мы использовали PentiumIII-500MHz), но для отрисовки сложных моделей (в среднем, они содержат около 4000 вершин или примерно 8000 треугольников) необходима любая видеокарта с аппаратным ускорением OpenGL. Но во многих случаях (например, в случае видеоконференции, коммуникаций вообще) клиент и сервер должны работать на одном компьютере.
На какой сегмент рынка нацелена технология? Вы ориентируетесь скорее на корпоративных или "домашних" пользователей?
Как видите, у наших технологий есть масса применений. Часть из них рассчитана на "домашних" пользователей — игры, образование и общение при помощи синтетических персонажей. Но "говорящие головы" могут с успехом использоваться в разных целях и на веб-сайтах компаний — для привлечения посетителей, а технологии распознавания — в различных корпоративных продуктах.
Существуют ли какие-нибудь демо версии для ознакомления с возможностями "3D Talking heads"? Если нет, то планируется ли их выпуск в будущем?
Да, такие демонстрационные версии существуют. Они показываются на различных выставках, а также семинарах, организуемых Intel. Но, поскольку мы не делаем конечного продукта, мы не раздаем наши демо всем желающим, а предоставляем их по запросу компаниям, которые заинтересуются нашими технологиями и захотят их использовать.
Когда ваша технология появится на рынке в виде готовых программных продуктов?
Мы хотим, чтобы это произошло как можно быстрее. Мы разработали технологии, теперь нужно найти компании или подразделения в Интел, которые используют их в своих продуктах. Cейчас наши технологии представлены в следующем виде: библиотека, содержащая функции для распознавания и слежения за лицом и получения анимационных параметров; библиотека функций для преобразований, анимации и визуализации 3D моделей; приложение для создания персонализированных моделей по фотографиям или видеопоследовательности. А также ряд приложений, демонстрирующих возможности этих технологий, например, упоминавшаяся видеоконференция.
Какие другие интересные технологии вы планируете реализовать в ближайшем будущем?
О-о-о, у нас столько планов, что, боюсь, места у вас не хватит для их описания:-) В свое время вы все увидите и обо всем узнаете сами.
Cпасибо за интересную информацию, Виктория! Успехов вам и всем разработчикам центра!
На этом первая часть материала подошла к концу. В следующей статье — информация о SerialATA и SerialATA II, PCI Express, Azalia и других интересных технологиях. To be continued...
(c) 2003 Щетько Николай АКА Nickky, me@nickky.com,
специально для "КГ"
или по следам московского Intel Developer Forum 2003
Отгремел IDF, и пришло время свести воедино всю информацию с форума, его технических сессий и других источников о новых технологиях Intel и совсем уже близком будущем IT-индустрии. Azalia, WiMAX, La-Grande, Vanderpool, Mani-toba — что стоит за этими красивыми названиями? О них (и не только о них) читайте в этой статье.
Не стану утомлять вас длинными предисловиями и переливаниями из пустого в порожнее — cразу перейду к делу. Но для начала стоит немного познакомить вас со структурой материала. В первой части я расскажу о технологиях ("T"-s) от Intel: как уже известных (Hyperthre-ading, Centrino), так и достаточно недавно появившихся на слуху LaGrande и Vanderpool. Завершит "первую часть" статьи интервью с Викторией Жислиной из команды разработчиков набора технологий "3D Talking Heads" (Нижегородский Центр Исследований и Разработки ПО Intel). Во второй части статьи разговор пойдет о новой, активно продвигаемой Intel, шине PCI Express, стандартах Serial ATA I и II, организации WiMAX для продвижения услуг и оборудования сетей 802.16a, интегрированной звуковой системе Azalia, а также продуктах Intel для наладонников (чипы серии PXA, базирующиеся на RISC ядре XScale). В заключении поговорим о планах Intel по производству процессоров для настольных систем, а также новых технологиях по дальнейшей миниатюризации чипов. Ну что, приступим?
