
Зачем таблице нужен ключ
Так определяется ключ, называемый "первичным". Однако во многих случаях первичного ключа оказывается недостаточно для индексации содержимого таблицы, особенно в случаях больших таблиц со множеством полей почти наверняка в процессе работы придется отбирать из них данные и по другим критериям, отличным от простого номера строки в таблице: в таблице адресов это может быть наименование населенного пункта при выборке данных для определенных регионов; в таблице продаж это может быть категория или группа товара, например бакалея или молочные продукты, при выявления статистических показателей по этим категориям. Таким образом, в определенных случаях возникает потребность в создании так называемых "индексов". Индекс - это дополнительная внутренняя таблица Microsoft Access, состоящая всего из двух столбцов: в первом содержатся значения полей, включенных в индекс, а во втором - местоположение этих полей в индексируемой таблице. Сама таблица индексов нигде не отражается и вообще никоим образом для пользователя не видна, тем не менее, начиная с момента создания, она строго привязана к конкретной таблице с данными и всегда доступна для встроенных в СУБД механизмов поиска. Применение индексов значительно ускоряет просмотр и выборку данных, так как СУБД может сразу обратиться к внутренней таблице индексов, вместо того чтобы сначала сортировать огромный массив данных по заданным условиям, потом выделять из него необходимую информацию и лишь затем уже делать с ней то, что пожелал составитель запроса. Правда, имеют индексы и оборотную сторону - каждый из них занимает дополнительное место на жестком диске, а также в оперативной памяти. К тому же сама база данных начинает открываться медленнее, так как каждый раз при запуске СУБД, например Microsoft Access 97, заново проводит перерасчет всех индексов, что требует определенного времени. Таким образом, желательно еще на этапе проектирования общей архитектуры конкретной СУБД продумывать степень разбивки данных по отдельным таблицам исходя из возможных потребностей в них. Иногда самым лучшим бывает создать одну большую таблицу и назначить ей несколько индексов, что также возможно, а иногда проще сразу сделать несколько таблиц меньшего размера, но обойтись минимальным количеством индексов или вообще без них.
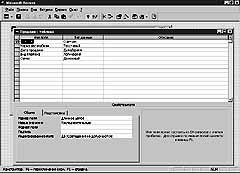
Даже чтобы точно указать число ее значащих величин, мало прочитать номер последней строки, нужно непременно писать специальный модуль, который будет проверять наличие пустых ячеек и подсчитывать их количество. Это и долго, и ресурсов требует, и времени. Так что, коль уж возникла нужда в отдельном индексировании каких-то полей таблицы, то пусть уж СУБД сразу избавит нас от лишней головной боли с этими пустыми ячейками. Хотя в некоторых случаях отсутствие информации даже само по себе может быть информацией. Допустим, отсутствие специальной галочки может, к примеру, означать, что клиент расплачивался наличными, а не кредитной карточкой.
Почти так же, как и по одному полю, индекс можно составить по двум и более полям. Вернемся к нашей автомобильной фирме. Предположим, что мы закупаем автомобили не от случая к случаю и не партиями, а официально представляем в данном регионе определенных производителей - таким образом, поставки происходят "под заказ". В то же время известно, что заводы поставляют машины сериями, что отражается в их ценах: там - на десять долларов дороже, тут - на пятерку дешевле и так далее. Технически, создавая собственную СУБД, программистам предстоит создать отдельную таблицу, в которой фиксировать каждую конкретную поставку. Однако может быть и другое решение, конкретная поставка однозначно идентифицируется также при помощи составного индекса. Зная марку машины и ее цену, можно совершенно однозначно сказать, из какой она партии. Это один из примеров составного индекса, объясняющий область их применения.
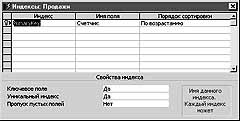
Чтобы создать составной индекс, например, состоящий из двух полей ("Марка автомобиля" и "Цена"), нужно проделать следующее: открыть нужную таблицу в режиме конструктора (в нашем случае - таблицу ПРОДАЖИ), в меню ВИД выбрать режим ИНДЕКСЫ (на экране должен появиться уже известный вам мастер (см. рис. 2)), в графе " Индекс" набрать с клавиатуры желаемое имя вновь создаваемого индекса. С этого момента процедура немного изменяется, вместо одного имени поля, нужно указать два (или более) - первое из них выбирается в поле " Имя поля" той же строки в поле " Индекс", которой вами только что было набрано имя этого составного индекса, а имя второго поля - строкой ниже. Далее по стандартной методике - когда все готово, окно мастера просто закрывается, как любое другое окно в Microsoft Windows 95, при помощи перечеркнутого квадратика, расположенного в правом верхнем углу. Отныне, продолжая разрабатывать базу данных, можно при создании запросов ссылаться не просто на те или иные поля таблицы, а исключительно на специально индексированные поля. В этом случае СУБД Microsoft Access 97 не станет перебирать саму базовую таблицу, а сразу же воспользуется таблицей соответствующего индекса. Компьютер весьма справедливо полагает, что с индексами придется возиться куда меньше, чем с самой таблицей данных. Причем следует помнить: составным индексом СУБД предпочитает пользоваться даже тогда, когда запрос касается не всех его полей, а лишь некоторых из них или даже вообще всего одним полем.
Вот и получается, что одним из самых важных дел, если вообще не важнейшим, является не конструирование схемы самих таблиц и их содержимого, а определение первичных ключей и всевозможных индексов. Вообще, ключи - дело полезное и удобное, а для СУБД так и вообще незаменимое.
Александр Запольскис
Компьютерная газета. Статья была опубликована в номере 06 за 1999 год в рубрике soft :: субд
