
Ускоренный графический порт (AGP)
Ускоренный графический порт (AGP)
Он стал достаточно мощным для высококачественной 3D-графики. Он стал достаточно мультимедийным для "живого" интерактивного видео и объемного звучания. В этом году на рынке будут господствовать системы на базе процессоров класса Pentium II и программы с такими возможностями представления информации, о которых пару лет назад и не догадывались пользователи персональных компьютеров.
Сегодня владельцы новых РС могут наслаждаться впечатляющей трехмерной графикой и видео, уровень качества которых раньше был доступен только на рабочих станциях стоимостью за $20,000. И достичь этого удалось во многом благодаря разработкам корпорации Intel, новые процессоры Pentium II которой в сочетании с созданным ею специальным ускоренным графическим портом (Accellerated Graphics Port, AGP) сделали реалистичную 3D-графику и "живое" видео доступными массовому пользователю.
Эти передовые разработки открывают возможности дальнейшего развития архитектуры персональных компьютеров платформы РС и позволяют перейти от ограниченных пропускной способностью шины PCI машин к "визуальным" компьютерам будущего (Visual Connected PC). Время сделать это уже настало.
Конструкция персональных компьютеров следующего поколения обеспечит производительность, требуемую для аркадного качества графики, интерактивных информационных 3D-систем, интерактивного видео, улучшенных приложений моделирования для систем CAD/CAM, захватывающей 3D-визуализации данных и новых трехмерных виртуальных миров VRML.
Однако появляющиеся уже сегодня приложения 3D-графики предъявляют к платформе РС целый букет жестких требований, которые для нее еще вчера были непосильны. Эти требования связаны с более быстрыми геометрическими вычислениями, более изощренными методами визуализации и более детализированными текстурами. Причем если новейшие процессоры, по производительности равные Pentium II, вполне способны справиться с возросшим объемом геометрических расчетов, а новое поколение чипов графических ускорителей поддерживает множество разнообразных эффектов визуализации, то растущий размер текстурных карт становится проблемой N№1.
Один из аспектов этой проблемы связан с объемом локальной видеопамяти, используемой графическим контроллером. Обычно на графической плате имеется 2 - 4 мегабайта такой памяти, в то время как уже появились 3D-приложения, использующие текстурные карты размером под 20 мегабайт. Видеопамять можно расширить, чтобы она удовлетворяла таким требованиям, но в результате компьютеры станут страшно дорогими и немасштабируемыми.
Второй источник головной боли - пропускная способность шины PCI. Графические контроллеры нуждаются в перекачке текстурных карт из основной памяти системы в свою локальную, и по мере роста размеров текстур шина PCI становится узким местом, сдерживающим быстродействие 3D-графики. Еще острее вопрос с приложениями, которые используют "живое" видео.
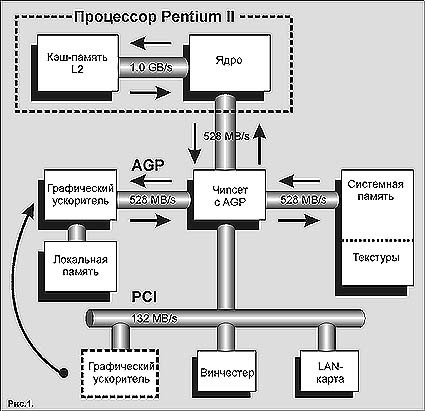
Решение найдено, и оно уже вполне доступно массовому пользователю. Технология AGP (структурная схема системы на ее основе показана на рис. 1) повышает общую производительность компьютера, предоставляя отдельный высокоскоростной канал между графическим контроллером и системной памятью. Эта магистраль позволяет графическому контроллеру обрабатывать текстуры прямо в основной памяти, а также служит руслом для потока декодированных центральным процессором видеоданных.
Вот и настал момент, когда всем пользователям, если их, конечно, еще интересуют перспективные направления в компьютерной технике, стоит ближе познакомиться с AGP и разобраться в основах того, как эта технология работает. Разумеется, несмотря на популярность материала, от вас потребуются некоторые представления о 3D-графике и архитектуре РС, так как начать с самых азов нет возможности.
3D-графика в предыдущем поколении РС
AGP - это новый интерфейс в компьютерах платформы РС, значительно улучшающий обработку трехмерной графики и "живого" видео. Для того чтобы полностью понять важность технологии AGP для современных и будущих приложений, необходимо сначала посмотреть, как 3D-графика поддерживается в настоящее время персональными компьютерами без AGP.
Известно, что анимированная 3D-графика требует от процессора производительности, достаточной для постоянных геометрических вычислений, которые определяют положение объектов в трехмерном пространстве. Обычно геометрические вычисления выполняются центральным процессором персонального компьютера, поскольку он хорошо подходит для нужных при расчетах операций с плавающей точкой. В то же время графический контроллер должен обрабатывать текстурные данные, чтобы создать в 3D-изображении реалистичные поверхности и тени.
Наиболее критичный аспект 3D-графики - обработка текстурных карт, то есть растровых изображений (карт), которые описывают детали поверхности трехмерных объектов. Обработка текстурных карт заключается в выборке одного, двух, четырех или восьми текселов (текстурных элементов) из растровой карты, их "усреднения", необходимого для получения окончательного изображения, с помощью математической аппроксимации положения в растровой карте (или нескольких картах) и записи полученных в результате пикселов в кадровый буфер графической платы. Расчет координат текселов является нетривиальной функцией; параметрами для нее служат координаты точки наблюдения за 3D-сценой и геометрия объекта, на который проецируются ("натягиваются") растровые карты.
Схема на рис.2 отражает процесс обработки текстурных карт предыдущим поколением персональных компьютеров. Как показано, процесс обработки текстур можно разложить на пять основных шагов.
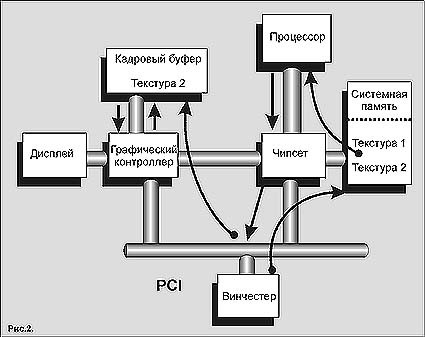 1. Перед использованием текстурные карты считываются с жесткого диска и загружаются в системную память компьютера. При этом данные до загрузки в память проходят через шину IDE и микросхемы чипсета.
1. Перед использованием текстурные карты считываются с жесткого диска и загружаются в системную память компьютера. При этом данные до загрузки в память проходят через шину IDE и микросхемы чипсета.
2. Когда текстурная карта должна быть использована для трехмерной сцены, она считывается из системной памяти процессором. Процессор выполняет над текстурной картой зависящие от точки наблюдения преобразования и сохраняет результаты в кэш-буфере.