"T"-s: Hyperthreading, Centrino, LaGrande, Vanderpool
За грубой силой (количеством гигагерцев) стоят функциональные возможности систем. Технологии ("T"-s) Intel призваны улучшить производительность, функциональность, "мобильность" и защищенность настольных/мобильных/серверных систем. Поговорим о каждой из них по порядку. Про Hyperthreading Technology (HT) слышали если не все, то, уверен, многие. Это технология логической двухпроцессорности, впервые реализованная в дорогих процессорах Xeon, нынче ставшая доступной "простым смертным" в топовых процессорах Intel Pentium 4. Физический процессор в большинстве случаев загружен не на 100% и постоянно переключается между выполнением различных задач (потоков). Intel реализовала технологию Hyperthreading, которая позволяет операционной системе "разбрасывать" потоки на два логических процессора, что, в теории, может увеличить производительность системы на треть, максимально эффективно задействовав вычислительные возможности процессора. На практике результат выглядит скромнее: 5-15% прироста в лучшем случае и падение производительности (до 10% и более) — в худшем. Дело в том, что для эффективного использования возможностей, предоставляемых HT, программное обеспечение должно быть написано с учетом особенностей технологии. Старый софт не использует специальной команды (pause) в режиме ожидания, и поэтому его потоки при простое блокируют определенные ресурсы процессора. Кстати, написанию приложений, эффективно использующих многопоточность в сочетании с HТ, было уделено особое внимание на тематических семинарах. Соответствующие компиляторы с оптимизацией под HT от Intel давно готовы, и программистам остается лишь перекомпилировать свои приложения. После должной оптимизации цифра в 30% прироста может стать вполне реальной. С одной стороны, даже теперешние 5%-15% прироста — немного, но если учесть, что эта разница в производительности достается нам практически "бесплатно", то становится очень приятно;) С постепенной оптимизацией ПО под Hyperthreading Technology, думаю, выгода от ее использования значительно возрастет.
Centrino Mobile Technology (CMT) — первый случай объединения компанией Intel нескольких технологий (в данном случае — "мобильных") под одной торговой маркой. Технологий, обеспечивающих снижение энергопотребления, увеличение производительности и качественную беспроводную связь (Wi-Fi, 802.11b). Строго говоря, Centrino представляет собой сочетание процессора Pentium M, набора системной логики Intel 855 (855GM — со встроенной графикой, 855PM — со внешней) и сетевого интерфейса Intel PRO/Wireless 2100. Pentium M (шина — 400 Mhz) производится по 0.13-микронной технологии и очень эффективно управляет собственным энергопотреблением (Intel SpeedStep), причем, малая "прожорливость" отнюдь не мешает ему показывать высокие результаты по быстродействию. Чипсет также поддерживает Intel SpeedStep, а также режим "глубокой спячки" Deeper Sleep и другие усовершенствования, направленные на снижение энергопотребления. Intel 855 поддерживает до 2 GB PC2100 DDR памяти и USB 2.0. Intel PRO/Wireless 2100 отвечает за связь с точками доступа 802.11b Wi-Fi и призван также минимизировать помехи от использования продуктов на Bluetooth. Основной упор в Centrino, как вы уже поняли, сделан на "мобильность" (беспроводной Wi-Fi доступ) и увеличение длительности "жизни" ноутбука при питании от батарей.
Защиту данных на аппаратном уровне должна обеспечить новая архитектура LaGrande Technology (LT). LaGrande используется для защиты конфиденциальных данных, в основном, от программных атак на сети и системы, а также для нейтрализации "шпионского" ПО (вроде кейлоггеров). В TPM (Trusted Platform Module, микросхеме на материнской плате) хранится информация о кодировании данных, необходимая для воздвижения "кирпичной стены" (организации защищенной области) вокруг приложения и его данных в памяти. Вдобавок организуются защищенные ("доверительные") каналы между приложениями и средствами ввода/вывода. Для реализации фирменной доменной структуры (аппаратно-программная защита областей памяти от несанкционированного доступа), чтобы LaGrande проявила себя, понадобится процессор и чипсет с поддержкой этой технологии, TPM версии 1.2 (в этом чипе находится аутентификационная информация, сертификаты, ключи и т.п.), а также видеокарта с клавиатурой, поддерживающие "защищенный канал" между ПО и графической подсистемой/подсистемой ввода. Честно говоря, не знаю, насколько это будет оправдано и когда введено в строй. Даже если компоненты с поддержкой LT будут продаваться по доступной цене, в ближайшее время, думаю, массового перехода на LT не произойдет. Так или иначе, будем ждать дальнейших новостей о технологии.
