
Обработка XML в J2ME-приложениях
Обработка XML в J2ME-приложениях
Все больше корпоративных Java-проектов используют XML в качестве стандартного средства для хранения данных для того, чтобы сделать их транспортабельными и доступными другим приложениям и сервисам. Однако из-за высоких требований XML-парсеров к вычислительной мощности J2ME-приложения в большинстве своем не могли воспользоваться XML для хранения каких-либо данных. Несмотря на это, сейчас можно найти XML-парсеры, которые не требуют много места и не слишком требовательны к количеству системных ресурсов. Таким образом, MIDP-программисты уже сегодня могут пользоваться XML в своих приложениях для мобильных устройств. В этой статье мы рассмотрим одно из таких приложений.
Совместное использование технологий Java и XML представляет собой очень мощную и эффективную комбинацию переносимого кода и переносимых данных. Но каким образом этот синтез можно заставить работать на платформе Java 2 Micro Edition (J2ME)? В этой статье мы в качестве примера рассмотрим один из урезанных XML-парсеров, который был сжат до таких размеров, что его стало возможным использовать в J2ME-приложениях на платформах с ограниченными системными ресурсами. Для написания нашего приложения для MIDP-платформы, которое будет разбирать XML-документы, мы будем использовать пакет kXML. Но для начала сделаем обзор XML-парсеров и определим, почему они так долго шли к тому, чтобы перейти на платформу J2ME.
Обзор XML-парсеров
Модель обработки XML описывает шаги-операции, которые должно выполнить приложение для обработки полной XML; приложения, которые реализуют такую модель, принято называть XML-парсерами. Вы можете достаточно просто интегрировать любой XML-парсер в любые Java-приложения с помощью Java API for XML Processing (JAXP). JAXP позволяет приложениям разбирать и преобразовывать XML-документы с помощью API, который не зависит от определенной реализации XML-процессора. Благодаря plug-in-подобному механизму разработчики могут менять реализацию XML-процессора (XML-парсер) на другую без необходимости изменять код самого приложения.
Процесс разбора XML происходит в три фазы:
1. Обработка входного XML-файла. На этой стадии приложение разбирает исходный документ и осуществляет проверку на соответствие его всем стандартам (спецификации), распознает и ищет нужную информацию по его местоположению или имени тегов в исходном документе; извлекает эту информацию, как только она была обнаружена, и опциально отображает ее в бизнес-объекты.
2. Отработка описанной бизнес-логики. Это стадия, на которой выполняется фактическая обработка получаемой информации. Результатом работы на этой стадии может явиться генерация выходной информации.
3. Обработка выходного представления XML-файла. На этой стадии приложение конструирует модель документа, которая будет представлена с помощью DOM-дерева (Document Object Model). После чего для получения выходного формата применяются таблицы стилей XSLT или же просто DOM-объект сериализуется напрямую в XML.
SAX (Simple API for XML) и DOM — это наиболее общие модели обработки XML. Если вы используете парсер на основе SAX для обработки XML-документа, вам будет необходимо определить методы для обработки событий, выбрасываемых парсером в случае, когда он обнаружит очередной опознавательный знак языка разметки. Поскольку SAX-парсер генерирует кратковременный поток событий, процесс обработки входного XML-файла (первая фаза разбора XML, упомянутая выше) будет выполнен в одном цикле: каждое возникшее событие немедленно обрабатывается, и нужная информация также извлекается автоматически.
В случае использования парсеров на основе модели DOM вам необходимо будет написать код, который проходил бы по структуре данных типа "дерево" и мог выбирать оттуда нужную информацию. Это дерево будет автоматически создано парсером при разборе XML-документа из исходного файла. При использовании этой модели для выполнения первой фазы разбора XML необходимо выполнить уже не один цикл операций, а два. Во-первых, DOM-парсер создает древовидную структуру, которая обычно называется DOM-деревом и моделирует исходный XML-документ. А во-вторых, приложение должно обойти это DOM-дерево, чтобы найти в нем нужную информацию и извлечь ее из него для дальнейшей обработки. Последний цикл, если необходимо, может проходить сколь угодно большое количество раз подряд, пока DOM-дерево все еще существует в памяти компьютера.
Парсеры, работающие по какой-нибудь из двух рассмотренных выше моделей, требуют достаточно большого объема оперативной памяти и вычислительной мощности, которых не могут предоставить нам многие J2ME-устройства. Для того чтобы обойти эти ограничения, были придуманы парсеры третьего типа. Такие парсеры читают документ небольшими кусками. Приложение с помощью парсера проходит по документу, постепенно запрашивая очередную его часть. Самым ярким представителем парсеров третьего типа можно назвать kXML. Именно с его помощью мы и будем писать J2ME-приложение, работающее с XML-данными, в этой статье.
