
Обучение, самоорганизация и эволюция как методы в искусственном интеллекте 2
Обучение, самоорганизация и эволюция как методы
в искусственном интеллекте
Нейронные сети. Обучение.
Первой формальной моделью нейронных сетей (НС) была модель Маккаллока-Питтса, уточненная и развитая Клини. Важная историческая роль этой модели заключалась в установлении того, что НС способны выполнять любые логические операции и вообще любые преобразования, реализуемые дискретными устройствами с конечной памятью. Эта модель легла в основу теории логических сетей и конечных автоматов и активно использовалась психологами и нейрофизиологами при моделировании некоторых локальных процессов нервной деятельности. В силу своей дискретности она вполне согласуется с компьютерной парадигмой и, более того, служит ее, так сказать, "нейронным фундаментом". Но при этом она содержит существенные возможности своего расширения за счет максимального использования параметрических и пороговых свойств нейрона [3].
Нейронные сети характеризуются нечетким представлением и переработкой информации, высоким параллелизмом обработки информации и распределенным хранением информации. Т.е. нет такого отдельного нейрона, который отвечал бы за какое-либо понятие. И если из сети изъять какой-нибудь нейрон, это не будет фатальным и приведет лишь к небольшому изменению точности решений.
Многие современные НС сконструированы из формальных нейронов, отдаленно напоминающих свой биологический прототип и имеющих следующий вид (рис. 3) [2,3,6,7]:

рис. 3
где x 1 ..x n — значения, поступающие на входы (синапсы) нейрона, w 1 ..w n — веса синапсов (могут быть как тормозящими, так и усиливающими), S — взвешенная сумма входных сигналов [2,3,6,7]:

t — порог нейрона, во многих моделях обходятся без него, f — функция активации нейрона, преобразующая взвешенную сумму в выходной сигнал , взвешенная сумма может быть интерпретирована как проекция входного вектора на вектор весов, где
, взвешенная сумма может быть интерпретирована как проекция входного вектора на вектор весов, где  — угол между этими векторами.
— угол между этими векторами.
Функции активации могут быть различными [6,7]:
— линейная ;
;
— пороговая бинарная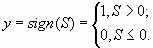 или биполярная
или биполярная  ;
;
— линейная ограниченная ;
;
— модифицированная пороговая (используется в ассоциативной памяти)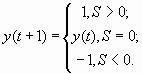 , t — параметр времени;
, t — параметр времени;
— сигмоидная , где c>0 — коэффициент ширины сигмоиды по оси абсцисс, данная функция монотонна и дифференцируема на всей области и поэтому получила широкое распространение в искусственных нейронных сетях (ИНС);
, где c>0 — коэффициент ширины сигмоиды по оси абсцисс, данная функция монотонна и дифференцируема на всей области и поэтому получила широкое распространение в искусственных нейронных сетях (ИНС);
— биполярная сигмоидная , диапазон [-0.5;+0.5];
, диапазон [-0.5;+0.5];
— гиперболический тангенс ;
;
— логарифмическая, характерна тем, что имеет диапазон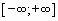 с точкой перегиба в начале координат,
с точкой перегиба в начале координат, 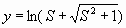 , данная функция усиливает очень слабые сигналы и ослабляет очень сильные;
, данная функция усиливает очень слабые сигналы и ослабляет очень сильные;
— радиально-базисная, характеризуется функцией Гаусса для нормального распределения , где
, где  — среднеквадратичное отклонение, характеризующее ширину функции, s в этом случае определяется как расстояние между входным и весовым вектором:
— среднеквадратичное отклонение, характеризующее ширину функции, s в этом случае определяется как расстояние между входным и весовым вектором: 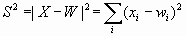 .
.
Выбор функции определяется характером решаемых задач. Следует также отметить существование других типов формальных нейронов, учитывающих другие свойства биологического нейрона. Это сигма-пи нейроны и стохастические нейроны, нейроны с поправочным блоком (сенсомоторная теория персептрона [8]), изучающие динамику объекта, и наиболее интересны голографические нейроны, используемые в голографической парадигме ИНС [3].
На сегодняшний день существует много разновидностей нейронных сетей, характерных для различных классов задач (следует напомнить, что в человеческом мозге насчитывается около 50 различных типов нейронов). Их можно классифицировать по следующим признакам [6]:
— Тип входной информации (аналоговые и двоичные).
— Характер обучения (с учителем и без).
— Характер настройки синапсов (фиксированные и динамические связи).
— Метод обучения (обратное распространение, конкурентное, правило Хебба, гибридные).
