
Java и XML 1
Java и XML
Метод анализа по DOM предоставляет гораздо больше возможностей по исследованию структуры дерева элементов XML-документа, однако, как уже говорилось, для работы с очень большими документами XML необходимо достаточное количество оперативной памяти. Поэтому при довольно крупных XML-документах лучше пользоваться SAX, но, опять же, не обязательно. В этой статье мы поговорим о том, что собой представляет объектная модель документа, и рассмотрим интерфейс DOM-парсеров.
Модель DOM полностью, до мельчайших подробностей описывает представляемый документ. Это означает, что, имея в распоряжении такую модель, мы без труда сможем заново воссоздать исходный документ. При этом в виде DOM-дерева можно представить не только XML-документ, но и, например, HTML и CSS.
Спецификация, разработанная World Wide Web Consortium, предполагает, что любая реализация DOM будет удовлетворять некоторым заранее определенным требованиям. Например, независимость от языков программирования и аппаратных платформ, обязательное наличие возможности восстанавливать (преобразовывать) DOM-дерево (модель документа) обратно в исходный документ и пр. С остальными требованиями можно ознакомиться обратившись к спецификации. Подобные требования необходимо знать при написании своей собственной реализации DOM-парсера, чтобы соответствовать стандарту.
Итак, спецификация DOM фактически состоит из двух частей: DOM Core Level I и DOM Core Level II. Их различие, скорее, в том, что Level II является некоторым расширением Level I (advanced). Это в основном проявляется в наличии дополнительных интерфейсов и определений, которые в процессе обычного анализа (как в нашем случае) просто оказываются лишними. Поэтому остановимся на Core Level I.
Сама спецификация DOM Core Level I состоит из нескольких интерфейсов, каждый из которых определяет объекты разных уровней дерева DOM (или, можно сказать, самого XML-документа). Из этих интерфейсов необходимо выделить Document, Element и Node. Если проводить параллель с реальным деревом (растением), то интерфейс Document будет определять "ствол" (или "корень"), Element — "ветви" или "подветви", а Node — "листья". Однако, как вы могли заметить, в DOM все можно считать узлами. На приведенной ниже схеме видно, что каждый элемент DOM-дерева является узлом.
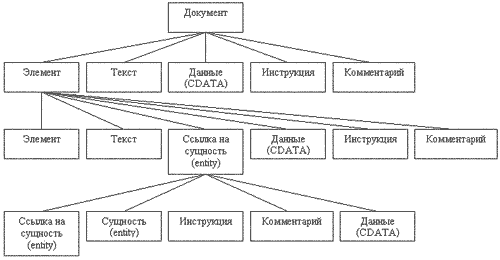
Каждый из узлов этого дерева представлен в виде константного значения в org.w3c.dom.Node. Например, ELEMENT_NODE для узла-элемента, TEXT_NODE для текста внутри элемента и пр. Полный список этих типов будет приведен несколько позже. А пока нужно сделать акцент на том, что элементы и данные, в них содержащиеся, находятся в разных узлах дерева. Фактически это означает, что элемент разбивается на составляющие его части: имя элемента, текст внутри элемента, данные CDATA, комментарий, сущности (entities), инструкции по обработке.
Если вы еще не забыли, то нашей основной целью, которая была сформулирована в предыдущей статье, было написать анализатор определенного ранее XML-документа. Этот документ содержал список книг. Этот анализатор должен был всего-навсего вывести в определенном формате этот список. В прошлый раз речь шла о SAX, теперь же попытаемся сделать то же, применяя спецификацию DOM. Если говорить о конкретной реализации DOM, то, наверное, лучшим для нас вариантом был бы парсер от IBM, так как именно на его примере мы рассматривали в прошлый раз SAX. Просто, если он у вас уже есть, то в этом парсере есть реализация как SAX, так и DOM. Но это, естественно, не единственный и, возможно, не лучший выход. Поэтому можно посмотреть на реализации от таких известных корпораций, как Sun, Oracle, Microsoft и пр.