Обработка XML в среде MIDP
Вы можете использовать XML-парсеры в ваших J2ME-приложениях для того, чтобы иметь возможность взаимодействовать с уже существующими XML-сервисами. Например, вы можете получать список новостей на определенную тему, который можно просматривать в удобном вам виде на вашем телефоне с сайта — поставщика новостей по данной теме. Обычно информация о новостях на таких сайтах, а именно заголовки новостей и описания к ним, хранятся в формате XML.
Поскольку, как уже говорилось ранее, обычные XML-парсеры слишком громоздки, чтобы J2ME-устройства могли удовлетворить их потребности в оперативной памяти, для работы в MIDP-среде нужны небольшие парсеры, способные работать даже на столь ограниченных системными ресурсами устройствах. Помимо этого, данные парсеры должны быть максимально портабельными, чтобы без лишних усилий их можно было портировать на MIDP.
Существуют два наиболее популярных XML-парсера, которые обычно используются для работы на устройствах с ограниченными системными ресурсами. Это kXML и NanoXML. kXML был написан специально для использования на J2ME-платформе (CLDC и MIDP). Что же касается NanoXML, то его версия 1.6.8 для MIDP уже имеет поддержку разбора XML по модели DOM (за более подробной информацией по NanoXML и kXML обращайтесь к ссылкам, приведенным в конце этой статьи).
Проблемы производительности
Существует ряд проблем производительности приложений, которые вы должны иметь в виду при разборе XML в своих MIDP-приложениях.
Увеличенный размер. Использование XML-парсеров зачастую приводит к значительному увеличению кода приложения. Это особенно болезненно в случае с MIDP-устройствами. Однако существует несколько приемов, применив которые вы, возможно, сможете избежать излишнего расширения кода вашего приложения. Во-первых, нужно удалить файлы ресурсов, которые вы используете. Помимо этого, крайне желательно воспользоваться обфускаторами (obfuscators), которые удалят за вас неиспользуемые классы, методы и различные переменные из JAD-файла.
Разбор крупных строк. XML-парсеры используют нагруженные строки для выполнения своей работы. Таким образом они сильно перегружают MIDP-приложения, оставляя для их работы слишком мало оперативной памяти. XML-документы для разбора в J2ME-приложениях должны состоять только из небольших строк и содержать как можно больше именно полезной (необходимой) информации.
Медлительные отклики. Как только MIDP-приложение приступит к разбору относительно больших объемов XML-данных, время на их обработку очевидно возрастет. Поэтому XML-файлы, которые будут разбираться, должны быть небольшими, и обработка этих файлов должна происходить в отдельном вычислительном потоке от основного приложения.
В приложении, которое мы будем писать в этой статье, мы, естественно, будем придерживаться некоторых из данных рекомендаций.
Разбор XML в J2ME-приложении
В этой части статьи приступим к разработке J2ME-приложения ParseXML, которое будет разбирать XML-документы в формате стандарта RSS (Rich Site Summary) и отображать информацию, закодированную в этих документах на экране телефона. RSS — это сравнительно простой XML-формат, который определяет стандарт определения заголовков и описаний новостей, которые размещаются на новостном или обычном сайтах. Ниже приведен пример RSS-документа:
<?xml version="1.0"?>
<!DOCTYPE rss PUBLIC
"-//Netscape Communications//DTD RSS 0.91//EN"
"http://my.netscape.com/publish/formats/rss-0.91.dtd"
>
<rss version="0.91">
<channel>
<title> Meerkat: An Open Wire Service</title>
<link> http://meerkat.oreillynet.com</link>
<description>
Meerkat is a Web-based syndicated content reader based on RSS ("Rich Site Summary").
RSS is a fantastic, simple-yet-powerful syndication system rapidly gaining momentum.
</description>
</channel>
</rss>
Во время выполнения ParseXML выводит на экран телефона заголовок и описание к нему, которые он берет из приведенного выше RSS-файла. Все вопросы организации пользовательского интерфейса (UI) берет на себя пакет javax.microedition.lcdui.
В этом приложении используется XML-парсер kXML версии 1.2. Для того чтобы сделать классы kXML доступными приложению, необходимо скачать файл kxml.zip. Он содержит все пакеты этого парсера. Этот файл можно найти на официальном сайте проекта kXML (см. раздел "Ресурсы" в конце статьи). После этого необходимо скопировать содержимое архива в нужную папку разрабатываемой вами системы. Если вы используете инструментарий J2ME от Sun (см. раздел "Ресурсы"), то скопировать содержимое архива следует в TOOLKIT_HOME\ apps\ParseXML\lib.