3. Над текстурной картой, размещенной в буфере, выполняются преобразования, связанные с расположением внутри 3D-сцены источников освещения и точки наблюдения. Результаты этих операций впоследствии записываются обратно в системную память.
4. Затем графический контроллер считывает преобразованные текстуры из системной памяти и записывает их в свою локальную видеопамять (называемую также памятью графического контроллера, кадровым буфером, экранной памятью). В системах предыдущего поколения, которые составляют сегодня основную часть парка персональных компьютеров, данные при этом должны пройти к графическому контроллеру по шине PCI.
5. Теперь графический контроллер считывает текстуры и двумерную цветовую информацию из своего кадрового буфера. Эти данные используются при визуализации кадра, который можно показать на двумерном экране монитора. Результаты записываются обратно в кадровый буфер. После этого размещенный на графической плате цифро-аналоговый преобразователь (RAMDAC) прочитывает содержимое кадрового буфера и преобразует представленные в цифровом виде пикселы в аналоговые сигналы, управляющие дисплеем.
Возможно, вы уже обратили внимание на массу проблем, сопровождающих описанный и широко применяющийся в настоящее время способ обработки текстурных карт.
Во-первых, текстуры должны храниться как в системной памяти, так и в кадровом буфере. Избыточная копия приводит к неэффективному использованию имеющихся в персональном компьютере ресурсов памяти.
Во-вторых, хранение текстур в кадровом буфере, пусть даже временное, накладывает жесткие ограничения на их размер. Поскольку в последнее время отмечается потребность в текстурах со все более высокой детализацией, на производителей аппаратного обеспечения оказывается прессинг с целью увеличения в их системах емкости кадрового буфера. С учетом того, что этот вид памяти достаточно дорогой, такой подход никак нельзя назвать оптимальным решением.
Наконец, пропускная способность шины PCI, не превышающая 132 мегабайт в секунду, ограничивает скорость, с которой текстурные карты могут быть переданы из памяти графической подсистеме. Более того, обычно в системе шиной PCI совместно пользуется несколько устройств ввода-вывода, поэтому полоса пропускания распределяется между ними. С появлением в составе РС новых высокоскоростных устройств, таких как жесткие диски Ultra DMA и 100-мегабитные сетевые карты, соперничество за часть пропускной способности PCI еще более ожесточилось. Не так уж трудно заметить, как перегрузка шины PCI ограничивает 3D-производительность персональных компьютеров.
Сегодня приложения применяют множество стратегий, чтобы компенсировать ограничения, доставшиеся по наследству от вчерашних персональных компьютеров. В частности, приложения широко используют алгоритмы кэширования, или свопинга, определяя, какие текстуры обязательно будут храниться в локальном кадровом буфере, а какие можно держать только в системной памяти. Обычно приложения выделяют часть экранной памяти под область межкадрового обмена текстурами, оставляя в памяти графической платы постоянно используемые текстуры (фиксированная текстурная память), такие, например, как облака и море в самолетных симуляторах.
Если аппаратно реализована обработка только тех текстур, которые находятся в локальной памяти графической карты, обычно применяется специальный алгоритм, пытающийся загодя загрузить в нее текстуры, необходимые для каждого кадра или сцены. Без упреждающей выборки пользователи могут увидеть на экране заметные паузы, так как программное обеспечение прекращает вывод на экран, пока требуемая текстура переносится из системной памяти в локальную или, что еще хуже, сначала с винчестера в системную память и только потом в локальную. Часто еще большие задержки при начальной загрузке текстур связаны с необходимостью преобразования формата, в котором они хранятся, в зависящий от аппаратной части системы сжатый формат.
 Приложения могут для свопинга зарезервировать часть локальной памяти, оставив другую часть под загруженные "фиксированные" текстуры, используемые постоянно. В зависимости от числа используемых в кадре текстур алгоритм способен изменять пропорцию между фиксированной текстурной памятью и областью свопинга текстур. Трехмерные сцены, которые содержат большое количество текстур, обычно отличаются меньшей степенью повторного использования одних и тех же. Эта тенденция облегчает жизнь, позволяя увеличить размер памяти под текстурный свопинг.
Приложения могут для свопинга зарезервировать часть локальной памяти, оставив другую часть под загруженные "фиксированные" текстуры, используемые постоянно. В зависимости от числа используемых в кадре текстур алгоритм способен изменять пропорцию между фиксированной текстурной памятью и областью свопинга текстур. Трехмерные сцены, которые содержат большое количество текстур, обычно отличаются меньшей степенью повторного использования одних и тех же. Эта тенденция облегчает жизнь, позволяя увеличить размер памяти под текстурный свопинг.
3D-графика в следующем поколении РС
Трехмерная графика определенно окажется в выигрыше от многих усовершенствований, внесенных в последнее время в архитектуру платформы РС.
Первое и наиболее значимое из них - переход на процессоры Pentium II. Эти процессоры способны лучше справиться с вычислениями на геометрической стадии конвейера 3D-графики, то есть обеспечивают просчет в секунду большего количества треугольников, из которых строятся 3D-объекты.
Процессор Pentium II содержит не только ядро, но и интегрированную кэш-память второго уровня. Он также имеет двойную независимую шинную архитектуру, при которой ядро процессора с кэш-памятью второго уровня и системной шиной персонального компьютера соединяют две независимые шины. То, что обе эти шины способны работать в одно и то же время, значительно повышает производительность процессора, поскольку он может одновременно выполнять операции с кэшем и взаимодействовать с внешними устройствами.
Появление AGP стало другим ключевым расширением платформы РС, от которого выиграет 3D-графика. AGP устраняет узкие места в реализации трехмерной графики, добавляя новую специальную высокоскоростную шину, обеспечивающую прямое взаимодействие между чипсетом и графическим контроллером. Это выводит требующий большой пропускной способности видео- и 3D-трафик из-под ограничений шины PCI.
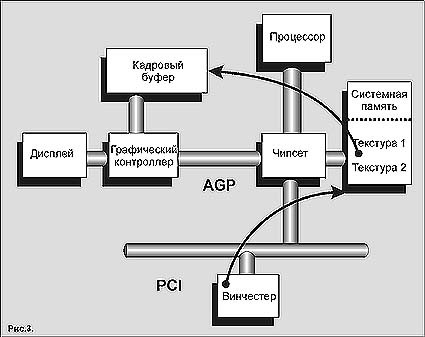
Кроме того, AGP открывает во время визуализации доступ к текстурам прямо в системной памяти вместо их упреждающей выборки в локальную графическую память (см. рис. 3). Сегменты системной памяти могут динамически резервироваться операционной системой для использования графическим контроллером - такая память называется AGP-памятью, или нелокальной видеопамятью.
 В чистом виде результат состоит в том, что графический контроллер нуждается в хранении в своей локальной памяти существенно меньшего числа текстурных карт. Меньший объем локальной памяти ведет к меньшей общей стоимости системы. Прямой доступ графического чипа к системной памяти устраняет и ограничения на объем текстур, когда их приходится размещать в локальной графической памяти. Благодаря этому приложения получают возможность использовать гораздо более детализированные и большие текстурные карты и значительно повысить реалистичность и качество трехмерных изображений.