О Vanderpool Technology (VT) до сих пор не было сказано ничего конкретного (правда, технология была уже несколько раз продемонстрирована: перезагрузка одной "виртуальной машины" никак не помешала другой проигрывать мультфильмы с DVD). Из всех "Т"-s она остается самой таинственной, что ли:) Судя по всему, Vanderpool будет аппаратно-программной технологией, позволяющей создавать нечто вроде виртуальных независимых друг от друга машин ("разделов") на одном компьютере. Об особенностях ее реализации вы обязательно узнаете, когда Intel соблаговолит открыть карты.
"3D Talking Heads"
Весьма любопытный, на мой взгляд, набор технологий для распознавания и визуализации мимики представил Нижегородский Центр Исследований и Разработки ПО Intel. Виктория Жислина из команды разработчиков "3D Talking Heads" любезно согласилась ответить на мои вопросы о продукте:
КГ: Добрый день, Виктория! Расскажите, пожалуйста, нашим читателям о вашей разработке, технологии "3D Talking Heads".
Виктория Жислина: "3D Talking Heads" ("Трехмерные Говорящие Головы") — это сокращенное название проекта, осуществленного в Нижегородском Центре Исследований и Разработки п\о компании INTEL(iNNL). Полное название нашей разработки "Synthetic Video: MPEG4 compliant 3D Talking Heads" (Синтетическое видео: MPEG4 совместимые 3D Говорящие Головы). А сама разработка представляет собой набор независимых технологий, которые могут быть использованы как совместно, так и по отдельности во многих приложениях, связанных с созданием и анимированием синтетических трехмерных говорящих персонажей.
Расскажите, пожалуйста, о технологиях набора поподробнее...
Первая технология — это автоматическое распознавание и слежение (так называемый трекинг) за мимикой и движениями головы человека на видеопоследовательности. Эта технология представлена в двух вариантах: режим реального времени (25 кадров в секунду на процессоре Pentium 4 1.7GHz), когда отслеживается человек, непосредственно стоящий перед видеокамерой, соединенной с компьютером; и оффлайн режим (со скоростью 1 кадр в секунду). В этом режиме распознавание и трекинг проходят по предварительно записанному видеофрагменту. При этом в реальном времени отслеживается динамика изменения положения/состояния человеческого лица. Мы можем приблизительно оценить углы поворота и наклона головы во всех плоскостях, примерную степень открывания и растяжения рта, поднятия бровей, распознать моргание. Для некоторых приложений такой приблизительной оценки достаточно, но, если нужно точно отследить мимику человека, то необходимы более сложные алгоритмы, а значит, увы, более медленные. В оффлайн режиме наша технология позволяет оценить не только положение головы в целом, но также абсолютно точно распознать и отследить внешние и внутренние контуры губ и зубов при разговоре, положение бровей, степень прикрытия глаз и даже смещение зрачков (направление взгляда).
Как это реализовано?
Для распознавания и слежения мы используем комбинацию общеизвестных алгоритмов (часть из которых реализована в библиотеке OpenCV) и собственных оригинальных методов. На основе полученных данных мы вычисляем параметры анимации лица, которые полностью соответствуют Facial Animation Parameters (FAP) стандарта MPEG-4. Здесь необходимо сказать несколько слов про стандарт MPEG-4. Немногие знают, что, помимо кодирования (сжатия) реальных аудио и видео потоков, этот стандарт предусматривает кодирование информации о синтетических объектах и их анимации (синтетическое видео). Одним из таких объектов и является человеческое лицо, заданное в виде 3D (триангулированной поверхности (сетки) в 3D пространстве). MPEG-4 определяет на лице человека особые точки — уголки и середины губ, глаз, бровей и т.д. К этим особым точкам (или ко всей модели в целом) и применяются анимационные параметры (FAP), описывающие изменение положения и выражения лица по сравнению с нейтральным состоянием. То есть, описание каждого кадра выглядит как набор параметров, по которым MPEG-4 декодер должен анимировать модель.