В начале своей работы J2ME-приложение выводит текстовое поле, кнопку, при нажатии на которую посылается запрос на вывод разобранных данных XML, и кнопку выхода Exit. При нажатии на кнопку Display XML вызывается метод viewXML(). В этом методе приложение создает экземпляр класса XMLParser, который и будет служить обработчиком XML-документа. При нахождении очередной записи парсер будет искать содержимое этого элемента: title и description, чтобы найти текст, который нужно вывести на дисплей телефона. Этот процесс протекает рекурсивно. Пользователь может прервать его в любой момент, нажав кнопку Exit.
RSS-данные будут доступны ParseXML в форме объекта класса String. Поскольку XML-парсер работает только с потоком байтов, объект класса String конвертируется в массив байтов. Этот массив используется для создания объекта класса ByteArrayInputStream. В свою очередь, ByteArrayInputStream используется для создания экземпляра класса InputStreamReader, который создает экземпляр класса ParseXML. Этот процесс проиллюстрирован в листинге, приведенном ниже:
byte[] xmlByteArray = xmlStr.getBytes();
ByteArrayInputStream xmlStream = new
ByteArrayInputStream( xmlByteArray );
InputStreamReader xmlReader = new
InputStreamReader( xmlStream );
XmlParser parser = new XmlParser(xmlRea-der );
Для того чтобы получить данные с новостного или любого другого сайта, приложение должно открыть URL-соединение и прочитать RSS-данные из полученного объекта-потока InputStream. Сам же объект класса InputStream доступен для ParseXML посредством объекта InputStreamReader. Ниже приведен отрывок кода, который это реализует:
HttpConnection hc = (HttpConnection)Connec-tor.open(url);
InputStream is = hc.openInputStream();
Reader reader = new InputStreamReader(is);
XmlParser parser = new XmlParser(reader);
Когда метод класса ParseXML read() обнаруживает элемент, он возвращает объект класса ParseEvent. Этот объект содержит важную информацию — например, тип события (это может быть начало тега, конец тега, конец документа, текст или пробельные символы), имя события (фактически это имя тега) и текст события (это текст, заключенный в начальный и конечный теги одного элемента). Как будет показано в следующем листинге, в нашем примере парсер ищет теги с именем title и description, а после этого идет дальше, чтобы получить их содержимое для вывода на экран.
Объект ParseEvent генерирует события (Event) типов Xml.START_TAG, Xml.END_TAG, Xml.END_ DOCUMENT, Xml.WHITESPACE и Xml.TEXT, когда обнаруживает начало тега, конец тега, конец документа, пробельные символы и текст, заключенный в теги, соответственно.
case Xml.START_TAG:
// смотрите документацию по API для Start-Tag для более подробной информации о его доступных методах
// "Ловим" Title (заголовок)
if ("title".equals(event.getName()))
{
pe = parser.read();
title = pe.getText();
}
// "Ловим" Description (описание)
if ("description".equals(event.getName()))
{
pe = parser.read();
desc = pe.getText();
}
Следующий листинг содержит полный вариант исходного кода приложения ParseXML.
import javax.microedition.midlet.*;
import javax.microedition.lcdui.*;
import javax.microedition.io.*;
import java.io.*;
// импорты kXML
import org.kxml.*;
import org.kxml.parser.*;
public class ParseXML extends MIDlet implements CommandListener {
private Command exitCommand; // Команда выхода из приложения
private Command displayXML; // При вызове этой команды на экран телефона выводятся заголовки и описания новостей RSS
private Display display; // Основной объект Display для этого MIDlet'а
// Элементы пользовательского интерфейса для отображения заголовков и описаний
private static TextBox t;
private static String textBoxString = "";
// Строка XML
private String xmlStr = "";
public ParseXML() {
display = Display.getDisplay( this );
exitCommand = new Command( "Exit", Com-mand.EXIT, 2 );
displayXML = new Command( "XML", Com-mand.SCREEN, 1 );
// Формирование XML-строки на основании данных RSS
StringBuffer xmlString = new String Buffer();
xmlString.append("<?xml version=\"1.0\"?>
<!DOCTYPE rss PUBLIC \"-//Netscape Commu-nications//DTD RSS 0.91//EN\"");
xmlString.append("\"http://my.netscape. com/publish/formats/rss-0.91.dtd\"> ");
xmlString.append("<rss version=\"0.91\"> ");
xmlString.append("<channel> <title> Meer-kat: An Open Wire Service</title> ");
xmlString.append("<link> http://meerkat. oreillynet.com</link> ");
xmlString.append("<description> Meerkat is a Web-based syndicated content
reader based on RSS (\"Rich Site Summary\"). RSS is a fantastic, simple-yet-powerful syndication system rapidly gaining momentum.");
xmlString.append("</description> <language> en-us</language> ");
xmlString.append("</channel> ");
xmlString.append("</rss> ");
xmlStr = xmlString.toString();
}
public void startApp() {
// В текстовом поле выводятся заголовок и описание данных из этой XML-строки
t = new TextBox( "MIDlet XML", "kXML", 256, 0 );
t.addCommand( exitCommand );
t.addCommand( displayXML );
t.setCommandListener( this );
display.setCurrent( t );
}
/**
Этот метод (пауза) не определен, поскольку нет никаких фоновых задач и не нужно заботиться о сохранении данных при закрытии или выходе из MIDlet'а
*/
public void pauseApp() { }
/**
Метод destroyApp() должен очистить все, что не входит в обязанности системного сборщика мусора. В нашем случае он не делает ничего.