В чистом виде результат состоит в том, что графический контроллер нуждается в хранении в своей локальной памяти существенно меньшего числа текстурных карт. Меньший объем локальной памяти ведет к меньшей общей стоимости системы. Прямой доступ графического чипа к системной памяти устраняет и ограничения на объем текстур, когда их приходится размещать в локальной графической памяти. Благодаря этому приложения получают возможность использовать гораздо более детализированные и большие текстурные карты и значительно повысить реалистичность и качество трехмерных изображений.
Наконец, необходимо отметить, что разгрузка шины PCI от графических и видеоданных оставляет на ней больше свободного места в распоряжении других высокоскоростных устройств, тоже предъявляющих большие претензии на пропускную способность шины.
Для шины AGP применен коннектор, подобный используемому для шины PCI - с 32 линиями для мультиплексированных адресов и данных. Введено 8 дополнительных линий для побочной адресации, которая описана ниже.
Локальная видеопамять обычно намного дороже, чем системная, и не может быть использована операционной системой для других целей, когда не востребована на графические нужды выполняемых приложений. Графическому контроллеру необходим как можно более быстрый доступ к локальной видеопамяти для обновления экрана, ее использования под Z-буферы и пикселы (буферы выводимого на экран и формируемого кадров). По этим причинам при использовании AGP программисты могут рассчитывать на получение большего объема текстурной памяти из общей памяти системы. Хранение текстур вне кадрового буфера обеспечивает поддержку больших разрешений экрана или Z-буферизацию для больших трехмерных сцен. Большинство новых 3D-приложений рассчитано на использование для хранения текстур от 2 до 16 мегабайт памяти. В случае AGP они могут ее получить.
Режимы передачи данных в AGP
Если максимальная скорость передачи данных по шине PCI составляет 132 мегабайта в секунду, AGP по той же частоте в 66 мегагерц способна пропустить 528 мегабайт в секунду. Столь значительное повышение скорости достигается, во-первых, за счет передачи данных как на передних, так и на задних фронтах 66-мегагерцевых тактовых импульсов, а также путем использования более эффективных режимов передачи данных. (Действительная скорость может отличаться для различных систем и приложений, но обычно она составляет 50 - 80% от пиковых значений при установившихся реальных процессах передачи данных.)
AGP предоставляет графическому контроллеру два режима для прямого доступа к текстурным картам в системной памяти: конвейеризацию и побочную адресацию. При конвейеризации AGP перекрывает время доступа к памяти или шине для запроса (n) выдачей последующих запросов (n+1, n+2 и т.д.). У шины PCI запрос n+1 не может начать выполняться, пока не будет закончена передача данных по запросу n. И если обе шины - и PCI, и AGP - способны передавать данные пакетами (передавать множество объектов данных последовательно в ответ на единственный запрос), это только частично скрывает неконвейерную сущность PCI. Глубина конвейеризации AGP зависит от ее реализации и остается невидимой для прикладных программ.
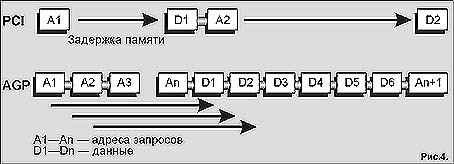
При побочной адресации AGP использует 8 дополнительных "побочных" адресных линий, которые позволяют графическому контроллеру передавать новые адреса и запросы одновременно с тем, как данные продолжают поступать в ответ на предыдущий запрос по основным 32 адресно-информационным линиям (см. рис. 4).
Распределение AGP-памяти
Так называемая AGP-память на деле является просто динамически выделяемой областью основной системной памяти, к которой организуется быстрый доступ графического контроллера. Высокая скорость обращения обеспечивается аппаратными средствами, встроенными в поддерживающие AGP чипсеты 440LX от Intel и Apollo VP3 от VIA.
Чипсет берет на себя трансляцию адресов, позволяя графическому контроллеру и его программному обеспечению "видеть" последовательную область в основной памяти, когда на самом деле она организована постранично и страницы не всегда являются смежными. Благодаря этому контроллер может обращаться к большим структурам данных, таким как растровые текстуры (обычно от 1 до 128 килобайт), как к единственному объекту (графическому примитиву).
Встроенное в чипсет аппаратное обеспечение называется таблицей преобразования графических адресов (Graphics Address Remapping Table, GART) и работает подобно устройству страничного доступа к памяти, входящему в состав центрального процессора. Процессорные "линейные" виртуальные адреса преобразуются этим устройством в физические адреса. Эти физические адреса и используются для доступа к системной памяти, локальному кадровому буферу и AGP-памяти. Причем центральный процессор обращается к локальному кадровому буферу и AGP-памяти, используя такие же адреса, как и графический контроллер. Операционная система, следовательно, конфигурирует страничное устройство центрального процессора для прямого, один к одному, бестрансляционного преобразования виртуальных адресов в физические.
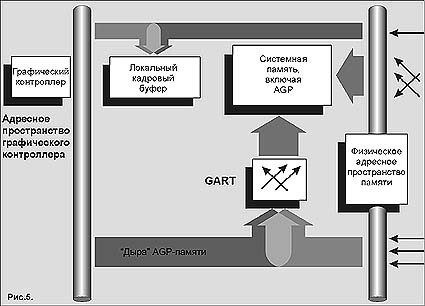 Как показано на рис. 5, для доступа к AGP-памяти и графический контроллер, и процессор используют непрерывную "дыру" в адресном пространстве памяти размером в несколько мегабайт. В свою очередь GART транслирует эти виртуальные адреса в различные, возможно несмежные, 4-килобайтные страничные адреса в системной памяти. Устройства PCI, которые обращаются к области AGP-памяти (например, для оцифровки "живого" видео), также попадают туда через GART.
Как показано на рис. 5, для доступа к AGP-памяти и графический контроллер, и процессор используют непрерывную "дыру" в адресном пространстве памяти размером в несколько мегабайт. В свою очередь GART транслирует эти виртуальные адреса в различные, возможно несмежные, 4-килобайтные страничные адреса в системной памяти. Устройства PCI, которые обращаются к области AGP-памяти (например, для оцифровки "живого" видео), также попадают туда через GART.
Подводя итоги: преимущества AGP
Перед тем как перейти к вопросам взаимоотношений операционных систем и прикладных программ с AGP, давайте переведем дух и подытожим ключевые преимущества новой технологии.
Во-первых, пиковое значение пропускной способности у AGP в четыре раза выше, чем у шины PCI. Это достигается за счет конвейеризации, побочной адресации и передачи данных как по передним, так и по задним фронтам импульсов тактовой частоты.