— Характер связей (прямое и прямое-обратное распространение информации).
— Архитектура: персептроны, самоорганизующиеся НС (Кохонена, адаптивного резонанса, рециркуляционные), НС с обратными связями (Хэмминга, Хопфилда, двунаправленная ассоциативная память, рекуррентные), гибридные НС (встречного распространения, с радиально-базисной функцией активации).
Рассмотрим возможности обучения ИНС на примере многослойных нейронных сетей с прямым распространением информации и методом обратного распространения ошибки при обучении.
Характер связей сети для нашего случая будет выглядеть так (рис. 4):
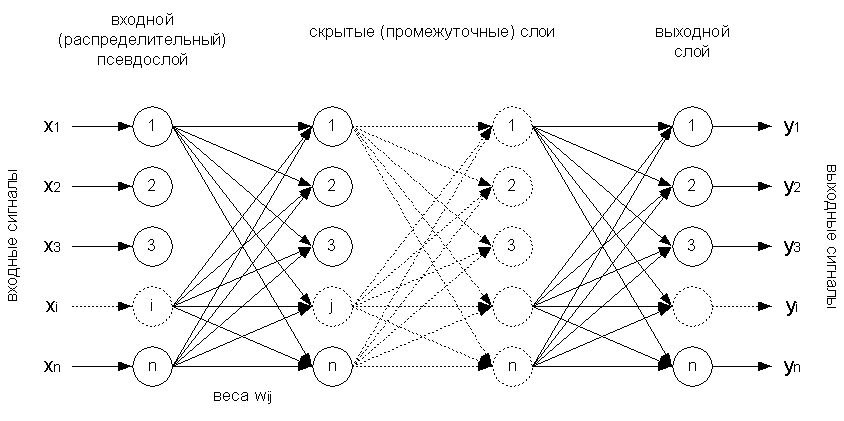
рис. 4
Входной слой никакой обработки информации не совершает и выполняет лишь распределительные функции. Как видно, нейроны некоторого слоя связаны только с нейронами предыдущего слоя, и информация распространяется от предыдущих слоев к последующим. Выбор количества слоев и типа активационной функции влияет на способность сети решать те или иные задачи. Однослойная сеть способна формировать линейные разделяющие поверхности, что сильно сужает круг задач, ими решаемых, в частности такая сеть не сможет решить задачу типа "исключающее или". Любую многослойную сеть с линейной функцией активации можно представить в виде аналогичной однослойной сети [6]:
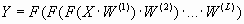 ,
,
но поскольку ,
,
то
 .
.
Поэтому для многослойных сетей необходимо использовать нелинейную функцию активации. Для объективности следует отметить, что существуют т.н. нейронные сети высокого порядка [6], в которых суммируются не только взвешенные входы (термы первого порядка), но и комбинации в виде произведения двух (термы второго порядка) или более компонент входного вектора, например для сетей второго порядка:
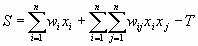 .
.
Разделяющая поверхность второго порядка называется гиперквадрикой [6]. Добавляя компоненты входного вектора в произведение, получим класс полиномиальных разделяющих поверхностей. Такие сети также можно обучать по методу обратного распространения, но многослойные НС эффективнее.
называется гиперквадрикой [6]. Добавляя компоненты входного вектора в произведение, получим класс полиномиальных разделяющих поверхностей. Такие сети также можно обучать по методу обратного распространения, но многослойные НС эффективнее.
С помощью многослойной НС с двумя перерабатывающими слоями можно с любой точностью аппроксимировать любую многомерную функцию на отрезке [0;1], что следует из теоремы Колмогорова, утверждающей, что любую непрерывную многомерную функцию на единичном отрезке [0;1] можно представить в виде конечного числа одномерных [6]:
 ,
,
функции и
и  непрерывные и одномерные,
непрерывные и одномерные, 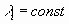 . Данное свойство НС было обобщено и на случай метода обратного распространения ошибки. Это позволяет использовать НС для решения таких задач, как прогнозирование.
. Данное свойство НС было обобщено и на случай метода обратного распространения ошибки. Это позволяет использовать НС для решения таких задач, как прогнозирование.
НС с нелинейной функцией активации и двумя перерабатывающими слоями позволяет формировать любые выпуклые области в пространстве решений, а с тремя перерабатывающими слоями — области любой сложности, в том числе и невыпуклой.