*/
public void destroyApp(boolean unconditional) { }
/*
Этим методом определяем обработчики команд при их вызове включая запрос на выход из приложения. При выходе из приложения мы выгружаем модуль нашего приложения и оповещаем об этом (notifyDestroyed()) систему.
*/
public void commandAction(Command c, Displayable s) {
if ( c == exitCommand ) {
destroyApp( false );
notifyDestroyed();
}
else if ( c == displayXML ) {
try {
viewXML();
}
catch( Exception e ) {
e.printStackTrace();
}
}
}
// Эта функция настраивает парсер kXML и вызывает метод traverse() для обработки строки XML
public void viewXML() throws IOException {
try {
byte[] xmlByteArray = xmlStr.getBytes();
ByteArrayInputStream xmlStream = new
ByteArrayInputStream( xmlByteArray );
InputStreamReader xmlReader = new
InputStreamReader( xmlStream );
XmlParser parser = new XmlParser( xmlReader );
try {
traverse( parser, "" );
}
catch (Exception exc)
{
exc.printStackTrace();
}
return;
}
catch ( IOException e ) {
return ;
} finally {
return ;
}
}
/**
Обрабатываем XML-данные
*/
public static void traverse( XmlParser parser, String indent ) throws Exception
{
boolean leave = false;
String title = new String();
String desc = new String();
do {
ParseEvent event = parser.read ();
ParseEvent pe;
switch ( event.getType() ) {
// Например, <title>
case Xml.START_TAG:
// "Ловим" Title (заголовок)
if ("title".equals(event.getName())) {
pe = parser.read();
title = pe.getText();
}
// "Ловим" Description (описание)
if ("description".equals(event.getNa-me())) {
pe = parser.read();
desc = pe.getText();
}
textBoxString = title + " " + desc;
traverse( parser, "" ) ; // рекурсивный вызов для каждой пары <тег> </тег>
break;
// Например, </title>
case Xml.END_TAG:
leave = true;
break;
// Например, </rss>
case Xml.END_DOCUMENT:
leave = true;
break;
// Текст, заключенный между двумя тегами элемента
case Xml.TEXT:
break;
case Xml.WHITESPACE:
break;
default:
}
} while( !leave );
t.setString( textBoxString );
}
}
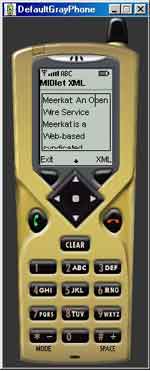
На изображении показано приложение ParseXML в действии.
В этой статье мы рассмотрели, каким образом можно, используя J2ME, сочетать мощь технологий Java и XML. Иными словами, скомбинировали переносимый код с переносимыми данными.
Проектирование J2ME-приложений со встроенными парсерами может оказаться непростой задачей, поскольку устройства, поддерживающие J2ME, обычно ограничены в количестве системных ресурсов.
Однако, поскольку компактные парсеры, удовлетворяющие потребностям MIDP, становятся все более распространенными, разбор XML-данных в скором времени очень широко распространится и станет одной из самых обычных возможностей платформы Java на мобильных устройствах.