Во-вторых, обработка текстур осуществляется напрямую в системной памяти. AGP обеспечивает графическому контроллеру высокоскоростной прямой доступ к системной памяти вместо того, чтобы тратить силы на упреждающую выборку текстурных данных в локальную видеопамять.
В-третьих, уменьшена нагрузка на шину PCI. К этой шине, как известно, подключается не только графический контроллер, но и множество других высокопроизводительных устройств ввода-вывода, таких как дисковые контроллеры, адаптеры локальной сети, системы оцифровки видеоизображений и т.д. AGP функционирует одновременно с большинством транзакций PCI и совершенно независимо от них. Более того, обращения центрального процессора к системной памяти могут происходить одновременно с такими же обращениями к ней графического контроллера по шине AGP.
В-четвертых, повышение параллелизма системы ведет к более сбалансированной производительности персонального компьютера. Процессор Pentium II может заняться другими делами, пока чип графического контроллера работает с текстурными данными, размещенными в системной памяти.
Что дает AGP разработчикам программ
Что могут сделать разработчики прикладного программного обеспечения с интерфейсом AGP? Тут есть две возможности: первая - ничего не делать; вторая - оптимизировать свои продукты под AGP. И в том, и в другом случае большое преимущество AGP заключается в большем количестве и большем размере текстур, обеспечивающем большую реалистичность 3D-графики без потерь в производительности.
Сегодняшние приложения обычно вынуждены самоограничиваться в любой момент времени менее чем 2 мегабайтами текстур, как того требуют графические контроллеры. AGP способна коренным образом изменить эту ситуацию, предполагая, что приложения обладают масштабируемостью с точки зрения применения высококачественных текстурных карт. Кроме того, любые существующие приложения, так же как и новые программы, написанные без специальных усилий по оптимизации для AGP, будут работать в AGP-системах быстрее.
Полностью поддерживающее AGP аппаратное обеспечение действительно способно сделать приложения более простыми. Однако устройства для РС с AGP могут создаваться по трем направлениям, и программное обеспечение, вполне возможно, должно будет поддерживать все три.
Тип 1. Эти устройства имеют интерфейс AGP, но не эксплуатируют его текстурные функции. Они просто передают данные быстрее, чем это позволяет шина PCI. Возможно, они не используют и конвейерные способности AGP или побочную адресацию.
Тип 2. Данные устройства визуализируют текстуры из AGP-памяти, поэтому приложения не нуждаются в свопинге текстур в локальную графическую память. Устройства могут также как иметь, так и не иметь возможности обрабатывать текстуры из локальной памяти. При этом, не работая с текстурами в локальной памяти, они могут функционировать быстрее, поскольку возможны конфликты при доступе к локальной памяти для записи пикселов, обновления экрана, чтения текселов и Z-значений.
Тип 3. Такие устройства работают лучше, когда одновременно задействуют для обработки текстур как локальную, так и AGP-память. Часто используемые или небольшие по размеру текстуры, возможно, лучше разместить в локальной памяти, в то время как не так часто используемые будут храниться в системной памяти. Это уменьшает расход пропускной способности основной памяти, снижая вероятность возникновения на этой почве конфликтов между графическим контроллером и центральным процессором.
DOS-приложения
Прямая обработка текстур в основной памяти требует использования GART, поскольку в современных операционных системах применяется схема виртуальной адресации. Но для приложений, работающих под управлением вчерашних операционных систем (таких как MS-DOS) без виртуальной адресации, использование GART в таких случаях бессмысленно.
Старые приложения, выполняемые под DOS, способны получить выигрыш от большей скорости AGP, но потребуется разработка новых драйверов, которые позволили бы им воспользоваться возможностью графического контроллера напрямую обращаться к текстурам, хранящимся в системной памяти.
Windows-приложения
Немодифицированные Windows-приложения получат пользу от ее AGP, поскольку операционная система и DirectDraw после незначительной доработки будут поддерживать ее по умолчанию. Сегодня AGP уже поддерживается DirectX пятой версии.
Для существующих аппаратных реализаций операционная система должна сделать AGP-память некэшируемой, чтобы не возникло проблем согласования между кэшированием со стороны центрального процессора и использованием данных графическим контроллером. В противном случае доступ графического контроллера к AGP-памяти потребует слежения за кэшем процессора, которое в некоторых случаях может привести к задержкам в работе. Чтение процессором данных из некэшированной памяти происходит медленно, поэтому программы, возможно, должны будут предотвращать чтение данных процессором из основной AGP-памяти так же, как и из локальной графической памяти.
В системах на базе процессоров Pentium II эта некэшируемая графическая память может быть помечена операционной системой как память с "комбинированной записью" (Write Combining, WC), что обеспечивает существенно более быстрый доступ по записи, чем обычный атрибут "некэшируемая" (Uncacheable, UC). Области памяти WC разрешают центральному процессору "скомбинировать" несколько дискретных обращений по записи в пакет записи для передачи по шине, когда та станет доступна. Для этого используются встроенные в чип специально выделенные буферы записи. За исключением большей скорости, механизм WC остается невидимым для приложений.
Если обращения процессора по чтению для WC не быстрее, чем для UC, то использование UC-памяти может заставить процессор Pentium II перейти к большей степени последовательным вычислениям, что существенно замедлит его работу. То, что несколько обращений по записи могут быть собраны вместе перед выходом за пределы центрального процессора, способно повлиять на работу драйверов аппаратных устройств, которые могут оказаться чувствительными к многочисленным последовательным обращениям по записи к одному месту в памяти, и выстраивает их строго по очереди.
Распределение памяти
в DirectDraw
Если приложение специально не потребует иначе, Microsoft DirectDraw по умолчанию выделяет память под текстуры в следующем порядке:
- локальная графическая память контроллера;
- основная AGP-память;
- системная память.
Что, если графический контроллер не способен работать с текстурами в AGP-памяти? Ничего страшного, в такой ситуации необходимо предостеречь DirectDraw от выделения под текстуры любой памяти, кроме локальной. Графический контроллер предоставляет в распоряжение операционной системы и DirectDraw отчет о своих возможностях, и если он не способен напрямую обращаться к системной памяти, DirectDraw будет выделять приложениям только локальную видеопамять. Аналогично, когда графический чип не может работать с текстурами в локальной памяти, DirectDraw не будет их там размещать.
Если все текстуры не помещаются в AGP-памяти, которую согласился выделить интерфейс DirectDraw, приложение должно будет, в конце концов, заняться свопингом текстур с жесткого диска в AGP-память. Высокореалистичные симуляторы полетов или другие приложения, использующие большое количество текстур, могут потребовать организации потока текстур с диска или из сети в AGP-память независимо от того, сколько памяти выделил им DirectDraw.
Приложения извлекают дополнительную выгоду от использования MIP-текстур вместе с AGP, так как MIP-карты (заранее отфильтрованные текстурные карты с разным разрешением) отличаются способностью повышать "локализованность" обращений к памяти во время текстурирования объектов. При этом версия с низким разрешением помещается в небольшом объеме системной памяти, и когда графический чип накладывает эти текстуры на объекты, расположенные вдали от точки наблюдения, контроллер чаще обращается к упрощенной версии текстуры внутри ограниченной области памяти.