Сеть, способная решать сложные задачи, у нас есть. Теперь самое интересное — проблема нахождения весов, нужных для решения поставленной задачи. Веса можно вычислить трудоемкими математическими или статистическими методами, например, решая математическое уравнение для нахождения разделяющих поверхностей или проведя статистическую обработку множества образов-примеров для выявления сходства и различия для всевозможных комбинаций входных образов. Но такие методы имеют очень большую вычислительную трудоемкость, и для многих задач время их решения возрастает экспоненциально с ростом размерности задачи, часто на характер данных накладываются существенные ограничения. В отличие от этих методов, метод обратного распространения ошибки не вычисляет, а подстраивает веса путем градиентного спуска в пространстве весов. Здесь можно провести аналогию с поиском экстремума функции методом градиентного спуска — движение осуществляется небольшими шагами по направлению возрастания (убывания) функции, которое определяется при помощи производной, а величина шага может зависеть также и от производных более высокого порядка.
Первый, и принципиально важный шаг, с которого начинается обучение, — инициализация весов случайными значениями. А это означает потерю такого свойства, как однозначность, — каждый раз обучив сеть заново, получим абсолютно непохожий набор весов, сходство которых будет лишь в одном — в умении сети распознавать образы, которым ее обучали. Причем наборы весов, полученные для разных циклов обучения, в общем случае не могут быть преобразованы один к другому — в процессе обучения могут сформироваться различные наборы разделяющих поверхностей. Это еще одна отличительная черта ИНС от статистических методов и различных механизмов нечетких логик, которые на одном и том же входном наборе данных дают одинаковый ответ. В процессе обучения начальное отличие весов играет важную роль — сети как бы есть, от чего отталкиваться, веса, усиливающие правильное решение, увеличиваются, а неправильные веса ослабляются, формируется новый рельеф, усиливающий нужные качества исходного и ослабляющий ненужные. Обучение с одинаковыми начальными весами будет похоже на скольжение по абсолютно гладкой поверхности, на которой не за что уцепиться, под воздействием обучающих импульсов. Математически, для метода обратного распространения, это будет выражаться тем, что величины коррекции весов каждого слоя, отличного от входного, будут одинаковыми.
Если же начальные веса делать неслучайными, но различными, возможны следующие варианты: начальный рельеф будет низкого качества и впоследствии все равно придется применить случайность или качество будет достаточным, то есть каждый будет обучаться одинаково, что снижает качество решений для других примеров.
Для того чтобы оценить, насколько верное решение сделала сеть, определим среднеквадратичную ошибку как разницу между эталонным и выходным вектором [2,3,6,7]:
 ,
,
где t j — эталонное выходное значение.
Веса будем подстраивать так, чтобы минимизировать среднеквадратичную ошибку, т.е. будем производить градиентный спуск в пространстве весов (промежуточные выкладки опущены):
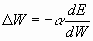 ,
,
 ,
,
где — коэффициент скорости обучения.
— коэффициент скорости обучения.
Если используется изменение порогов, оно будет выводиться аналогично:
 .
.
В [7] упоминается использование производных второго порядка для улучшения точности коррекции весов и оптимальность такого способа в том смысле, что производные более высокого порядка не позволяют улучшить оценку.
Для выходного слоя определение ошибки (правильнее сказать коэффициента коррекции веса) нейрона j тривиально и напоминает систему поощрений-наказаний дельта-правила, используемого при обучении однослойных сетей:
нейрона j тривиально и напоминает систему поощрений-наказаний дельта-правила, используемого при обучении однослойных сетей:  , а для каждого предыдущего слоя ошибка определяется рекурсивно через ошибку следующего слоя:
, а для каждого предыдущего слоя ошибка определяется рекурсивно через ошибку следующего слоя:  , т.е. для каждого j-го нейрона ошибки следующего слоя как бы распространяются к нему обратно сквозь соответствующие веса.
, т.е. для каждого j-го нейрона ошибки следующего слоя как бы распространяются к нему обратно сквозь соответствующие веса.
Почему в основу метода легло именно вычисление ошибки первого слоя по дельта-правилу и рекурсивное обратное распространение, а не вычисление всех частных производных трехмерной (т.е. для всех слоев) матрицы весов сразу? В приводимой литературе нет ответа на этот вопрос, но, видимо, это опять-таки связано с вычислительной эффективностью и простотой.
В общем виде алгоритм обучения НС по методу обратного распространения ошибки таков:
— инициализация весов случайными значениями;
— последовательно или случайно берется образ из выборки, для которого сначала производится прямой ход вычисления выходных значений, а затем обратный ход коррекции весов;
— вычисляется текущая ошибка E и сравнивается с требуемой E min, если E<E min, то обучение прекращается, иначе повторяется со второго шага.