Ресурсы
Парсер kXML: http://kxml.enhydra.org/software/downloads/
Парсер NanoXML: http://web.wanadoo.be/cyberelf/nanoxml/
Раздел, посвященный беспроводным решениям на developerWorks от IBM: http://www-106.ibm.com/developerworks/wireless
J2ME Toolkit от Sun: http://java.sun.com/products/j2mewtoolkit/
Ряд статей по J2ME от Java.sun.com: http://wireless.java.sun.com/midp/articles
По материалам Soma Ghosh
Алексей Литвинюк, litvinuke@tut.by
Все больше корпоративных Java-проектов используют XML в качестве стандартного средства для хранения данных для того, чтобы сделать их транспортабельными и доступными другим приложениям и сервисам. Однако из-за высоких требований XML-парсеров к вычислительной мощности J2ME-приложения в большинстве своем не могли воспользоваться XML для хранения каких-либо данных. Несмотря на это, сейчас можно найти XML-парсеры, которые не требуют много места и не слишком требовательны к количеству системных ресурсов. Таким образом, MIDP-программисты уже сегодня могут пользоваться XML в своих приложениях для мобильных устройств. В этой статье мы рассмотрим одно из таких приложений.
Совместное использование технологий Java и XML представляет собой очень мощную и эффективную комбинацию переносимого кода и переносимых данных. Но каким образом этот синтез можно заставить работать на платформе Java 2 Micro Edition (J2ME)? В этой статье мы в качестве примера рассмотрим один из урезанных XML-парсеров, который был сжат до таких размеров, что его стало возможным использовать в J2ME-приложениях на платформах с ограниченными системными ресурсами. Для написания нашего приложения для MIDP-платформы, которое будет разбирать XML-документы, мы будем использовать пакет kXML. Но для начала сделаем обзор XML-парсеров и определим, почему они так долго шли к тому, чтобы перейти на платформу J2ME.
Обзор XML-парсеров
Модель обработки XML описывает шаги-операции, которые должно выполнить приложение для обработки полной XML; приложения, которые реализуют такую модель, принято называть XML-парсерами. Вы можете достаточно просто интегрировать любой XML-парсер в любые Java-приложения с помощью Java API for XML Processing (JAXP). JAXP позволяет приложениям разбирать и преобразовывать XML-документы с помощью API, который не зависит от определенной реализации XML-процессора. Благодаря plug-in-подобному механизму разработчики могут менять реализацию XML-процессора (XML-парсер) на другую без необходимости изменять код самого приложения.
Процесс разбора XML происходит в три фазы:
1. Обработка входного XML-файла. На этой стадии приложение разбирает исходный документ и осуществляет проверку на соответствие его всем стандартам (спецификации), распознает и ищет нужную информацию по его местоположению или имени тегов в исходном документе; извлекает эту информацию, как только она была обнаружена, и опциально отображает ее в бизнес-объекты.
2. Отработка описанной бизнес-логики. Это стадия, на которой выполняется фактическая обработка получаемой информации. Результатом работы на этой стадии может явиться генерация выходной информации.
3. Обработка выходного представления XML-файла. На этой стадии приложение конструирует модель документа, которая будет представлена с помощью DOM-дерева (Document Object Model). После чего для получения выходного формата применяются таблицы стилей XSLT или же просто DOM-объект сериализуется напрямую в XML.
SAX (Simple API for XML) и DOM — это наиболее общие модели обработки XML. Если вы используете парсер на основе SAX для обработки XML-документа, вам будет необходимо определить методы для обработки событий, выбрасываемых парсером в случае, когда он обнаружит очередной опознавательный знак языка разметки. Поскольку SAX-парсер генерирует кратковременный поток событий, процесс обработки входного XML-файла (первая фаза разбора XML, упомянутая выше) будет выполнен в одном цикле: каждое возникшее событие немедленно обрабатывается, и нужная информация также извлекается автоматически.
В случае использования парсеров на основе модели DOM вам необходимо будет написать код, который проходил бы по структуре данных типа "дерево" и мог выбирать оттуда нужную информацию. Это дерево будет автоматически создано парсером при разборе XML-документа из исходного файла. При использовании этой модели для выполнения первой фазы разбора XML необходимо выполнить уже не один цикл операций, а два. Во-первых, DOM-парсер создает древовидную структуру, которая обычно называется DOM-деревом и моделирует исходный XML-документ. А во-вторых, приложение должно обойти это DOM-дерево, чтобы найти в нем нужную информацию и извлечь ее из него для дальнейшей обработки. Последний цикл, если необходимо, может проходить сколь угодно большое количество раз подряд, пока DOM-дерево все еще существует в памяти компьютера.
Парсеры, работающие по какой-нибудь из двух рассмотренных выше моделей, требуют достаточно большого объема оперативной памяти и вычислительной мощности, которых не могут предоставить нам многие J2ME-устройства. Для того чтобы обойти эти ограничения, были придуманы парсеры третьего типа. Такие парсеры читают документ небольшими кусками. Приложение с помощью парсера проходит по документу, постепенно запрашивая очередную его часть. Самым ярким представителем парсеров третьего типа можно назвать kXML. Именно с его помощью мы и будем писать J2ME-приложение, работающее с XML-данными, в этой статье.