Без MIP-текстурирования чип должен пропустить множество байтов большой текстурной карты (с единым разрешением), чтобы найти правильные текселы для каждого выводимого на экран пиксела. Адреса памяти изменяются на большую величину, и ее пропускная способность падает.
Что дает AGP пользователям
В настоящее время технология AGP как с аппаратной, так и с программной точки зрения готова решить проблемы, которые возникнут по мере перехода на будущие "визуальные" способы работы с информацией. На рынке уже достаточно персональных компьютеров, построенных на базе AGP, и их цена все доступнее массовому пользователю.
Они сулят множество преимуществ. Станет возможным использование текстурных карт неограниченного размера, детальности и реалистичности. 3D-приложения будут выполняться намного быстрее, когда отпадет необходимость в упреждающей выборке текстур в локальную память графического контроллера. Насколько? Тест Ziff-Davis 3D WinBench 97 показывает, что при применении AGP скорость вывода 3D-изображений (в кадрах в секунду) может возрасти в 12.6 раза! По шине AGP поток видеоданных без задержек пройдет от процессора к экрану монитора, поэтому качество "живого" видео на РС будет ничуть не хуже телевизионного.
Снижая требования к объему дорогой видеопамяти, AGP дает производителям возможность контролировать стоимость новейших моделей персональных компьютеров и поддерживать ее на доступном, а не таком, как у рабочих станций, уровне. Да и сами компьютеры станут работать надежнее, когда мощный трафик графических и видеоданных, отвлекающий на себя львиную долю пропускной способности шины PCI, будет перенесен с нее на специальную высокоскоростную магистраль AGP.
И в то же время результаты независимых испытаний пока не демонстрируют ощутимого превосходства систем с шиной AGP над аналогичными по конфигурации PCI-системами.
Это, скорее всего, связано с тем, что большинство приложений и операционных систем, так же как и тестовых программ, еще не "научились" использовать мощь новой технологии. В частности, при небольших 3D-сценах (640 х 480 пикселов) иногда PCI-версии графических ускорителей даже оказываются чуть быстрее, чем их AGP-аналоги. Впрочем, уже сегодня при переходе на большие 3D-сцены (800 х 600 или 1,024 х 768 пикселов) и текстуры высокой реалистичности отрыв по производительности систем на базе AGP становится очевидным.
В общем, планируя обновление компьютерной техники, не сбрасывайте со счетов возможность в скором будущем тотального использования приложениями 3D-графики и видео, а следовательно, обратите внимание и на AGP-системы.
Роман Соболенко по материалам Intel компьютерная газета
Он стал достаточно мощным для высококачественной 3D-графики. Он стал достаточно мультимедийным для "живого" интерактивного видео и объемного звучания. В этом году на рынке будут господствовать системы на базе процессоров класса Pentium II и программы с такими возможностями представления информации, о которых пару лет назад и не догадывались пользователи персональных компьютеров.
Сегодня владельцы новых РС могут наслаждаться впечатляющей трехмерной графикой и видео, уровень качества которых раньше был доступен только на рабочих станциях стоимостью за $20,000. И достичь этого удалось во многом благодаря разработкам корпорации Intel, новые процессоры Pentium II которой в сочетании с созданным ею специальным ускоренным графическим портом (Accellerated Graphics Port, AGP) сделали реалистичную 3D-графику и "живое" видео доступными массовому пользователю.
Эти передовые разработки открывают возможности дальнейшего развития архитектуры персональных компьютеров платформы РС и позволяют перейти от ограниченных пропускной способностью шины PCI машин к "визуальным" компьютерам будущего (Visual Connected PC). Время сделать это уже настало.
Конструкция персональных компьютеров следующего поколения обеспечит производительность, требуемую для аркадного качества графики, интерактивных информационных 3D-систем, интерактивного видео, улучшенных приложений моделирования для систем CAD/CAM, захватывающей 3D-визуализации данных и новых трехмерных виртуальных миров VRML.
Однако появляющиеся уже сегодня приложения 3D-графики предъявляют к платформе РС целый букет жестких требований, которые для нее еще вчера были непосильны. Эти требования связаны с более быстрыми геометрическими вычислениями, более изощренными методами визуализации и более детализированными текстурами. Причем если новейшие процессоры, по производительности равные Pentium II, вполне способны справиться с возросшим объемом геометрических расчетов, а новое поколение чипов графических ускорителей поддерживает множество разнообразных эффектов визуализации, то растущий размер текстурных карт становится проблемой N№1.
Один из аспектов этой проблемы связан с объемом локальной видеопамяти, используемой графическим контроллером. Обычно на графической плате имеется 2 - 4 мегабайта такой памяти, в то время как уже появились 3D-приложения, использующие текстурные карты размером под 20 мегабайт. Видеопамять можно расширить, чтобы она удовлетворяла таким требованиям, но в результате компьютеры станут страшно дорогими и немасштабируемыми.
Второй источник головной боли - пропускная способность шины PCI. Графические контроллеры нуждаются в перекачке текстурных карт из основной памяти системы в свою локальную, и по мере роста размеров текстур шина PCI становится узким местом, сдерживающим быстродействие 3D-графики. Еще острее вопрос с приложениями, которые используют "живое" видео.
Решение найдено, и оно уже вполне доступно массовому пользователю. Технология AGP (структурная схема системы на ее основе показана на рис. 1) повышает общую производительность компьютера, предоставляя отдельный высокоскоростной канал между графическим контроллером и системной памятью. Эта магистраль позволяет графическому контроллеру обрабатывать текстуры прямо в основной памяти, а также служит руслом для потока декодированных центральным процессором видеоданных.
Вот и настал момент, когда всем пользователям, если их, конечно, еще интересуют перспективные направления в компьютерной технике, стоит ближе познакомиться с AGP и разобраться в основах того, как эта технология работает. Разумеется, несмотря на популярность материала, от вас потребуются некоторые представления о 3D-графике и архитектуре РС, так как начать с самых азов нет возможности.
3D-графика в предыдущем поколении РС
AGP - это новый интерфейс в компьютерах платформы РС, значительно улучшающий обработку трехмерной графики и "живого" видео. Для того чтобы полностью понять важность технологии AGP для современных и будущих приложений, необходимо сначала посмотреть, как 3D-графика поддерживается в настоящее время персональными компьютерами без AGP.
Известно, что анимированная 3D-графика требует от процессора производительности, достаточной для постоянных геометрических вычислений, которые определяют положение объектов в трехмерном пространстве. Обычно геометрические вычисления выполняются центральным процессором персонального компьютера, поскольку он хорошо подходит для нужных при расчетах операций с плавающей точкой. В то же время графический контроллер должен обрабатывать текстурные данные, чтобы создать в 3D-изображении реалистичные поверхности и тени.