Ошибку можно вычислять как среднюю для всех образов, так и проверить для каждого образа отдельно, в этом случае успехом считается ситуация, когда для каждого образа ошибка меньше требуемой.
Вычисление выходных значений (прямой ход) происходит так:
,
 ,
,
где — значения, подаваемые на вход сети,
— значения, подаваемые на вход сети,  — значения, снимаемые с выхода сети, l — количество слоев, k — номер слоя, изменяется по направлению от входного слоя к выходному, m — количество нейронов в слое (в общем случае слои могут различаться количеством нейронов),
— значения, снимаемые с выхода сети, l — количество слоев, k — номер слоя, изменяется по направлению от входного слоя к выходному, m — количество нейронов в слое (в общем случае слои могут различаться количеством нейронов),  — вес, связывающий нейрон i слоя k и нейрон j слоя k-1, для k-1=0 берется входной слой (т.е. система индексации такова: [№ слоя][№ нейрона в слое][№ входа нейрона]).
— вес, связывающий нейрон i слоя k и нейрон j слоя k-1, для k-1=0 берется входной слой (т.е. система индексации такова: [№ слоя][№ нейрона в слое][№ входа нейрона]).
Коррекция весов (обратный ход) осуществляется так:
а) вычисление ошибок:
 ,
,
 ,
,
номер слоя k изменяется в обратном направлении, от выходных слоев к входным;
б) изменение весов (если используются пороги, то и их):
 .
.
Приведем вид для некоторых активационных функций [2,3,6,7]:
для некоторых активационных функций [2,3,6,7]:
— сигмоидная: ;
;
— биполярная сигмоидная: ;
;
— гиперболический тангенс: ;
;
— логарифмическая: .
.
Для сигмоидной функции, например, применение будет таким:
,
.
Естественным в этом случае может быть вопрос, почему же нельзя подать на вход сети сразу все образы? То есть подать не суммарный образ, а сначала вычислить ошибку для каждого образа, а потом произвести коррекцию усредненной ошибкой? К сожалению, в обозреваемой здесь литературе нет даже постановки такого вопроса, поэтому попытаемся ответить на него здесь. Образы, принадлежащие одному классу, могут занимать в пространстве сложную область, которая нетривиальным образом сочетается с областями других классов. Подача образов по одному как бы вычерчивает в пространстве границу данного класса, а подача усредненной ошибки таким свойством не обладает, это уже будет простым вычислением расстояний в пространстве образов от центра класса, и для этого не требуется применение нейронных сетей.
Какие же недостатки характерны для метода обратного распространения ошибки и каковы пути их устранения?
Выбор количества слоев и нейронов. Слишком большое количество нейронов может привести к переобучению сети, когда сеть будет давать правильные ответы только на примерах, которым ее обучили. Недостаточное количество нейронов не позволит сети обучится с нужным качеством. Рекомендуется соизмерять объем сети с числом обучающих примеров [2,6]. Широкие возможности открываются при использовании самоорганизации (т.е. изменения числа слоев и нейронов в процессе обучения) сети [4], интересна возможность привлечения генетических алгоритмов в процессе обучения ИНС.
Количество входных нейронов должно соответствовать размерности входного вектора. Возможно существенное увеличение скорости обучения за счет разбиения диапазона значений одного входа на дискретные промежутки и сопоставления каждому промежутку отдельного входа [2]. Количество выходных нейронов рекомендуется брать равным числу классов, здесь, конечно, присутствует некоторая избыточность, но за счет нее сеть функционирует лучше. Возможно выделение нескольких нейронов на каждый класс, причем в процессе обучения каждому нейрону сопоставить различную степень точности, с которой он должен реагировать на свой класс. Это позволит классифицировать входные образы, объединенные в нечеткие (размытые или пересекающиеся) множества [2].
Слишком большие или слишком маленькие входные значения. В этом случае входные значения можно пронормировать: .
Влияние диапазона начальных весов на решение. Рекомендуется брать небольшой диапазон [-0.1;+0.1], или, n k — количество нейронов слоя k. Для некоторых задач целесообразно инициализировать значения первого (после входного) слоя одинаковыми значениями. Это приводит к ускорению обучения и возможности невооруженным взглядом наблюдать различные комбинации входных образов, сформировавшихся на весах нейронов. Однако здесь более часто проявляется расхождение в процессе обучения.
Паралич сети. Ситуация, когда веса имеют слишком большие положительные или отрицательные значения, а производная в этом случае будет очень мала и обучение остановится. Чтобы этого не случилось, выбирают не очень большой шаг изменения весов.