Обработка XML в среде MIDP
Вы можете использовать XML-парсеры в ваших J2ME-приложениях для того, чтобы иметь возможность взаимодействовать с уже существующими XML-сервисами. Например, вы можете получать список новостей на определенную тему, который можно просматривать в удобном вам виде на вашем телефоне с сайта — поставщика новостей по данной теме. Обычно информация о новостях на таких сайтах, а именно заголовки новостей и описания к ним, хранятся в формате XML.
Поскольку, как уже говорилось ранее, обычные XML-парсеры слишком громоздки, чтобы J2ME-устройства могли удовлетворить их потребности в оперативной памяти, для работы в MIDP-среде нужны небольшие парсеры, способные работать даже на столь ограниченных системными ресурсами устройствах. Помимо этого, данные парсеры должны быть максимально портабельными, чтобы без лишних усилий их можно было портировать на MIDP.
Существуют два наиболее популярных XML-парсера, которые обычно используются для работы на устройствах с ограниченными системными ресурсами. Это kXML и NanoXML. kXML был написан специально для использования на J2ME-платформе (CLDC и MIDP). Что же касается NanoXML, то его версия 1.6.8 для MIDP уже имеет поддержку разбора XML по модели DOM (за более подробной информацией по NanoXML и kXML обращайтесь к ссылкам, приведенным в конце этой статьи).
Проблемы производительности
Существует ряд проблем производительности приложений, которые вы должны иметь в виду при разборе XML в своих MIDP-приложениях.
Увеличенный размер. Использование XML-парсеров зачастую приводит к значительному увеличению кода приложения. Это особенно болезненно в случае с MIDP-устройствами. Однако существует несколько приемов, применив которые вы, возможно, сможете избежать излишнего расширения кода вашего приложения. Во-первых, нужно удалить файлы ресурсов, которые вы используете. Помимо этого, крайне желательно воспользоваться обфускаторами (obfuscators), которые удалят за вас неиспользуемые классы, методы и различные переменные из JAD-файла.
Разбор крупных строк. XML-парсеры используют нагруженные строки для выполнения своей работы. Таким образом они сильно перегружают MIDP-приложения, оставляя для их работы слишком мало оперативной памяти. XML-документы для разбора в J2ME-приложениях должны состоять только из небольших строк и содержать как можно больше именно полезной (необходимой) информации.
Медлительные отклики. Как только MIDP-приложение приступит к разбору относительно больших объемов XML-данных, время на их обработку очевидно возрастет. Поэтому XML-файлы, которые будут разбираться, должны быть небольшими, и обработка этих файлов должна происходить в отдельном вычислительном потоке от основного приложения.
В приложении, которое мы будем писать в этой статье, мы, естественно, будем придерживаться некоторых из данных рекомендаций.
Разбор XML в J2ME-приложении
В этой части статьи приступим к разработке J2ME-приложения ParseXML, которое будет разбирать XML-документы в формате стандарта RSS (Rich Site Summary) и отображать информацию, закодированную в этих документах на экране телефона. RSS — это сравнительно простой XML-формат, который определяет стандарт определения заголовков и описаний новостей, которые размещаются на новостном или обычном сайтах. Ниже приведен пример RSS-документа:
<?xml version="1.0"?>
<!DOCTYPE rss PUBLIC
"-//Netscape Communications//DTD RSS 0.91//EN"
"http://my.netscape.com/publish/formats/rss-0.91.dtd"
>
<rss version="0.91">
<channel>
<title> Meerkat: An Open Wire Service</title>
<link> http://meerkat.oreillynet.com</link>
<description>
Meerkat is a Web-based syndicated content reader based on RSS ("Rich Site Summary").
RSS is a fantastic, simple-yet-powerful syndication system rapidly gaining momentum.
</description>
</channel>
</rss>
Во время выполнения ParseXML выводит на экран телефона заголовок и описание к нему, которые он берет из приведенного выше RSS-файла. Все вопросы организации пользовательского интерфейса (UI) берет на себя пакет javax.microedition.lcdui.
В этом приложении используется XML-парсер kXML версии 1.2. Для того чтобы сделать классы kXML доступными приложению, необходимо скачать файл kxml.zip. Он содержит все пакеты этого парсера. Этот файл можно найти на официальном сайте проекта kXML (см. раздел "Ресурсы" в конце статьи). После этого необходимо скопировать содержимое архива в нужную папку разрабатываемой вами системы. Если вы используете инструментарий J2ME от Sun (см. раздел "Ресурсы"), то скопировать содержимое архива следует в TOOLKIT_HOME\ apps\ParseXML\lib.