Прежде чем начать писать саму программу, рассмотрим методы интересующих нас интерфейсов Node, Document и Element. Начнем по порядку. Интерфейс Node предоставляет возможность поиска информации об узлах (т.е. о свойствах элементов), изменения, чтения и добавления текстовой информации внутрь элементов, а также возможности перемещаться по дереву относительно текущего узла. Каждый узел имеет свой тип. Такой тип узла можно получить с помощью метода getNodeType() интерфейса Node. Вот полный список типов, которые могут возвращаться методом getNodeType():
Символьная Значение
константа (short)
ELEMENT_NODE 1
ATTRIBUTE_NODE 2
TEXT_NODE 3
CDATA_SECTION 4
ENTITY_REFERENCE_NODE 5
ENTITY_NODE 6
PROCESSING_INSTRUCTION_NODE 7
COMMENT_NODE 8
DOCUMENT_NODE 9
DOCUMENT_TYPE_NODE 10
DOCUMENT_FRAGMENT_NODE 11
NOTATION_NODE 12
Помимо типа узла мы также можем извлечь и другую, не менее важную информацию, например, имя узла, его значение, а также его атрибуты. Имя узла можно получить методом get NodeName(), его содержимое методом getNodeValue(), а список атрибутов методом getAttributes(). Метод getAttributes() возвращает объект класса NamedNodeMap, который содержит в себе коллекцию объектов класса Node, каждый из которых и представляет определенный атрибут элемента. Для извлечения имени и значения каждого атрибута необходимо воспользоваться только что упоминавшимися методами: getNodeName() и getNodeValue() для каждого из объектов полученной коллекции. В интерфейсе NamedNodeMap есть два метода, о существовании которых нужно знать. Первый — это метод, возвращающий количество элементов, getLength(), а второй — для извлечения элементов с указанным индексом, item(int). Если узел не содержит атрибутов, то возвращается null.
Установить значение узла можно методом setNodeValue(). А узнать о существовании или отсутствии дочерних узлов можно методом hasChildNodes(), который возвращает значение типа boolean. В случае значения true дочерние узлы есть, если же значение false, их нет. Если дочерние элементы есть, и нам нужно их получить, то можно воспользоваться методом getChildNodes(), который возвращает объект класса NodeList (см. ниже), в котором содержатся ссылки на все дочерние узлы.
Не будем останавливаться на всех методах этого интерфейса, потому как их количество значительно превышает наши потребности для решения поставленной задачи. Приведенных выше методов для этого более чем достаточно.
Интерфейс Document. Здесь необходимо выделить один из самых полезных методов — это getElementsByTagName(String). В качестве параметра задается имя элемента. Метод возвращает объект класса NodeList (среди его методов также присутствуют getLength() и item(int), как у NamedNodeMap), содержащий ссылки на все элементы с заданным именем. Очень похожий метод также присутствует в интерфейсе Element. Он тоже называется getElementsByTagName(String). Работа этого метода идентична вышерассмотренному, с той лишь разницей, что этот метод ищет элементы только среди вложенных элементов текущего узла, а ранее рассмотренный по всему документу вне зависимости от расположения искомых элементов.
Этого вполне достаточно, чтобы приступить к написанию программы. Вот и она:
import java.io.FileInputStream;
import org.w3c.dom.*;
import com.sun.xml.tree.*;
public class LibraryParser2
{
public static void main(String argv[])
{
FileInputStream fis;
Document doc;
Node n;
try
{
fis = new FileInputStream ("./sample.xml");
doc = new XmlDocument.create XmlDocument(fis, true);
NodeList nl = doc.getElementsByTagName("book");
if (nl.getLength() == 0) return;
for (int i = 0; i < nl.getLength(); i++)
{
n = nl.item(i);
NamedNodeMap nnm = n.get Attributes();
System.out.println("\n #" + nnm.item(0).getNodeValue());
if (n.hasChildNodes())
{
NodeList nlTemp = n.getChildNodes();
System.out.println("Title: " + nlTemp.item(0).getNodeValue());
System.out.println("Author: " + nl Temp.item(1).getNodeValue());
System.out.println("Published: " + nl Temp.item(2).getNodeValue()+"--\n");
}
}
}
catch (Exception e)
{
e.printStackTrace();
}
}
}
Вы, должно быть, заметили, насколько объем кода данной программы отличается от нашего предыдущего решения этой задачи с использованием SAX.
Итак, мы использовали на этот раз реализацию от Sun (com.sun. xml.tree.*). Это решение обусловливается просто тем, что я не хотел останавливаться только на парсерах IBM. Хотя, в принципе, их использование мало чем отличается друг от друга. Второй из неизвестных нам подключаемых пакетов — это org.w3c.dom.*. В нем описана стандартная часть, за которую отвечает World Wide Web Consortium. Т.к. мы используем в качестве источника XML-документа обычный файл, то нам понадобится класс FileInputStream, поэтому его мы также импортируем.
Первым делом в программе мы создаем объект класса Document при помощи статического метода createXmlDocument() класса XmlDocument. Этот метод принимает два параметра. Первый — это поток или набор строк, содержащий сам XML-документ, а второй определяет, производить проверку на соответствие DTD или нет. После того, как документ создан, мы производим необходимые действия по извлечению необходимых данных из DOM-модели документа и выводим их на экран в форматном виде. В процессе извлечения мы использовали только те методы, которые были рассмотрены нами ранее. Поэтому проблем с пониманием кода, думаю, возникнуть не должно.