Выбор шага обучения. Слишком малая скорость приводит к медленному обучению или зацикливанию в локальных минимумах, большая скорость может привести к пропусканию глобального минимума и несходимости процесса обучения. В этом случае можно использовать переменный шаг обучения, начиная с больших значений и уменьшая в процессе обучения. Существует также адаптивный шаг обучения [6], выбираемый исходя из соображения минимизации среднеквадратичной ошибки сети за счет выбора величины шага. Ускорения обучения можно достигнуть с помощью метода импульса [2,7], заключается в добавлении к величине коррекции веса величины, пропорциональной предыдущему изменению:
 .
.
Так же неоптимален диапазон выходных значений [0;1], в [7] упоминается ускорение обучения при использовании биполярной сигмоидной функции.

рис. 5
Проблема поиска глобального минимума ошибки. В общем случае результат обучения НС выдает субоптимальное решение, т.е. не глобальный оптимум, а решение, которое нас устроит. В самом деле (рис. 5), если Е лок2 <Е требуемое, то такое решение вполне приемлемо. Другое дело, когда веса попадают в область локального минимума (такого как Е лок1 ) и при этом Е лок >Е требуемое, а величины шага обучения не хватает, чтобы выйти оттуда. В этом случае (т.е. при стабилизации весов и неизменности Е) шаг обучения кратковременно увеличивают. Однако в целом это проблемы не решает. Существуют стохастические методы [6,7], но они медленные. Суть их такова: совершаются псевдослучайные изменения весов, и в случае уменьшения ошибки изменения сохраняются, в противном случае эти изменения могут сохраняться с некоторой малой вероятностью, зависящей от температуры. Величина изменения весов зависит от температуры, которая уменьшается в процессе обучения. Можно провести аналогию с тряской шарика в коробке с волнистой поверхностью: постепенно уменьшая силу тряски, шарик скорее всего попадет в самое низкое место. Привлекательно также выглядит использование генетических алгоритмов в процессе обучения сети (особенно в свете того, что обучение сети все-таки является NP-трудной задачей [6]).
Расхождение в процессе обучения. Наиболее ярко выражено в гетерогенных сетях (для каждого слоя различные функции активации), используемых, в частности, для прогнозирования хода различных процессов [6]. Для преодоления этого недостатка используется послойное обучение, проявившее себя полностью устойчивым для некоторых задач. В этом алгоритме не вычисляются все ошибки сразу с последующей одновременной коррекцией всех весов. Суть алгоритма такова: корректировка весов для каждого слоя осуществляется отдельно, начиная с выходного слоя и двигаясь по направлению ко входу; корректируются веса текущего слоя, после чего выходы всех нейронов и ошибки опять пересчитываются (для того же образа) — и так до достижения входного слоя.
Окончание следует. Интересующие вас вопросы, связанные с искусственным интеллектом, можно задать на AI-Forum'е: http://www.pool-7.ru/alexkuck/aiforum
Дмитрий Брилюк
bdv78@newmail.ru
http://bdv78.newmail.ru
(c) компьютерная газета
в искусственном интеллекте
Нейронные сети. Обучение.
Первой формальной моделью нейронных сетей (НС) была модель Маккаллока-Питтса, уточненная и развитая Клини. Важная историческая роль этой модели заключалась в установлении того, что НС способны выполнять любые логические операции и вообще любые преобразования, реализуемые дискретными устройствами с конечной памятью. Эта модель легла в основу теории логических сетей и конечных автоматов и активно использовалась психологами и нейрофизиологами при моделировании некоторых локальных процессов нервной деятельности. В силу своей дискретности она вполне согласуется с компьютерной парадигмой и, более того, служит ее, так сказать, "нейронным фундаментом". Но при этом она содержит существенные возможности своего расширения за счет максимального использования параметрических и пороговых свойств нейрона [3].
Нейронные сети характеризуются нечетким представлением и переработкой информации, высоким параллелизмом обработки информации и распределенным хранением информации. Т.е. нет такого отдельного нейрона, который отвечал бы за какое-либо понятие. И если из сети изъять какой-нибудь нейрон, это не будет фатальным и приведет лишь к небольшому изменению точности решений.