Это все было о первой технологии. А что с остальными?
Вторая наша технология имеет непосредственное отношение к MPEG-4 — это автоматическая анимация в реальном времени произвольных трехмерных моделей голов в соответствии с имеющимися параметрами анимации, полученными при помощи наших алгоритмов распознавания и трекинга или из любых других источников (например, TextTo-Speech). При этом, единственное требование, накладываемое на модель — ее соответствие MPEG-4 стандарту. И, наконец, третья технология — автоматическое создание фотореалистичной модели головы конкретного человека (прототипа), персонализация существующей "модели абстрактного человека" с использованием либо двух фотографий человека-прототипа (вид спереди и сбоку), либо видеопоследовательности, на которой человек поворачивает голову от одного плеча к другому. Персонализация выполняется в оффлайн режиме (занимает порядка 10 минут), ее алгоритмы разработаны совместно с исследовательской группой Московского Государственного Университета.
А как эта "сумма технологий" будет применяться на практике?
Один из возможных способов использования наших технологий был продемонстрирован на IDF: синтетическая видеоконференция в реальном времени, включающая в себя автоматическое распознавание и отслеживание мимики и движений головы говорящего человека, расчет и передачу по сети параметров анимации лица, анимацию и визуализацию произвольной модели в соответствии с полученными параметрами анимации. Стоит отметить, что, в отличие от обычной видеоконференции, которая требует большой пропускной способности сети (передается все изображение каждого кадра), синтетическая видеоконференция рассчитана на работу в условиях очень низкой пропускной способности сети — достаточно всего 2 Кбод (ведь каждый кадр описывается всего несколькими числами-параметрами анимации). Поэтому, синтетическое видео — это хорошее решение для различных мобильных устройств или модемных линий, где пропускная способность канала передачи физически ограничена.
Существуют ли у вашей разработки аналоги в мире?
Есть масса компаний, которые занимаются как распознаванием и слежением за лицом, так и персонализацией и анимацией "говорящих голов". Назовем только несколько самых известных имен: BioVirtual, Eyematic, face2face, Famous3D, Matrox&Digimask, SeeStorm, Haptek. У всех этих компаний, безусловно, есть достижения в некоторых областях: у кого-то отличного качества модели, кто-то показывает очень реалистичную анимацию, кто-то достиг успехов в распознавании и слежении за лицом. Но, во-первых, почти все компании используют в своей работе над созданием модели и ее анимацией ручной труд художников (аниматоров), а во-вторых, большинство показывает свои модели в маленьком окне без возможности увеличить или повернуть модель. Наши же модели и анимация создаются полностью автоматически. Наши алгоритмы распознавания и слежения за лицом не требуют нанесения на лицо никаких специальных датчиков, меток или косметики, необходимой для корректной работы приложений наших конкурентов. И, наконец, насколько нам известно, ни одна компания не предлагает всего набора технологий, позволяющего полностью автоматически создать синтетическое видео, на котором модель, очень похожая на свой прототип, хорошо копирует его мимику и движения.
Как возникла идея создания технологии и сколько в итоге занял процесс разработки?
Идея проекта принадлежит менеджеру группы разработчиков Intel Валерию Курякину и возникла сперва как часть реализации библиотеки MPEG Processing Library, которая в свое время разрабатывалась в Intel, а потом — как комбинированный продукт, который способен служить как хорошим тестом, так и демонстрацией возможностей платформ Intel. Разработки начались в 2000 и были полностью завершены в июле 2003 года, в разное время над проектом работало от 3 до 7 человек.
В чем заключались основные сложности при разработке технологии? Алгоритм для анализа мимики в реальном времени? Что-то еще?