В начале своей работы J2ME-приложение выводит текстовое поле, кнопку, при нажатии на которую посылается запрос на вывод разобранных данных XML, и кнопку выхода Exit. При нажатии на кнопку Display XML вызывается метод viewXML(). В этом методе приложение создает экземпляр класса XMLParser, который и будет служить обработчиком XML-документа. При нахождении очередной записи парсер будет искать содержимое этого элемента: title и description, чтобы найти текст, который нужно вывести на дисплей телефона. Этот процесс протекает рекурсивно. Пользователь может прервать его в любой момент, нажав кнопку Exit.
RSS-данные будут доступны ParseXML в форме объекта класса String. Поскольку XML-парсер работает только с потоком байтов, объект класса String конвертируется в массив байтов. Этот массив используется для создания объекта класса ByteArrayInputStream. В свою очередь, ByteArrayInputStream используется для создания экземпляра класса InputStreamReader, который создает экземпляр класса ParseXML. Этот процесс проиллюстрирован в листинге, приведенном ниже:
byte[] xmlByteArray = xmlStr.getBytes();
ByteArrayInputStream xmlStream = new
ByteArrayInputStream( xmlByteArray );
InputStreamReader xmlReader = new
InputStreamReader( xmlStream );
XmlParser parser = new XmlParser(xmlRea-der );
Для того чтобы получить данные с новостного или любого другого сайта, приложение должно открыть URL-соединение и прочитать RSS-данные из полученного объекта-потока InputStream. Сам же объект класса InputStream доступен для ParseXML посредством объекта InputStreamReader. Ниже приведен отрывок кода, который это реализует:
HttpConnection hc = (HttpConnection)Connec-tor.open(url);
InputStream is = hc.openInputStream();
Reader reader = new InputStreamReader(is);
XmlParser parser = new XmlParser(reader);
Когда метод класса ParseXML read() обнаруживает элемент, он возвращает объект класса ParseEvent. Этот объект содержит важную информацию — например, тип события (это может быть начало тега, конец тега, конец документа, текст или пробельные символы), имя события (фактически это имя тега) и текст события (это текст, заключенный в начальный и конечный теги одного элемента). Как будет показано в следующем листинге, в нашем примере парсер ищет теги с именем title и description, а после этого идет дальше, чтобы получить их содержимое для вывода на экран.
Объект ParseEvent генерирует события (Event) типов Xml.START_TAG, Xml.END_TAG, Xml.END_ DOCUMENT, Xml.WHITESPACE и Xml.TEXT, когда обнаруживает начало тега, конец тега, конец документа, пробельные символы и текст, заключенный в теги, соответственно.
case Xml.START_TAG:
// смотрите документацию по API для Start-Tag для более подробной информации о его доступных методах
// "Ловим" Title (заголовок)
if ("title".equals(event.getName()))
{
pe = parser.read();
title = pe.getText();
}
// "Ловим" Description (описание)
if ("description".equals(event.getName()))
{
pe = parser.read();
desc = pe.getText();
}
Следующий листинг содержит полный вариант исходного кода приложения ParseXML.
import javax.microedition.midlet.*;
import javax.microedition.lcdui.*;
import javax.microedition.io.*;
import java.io.*;
// импорты kXML
import org.kxml.*;
import org.kxml.parser.*;
public class ParseXML extends MIDlet implements CommandListener {
private Command exitCommand; // Команда выхода из приложения
private Command displayXML; // При вызове этой команды на экран телефона выводятся заголовки и описания новостей RSS
private Display display; // Основной объект Display для этого MIDlet'а
// Элементы пользовательского интерфейса для отображения заголовков и описаний
private static TextBox t;
private static String textBoxString = "";
// Строка XML
private String xmlStr = "";
public ParseXML() {
display = Display.getDisplay( this );
exitCommand = new Command( "Exit", Com-mand.EXIT, 2 );
displayXML = new Command( "XML", Com-mand.SCREEN, 1 );
// Формирование XML-строки на основании данных RSS
StringBuffer xmlString = new String Buffer();
xmlString.append("<?xml version=\"1.0\"?>
<!DOCTYPE rss PUBLIC \"-//Netscape Commu-nications//DTD RSS 0.91//EN\"");
xmlString.append("\"http://my.netscape. com/publish/formats/rss-0.91.dtd\"> ");
xmlString.append("<rss version=\"0.91\"> ");
xmlString.append("<channel> <title> Meer-kat: An Open Wire Service</title> ");
xmlString.append("<link> http://meerkat. oreillynet.com</link> ");
xmlString.append("<description> Meerkat is a Web-based syndicated content
reader based on RSS (\"Rich Site Summary\"). RSS is a fantastic, simple-yet-powerful syndication system rapidly gaining momentum.");
xmlString.append("</description> <language> en-us</language> ");
xmlString.append("</channel> ");
xmlString.append("</rss> ");
xmlStr = xmlString.toString();
}
public void startApp() {
// В текстовом поле выводятся заголовок и описание данных из этой XML-строки
t = new TextBox( "MIDlet XML", "kXML", 256, 0 );
t.addCommand( exitCommand );
t.addCommand( displayXML );
t.setCommandListener( this );
display.setCurrent( t );
}
/**
Этот метод (пауза) не определен, поскольку нет никаких фоновых задач и не нужно заботиться о сохранении данных при закрытии или выходе из MIDlet'а
*/
public void pauseApp() { }
/**
Метод destroyApp() должен очистить все, что не входит в обязанности системного сборщика мусора. В нашем случае он не делает ничего.