Многие современные НС сконструированы из формальных нейронов, отдаленно напоминающих свой биологический прототип и имеющих следующий вид (рис. 3) [2,3,6,7]:
рис. 3
где x 1 ..x n — значения, поступающие на входы (синапсы) нейрона, w 1 ..w n — веса синапсов (могут быть как тормозящими, так и усиливающими), S — взвешенная сумма входных сигналов [2,3,6,7]:
t — порог нейрона, во многих моделях обходятся без него, f — функция активации нейрона, преобразующая взвешенную сумму в выходной сигнал
Функции активации могут быть различными [6,7]:
— линейная
— пороговая бинарная
— линейная ограниченная
— модифицированная пороговая (используется в ассоциативной памяти)
— сигмоидная
— биполярная сигмоидная
— гиперболический тангенс
— логарифмическая, характерна тем, что имеет диапазон
— радиально-базисная, характеризуется функцией Гаусса для нормального распределения
Выбор функции определяется характером решаемых задач. Следует также отметить существование других типов формальных нейронов, учитывающих другие свойства биологического нейрона. Это сигма-пи нейроны и стохастические нейроны, нейроны с поправочным блоком (сенсомоторная теория персептрона [8]), изучающие динамику объекта, и наиболее интересны голографические нейроны, используемые в голографической парадигме ИНС [3].
На сегодняшний день существует много разновидностей нейронных сетей, характерных для различных классов задач (следует напомнить, что в человеческом мозге насчитывается около 50 различных типов нейронов). Их можно классифицировать по следующим признакам [6]:
— Тип входной информации (аналоговые и двоичные).
— Характер обучения (с учителем и без).
— Характер настройки синапсов (фиксированные и динамические связи).
— Метод обучения (обратное распространение, конкурентное, правило Хебба, гибридные).
— Характер связей (прямое и прямое-обратное распространение информации).
— Архитектура: персептроны, самоорганизующиеся НС (Кохонена, адаптивного резонанса, рециркуляционные), НС с обратными связями (Хэмминга, Хопфилда, двунаправленная ассоциативная память, рекуррентные), гибридные НС (встречного распространения, с радиально-базисной функцией активации).
Рассмотрим возможности обучения ИНС на примере многослойных нейронных сетей с прямым распространением информации и методом обратного распространения ошибки при обучении.
Характер связей сети для нашего случая будет выглядеть так (рис. 4):
рис. 4
Входной слой никакой обработки информации не совершает и выполняет лишь распределительные функции. Как видно, нейроны некоторого слоя связаны только с нейронами предыдущего слоя, и информация распространяется от предыдущих слоев к последующим. Выбор количества слоев и типа активационной функции влияет на способность сети решать те или иные задачи. Однослойная сеть способна формировать линейные разделяющие поверхности, что сильно сужает круг задач, ими решаемых, в частности такая сеть не сможет решить задачу типа "исключающее или". Любую многослойную сеть с линейной функцией активации можно представить в виде аналогичной однослойной сети [6]:
но поскольку
то
Поэтому для многослойных сетей необходимо использовать нелинейную функцию активации. Для объективности следует отметить, что существуют т.н. нейронные сети высокого порядка [6], в которых суммируются не только взвешенные входы (термы первого порядка), но и комбинации в виде произведения двух (термы второго порядка) или более компонент входного вектора, например для сетей второго порядка:
Разделяющая поверхность второго порядка
С помощью многослойной НС с двумя перерабатывающими слоями можно с любой точностью аппроксимировать любую многомерную функцию на отрезке [0;1], что следует из теоремы Колмогорова, утверждающей, что любую непрерывную многомерную функцию на единичном отрезке [0;1] можно представить в виде конечного числа одномерных [6]:
функции
НС с нелинейной функцией активации и двумя перерабатывающими слоями позволяет формировать любые выпуклые области в пространстве решений, а с тремя перерабатывающими слоями — области любой сложности, в том числе и невыпуклой.
Сеть, способная решать сложные задачи, у нас есть. Теперь самое интересное — проблема нахождения весов, нужных для решения поставленной задачи. Веса можно вычислить трудоемкими математическими или статистическими методами, например, решая математическое уравнение для нахождения разделяющих поверхностей или проведя статистическую обработку множества образов-примеров для выявления сходства и различия для всевозможных комбинаций входных образов. Но такие методы имеют очень большую вычислительную трудоемкость, и для многих задач время их решения возрастает экспоненциально с ростом размерности задачи, часто на характер данных накладываются существенные ограничения. В отличие от этих методов, метод обратного распространения ошибки не вычисляет, а подстраивает веса путем градиентного спуска в пространстве весов. Здесь можно провести аналогию с поиском экстремума функции методом градиентного спуска — движение осуществляется небольшими шагами по направлению возрастания (убывания) функции, которое определяется при помощи производной, а величина шага может зависеть также и от производных более высокого порядка.