Сложным было все. MPEG-4 описывает только параметры анимации лица, но не методы их получения и не алгоритмы анимации и не технику визуализации. Не сказано в стандарте MPEG-4 и про алгоритмы персонализации абстрактной модели под конкретного человека. Все эти методы нам приходилось разрабатывать самим методом проб и ошибок. Еще одна трудность — это оценка конечного результата. Ведь термины "похоже и не похоже" — не математические, они зависят от восприятия конкретного человека, и понять, насколько наша синтетическая модель и ее анимация отличаются от прототипа, сложно. Кому-то нравится, кому-то нет. Хотя, если три года назад наши модели вызывали у посторонних зрителей смех или ужас, то теперь посетителям IDF приходилось объяснять, в каком окне реальное видео, а в каком — синтетическое. Но, конечно, недостатки еще есть, и в дальнейшем эти технологии могут быть усовершенствованы.
Каковы минимальные требования к аппаратной части "сервера" и "клиента"?
"Сервер" в нашей технологии — это компьютер, к которому присоединена видеокамера и который производит расчет параметров анимации — распознавание и слежение за мимикой и движениями головы человека. Этот процесс весьма ресурсоемкий. Для работы в реальном времени он требует процессора не менее Pentium4 1.7GHz, с достаточным количеством памяти -128Mb. "Клиент" — это компьютер, который демонстрирует синтетическое видео — анимирует и визуализирует трехмерную модель. Для работы в реальном времени ему не нужен мощный процессор (мы использовали PentiumIII-500MHz), но для отрисовки сложных моделей (в среднем, они содержат около 4000 вершин или примерно 8000 треугольников) необходима любая видеокарта с аппаратным ускорением OpenGL. Но во многих случаях (например, в случае видеоконференции, коммуникаций вообще) клиент и сервер должны работать на одном компьютере.
На какой сегмент рынка нацелена технология? Вы ориентируетесь скорее на корпоративных или "домашних" пользователей?
Как видите, у наших технологий есть масса применений. Часть из них рассчитана на "домашних" пользователей — игры, образование и общение при помощи синтетических персонажей. Но "говорящие головы" могут с успехом использоваться в разных целях и на веб-сайтах компаний — для привлечения посетителей, а технологии распознавания — в различных корпоративных продуктах.
Существуют ли какие-нибудь демо версии для ознакомления с возможностями "3D Talking heads"? Если нет, то планируется ли их выпуск в будущем?
Да, такие демонстрационные версии существуют. Они показываются на различных выставках, а также семинарах, организуемых Intel. Но, поскольку мы не делаем конечного продукта, мы не раздаем наши демо всем желающим, а предоставляем их по запросу компаниям, которые заинтересуются нашими технологиями и захотят их использовать.
Когда ваша технология появится на рынке в виде готовых программных продуктов?
Мы хотим, чтобы это произошло как можно быстрее. Мы разработали технологии, теперь нужно найти компании или подразделения в Интел, которые используют их в своих продуктах. Cейчас наши технологии представлены в следующем виде: библиотека, содержащая функции для распознавания и слежения за лицом и получения анимационных параметров; библиотека функций для преобразований, анимации и визуализации 3D моделей; приложение для создания персонализированных моделей по фотографиям или видеопоследовательности. А также ряд приложений, демонстрирующих возможности этих технологий, например, упоминавшаяся видеоконференция.
Какие другие интересные технологии вы планируете реализовать в ближайшем будущем?
О-о-о, у нас столько планов, что, боюсь, места у вас не хватит для их описания:-) В свое время вы все увидите и обо всем узнаете сами.
Cпасибо за интересную информацию, Виктория! Успехов вам и всем разработчикам центра!
На этом первая часть материала подошла к концу. В следующей статье — информация о SerialATA и SerialATA II, PCI Express, Azalia и других интересных технологиях. To be continued...
(c) 2003 Щетько Николай АКА Nickky, me@nickky.com,
специально для "КГ"
Компьютерная газета. Статья была опубликована в номере 45 за 2003 год в рубрике hard :: технологии