*/
public void destroyApp(boolean unconditional) { }
/*
Этим методом определяем обработчики команд при их вызове включая запрос на выход из приложения. При выходе из приложения мы выгружаем модуль нашего приложения и оповещаем об этом (notifyDestroyed()) систему.
*/
public void commandAction(Command c, Displayable s) {
if ( c == exitCommand ) {
destroyApp( false );
notifyDestroyed();
}
else if ( c == displayXML ) {
try {
viewXML();
}
catch( Exception e ) {
e.printStackTrace();
}
}
}
// Эта функция настраивает парсер kXML и вызывает метод traverse() для обработки строки XML
public void viewXML() throws IOException {
try {
byte[] xmlByteArray = xmlStr.getBytes();
ByteArrayInputStream xmlStream = new
ByteArrayInputStream( xmlByteArray );
InputStreamReader xmlReader = new
InputStreamReader( xmlStream );
XmlParser parser = new XmlParser( xmlReader );
try {
traverse( parser, "" );
}
catch (Exception exc)
{
exc.printStackTrace();
}
return;
}
catch ( IOException e ) {
return ;
} finally {
return ;
}
}
/**
Обрабатываем XML-данные
*/
public static void traverse( XmlParser parser, String indent ) throws Exception
{
boolean leave = false;
String title = new String();
String desc = new String();
do {
ParseEvent event = parser.read ();
ParseEvent pe;
switch ( event.getType() ) {
// Например, <title>
case Xml.START_TAG:
// "Ловим" Title (заголовок)
if ("title".equals(event.getName())) {
pe = parser.read();
title = pe.getText();
}
// "Ловим" Description (описание)
if ("description".equals(event.getNa-me())) {
pe = parser.read();
desc = pe.getText();
}
textBoxString = title + " " + desc;
traverse( parser, "" ) ; // рекурсивный вызов для каждой пары <тег> </тег>
break;
// Например, </title>
case Xml.END_TAG:
leave = true;
break;
// Например, </rss>
case Xml.END_DOCUMENT:
leave = true;
break;
// Текст, заключенный между двумя тегами элемента
case Xml.TEXT:
break;
case Xml.WHITESPACE:
break;
default:
}
} while( !leave );
t.setString( textBoxString );
}
}
На изображении показано приложение ParseXML в действии.
В этой статье мы рассмотрели, каким образом можно, используя J2ME, сочетать мощь технологий Java и XML. Иными словами, скомбинировали переносимый код с переносимыми данными.
Проектирование J2ME-приложений со встроенными парсерами может оказаться непростой задачей, поскольку устройства, поддерживающие J2ME, обычно ограничены в количестве системных ресурсов.
Однако, поскольку компактные парсеры, удовлетворяющие потребностям MIDP, становятся все более распространенными, разбор XML-данных в скором времени очень широко распространится и станет одной из самых обычных возможностей платформы Java на мобильных устройствах.
Ресурсы
Парсер kXML: http://kxml.enhydra.org/software/downloads/
Парсер NanoXML: http://web.wanadoo.be/cyberelf/nanoxml/
Раздел, посвященный беспроводным решениям на developerWorks от IBM: http://www-106.ibm.com/developerworks/wireless
J2ME Toolkit от Sun: http://java.sun.com/products/j2mewtoolkit/
Ряд статей по J2ME от Java.sun.com: http://wireless.java.sun.com/midp/articles
По материалам Soma Ghosh
Алексей Литвинюк, litvinuke@tut.by
Компьютерная газета. Статья была опубликована в номере 40 за 2003 год в рубрике программирование :: разное