Первый, и принципиально важный шаг, с которого начинается обучение, — инициализация весов случайными значениями. А это означает потерю такого свойства, как однозначность, — каждый раз обучив сеть заново, получим абсолютно непохожий набор весов, сходство которых будет лишь в одном — в умении сети распознавать образы, которым ее обучали. Причем наборы весов, полученные для разных циклов обучения, в общем случае не могут быть преобразованы один к другому — в процессе обучения могут сформироваться различные наборы разделяющих поверхностей. Это еще одна отличительная черта ИНС от статистических методов и различных механизмов нечетких логик, которые на одном и том же входном наборе данных дают одинаковый ответ. В процессе обучения начальное отличие весов играет важную роль — сети как бы есть, от чего отталкиваться, веса, усиливающие правильное решение, увеличиваются, а неправильные веса ослабляются, формируется новый рельеф, усиливающий нужные качества исходного и ослабляющий ненужные. Обучение с одинаковыми начальными весами будет похоже на скольжение по абсолютно гладкой поверхности, на которой не за что уцепиться, под воздействием обучающих импульсов. Математически, для метода обратного распространения, это будет выражаться тем, что величины коррекции весов каждого слоя, отличного от входного, будут одинаковыми.
Если же начальные веса делать неслучайными, но различными, возможны следующие варианты: начальный рельеф будет низкого качества и впоследствии все равно придется применить случайность или качество будет достаточным, то есть каждый будет обучаться одинаково, что снижает качество решений для других примеров.
Для того чтобы оценить, насколько верное решение сделала сеть, определим среднеквадратичную ошибку как разницу между эталонным и выходным вектором [2,3,6,7]:
где t j — эталонное выходное значение.
Веса будем подстраивать так, чтобы минимизировать среднеквадратичную ошибку, т.е. будем производить градиентный спуск в пространстве весов (промежуточные выкладки опущены):
где
Если используется изменение порогов, оно будет выводиться аналогично:
В [7] упоминается использование производных второго порядка для улучшения точности коррекции весов и оптимальность такого способа в том смысле, что производные более высокого порядка не позволяют улучшить оценку.
Для выходного слоя определение ошибки (правильнее сказать коэффициента коррекции веса)
Почему в основу метода легло именно вычисление ошибки первого слоя по дельта-правилу и рекурсивное обратное распространение, а не вычисление всех частных производных трехмерной (т.е. для всех слоев) матрицы весов сразу? В приводимой литературе нет ответа на этот вопрос, но, видимо, это опять-таки связано с вычислительной эффективностью и простотой.
В общем виде алгоритм обучения НС по методу обратного распространения ошибки таков:
— инициализация весов случайными значениями;
— последовательно или случайно берется образ из выборки, для которого сначала производится прямой ход вычисления выходных значений, а затем обратный ход коррекции весов;
— вычисляется текущая ошибка E и сравнивается с требуемой E min, если E<E min, то обучение прекращается, иначе повторяется со второго шага.
Ошибку можно вычислять как среднюю для всех образов, так и проверить для каждого образа отдельно, в этом случае успехом считается ситуация, когда для каждого образа ошибка меньше требуемой.
Вычисление выходных значений (прямой ход) происходит так:
где
Коррекция весов (обратный ход) осуществляется так:
а) вычисление ошибок:
номер слоя k изменяется в обратном направлении, от выходных слоев к входным;
б) изменение весов (если используются пороги, то и их):
Приведем вид
— сигмоидная:
— биполярная сигмоидная:
— гиперболический тангенс:
— логарифмическая:
Для сигмоидной функции, например, применение будет таким:
Естественным в этом случае может быть вопрос, почему же нельзя подать на вход сети сразу все образы? То есть подать не суммарный образ, а сначала вычислить ошибку для каждого образа, а потом произвести коррекцию усредненной ошибкой? К сожалению, в обозреваемой здесь литературе нет даже постановки такого вопроса, поэтому попытаемся ответить на него здесь. Образы, принадлежащие одному классу, могут занимать в пространстве сложную область, которая нетривиальным образом сочетается с областями других классов. Подача образов по одному как бы вычерчивает в пространстве границу данного класса, а подача усредненной ошибки таким свойством не обладает, это уже будет простым вычислением расстояний в пространстве образов от центра класса, и для этого не требуется применение нейронных сетей.
Какие же недостатки характерны для метода обратного распространения ошибки и каковы пути их устранения?