На этом мы закончим разговор о методах анализа XML-документов средствами Java. Тема далеко не исчерпана и будет затрагиваться и в дальнейшем. С вопросами и предложениями — пишите.
Алексей Литвинюк
Метод анализа по DOM предоставляет гораздо больше возможностей по исследованию структуры дерева элементов XML-документа, однако, как уже говорилось, для работы с очень большими документами XML необходимо достаточное количество оперативной памяти. Поэтому при довольно крупных XML-документах лучше пользоваться SAX, но, опять же, не обязательно. В этой статье мы поговорим о том, что собой представляет объектная модель документа, и рассмотрим интерфейс DOM-парсеров.
Модель DOM полностью, до мельчайших подробностей описывает представляемый документ. Это означает, что, имея в распоряжении такую модель, мы без труда сможем заново воссоздать исходный документ. При этом в виде DOM-дерева можно представить не только XML-документ, но и, например, HTML и CSS.
Спецификация, разработанная World Wide Web Consortium, предполагает, что любая реализация DOM будет удовлетворять некоторым заранее определенным требованиям. Например, независимость от языков программирования и аппаратных платформ, обязательное наличие возможности восстанавливать (преобразовывать) DOM-дерево (модель документа) обратно в исходный документ и пр. С остальными требованиями можно ознакомиться обратившись к спецификации. Подобные требования необходимо знать при написании своей собственной реализации DOM-парсера, чтобы соответствовать стандарту.
Итак, спецификация DOM фактически состоит из двух частей: DOM Core Level I и DOM Core Level II. Их различие, скорее, в том, что Level II является некоторым расширением Level I (advanced). Это в основном проявляется в наличии дополнительных интерфейсов и определений, которые в процессе обычного анализа (как в нашем случае) просто оказываются лишними. Поэтому остановимся на Core Level I.
Сама спецификация DOM Core Level I состоит из нескольких интерфейсов, каждый из которых определяет объекты разных уровней дерева DOM (или, можно сказать, самого XML-документа). Из этих интерфейсов необходимо выделить Document, Element и Node. Если проводить параллель с реальным деревом (растением), то интерфейс Document будет определять "ствол" (или "корень"), Element — "ветви" или "подветви", а Node — "листья". Однако, как вы могли заметить, в DOM все можно считать узлами. На приведенной ниже схеме видно, что каждый элемент DOM-дерева является узлом.
Каждый из узлов этого дерева представлен в виде константного значения в org.w3c.dom.Node. Например, ELEMENT_NODE для узла-элемента, TEXT_NODE для текста внутри элемента и пр. Полный список этих типов будет приведен несколько позже. А пока нужно сделать акцент на том, что элементы и данные, в них содержащиеся, находятся в разных узлах дерева. Фактически это означает, что элемент разбивается на составляющие его части: имя элемента, текст внутри элемента, данные CDATA, комментарий, сущности (entities), инструкции по обработке.
Если вы еще не забыли, то нашей основной целью, которая была сформулирована в предыдущей статье, было написать анализатор определенного ранее XML-документа. Этот документ содержал список книг. Этот анализатор должен был всего-навсего вывести в определенном формате этот список. В прошлый раз речь шла о SAX, теперь же попытаемся сделать то же, применяя спецификацию DOM. Если говорить о конкретной реализации DOM, то, наверное, лучшим для нас вариантом был бы парсер от IBM, так как именно на его примере мы рассматривали в прошлый раз SAX. Просто, если он у вас уже есть, то в этом парсере есть реализация как SAX, так и DOM. Но это, естественно, не единственный и, возможно, не лучший выход. Поэтому можно посмотреть на реализации от таких известных корпораций, как Sun, Oracle, Microsoft и пр.
Прежде чем начать писать саму программу, рассмотрим методы интересующих нас интерфейсов Node, Document и Element. Начнем по порядку. Интерфейс Node предоставляет возможность поиска информации об узлах (т.е. о свойствах элементов), изменения, чтения и добавления текстовой информации внутрь элементов, а также возможности перемещаться по дереву относительно текущего узла. Каждый узел имеет свой тип. Такой тип узла можно получить с помощью метода getNodeType() интерфейса Node. Вот полный список типов, которые могут возвращаться методом getNodeType():
Символьная Значение
константа (short)
ELEMENT_NODE 1
ATTRIBUTE_NODE 2
TEXT_NODE 3
CDATA_SECTION 4
ENTITY_REFERENCE_NODE 5
ENTITY_NODE 6
PROCESSING_INSTRUCTION_NODE 7
COMMENT_NODE 8
DOCUMENT_NODE 9
DOCUMENT_TYPE_NODE 10
DOCUMENT_FRAGMENT_NODE 11
NOTATION_NODE 12
Помимо типа узла мы также можем извлечь и другую, не менее важную информацию, например, имя узла, его значение, а также его атрибуты. Имя узла можно получить методом get NodeName(), его содержимое методом getNodeValue(), а список атрибутов методом getAttributes(). Метод getAttributes() возвращает объект класса NamedNodeMap, который содержит в себе коллекцию объектов класса Node, каждый из которых и представляет определенный атрибут элемента. Для извлечения имени и значения каждого атрибута необходимо воспользоваться только что упоминавшимися методами: getNodeName() и getNodeValue() для каждого из объектов полученной коллекции. В интерфейсе NamedNodeMap есть два метода, о существовании которых нужно знать. Первый — это метод, возвращающий количество элементов, getLength(), а второй — для извлечения элементов с указанным индексом, item(int). Если узел не содержит атрибутов, то возвращается null.