Наиболее критичный аспект 3D-графики - обработка текстурных карт, то есть растровых изображений (карт), которые описывают детали поверхности трехмерных объектов. Обработка текстурных карт заключается в выборке одного, двух, четырех или восьми текселов (текстурных элементов) из растровой карты, их "усреднения", необходимого для получения окончательного изображения, с помощью математической аппроксимации положения в растровой карте (или нескольких картах) и записи полученных в результате пикселов в кадровый буфер графической платы. Расчет координат текселов является нетривиальной функцией; параметрами для нее служат координаты точки наблюдения за 3D-сценой и геометрия объекта, на который проецируются ("натягиваются") растровые карты.
Схема на рис.2 отражает процесс обработки текстурных карт предыдущим поколением персональных компьютеров. Как показано, процесс обработки текстур можно разложить на пять основных шагов.
2. Когда текстурная карта должна быть использована для трехмерной сцены, она считывается из системной памяти процессором. Процессор выполняет над текстурной картой зависящие от точки наблюдения преобразования и сохраняет результаты в кэш-буфере.
3. Над текстурной картой, размещенной в буфере, выполняются преобразования, связанные с расположением внутри 3D-сцены источников освещения и точки наблюдения. Результаты этих операций впоследствии записываются обратно в системную память.
4. Затем графический контроллер считывает преобразованные текстуры из системной памяти и записывает их в свою локальную видеопамять (называемую также памятью графического контроллера, кадровым буфером, экранной памятью). В системах предыдущего поколения, которые составляют сегодня основную часть парка персональных компьютеров, данные при этом должны пройти к графическому контроллеру по шине PCI.
5. Теперь графический контроллер считывает текстуры и двумерную цветовую информацию из своего кадрового буфера. Эти данные используются при визуализации кадра, который можно показать на двумерном экране монитора. Результаты записываются обратно в кадровый буфер. После этого размещенный на графической плате цифро-аналоговый преобразователь (RAMDAC) прочитывает содержимое кадрового буфера и преобразует представленные в цифровом виде пикселы в аналоговые сигналы, управляющие дисплеем.
Возможно, вы уже обратили внимание на массу проблем, сопровождающих описанный и широко применяющийся в настоящее время способ обработки текстурных карт.
Во-первых, текстуры должны храниться как в системной памяти, так и в кадровом буфере. Избыточная копия приводит к неэффективному использованию имеющихся в персональном компьютере ресурсов памяти.
Во-вторых, хранение текстур в кадровом буфере, пусть даже временное, накладывает жесткие ограничения на их размер. Поскольку в последнее время отмечается потребность в текстурах со все более высокой детализацией, на производителей аппаратного обеспечения оказывается прессинг с целью увеличения в их системах емкости кадрового буфера. С учетом того, что этот вид памяти достаточно дорогой, такой подход никак нельзя назвать оптимальным решением.
Наконец, пропускная способность шины PCI, не превышающая 132 мегабайт в секунду, ограничивает скорость, с которой текстурные карты могут быть переданы из памяти графической подсистеме. Более того, обычно в системе шиной PCI совместно пользуется несколько устройств ввода-вывода, поэтому полоса пропускания распределяется между ними. С появлением в составе РС новых высокоскоростных устройств, таких как жесткие диски Ultra DMA и 100-мегабитные сетевые карты, соперничество за часть пропускной способности PCI еще более ожесточилось. Не так уж трудно заметить, как перегрузка шины PCI ограничивает 3D-производительность персональных компьютеров.
Сегодня приложения применяют множество стратегий, чтобы компенсировать ограничения, доставшиеся по наследству от вчерашних персональных компьютеров. В частности, приложения широко используют алгоритмы кэширования, или свопинга, определяя, какие текстуры обязательно будут храниться в локальном кадровом буфере, а какие можно держать только в системной памяти. Обычно приложения выделяют часть экранной памяти под область межкадрового обмена текстурами, оставляя в памяти графической платы постоянно используемые текстуры (фиксированная текстурная память), такие, например, как облака и море в самолетных симуляторах.
Если аппаратно реализована обработка только тех текстур, которые находятся в локальной памяти графической карты, обычно применяется специальный алгоритм, пытающийся загодя загрузить в нее текстуры, необходимые для каждого кадра или сцены. Без упреждающей выборки пользователи могут увидеть на экране заметные паузы, так как программное обеспечение прекращает вывод на экран, пока требуемая текстура переносится из системной памяти в локальную или, что еще хуже, сначала с винчестера в системную память и только потом в локальную. Часто еще большие задержки при начальной загрузке текстур связаны с необходимостью преобразования формата, в котором они хранятся, в зависящий от аппаратной части системы сжатый формат.
3D-графика в следующем поколении РС
Трехмерная графика определенно окажется в выигрыше от многих усовершенствований, внесенных в последнее время в архитектуру платформы РС.
Первое и наиболее значимое из них - переход на процессоры Pentium II. Эти процессоры способны лучше справиться с вычислениями на геометрической стадии конвейера 3D-графики, то есть обеспечивают просчет в секунду большего количества треугольников, из которых строятся 3D-объекты.
Процессор Pentium II содержит не только ядро, но и интегрированную кэш-память второго уровня. Он также имеет двойную независимую шинную архитектуру, при которой ядро процессора с кэш-памятью второго уровня и системной шиной персонального компьютера соединяют две независимые шины. То, что обе эти шины способны работать в одно и то же время, значительно повышает производительность процессора, поскольку он может одновременно выполнять операции с кэшем и взаимодействовать с внешними устройствами.
Появление AGP стало другим ключевым расширением платформы РС, от которого выиграет 3D-графика. AGP устраняет узкие места в реализации трехмерной графики, добавляя новую специальную высокоскоростную шину, обеспечивающую прямое взаимодействие между чипсетом и графическим контроллером. Это выводит требующий большой пропускной способности видео- и 3D-трафик из-под ограничений шины PCI.
Кроме того, AGP открывает во время визуализации доступ к текстурам прямо в системной памяти вместо их упреждающей выборки в локальную графическую память (см. рис. 3). Сегменты системной памяти могут динамически резервироваться операционной системой для использования графическим контроллером - такая память называется AGP-памятью, или нелокальной видеопамятью.
Наконец, необходимо отметить, что разгрузка шины PCI от графических и видеоданных оставляет на ней больше свободного места в распоряжении других высокоскоростных устройств, тоже предъявляющих большие претензии на пропускную способность шины.
Для шины AGP применен коннектор, подобный используемому для шины PCI - с 32 линиями для мультиплексированных адресов и данных. Введено 8 дополнительных линий для побочной адресации, которая описана ниже.