Выбор количества слоев и нейронов. Слишком большое количество нейронов может привести к переобучению сети, когда сеть будет давать правильные ответы только на примерах, которым ее обучили. Недостаточное количество нейронов не позволит сети обучится с нужным качеством. Рекомендуется соизмерять объем сети с числом обучающих примеров [2,6]. Широкие возможности открываются при использовании самоорганизации (т.е. изменения числа слоев и нейронов в процессе обучения) сети [4], интересна возможность привлечения генетических алгоритмов в процессе обучения ИНС.
Количество входных нейронов должно соответствовать размерности входного вектора. Возможно существенное увеличение скорости обучения за счет разбиения диапазона значений одного входа на дискретные промежутки и сопоставления каждому промежутку отдельного входа [2]. Количество выходных нейронов рекомендуется брать равным числу классов, здесь, конечно, присутствует некоторая избыточность, но за счет нее сеть функционирует лучше. Возможно выделение нескольких нейронов на каждый класс, причем в процессе обучения каждому нейрону сопоставить различную степень точности, с которой он должен реагировать на свой класс. Это позволит классифицировать входные образы, объединенные в нечеткие (размытые или пересекающиеся) множества [2].
Слишком большие или слишком маленькие входные значения. В этом случае входные значения можно пронормировать:
Влияние диапазона начальных весов на решение. Рекомендуется брать небольшой диапазон [-0.1;+0.1], или
Паралич сети. Ситуация, когда веса имеют слишком большие положительные или отрицательные значения, а производная в этом случае будет очень мала и обучение остановится. Чтобы этого не случилось, выбирают не очень большой шаг изменения весов.
Выбор шага обучения. Слишком малая скорость приводит к медленному обучению или зацикливанию в локальных минимумах, большая скорость может привести к пропусканию глобального минимума и несходимости процесса обучения. В этом случае можно использовать переменный шаг обучения, начиная с больших значений и уменьшая в процессе обучения. Существует также адаптивный шаг обучения [6], выбираемый исходя из соображения минимизации среднеквадратичной ошибки сети за счет выбора величины шага. Ускорения обучения можно достигнуть с помощью метода импульса [2,7], заключается в добавлении к величине коррекции веса величины, пропорциональной предыдущему изменению:
Так же неоптимален диапазон выходных значений [0;1], в [7] упоминается ускорение обучения при использовании биполярной сигмоидной функции.
рис. 5
Проблема поиска глобального минимума ошибки. В общем случае результат обучения НС выдает субоптимальное решение, т.е. не глобальный оптимум, а решение, которое нас устроит. В самом деле (рис. 5), если Е лок2 <Е требуемое, то такое решение вполне приемлемо. Другое дело, когда веса попадают в область локального минимума (такого как Е лок1 ) и при этом Е лок >Е требуемое, а величины шага обучения не хватает, чтобы выйти оттуда. В этом случае (т.е. при стабилизации весов и неизменности Е) шаг обучения кратковременно увеличивают. Однако в целом это проблемы не решает. Существуют стохастические методы [6,7], но они медленные. Суть их такова: совершаются псевдослучайные изменения весов, и в случае уменьшения ошибки изменения сохраняются, в противном случае эти изменения могут сохраняться с некоторой малой вероятностью, зависящей от температуры. Величина изменения весов зависит от температуры, которая уменьшается в процессе обучения. Можно провести аналогию с тряской шарика в коробке с волнистой поверхностью: постепенно уменьшая силу тряски, шарик скорее всего попадет в самое низкое место. Привлекательно также выглядит использование генетических алгоритмов в процессе обучения сети (особенно в свете того, что обучение сети все-таки является NP-трудной задачей [6]).
Расхождение в процессе обучения. Наиболее ярко выражено в гетерогенных сетях (для каждого слоя различные функции активации), используемых, в частности, для прогнозирования хода различных процессов [6]. Для преодоления этого недостатка используется послойное обучение, проявившее себя полностью устойчивым для некоторых задач. В этом алгоритме не вычисляются все ошибки сразу с последующей одновременной коррекцией всех весов. Суть алгоритма такова: корректировка весов для каждого слоя осуществляется отдельно, начиная с выходного слоя и двигаясь по направлению ко входу; корректируются веса текущего слоя, после чего выходы всех нейронов и ошибки опять пересчитываются (для того же образа) — и так до достижения входного слоя.
Окончание следует. Интересующие вас вопросы, связанные с искусственным интеллектом, можно задать на AI-Forum'е: http://www.pool-7.ru/alexkuck/aiforum
Дмитрий Брилюк
bdv78@newmail.ru
http://bdv78.newmail.ru
(c) компьютерная газета
Компьютерная газета. Статья была опубликована в номере 45 за 2000 год в рубрике разное :: мелочи жизни