Установить значение узла можно методом setNodeValue(). А узнать о существовании или отсутствии дочерних узлов можно методом hasChildNodes(), который возвращает значение типа boolean. В случае значения true дочерние узлы есть, если же значение false, их нет. Если дочерние элементы есть, и нам нужно их получить, то можно воспользоваться методом getChildNodes(), который возвращает объект класса NodeList (см. ниже), в котором содержатся ссылки на все дочерние узлы.
Не будем останавливаться на всех методах этого интерфейса, потому как их количество значительно превышает наши потребности для решения поставленной задачи. Приведенных выше методов для этого более чем достаточно.
Интерфейс Document. Здесь необходимо выделить один из самых полезных методов — это getElementsByTagName(String). В качестве параметра задается имя элемента. Метод возвращает объект класса NodeList (среди его методов также присутствуют getLength() и item(int), как у NamedNodeMap), содержащий ссылки на все элементы с заданным именем. Очень похожий метод также присутствует в интерфейсе Element. Он тоже называется getElementsByTagName(String). Работа этого метода идентична вышерассмотренному, с той лишь разницей, что этот метод ищет элементы только среди вложенных элементов текущего узла, а ранее рассмотренный по всему документу вне зависимости от расположения искомых элементов.
Этого вполне достаточно, чтобы приступить к написанию программы. Вот и она:
import java.io.FileInputStream;
import org.w3c.dom.*;
import com.sun.xml.tree.*;
public class LibraryParser2
{
public static void main(String argv[])
{
FileInputStream fis;
Document doc;
Node n;
try
{
fis = new FileInputStream ("./sample.xml");
doc = new XmlDocument.create XmlDocument(fis, true);
NodeList nl = doc.getElementsByTagName("book");
if (nl.getLength() == 0) return;
for (int i = 0; i < nl.getLength(); i++)
{
n = nl.item(i);
NamedNodeMap nnm = n.get Attributes();
System.out.println("\n #" + nnm.item(0).getNodeValue());
if (n.hasChildNodes())
{
NodeList nlTemp = n.getChildNodes();
System.out.println("Title: " + nlTemp.item(0).getNodeValue());
System.out.println("Author: " + nl Temp.item(1).getNodeValue());
System.out.println("Published: " + nl Temp.item(2).getNodeValue()+"--\n");
}
}
}
catch (Exception e)
{
e.printStackTrace();
}
}
}
Вы, должно быть, заметили, насколько объем кода данной программы отличается от нашего предыдущего решения этой задачи с использованием SAX.
Итак, мы использовали на этот раз реализацию от Sun (com.sun. xml.tree.*). Это решение обусловливается просто тем, что я не хотел останавливаться только на парсерах IBM. Хотя, в принципе, их использование мало чем отличается друг от друга. Второй из неизвестных нам подключаемых пакетов — это org.w3c.dom.*. В нем описана стандартная часть, за которую отвечает World Wide Web Consortium. Т.к. мы используем в качестве источника XML-документа обычный файл, то нам понадобится класс FileInputStream, поэтому его мы также импортируем.
Первым делом в программе мы создаем объект класса Document при помощи статического метода createXmlDocument() класса XmlDocument. Этот метод принимает два параметра. Первый — это поток или набор строк, содержащий сам XML-документ, а второй определяет, производить проверку на соответствие DTD или нет. После того, как документ создан, мы производим необходимые действия по извлечению необходимых данных из DOM-модели документа и выводим их на экран в форматном виде. В процессе извлечения мы использовали только те методы, которые были рассмотрены нами ранее. Поэтому проблем с пониманием кода, думаю, возникнуть не должно.
На этом мы закончим разговор о методах анализа XML-документов средствами Java. Тема далеко не исчерпана и будет затрагиваться и в дальнейшем. С вопросами и предложениями — пишите.
Алексей Литвинюк
Компьютерная газета. Статья была опубликована в номере 45 за 2002 год в рубрике программирование :: java