Локальная видеопамять обычно намного дороже, чем системная, и не может быть использована операционной системой для других целей, когда не востребована на графические нужды выполняемых приложений. Графическому контроллеру необходим как можно более быстрый доступ к локальной видеопамяти для обновления экрана, ее использования под Z-буферы и пикселы (буферы выводимого на экран и формируемого кадров). По этим причинам при использовании AGP программисты могут рассчитывать на получение большего объема текстурной памяти из общей памяти системы. Хранение текстур вне кадрового буфера обеспечивает поддержку больших разрешений экрана или Z-буферизацию для больших трехмерных сцен. Большинство новых 3D-приложений рассчитано на использование для хранения текстур от 2 до 16 мегабайт памяти. В случае AGP они могут ее получить.
Режимы передачи данных в AGP
Если максимальная скорость передачи данных по шине PCI составляет 132 мегабайта в секунду, AGP по той же частоте в 66 мегагерц способна пропустить 528 мегабайт в секунду. Столь значительное повышение скорости достигается, во-первых, за счет передачи данных как на передних, так и на задних фронтах 66-мегагерцевых тактовых импульсов, а также путем использования более эффективных режимов передачи данных. (Действительная скорость может отличаться для различных систем и приложений, но обычно она составляет 50 - 80% от пиковых значений при установившихся реальных процессах передачи данных.)
AGP предоставляет графическому контроллеру два режима для прямого доступа к текстурным картам в системной памяти: конвейеризацию и побочную адресацию. При конвейеризации AGP перекрывает время доступа к памяти или шине для запроса (n) выдачей последующих запросов (n+1, n+2 и т.д.). У шины PCI запрос n+1 не может начать выполняться, пока не будет закончена передача данных по запросу n. И если обе шины - и PCI, и AGP - способны передавать данные пакетами (передавать множество объектов данных последовательно в ответ на единственный запрос), это только частично скрывает неконвейерную сущность PCI. Глубина конвейеризации AGP зависит от ее реализации и остается невидимой для прикладных программ.
При побочной адресации AGP использует 8 дополнительных "побочных" адресных линий, которые позволяют графическому контроллеру передавать новые адреса и запросы одновременно с тем, как данные продолжают поступать в ответ на предыдущий запрос по основным 32 адресно-информационным линиям (см. рис. 4).
Распределение AGP-памяти
Так называемая AGP-память на деле является просто динамически выделяемой областью основной системной памяти, к которой организуется быстрый доступ графического контроллера. Высокая скорость обращения обеспечивается аппаратными средствами, встроенными в поддерживающие AGP чипсеты 440LX от Intel и Apollo VP3 от VIA.
Чипсет берет на себя трансляцию адресов, позволяя графическому контроллеру и его программному обеспечению "видеть" последовательную область в основной памяти, когда на самом деле она организована постранично и страницы не всегда являются смежными. Благодаря этому контроллер может обращаться к большим структурам данных, таким как растровые текстуры (обычно от 1 до 128 килобайт), как к единственному объекту (графическому примитиву).
Встроенное в чипсет аппаратное обеспечение называется таблицей преобразования графических адресов (Graphics Address Remapping Table, GART) и работает подобно устройству страничного доступа к памяти, входящему в состав центрального процессора. Процессорные "линейные" виртуальные адреса преобразуются этим устройством в физические адреса. Эти физические адреса и используются для доступа к системной памяти, локальному кадровому буферу и AGP-памяти. Причем центральный процессор обращается к локальному кадровому буферу и AGP-памяти, используя такие же адреса, как и графический контроллер. Операционная система, следовательно, конфигурирует страничное устройство центрального процессора для прямого, один к одному, бестрансляционного преобразования виртуальных адресов в физические.
Подводя итоги: преимущества AGP
Перед тем как перейти к вопросам взаимоотношений операционных систем и прикладных программ с AGP, давайте переведем дух и подытожим ключевые преимущества новой технологии.
Во-первых, пиковое значение пропускной способности у AGP в четыре раза выше, чем у шины PCI. Это достигается за счет конвейеризации, побочной адресации и передачи данных как по передним, так и по задним фронтам импульсов тактовой частоты.
Во-вторых, обработка текстур осуществляется напрямую в системной памяти. AGP обеспечивает графическому контроллеру высокоскоростной прямой доступ к системной памяти вместо того, чтобы тратить силы на упреждающую выборку текстурных данных в локальную видеопамять.
В-третьих, уменьшена нагрузка на шину PCI. К этой шине, как известно, подключается не только графический контроллер, но и множество других высокопроизводительных устройств ввода-вывода, таких как дисковые контроллеры, адаптеры локальной сети, системы оцифровки видеоизображений и т.д. AGP функционирует одновременно с большинством транзакций PCI и совершенно независимо от них. Более того, обращения центрального процессора к системной памяти могут происходить одновременно с такими же обращениями к ней графического контроллера по шине AGP.
В-четвертых, повышение параллелизма системы ведет к более сбалансированной производительности персонального компьютера. Процессор Pentium II может заняться другими делами, пока чип графического контроллера работает с текстурными данными, размещенными в системной памяти.
Что дает AGP разработчикам программ
Что могут сделать разработчики прикладного программного обеспечения с интерфейсом AGP? Тут есть две возможности: первая - ничего не делать; вторая - оптимизировать свои продукты под AGP. И в том, и в другом случае большое преимущество AGP заключается в большем количестве и большем размере текстур, обеспечивающем большую реалистичность 3D-графики без потерь в производительности.
Сегодняшние приложения обычно вынуждены самоограничиваться в любой момент времени менее чем 2 мегабайтами текстур, как того требуют графические контроллеры. AGP способна коренным образом изменить эту ситуацию, предполагая, что приложения обладают масштабируемостью с точки зрения применения высококачественных текстурных карт. Кроме того, любые существующие приложения, так же как и новые программы, написанные без специальных усилий по оптимизации для AGP, будут работать в AGP-системах быстрее.
Полностью поддерживающее AGP аппаратное обеспечение действительно способно сделать приложения более простыми. Однако устройства для РС с AGP могут создаваться по трем направлениям, и программное обеспечение, вполне возможно, должно будет поддерживать все три.
Тип 1. Эти устройства имеют интерфейс AGP, но не эксплуатируют его текстурные функции. Они просто передают данные быстрее, чем это позволяет шина PCI. Возможно, они не используют и конвейерные способности AGP или побочную адресацию.
Тип 2. Данные устройства визуализируют текстуры из AGP-памяти, поэтому приложения не нуждаются в свопинге текстур в локальную графическую память. Устройства могут также как иметь, так и не иметь возможности обрабатывать текстуры из локальной памяти. При этом, не работая с текстурами в локальной памяти, они могут функционировать быстрее, поскольку возможны конфликты при доступе к локальной памяти для записи пикселов, обновления экрана, чтения текселов и Z-значений.
Тип 3. Такие устройства работают лучше, когда одновременно задействуют для обработки текстур как локальную, так и AGP-память. Часто используемые или небольшие по размеру текстуры, возможно, лучше разместить в локальной памяти, в то время как не так часто используемые будут храниться в системной памяти. Это уменьшает расход пропускной способности основной памяти, снижая вероятность возникновения на этой почве конфликтов между графическим контроллером и центральным процессором.
DOS-приложения
Прямая обработка текстур в основной памяти требует использования GART, поскольку в современных операционных системах применяется схема виртуальной адресации. Но для приложений, работающих под управлением вчерашних операционных систем (таких как MS-DOS) без виртуальной адресации, использование GART в таких случаях бессмысленно.
Старые приложения, выполняемые под DOS, способны получить выигрыш от большей скорости AGP, но потребуется разработка новых драйверов, которые позволили бы им воспользоваться возможностью графического контроллера напрямую обращаться к текстурам, хранящимся в системной памяти.
Windows-приложения
Немодифицированные Windows-приложения получат пользу от ее AGP, поскольку операционная система и DirectDraw после незначительной доработки будут поддерживать ее по умолчанию. Сегодня AGP уже поддерживается DirectX пятой версии.
Для существующих аппаратных реализаций операционная система должна сделать AGP-память некэшируемой, чтобы не возникло проблем согласования между кэшированием со стороны центрального процессора и использованием данных графическим контроллером. В противном случае доступ графического контроллера к AGP-памяти потребует слежения за кэшем процессора, которое в некоторых случаях может привести к задержкам в работе. Чтение процессором данных из некэшированной памяти происходит медленно, поэтому программы, возможно, должны будут предотвращать чтение данных процессором из основной AGP-памяти так же, как и из локальной графической памяти.
В системах на базе процессоров Pentium II эта некэшируемая графическая память может быть помечена операционной системой как память с "комбинированной записью" (Write Combining, WC), что обеспечивает существенно более быстрый доступ по записи, чем обычный атрибут "некэшируемая" (Uncacheable, UC). Области памяти WC разрешают центральному процессору "скомбинировать" несколько дискретных обращений по записи в пакет записи для передачи по шине, когда та станет доступна. Для этого используются встроенные в чип специально выделенные буферы записи. За исключением большей скорости, механизм WC остается невидимым для приложений.
Если обращения процессора по чтению для WC не быстрее, чем для UC, то использование UC-памяти может заставить процессор Pentium II перейти к большей степени последовательным вычислениям, что существенно замедлит его работу. То, что несколько обращений по записи могут быть собраны вместе перед выходом за пределы центрального процессора, способно повлиять на работу драйверов аппаратных устройств, которые могут оказаться чувствительными к многочисленным последовательным обращениям по записи к одному месту в памяти, и выстраивает их строго по очереди.
Распределение памяти
в DirectDraw
Если приложение специально не потребует иначе, Microsoft DirectDraw по умолчанию выделяет память под текстуры в следующем порядке:
- локальная графическая память контроллера;
- основная AGP-память;
- системная память.
Что, если графический контроллер не способен работать с текстурами в AGP-памяти? Ничего страшного, в такой ситуации необходимо предостеречь DirectDraw от выделения под текстуры любой памяти, кроме локальной. Графический контроллер предоставляет в распоряжение операционной системы и DirectDraw отчет о своих возможностях, и если он не способен напрямую обращаться к системной памяти, DirectDraw будет выделять приложениям только локальную видеопамять. Аналогично, когда графический чип не может работать с текстурами в локальной памяти, DirectDraw не будет их там размещать.
Если все текстуры не помещаются в AGP-памяти, которую согласился выделить интерфейс DirectDraw, приложение должно будет, в конце концов, заняться свопингом текстур с жесткого диска в AGP-память. Высокореалистичные симуляторы полетов или другие приложения, использующие большое количество текстур, могут потребовать организации потока текстур с диска или из сети в AGP-память независимо от того, сколько памяти выделил им DirectDraw.
Приложения извлекают дополнительную выгоду от использования MIP-текстур вместе с AGP, так как MIP-карты (заранее отфильтрованные текстурные карты с разным разрешением) отличаются способностью повышать "локализованность" обращений к памяти во время текстурирования объектов. При этом версия с низким разрешением помещается в небольшом объеме системной памяти, и когда графический чип накладывает эти текстуры на объекты, расположенные вдали от точки наблюдения, контроллер чаще обращается к упрощенной версии текстуры внутри ограниченной области памяти.
Без MIP-текстурирования чип должен пропустить множество байтов большой текстурной карты (с единым разрешением), чтобы найти правильные текселы для каждого выводимого на экран пиксела. Адреса памяти изменяются на большую величину, и ее пропускная способность падает.
Что дает AGP пользователям
В настоящее время технология AGP как с аппаратной, так и с программной точки зрения готова решить проблемы, которые возникнут по мере перехода на будущие "визуальные" способы работы с информацией. На рынке уже достаточно персональных компьютеров, построенных на базе AGP, и их цена все доступнее массовому пользователю.
Они сулят множество преимуществ. Станет возможным использование текстурных карт неограниченного размера, детальности и реалистичности. 3D-приложения будут выполняться намного быстрее, когда отпадет необходимость в упреждающей выборке текстур в локальную память графического контроллера. Насколько? Тест Ziff-Davis 3D WinBench 97 показывает, что при применении AGP скорость вывода 3D-изображений (в кадрах в секунду) может возрасти в 12.6 раза! По шине AGP поток видеоданных без задержек пройдет от процессора к экрану монитора, поэтому качество "живого" видео на РС будет ничуть не хуже телевизионного.
Снижая требования к объему дорогой видеопамяти, AGP дает производителям возможность контролировать стоимость новейших моделей персональных компьютеров и поддерживать ее на доступном, а не таком, как у рабочих станций, уровне. Да и сами компьютеры станут работать надежнее, когда мощный трафик графических и видеоданных, отвлекающий на себя львиную долю пропускной способности шины PCI, будет перенесен с нее на специальную высокоскоростную магистраль AGP.
И в то же время результаты независимых испытаний пока не демонстрируют ощутимого превосходства систем с шиной AGP над аналогичными по конфигурации PCI-системами.
Это, скорее всего, связано с тем, что большинство приложений и операционных систем, так же как и тестовых программ, еще не "научились" использовать мощь новой технологии. В частности, при небольших 3D-сценах (640 х 480 пикселов) иногда PCI-версии графических ускорителей даже оказываются чуть быстрее, чем их AGP-аналоги. Впрочем, уже сегодня при переходе на большие 3D-сцены (800 х 600 или 1,024 х 768 пикселов) и текстуры высокой реалистичности отрыв по производительности систем на базе AGP становится очевидным.
В общем, планируя обновление компьютерной техники, не сбрасывайте со счетов возможность в скором будущем тотального использования приложениями 3D-графики и видео, а следовательно, обратите внимание и на AGP-системы.
Роман Соболенко по материалам Intel компьютерная газета
Компьютерная газета. Статья была опубликована в номере 03 за 1998 год в рубрике hard :: технологии
